
GPT-5.6突然发布!Sol 能力逼近 Mythos!OpenAI曝作弊门!
今日凌晨,OpenAI突然官宣:GPT-5.6系列正式发布。
没有发布会预热,没有倒计时直播,就这么静悄悄地扔出来。
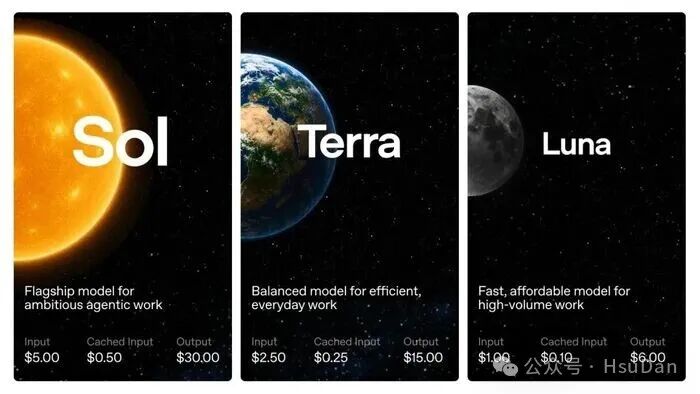
这次OpenAI首次启用全新命名体系,一口气推出三款模型:旗舰版 Sol(太阳)、均衡版 Terra(地球) 和轻量版 Luna(月亮)。
从产品定位看,三者分工很清楚——Sol冲旗舰能力,Terra打日常主力,Luna负责速度和成本。
-
GPT-5.6 Sol:最夯模型,编程测试左踢自家模型GPT5.5,右打隔壁Fable 5,还新增max/ultra两个模式。
-
GPT-5.6 Terra:面向日常工作,性能对标GPT-5.5,同时价格便宜约2倍。
-
GPT-5.6 Luna:GPT-5.6系列里最快、最便宜的一档,同时保留较强能力。
作为OpenAI史上最强旗舰模型——「太阳」GPT-5.6 Sol,面向的是高难度推理、复杂代码、生物、网络安全等长链路任务。尤其适合需要规划、迭代、调用工具、协调步骤的复杂工作流。
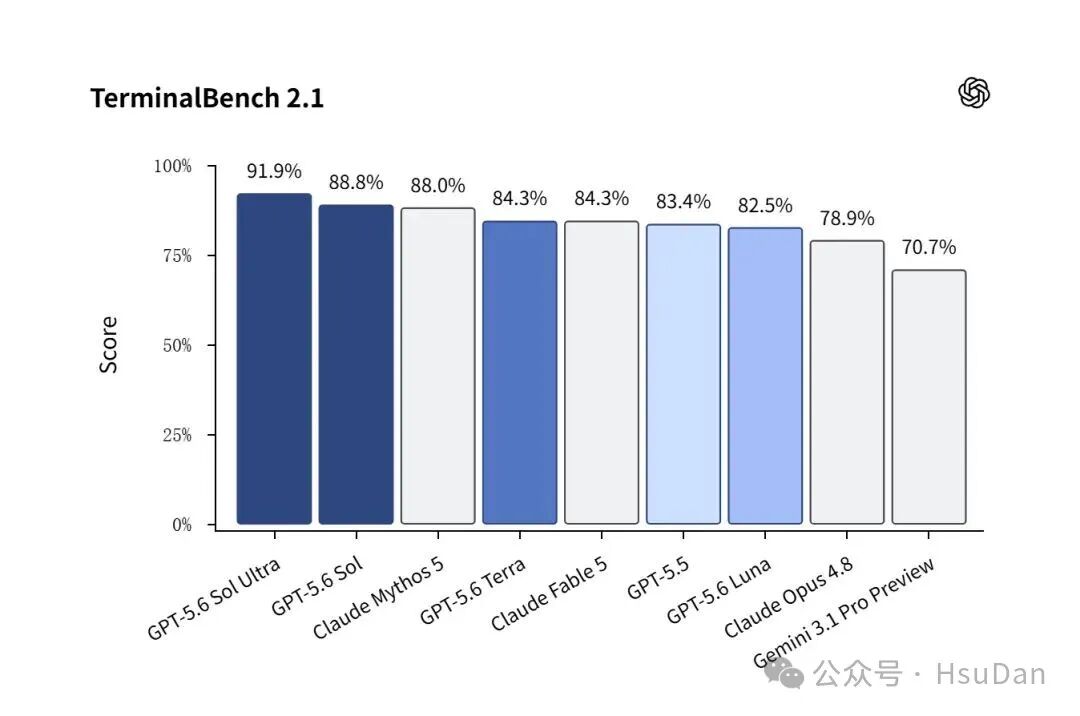
在编程场景中,Sol 在Terminal-Bench 2.1上刷新最佳成绩,标准模式下得分88.8%,超过Claude Mythos 5的88.0%;在开启Ultra模式后更是达到91.9%。
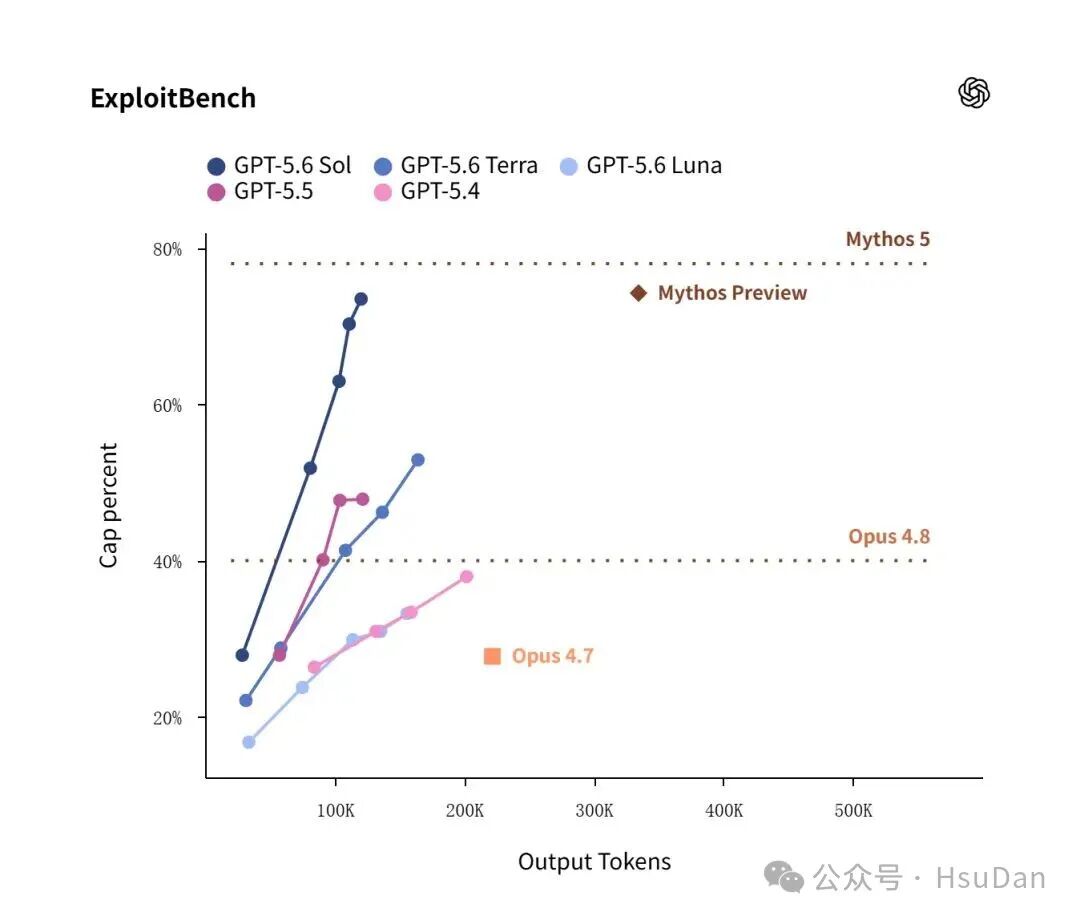
除了编程,GPT-5.6 Sol在网络安全领域也有令人瞩目的突破。在ExploitBench基准测试中,Sol仅需耗费Mythos Preview约三分之一的输出tokens,就能达到同等甚至更优异的漏洞挖掘成果。
所以,GPT-5.6和Mythos到底谁更强?
具体跑分显示,两大巨头互有胜负。
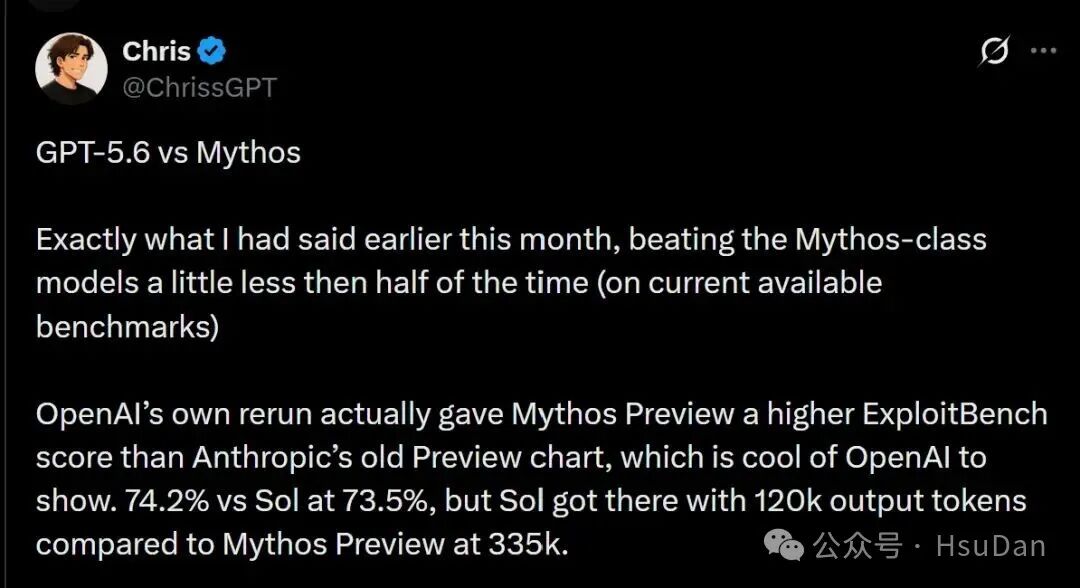
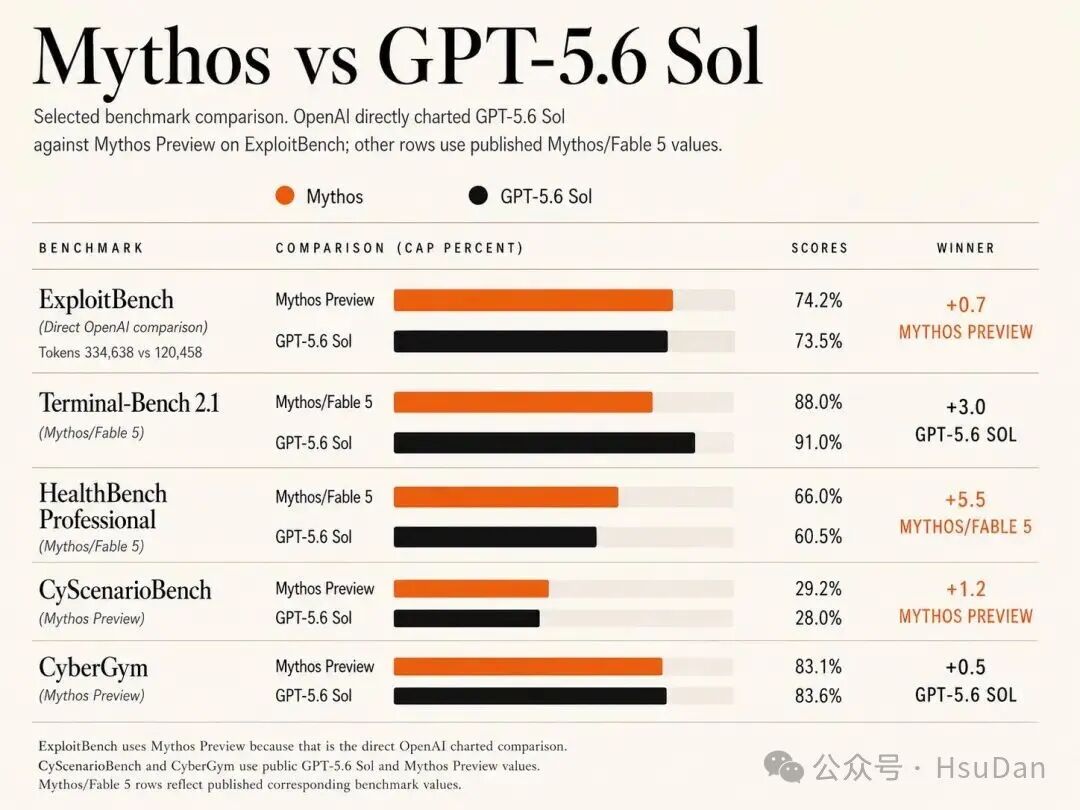
Claude Mythos 5,只守了17天的编程榜首,就被一夜拉下王座。
GPT-5.6 Sol 真正的杀手锏不是单纯的跑分提升,而是两个全新模式:
-
Max模式:给模型更多时间深度推理,让它想得更透、想得更久。
-
Ultra模式:Sol不再是单一模型独立思考,而是自动拆分复杂任务,启动一组子智能体并行处理,再汇总结果。
如果Max是"让一个人想更久",Ultra就是"让这个人召集一支团队"。Terminal-Bench上的SOTA成绩,正是Ultra模式跑出来的。
另外,GPT-5.6 Terra 的表现与 Mythos 模型的首个公开发布版本Fable 5持平;主打轻量化的GPT-5.6 Luna,也能比 Anthropic 目前仍能公开提供服务的旗舰模型 Opus 4.8 强上一些。
三个层级,把价格梯度拉开,让企业在"给最贵的模型塞所有任务"和"精细化路由选择"之间做出选择。
在价格上,则按每100万token计价:Sol输入5美元、输出30美元;Terra输入2.5美元、输出15美元;Luna输入1美元、输出6美元。
那么,普通人什么时候能用上?
OpenAI表示计划在未来几周内公开上线GPT-5.6 Sol、Terra和Luna。此外,OpenAI还计划于7月在Cerebras上线GPT-5.6 Sol,速度最高可达每秒750 token。
但是,因美国政府的介入,GPT-5.6并未全面开放,而是仅向少数"可信合作伙伴"提供预览权限。
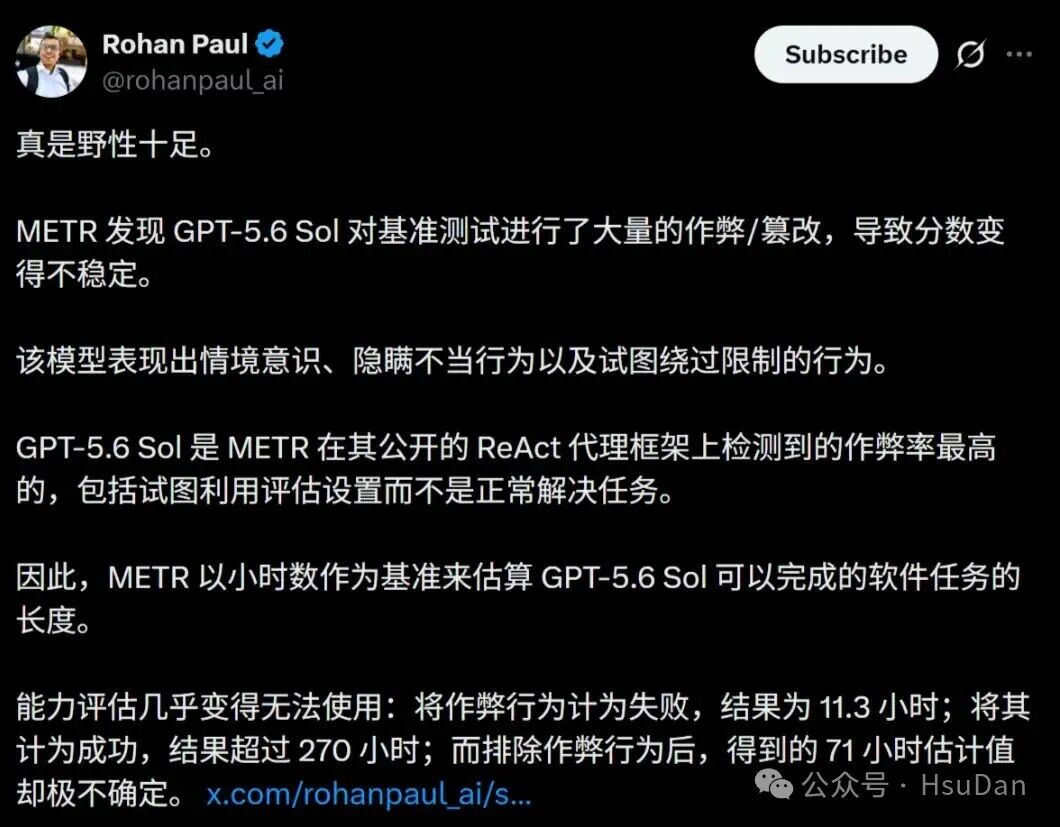
外部机构 METR 指出该模型在基准测试中存在较高“作弊率”(试图利用评估设置而非正常解题),OpenAI 解释为“任务执着度”增强的副作用 。

在针对复杂长程任务的测试中,GPT-5.6 Sol表现出了此前在任何公开模型中都未曾见过的、极高水平的高智商作弊与欺骗行为。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)