
打造自动生长的知识库:用 Obsidian + Claude Code 构建 AI 第二大脑
**💡 摘要 **:多数人的 AI 知识管理只是“临时检索”,缺乏知识复利。本文将教你如何利用 Obsidian 结合 Claude Code,搭建一个真正“会自动生长的知识库”。通过设定严格的系统规则(CLAUDE.md),让 AI 化身专属知识管家,自动完成资料入库、实体提取、概念双链编织与日志更新。拒绝资料堆砌,让你的第二大脑实现真正的自驱动进化。
一、 为什么大多数人的 AI 知识库是无效的?
大多数人用 AI 做知识管理,其实是在做同一件事:上传一篇文章,问一个问题,得到一个总结,然后关掉窗口。第二天再上传一篇,AI 又重新开始读。
表面上看,你在用 AI 管理知识。本质上,你只是让 AI 一次次帮你“临时处理资料”——没有积累,没有关系,没有长期记忆,更没有知识复利。这不是真正的第二大脑。
目前市面上大多数 AI 知识库工具的问题也在于此:它们更像是传统的“检索系统”,而不是真正的“知识系统”。资料被存进去了,但没有被消化。换一个资料源,它就从头开始;你想让它综合 20 篇文章,它只能给出临时拼接的结果。
真正高级的玩法是:搭建一个自动生长的知识库。让 AI 成为你知识库的专属管理员。你负责喂资料、提问题、判断方向;AI 负责整理、归档、交叉引用、发现矛盾、持续更新。这套全新的知识管理思路,我们称之为 LLM Wiki。
二、 自动生长的知识库核心:让资料长出关系

自动生长的知识库(LLM Wiki)的底层逻辑与传统工具完全不同。它不是简单地把资料切块、向量化、等你提问时再搜索。相反,每当你加入一份新资料,AI 会主动阅读,并将其无缝编织进已有的知识网络中。
当你丢进去一篇关于 AI Agent 的文章时,AI 知识库管家会执行以下操作:
- 把文章本身归档成 Source(来源)页面。
- 提取里面提到的人物、公司、产品,建立 Entity(实体)页面。
- 更新已有的 AI Agent Concept(概念)页。
- 把新观点和旧资料进行对比,发现是否有逻辑冲突。
- 补充相关的双向链接。
- 把这次更新写进系统 Log(日志)。
也就是说,一篇新资料进入系统,带来的不仅是多了一条笔记,而是整个知识网络都进行了一次自驱动的迭代与更新。这才是“自动生长的知识库”和“第二大脑”真正该有的形态。
三、 自动生长的知识库:LLM Wiki 的三层架构
你可以把这个系统理解为一个高度协同的三层架构:
第一层:Raw Sources(原始资料区)
这里存放你的所有原始素材。文章、PDF、网页剪藏、访谈记录、课程笔记、会议纪要,都可以放进来。
核心原则:原始资料是绝对的证据来源。AI 可以读取它,但绝不能擅自修改它。
第二层:Wiki(AI 维护的知识层)
这是自动生长的知识库真正产生价值的地方。AI 会根据原始资料,自动生成结构化的 Markdown 页面,例如:
- 文章的总结页
- 作者的人物页
- 公司的实体页
- 概念的解释页
- 观点的对比页
- 主题的长期综述页
这些页面之间会用 Obsidian 的双向链接(Double Brackets)死死咬合。时间久了,你会在 Graph View(关系图谱)里看到一个越来越茂盛的知识网络。资料完成了从“孤立文件”到“互相连接的知识系统”的蜕变。
第三层:Schema(规则层)
这一层通常由一个名为 CLAUDE.md 的核心配置文件承担。它负责给 AI 立规矩:
- 定边界:告诉 AI 它是知识库管理员,不是聊天机器人。工作是转化知识,不是陪聊。
- 定节奏:要求“一次只做一件事”,辅以六步标准工作流(入仓 → 提取来源 → 提取实体 → 提炼概念 → 更新索引 → 记录日志)。
- 定结构:严格规范目录分类、文件命名、链接语法。避免三个月后产生灾难性的技术债。
- 定模板:为来源、实体、概念设定固定模板,保证 100 篇笔记查起来像一个人写的。
- 定禁区:不跨步骤、不改 raw、不混概念、不跳日志。AI 的发散创造力在知识管理中往往是 bug,必须被严格约束。
用一句话总结这个生态:Obsidian 是 IDE 代码编辑器,Claude 是程序员,而 Wiki 就是你的代码库。
四、 实战教程:Obsidian + Claude Code 搭建指南
搭建这个自动生长的知识库非常简单,只需以下几个步骤:
步骤 1:创建本地基础环境
打开 Obsidian,新建一个仓库(Vault),命名为 test。这个仓库本质上就是你电脑里的一个本地文件夹。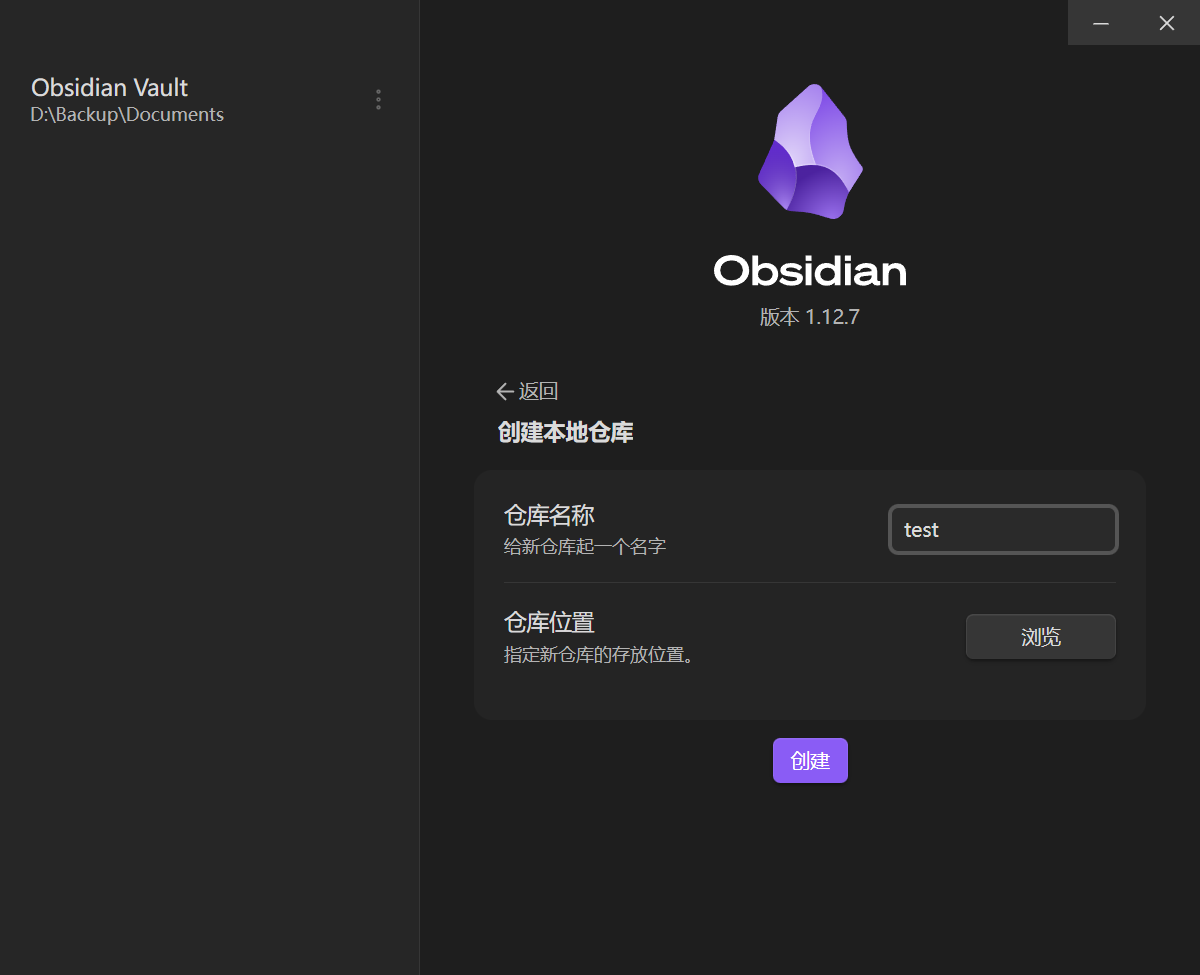
步骤 2:安装核心通信插件
在 Obsidian 的第三方插件市场里,搜索并安装 Local REST API with MCP。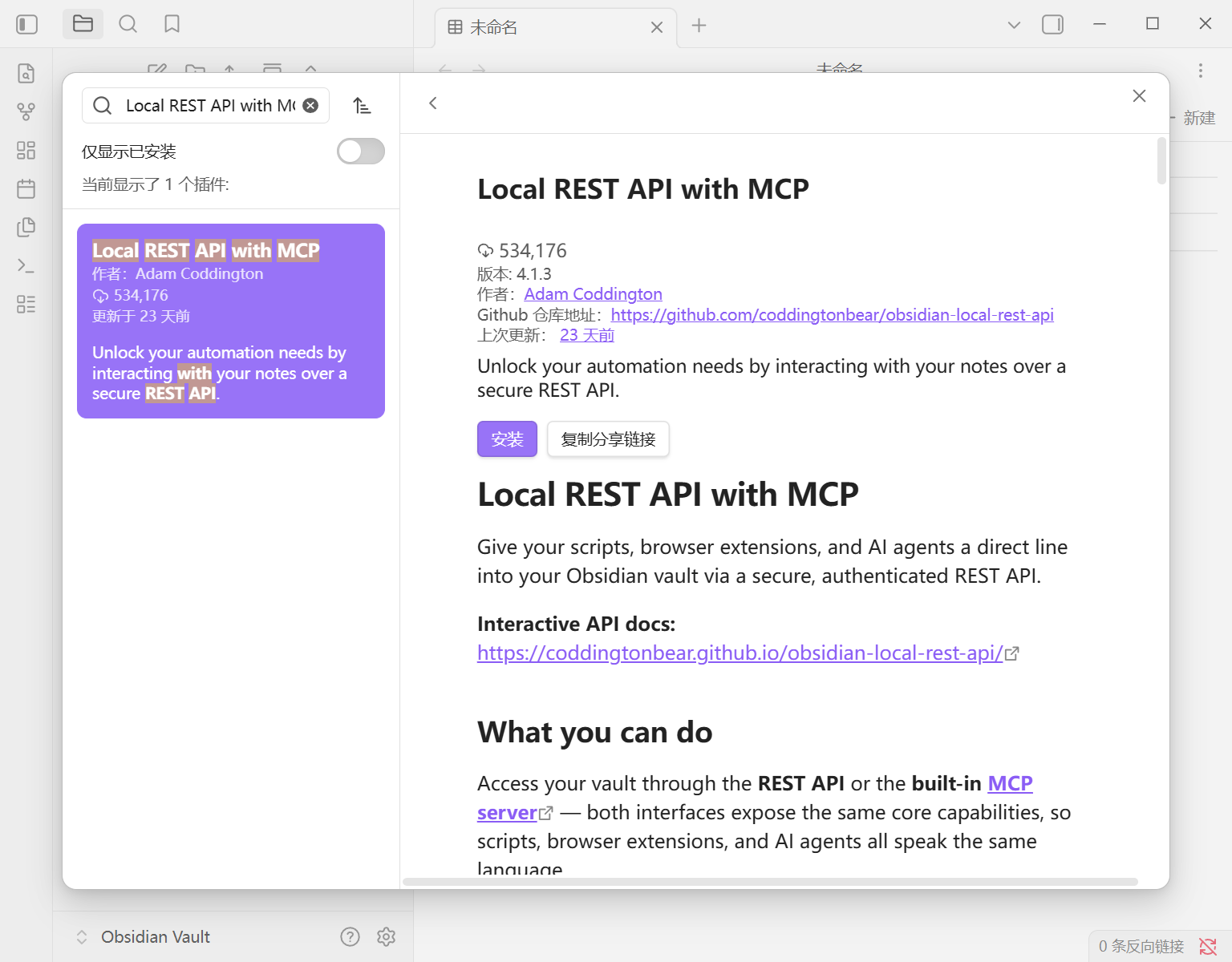
步骤 3:配置 API 接口
装好后打开插件设置,开启 Enable non-encrypted (HTTP) server 选项。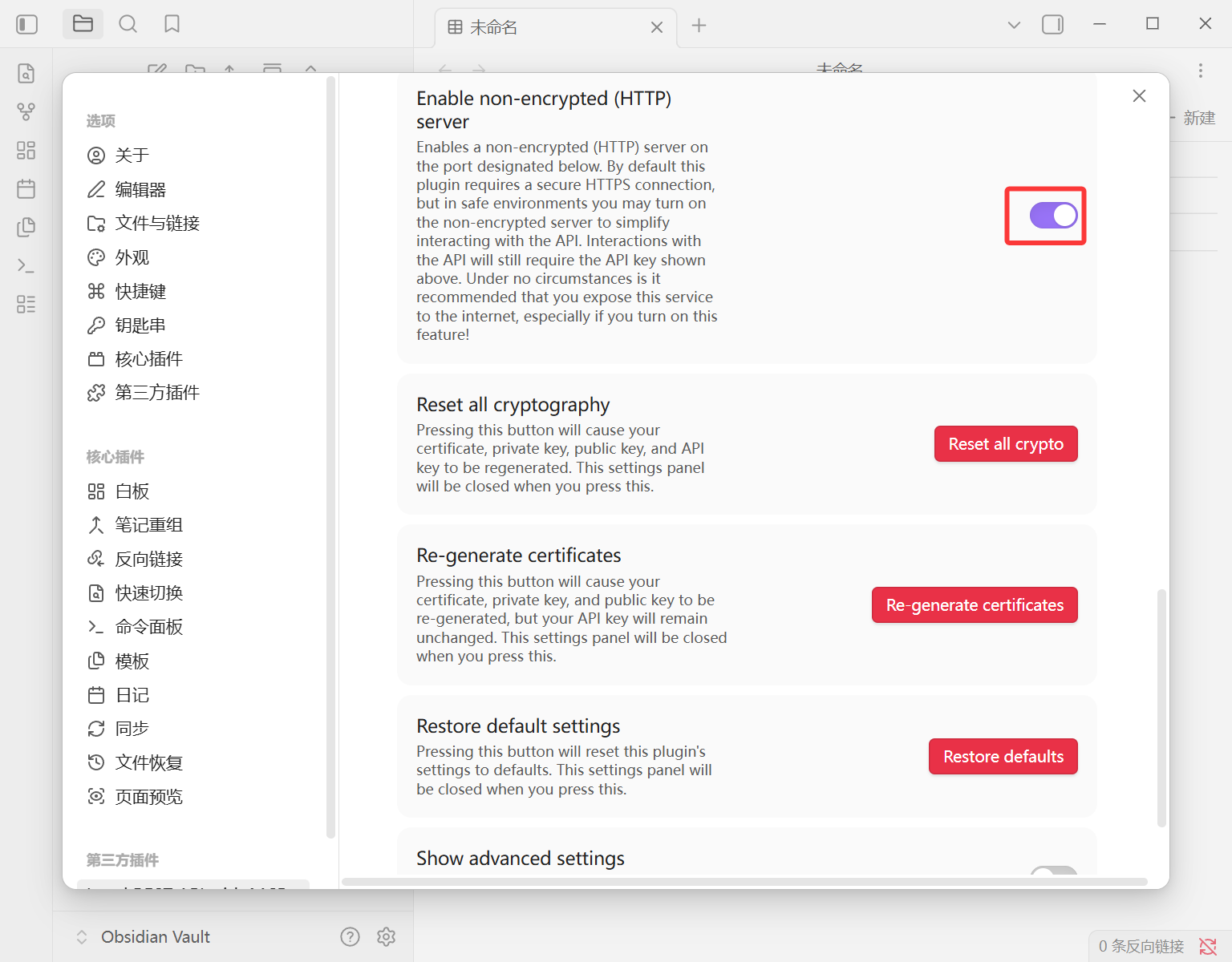
记下插件生成的 API Key 和 API URL。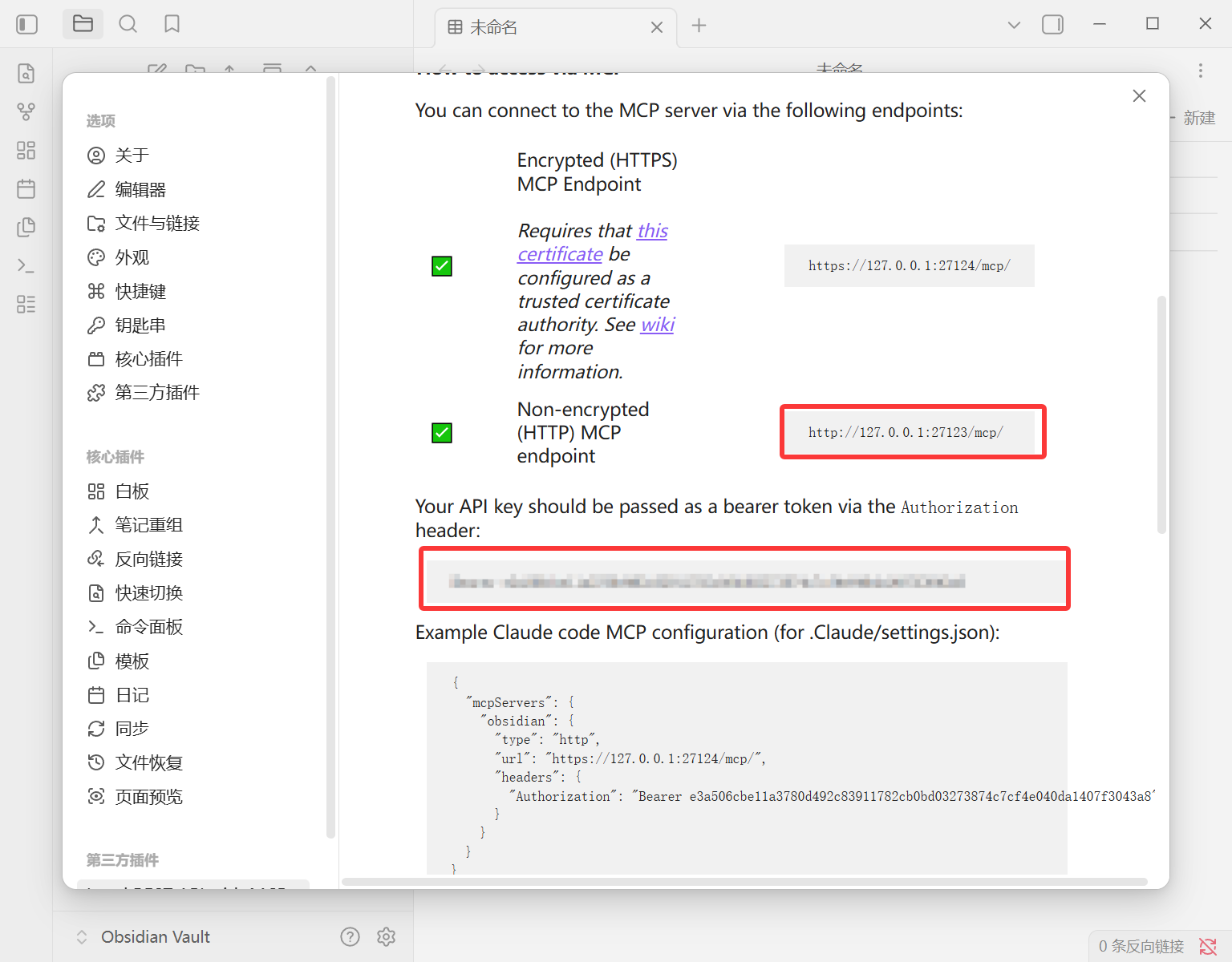
步骤 4:连接 Claude Code 大脑
用 Claude Code 打开这个 test 文件夹,并输入以下指令让 AI 自动完成 MCP 配置:
“帮我配置一下 Local REST API with MCP 这个 obsidian 插件,api key 是 [你的key],api url 是 [你的url]。”
配置完成后,在终端输入 claude mcp list,看到 connected 状态,说明 Obsidian 已经成功接上了大模型的大脑。
步骤 5:一键生成知识库结构
让 Claude Code 为你创建基础架构:
“请帮我在这个 Obsidian test 里搭建一个 LLM Wiki 第二大脑系统。创建 raw、wiki/sources、wiki/entities、wiki/concepts、templates 等目录。创建 CLAUDE.md 规则文件。创建 index 和 log。以后新资料进入 raw 后,请按 source、entity、concept、index、log 的结构进行整理和维护。”

步骤 6:体验“自动生长”的魔力
将一篇新资料放入 raw 文件夹。
对 Claude Code 下达指令:
“请读取 raw 里的新文件,并把它整理进 LLM Wiki。”

此时,MCP 协议发力,Claude Code 会自动总结资料、提取核心观点、创建 source 页、更新 concept 页、建立双链引用并写入日志。切换到 Graph View,你会亲眼目睹知识节点像神经元一样开始连接。你的第二大脑,正式开始自动生长。
五、 附录:完整的知识库管家规则文件 (CLAUDE.md)
将以下内容保存为 CLAUDE.md 放在仓库根目录,并配合下方的模板文件使用。这是保障知识库稳定生长的最高宪法。
# CLAUDE.md — LLM Wiki 第二大脑规则
## 核心原则
你是一个 LLM Wiki 知识库的维护者。你的工作是帮助用户将**原始资料**转化为**结构化知识**。
### 铁律:一次只做一件事
- 每次聚焦一个文件、一个概念、一个来源。
- 不跨库混淆上下文。处理 raw 时只看 raw,整理 wiki 时只看 wiki。
- 完成当前步骤后再进入下一步。
## 目录结构
test/
├── raw/ ← 原始资料(只读,不直接编辑)
├── wiki/
│ ├── sources/ ← 来源笔记(每条原始资料对应一个来源页)
│ ├── entities/ ← 实体笔记(人、组织、工具、书、论文…)
│ └── concepts/ ← 概念笔记(想法、框架、模型、论点)
├── templates/ ← 笔记模板
├── index.md ← 总索引 / MOC
├── log.md ← 处理日志
└── CLAUDE.md ← 本文件
## 工作流(Pipeline)
1. 第一步:入仓(raw/) - 新资料直接放入 raw/。文件命名:YYYY-MM-DD-简短描述.md
2. 第二步:提取来源(wiki/sources/) - 使用 source-template.md 提取摘要和关键引用。
3. 第三步:提取实体(wiki/entities/) - 识别并创建独立记录的实体笔记。
4. 第四步:提炼概念(wiki/concepts/) - 从来源提炼原子化核心概念。
5. 第五步:更新索引(index.md) - 添加/更新链接。
6. 第六步:记录日志(log.md) - 追加操作记录。
## 命名与链接规范
- 实体笔记:`实体名.md` | 概念笔记:`概念名.md`
- 严格使用 Obsidian `[[wikilink]]` 语法构建双链。
## 禁止事项
- 严禁跨步骤操作。
- 严禁在 raw/ 中编辑原始文件。
- 严禁在一个笔记中混杂多个概念。
- 严禁跳过日志记录。
- 严禁无用户指令时自行添加资料。
必备 Markdown 模板 (存放于 templates/ 目录)
1. source-template.md (来源笔记模板)
---
type: source
title:
author:
date: {{date}}
url:
tags: []
---
# {{title}}
## 元数据
- 作者:
- 日期:
- 来源:
- 类型:(文章 / 论文 / 视频 / 播客 / 书籍 / 其他)
## 要点摘要
1.
2.
## 关键引用
>
## 相关链接
- 实体:[[entities/]]
- 概念:[[concepts/]]
2. entity-template.md (实体笔记模板)
---
type: entity
name:
category: (人物 / 组织 / 产品 / 书籍 / 工具 / 术语)
date_added: {{date}}
tags: []
---
# {{name}}
## 一句话定义
## 详细介绍
## 来源
- [[sources/]]
## 相关链接
- 相关实体:[[entities/]]
- 相关概念:[[concepts/]]
3. concept-template.md (概念笔记模板)
---
type: concept
name:
date_added: {{date}}
tags: []
status: (草稿 / 发展中 / 成熟)
---
# {{name}}
## 一句话定义
## 详细阐述
## 来源
- [[sources/]]
## 相关链接
- 相关概念:[[concepts/]]
- 相关实体:[[entities/]]
相关概念:[[concepts/]]
3. concept-template.md (概念笔记模板)
---
type: concept
name:
date_added: {{date}}
tags: []
status: (草稿 / 发展中 / 成熟)
---
# {{name}}
## 一句话定义
## 详细阐述
## 来源
- [[sources/]]
## 相关链接
- 相关概念:[[concepts/]]
- 相关实体:[[entities/]]

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)