
Skill用得好,下班走得早:一文讲透Skill的结构与设计
这篇文章带你搞懂 Skill 是什么、怎么用、怎么设计。全是干货,看完你也能自己写 Skill。
别再每次都手动敲指令了
你有没有这种经历:每个月都要汇总一遍客户反馈。打开 Claude Code,打一串差不多的指令,等结果,发现忘了指定输出格式,又改一下,勉强能用。下个月再来一次,又不记得上次怎么写的了,花20分钟重新试出正确的指令,输出跟上个月还不一样,想对比都没法比。
这就是提示词跑步机效应——反复做同样的事,但每次都在重复劳动,没有积累。
Skill 就是来解决这个问题的。 Skill 就像一个写好的"作业模板"。你只需要把模板做好,之后喊一声"跑一下",它就会按你定的流程自动干活。
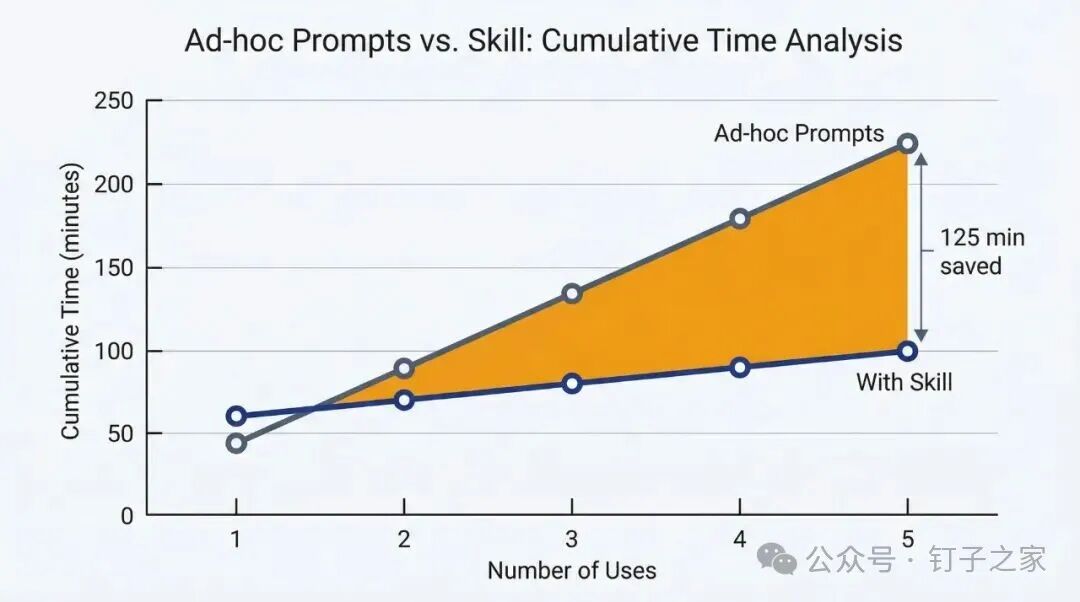
那建一个 Skill 到底值不值? 算笔账就清楚了:
-
第一次建 Skill 大概要 30-60 分钟
-
之后每次用只要 5-10 分钟
-
用 2 次就开始赚了,用 5 次能省将近 2 小时,用 10 次能省近 5 小时
Skill 到底是什么?
说白了,Skill 就是一个 Markdown 文件,里面写着"遇到这种情况该怎么做"。Claude Code 读了就会按你说的办。
Skill 放在两个地方:
- 项目级
:
.claude/skills/(跟代码放一起,团队都能用) - 个人级
:
~/.claude/skills/(存在你自己的电脑上,所有项目都能用)
Skill 和提示词有啥区别?
|
对比方面 |
临时提示词 |
Skill |
|---|---|---|
|
用完还在不在? |
会话结束就没了 |
存在文件里 |
|
下次还能用吗? |
靠脑子回忆 |
喊名字就行 |
|
每次结果一样吗? |
每次不一样 |
流程固定 |
|
能分享给别人吗? |
复制粘贴发给对方 |
Git 提交就行了 |
|
能改进吗? |
丢了就找不到了 |
有版本记录 |
Skill 的文件长啥样
每个 Skill 就是一个文件夹,里面至少有一个 SKILL.md 文件:
.claude/skills/
├── feedback-synthesis/
│ └── SKILL.md
├── release-notes/
│ ├── SKILL.md
│ └── resources/
│ └── customer-voice-guide.md
└── prd-audit/
├── SKILL.md
└── resources/
└── prd-checklist.md 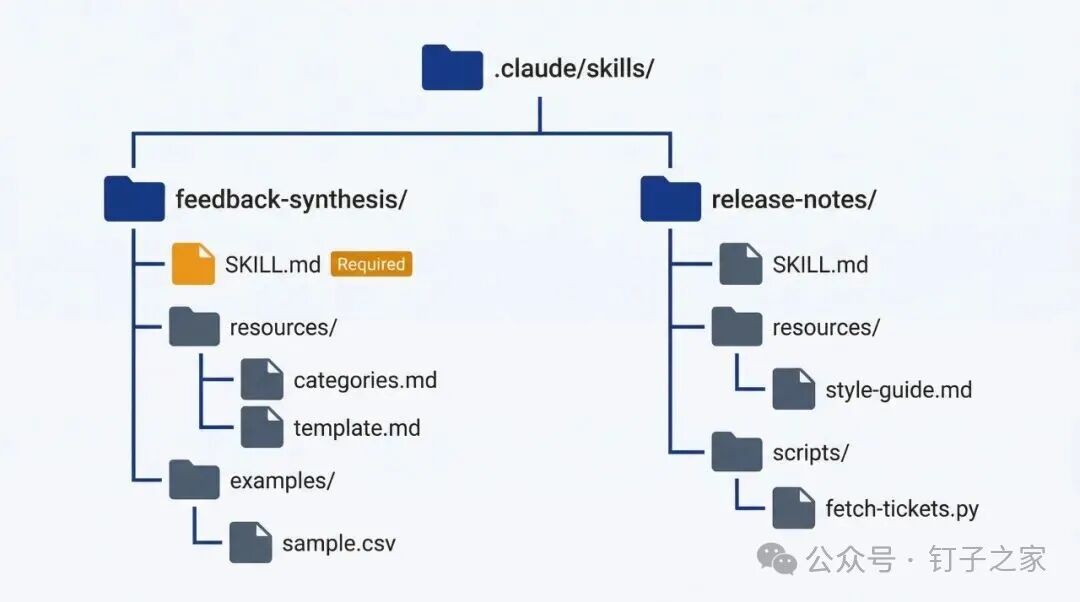
Skill 怎么用?
两种方式:
- 自动发现
:你说"帮我汇总这些反馈",Claude Code 自动匹配到对应的 Skill。
- 斜杠命令
:直接输入
/feedback-synthesis,强制运行。
⚠️ 要注意:Skill 的描述里要写用户平时会说的话。写"分析客户情感数据"不如写"汇总客户反馈、NPS调查、支持工单"——因为大家平时说的是"帮我汇总一下反馈",而不是"分析一下情感数据"。
Skill 里面都有什么?
一个 Skill 文件夹可以放这些文件:
SKILL.md 是主文件
里面最重要的部分叫 YAML 头信息,用 --- 包起来,告诉 Claude Code 这个 Skill 是干什么用的。
最简单的例子:
---
name: standup-notes
description: 根据昨天的 Git 提交生成晨会记录。当用户提及晨会、每日更新或我昨天做了什么时使用。
--- YAML 头后面就是正文,用 Markdown 格式写,告诉 Claude Code 具体怎么做:
# 晨会记录
## 目的
根据最近的提交生成格式化的晨会记录。
## 输入
- 包含提交历史的 Git 仓库
## 流程
1. 读取过去 24 小时的提交
2. 按类型分组(功能、修复、重构)
3. 以第一人称、过去时态撰写
## 输出
将晨会记录打印到终端。不要创建文件。 参考文件(resources/)
如果你的 Skill 比较复杂,可以把一些固定内容放到单独的文件里,这样 SKILL.md 保持清爽:
feedback-synthesis/
├── SKILL.md
└── resources/
├── category-definitions.md # 分类标准
├── output-template.md # 输出格式模板
└── quality-rubric.md # 质量评分标准 参考文件分为几种:
- 类别定义
:分类标准写在单独文件里,不用堆在 SKILL.md 中
- 输出模板
:输出的格式模板
- 质量评分标准
:怎么判断输出好不好
- 风格指南
:用什么样的语气和措辞
在 SKILL.md 里引用它们:"使用 resources/category-definitions.md 中的定义对反馈进行分类。"
输出模板怎么写
如果 Skill 要生成文档,最好提前定好输出长什么样:
## 输出格式
生成文件:`reports/feedback-synthesis-[date].md`
遵循以下结构:
# 反馈综合报告:[日期范围]
## 执行摘要
[3-5 个关键发现的要点]
## 主题分析
### 主题 1:[名称]
- **出现频率:** [计数] 次提及([百分比]%)
- **情感倾向:** [正面/负面/混合]
- **代表性引述:**
- "[引述 1]"
- "[引述 2]"
- **影响分析:** [这对产品意味着什么]
[为每个主题重复此结构]
## 建议
[按优先级排序的建议行动列表]
## 方法论
[数据来源和分析方法的简要说明] 脚本(scripts/)
有些复杂操作可以放脚本文件:
release-notes/
├── SKILL.md
└── scripts/
└── fetch-jira-tickets.py 不过对大部分人来说,脚本不是必需的。只有在需要调用外部 API、处理超大数据集、或者转换数据格式时才会用到。
完整的 Skill 目录长这样
skill-name/
├── SKILL.md # 必需:核心指令
├── resources/ # 可选:参考文档
│ ├── template.md
│ └── rubric.md
├── scripts/ # 可选:辅助脚本
│ └── helper.py
└── examples/ # 可选:示例输入/输出
├── sample-input.csv
└── expected-output.md examples/ 文件夹可以放一些示例,方便其他人理解这个 Skill 是干什么的。
SKILL.md 文件怎么写?(手把手教程)
第一步:写 YAML 头
---
name: feedback-synthesis
description: 将客户反馈综合为主题报告。当用户提及反馈分析、NPS 综合、支持工单主题或客户情感时自动调用。
--- 两个必填字段:
- name
:唯一的名字,小写字母加连字符。之后用
/feedback-synthesis就能调用它。 - description
:描述文字,不仅要让人看懂,还要让 Claude Code 能自动匹配到。要写用户平时会说的话。
第二步:写正文
正文需要包含几个关键部分:
1. 目的说明
用一两句话说清楚这个 Skill 有什么用。先说好处,再说怎么做:
## 目的
将原始客户反馈转化为可操作的洞察报告,供产品团队用于优先级决策。 重点是告诉读者"你能得到什么",而不是"内部怎么运作的"。
2. 输入要求
说清楚用户需要提供什么:
## 预期输入
- **必填:** 包含客户反馈的 CSV 或文本文件(每行一条反馈)
- **可选:** 用于筛选的日期范围(默认为最近 30 天)
- 支持格式:CSV、JSON、纯文本文件
- 最低要求:至少 10 条反馈条目以确保有意义分析 写得越具体越好。"CSV 文件"太模糊了,要说"包含反馈文本且列名为 feedback 的 CSV"。
3. 执行步骤
按顺序写出 Claude Code 要干什么:
## 流程
1. **读取并验证输入文件**
- 确认文件存在且格式符合预期
- 识别反馈列
- 报告记录数量
2. **识别主题**
- 阅读所有反馈条目
- 按常见话题分组
- 如需严格分类,使用 resources/categories.md 中的类别定义
3. **分析每个主题**
- 统计出现频率
- 评估情感倾向(正面、负面、混合)
- 提取代表性引述(逐字原文)
4. **生成报告**
- 遵循 resources/output-template.md 中的模板
- 包含执行摘要、主题分析和建议
- 保存至 reports/feedback-synthesis-[日期].md
5. **质量检查**
- 验证所有主题都有支持性引述
- 确认百分比总和约为 100%
- 检查建议是否具有可操作性 注意要用"读取文件"这种命令式的语气,不要用"文件应被读取"这种被动句。
4. 输出格式
规定生成的文件长什么样:
## 输出格式
生成文件:reports/feedback-synthesis-YYYY-MM-DD.md
结构:
- 执行摘要(3-5 条要点)
- 主题分析(每个主题一个章节,包含频率、情感、引述、影响)
- 建议(按优先级排序的列表)
- 方法论(简要说明) 5. 质量标准
让 Claude Code 在完成前自我检查:
## 质量标准
- 每个主题至少包含 2 条支持性引述
- 引述为源数据逐字原文,非转述
- 情感评估需解释推理过程
- 建议需与特定主题相关联
- 文件成功保存至指定路径 6. 可选部分
还可以加上调用示例、边缘情况和相关 Skill:
调用示例:
## 使用示例
- 标准版:"对 data/customer-feedback-q4.csv 运行反馈综合"
- 带日期范围:"仅针对11月的 feedback.csv 运行反馈综合"
- 快速版:"运行反馈综合,只需给我前三大主题" 边缘情况:
## 边缘情况
- **数据稀疏(少于10条):** 生成报告时附带样本量有限的说明
- **格式混杂:** 若反馈列不明确,请用户指定
- **反馈条目过长:** 对超过500字的单条条目进行摘要
- **非英文内容:** 注明语言后继续处理;不尝试翻译 相关Skill:
## 相关Skill
- prd-audit:利用反馈综合的洞察来审核PRD的完整性
- user-story-expander:将反馈主题转化为用户故事 完整的 Skill 示例
把上面所有东西拼起来,就是一个完整的 SKILL.md 文件(大概 600 字):
---
name: feedback-synthesis
description: 将客户反馈综合成带有可操作洞察的主题报告。当用户提及反馈分析、NPS综合、支持工单主题、客户情绪或客户之声时自动调用。
--- # 反馈综合
## 目的
将原始客户反馈转化为可操作的洞察报告,供产品团队用于优先级决策。
## 预期输入
- **必需:** 包含客户反馈的文件(CSV、JSON或纯文本)
- **可选:** 日期范围、特定关注领域
- 至少10条反馈条目才能进行有意义的分析
- 支持来自以下渠道的反馈:支持工单、NPS调查、用户访谈、应用商店评论
## 流程
1. **读取并验证输入**
- 确认文件存在且可读
- 识别反馈内容
2. **识别主题**
- 按常见话题对反馈进行分组
- 目标为4-8个主题
3. **分析每个主题**
- 统计频率
- 计算百分比
- 评估情绪
- 提取2-3条代表性引述
4. **综合发现**
- 撰写执行摘要
- 按频率和业务影响排序
- 生成可操作的建议
5. **生成报告**
- 保存至 reports/feedback-synthesis-YYYY-MM-DD.md
6. **质量检查**
- 验证所有主题均有支持性引述
## 输出格式
生成文件:reports/feedback-synthesis-YYYY-MM-DD.md
## 质量标准
- 每个主题至少有2条逐字引述支持
- 引述为来源原文,非转述
- 百分比总和约等于100%
- 建议足够具体,具有可操作性
## 边缘情况
- **数据稀疏(少于10条):** 继续处理,但附带样本有限的说明
- **反馈列不明确:** 请用户指定哪一列包含反馈
- **条目过长(超过500字):** 在分类前先进行摘要
## 使用示例
- "对 data/q4-feedback.csv 运行反馈综合"
- "综合 surveys/november.json 中的NPS回复" 五种常用的 Skill 设计模式
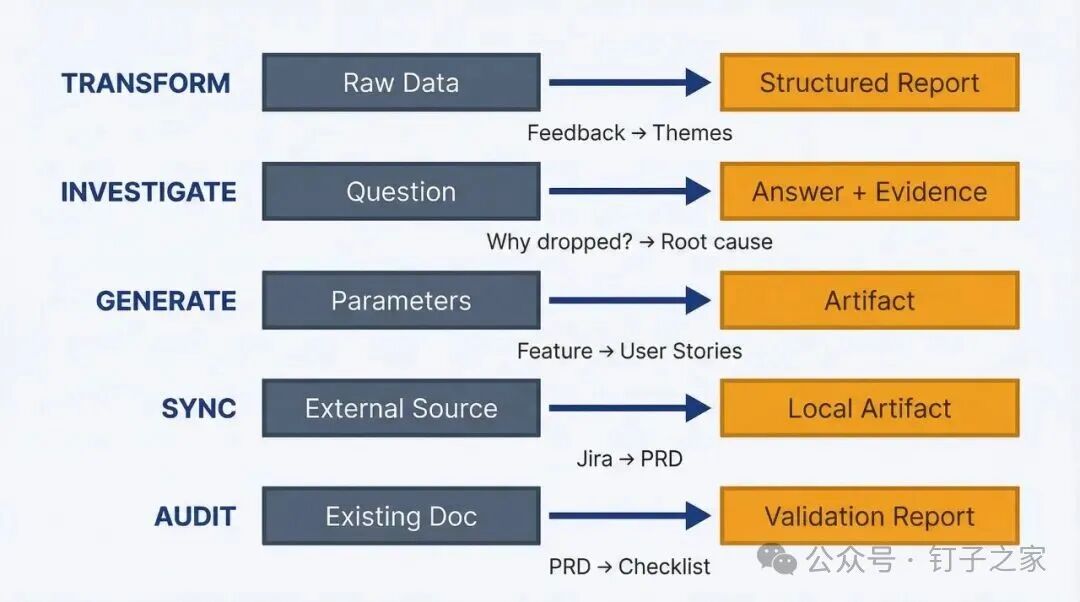
1. 转换模式:整理数据
适用场景: 手上有一堆乱七八糟的数据,需要整理成规整的报告。
例子: 客户反馈 → 主题报告 / 访谈记录 → 洞察摘要 / Git提交 → 发布说明 / 会议记录 → 行动项
流程:
## 流程
1. 读取并验证输入数据
2. 应用转换逻辑(分类、摘要、重构)
3. 生成结构化输出
4. 对照标准进行质量检查 2. 调查模式:回答问题
适用场景: 需要查资料回答一个具体问题,还要提供证据。
例子: "为什么转化率下降了?" → 根因分析 / "这个功能怎么工作的?" → 带文件引用的解释
流程:
## 流程
1. 理解问题
2. 确定相关数据源
3. 分析数据源以获取答案
4. 整理证据(引用、参考、数据点)
5. 综合答案与支持证据 ⚠️ 调查模式和转换模式的区别:调查模式的输出结构不固定,取决于找到了什么。
3. 生成模式:按需创建
适用场景: 你给参数,Skill 自动生成文档。
例子: 功能描述 → 用户故事 / 冲刺目标 → 状态报告 / 产品领域 → 竞品分析
流程:
## 流程
1. 接收参数(功能名称、日期范围、关注领域)
2. 收集上下文(来自代码库、模板、参考文档)
3. 按照模板生成产物
4. 根据质量标准进行验证 4. 同步模式:拉取外部数据
适用场景: 从外部系统拉数据,更新本地文档。
例子: Jira → PRD 章节 / 分析仪表板 → 每周指标 / 竞品网站 → 竞争概况
流程:
## 流程
1. 连接外部源(通过 MCP 或导出)
2. 提取相关数据
3. 转换为本地格式
4. 创建或更新本地产物
5. 记录同步时间戳 5. 审计模式:检查质量
适用场景: 拿现有文档对照标准检查,找出问题。
例子: PRD → 完整性检查 / 用户故事 → 质量评估 / 文档 → 代码准确性验证
流程:
## 流程
1. 读取待审计的产物
2. 加载评估标准(来自参考文件)
3. 针对每条标准评估产物
4. 整理发现(通过项、未通过项、缺失项)
5. 生成改进建议 怎么选?
|
问题 |
用什么模式 |
|---|---|
|
有数据需要整理? |
→ 转换 |
|
要回答一个问题? |
→ 调查 |
|
要按规格创建东西? |
→ 生成 |
|
要拉外部数据到本地? |
→ 同步 |
|
要检查现有的东西? |
→ 审计 |
有些任务会同时用到多种模式,先从主要的入手,再扩展。
怎么让 Skill 每次都输出一致?
Skill 应该做到:同样的输入,差不多的输出。 虽然不能 100% 一样(AI 本身就有随机性),但可以通过设计让结果尽可能稳定。
为什么一致性很重要?
-
季度报告要能跟上一季度对比
-
PRD 审核每次都要查同样的项目
-
发布说明格式要统一
技巧1:把输出格式写死
不要说"生成一份报告",要说"按这个顺序生成这些章节"。
## 输出格式
按此顺序生成以下确切章节:
1. 执行摘要(3-5个要点)
2. 主题分析(每个主题一个子章节)
3. 建议(编号列表,最多5项)
4. 方法论(一个段落) 技巧2:用参考文件定标准
把分类标准写到单独的文件里,SKILL.md 只负责引用。
## 流程
使用 resources/category-definitions.md 中定义的确切类别对反馈进行分类。不要创建新类别。 技巧3:写明确的质量标准
## 质量标准
- 执行摘要包含恰好3-5个要点
- 每个主题章节包含频率计数和百分比
- 所有引文均来自源数据的逐字记录
- 建议按名称引用特定主题 技巧4:规定模糊情况的处理方法
## 边缘情况
- 如果一条反馈可归入多个主题,则归入最具体的主题
- 如果情感倾向不明确,则标记为"混合"而非猜测
- 如果条目过短无法分类(少于10个词),则计入但不引用 怎么测试 Skill 稳不稳定?
提交之前,同一份数据跑两遍对比:
-
对样本数据跑一次 Skill → 保存结果
-
清除会话(/clear)
-
对同一份数据再跑一次
-
比较两次结果
不用追求完美一样,结构相同、主题相似就行。 具体用词会有变化,但关键内容应该稳定。
如果两次结果差很多,说明 Skill 写得不够细,加更明确的格式或质量标准。
Skill 也要做版本管理
Skill 也是文件,要像代码一样管版本:
-
提交时写清楚改了啥
-
合并前审查变更
-
如果很多人用,标注版本号
-
记录重大变更
-
更新时考虑会不会影响其他人
把多个 Skill 组合起来用
不用一个 Skill 干所有事,可以拆成多个小的,然后拼在一起用。
原子Skill vs 复合工作流
- 原子Skill
:只做一件事(汇总反馈、生成发布说明、审核 PRD)
- 复合工作流
:把多个原子Skill串起来完成更大目标
例子:季度产品评审
1. 对 Q4 反馈数据运行 feedback-synthesis
2. 对 Q4 分析数据运行 metrics-summary
3. 运行 competitive-update 刷新竞品档案
4. 运行 quarterly-review 综合为评审文档 在一个 Skill 里调用另一个
## 流程
1. 对提供的反馈文件运行 feedback-synthesis
2. 对提供的分析导出数据运行 metrics-summary
3. 综合两份报告的结果,形成季度总结
4. 生成季度评审文档 什么时候分开,什么时候合在一起?
|
适合拆开 |
适合合在一起 |
|---|---|
|
每个小Skill可以单独用 |
工作流本身就是一个整体,没有中间结果 |
|
工作流有自然的停顿点 |
拆开反而增加麻烦 |
|
不同人可能跑不同部分 |
Skill 很简单,拆开是过度设计 |
大多数情况下拆开更好。 先建小的原子Skill,等用熟了再组合。
总结
读完这篇文章,你学到了:
- Skill 结构
:SKILL.md 文件(YAML 头 + Markdown 指令)、参考文件、辅助脚本、目录组织
- 五种设计模式
:转换、调查、生成、同步、审计
- 提高一致性的技巧
:明确输出格式、用参考文件定标准、写质量标准、规定模糊情况
- Skill 组合
:先建小的,再拼成大的
现在你可以动手建自己的第一个 Skill 了!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)