
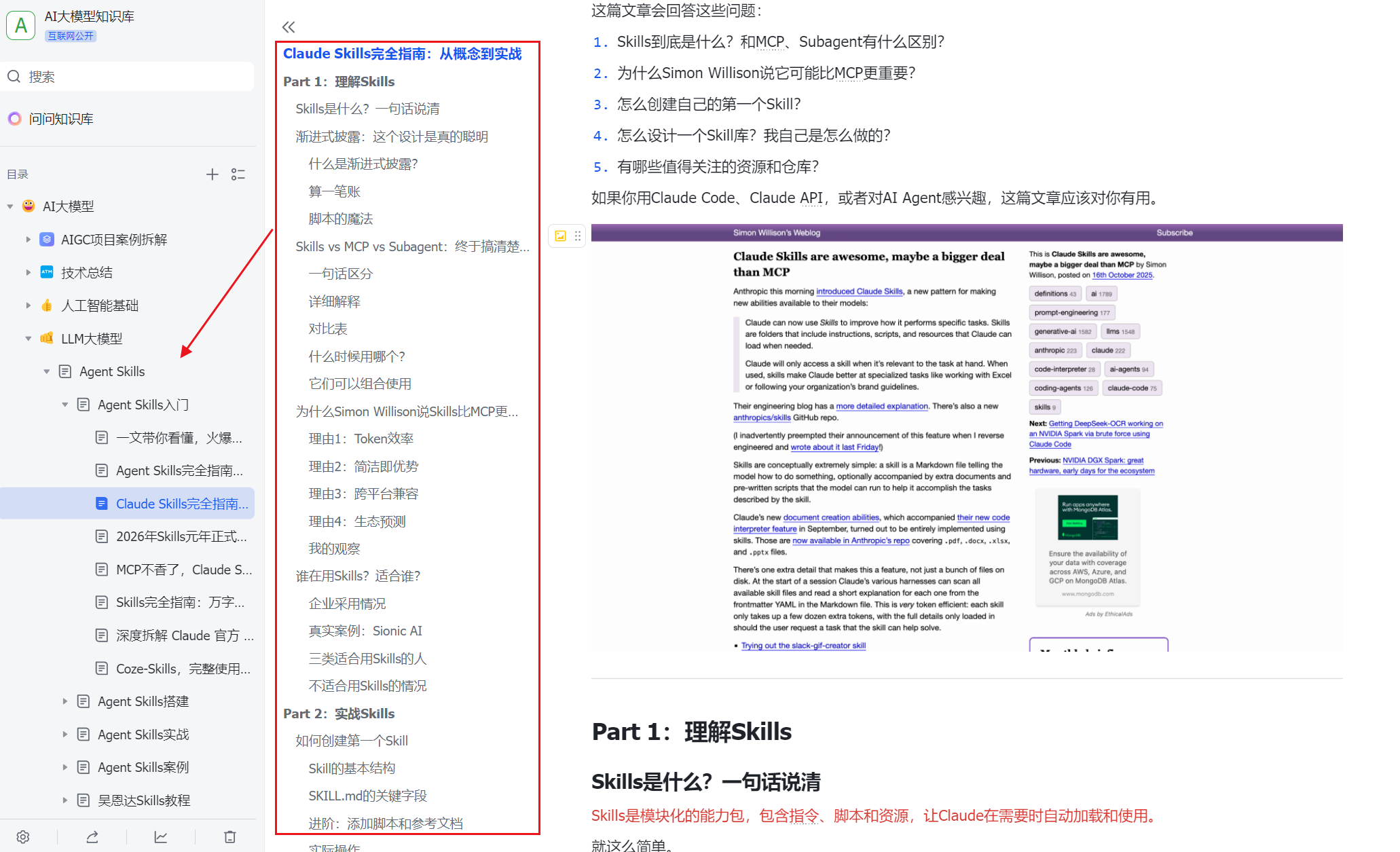
Codex 实战:工程实践里的常见坑
这篇我按“先跑起来、再讲取舍”的方式写《Codex 实战:工程实践里的常见坑》。概念会讲,但重点放在代码怎么组织、哪里容易踩坑。
摘要
本文概述文章目标、核心观点和实践价值。
之前有个做后端架构的朋友问我:“既然 OpenAI 出了 Codex CLI,是不是以后写代码就能全自动了?”我直接给他泼了盆冷水:别把工具当保姆,它更像是个手速极快但偶尔会脑补过度的初级实习生。
最近我在几个内部项目中深度集成了 Codex,从最初的“哇塞真神”到后来的“这写的什么鬼”,再到现在的“知道怎么让它闭嘴干活”,踩了不少坑。今天不聊虚的,专门聊聊在真实企业级项目中,如何把 Codex 接进 CI/CD 或者日常开发流,以及那些面试时能帮你加分、实际开发中能让你少掉头发的心得。
目录
- Codex 的定位:不是替代,是增强
- 项目上下文理解:喂给它的“说明书”
- Tech Stack
- Naming Conventions
- Critical Rules
- 代码修改流程:增量而非全量
- 测试与验证:AI 的软肋与强项
- 团队使用建议:标准化与边界
- 总结:如何把这段经历写进简历?
Codex 的定位:不是替代,是增强
很多团队引入 AI 编码助手失败的原因,是一开始就指望它重构遗留代码(Legacy Code)。我的经验是:Codex 最适合处理的是“样板代码”、“测试用例”和“小功能模块”。
在面试或项目复盘中,如果你说“我用 Codex 重写了整个微服务网关”,面试官通常会觉得你在吹牛或者对风险缺乏认知。更诚实且专业的说法是:“我利用 Codex 快速生成了网关的健康检查接口和单元测试,将重复性劳动时间减少了 60%。”
核心观点: 把它当作你的 Pair Programmer(结对程序员),而不是 Author(作者)。你负责设计、审查和集成,它负责填充细节。
项目上下文理解:喂给它的“说明书”
Codex 最大的痛点在于“不知道上下文”。你打开终端敲 codex generate,它不知道你是 Spring Boot 还是 Go Gin,更不知道你们团队内部的命名规范。
坑点 1:默认配置过于简陋
如果不指定上下文,它会用通用的 Python 或 JS 风格去解释 Java 代码,生成的变量名可能是 tempData 这种毫无意义的东西。
解决思路:建立 `.codexignore` 和 `context.txt`
我在项目中强制要求创建一个 CONTEXT.md 文件,放在项目根目录。这个文件不是给人类看的,是给 AI 看的。
# Project Context for AI Coding Assistant
## Tech Stack
- Backend: Java 17 + Spring Boot 3.x
- Database: PostgreSQL 15
- ORM: JPA with QueryDSL
- Testing: JUnit 5 + Mockito
## Naming Conventions
- Entities: PascalCase (e.g., UserAccount)
- Repositories: Interface name ending in 'Repository'
- Services: Interface name ending in 'Service', Impl ending in 'ServiceImpl'

## Critical Rules
- NEVER use raw SQL unless absolutely necessary.
- Always include `@Transactional(readOnly = true)` on GET operations.
- Error handling must use global exception handler `GlobalExceptionHandler`.在实战中,我会这样调用:codex --context CONTEXT.md generate service UserAccountService
这样生成的代码,80% 可以直接通过编译,剩下的 20% 你需要做的是修正逻辑错误,而不是重写风格。
代码修改流程:增量而非全量
很多初学者喜欢让 AI “优化整个 Controller”。这是大忌。代码量大时,注意力机制分散,AI 容易 hallucinate(幻觉),把别的文件的逻辑混进来,或者删掉关键的鉴权代码。
推荐做法:原子化指令
1. 明确输入输出:告诉它具体的 Method Signature。
2. 限制范围:指定只修改某个特定的 Service 方法。
3. 提供示例:如果业务逻辑复杂,给它一个类似的旧代码片段作为 Few-Shot Prompt。
实战案例:
我要加一个“批量导入用户”的功能。
❌ 错误指令:“帮我写一个批量导入用户的接口。”
✅ 正确指令:“参考现有的 SingleUserImportService.java,在 BatchUserImportService.java 中新增 importUsers 方法。要求:使用 @Async 异步处理,结果写入 ImportResultLog 表。注意事务回滚策略。”
测试与验证:AI 的软肋与强项
这里有一个巨大的误区:认为 AI 生成的单元测试就是可信的。
实际上,Codex 非常擅长生成“Happy Path”(快乐路径)的测试,但对于边界条件、异常分支、并发竞争,它往往覆盖不足。
我的验证策略
1. 先生成测试,再写代码:有时我会反过来,让 Codex 根据需求描述生成测试用例,然后我再写实现代码去通过测试。这能倒逼需求清晰化。
2. 人工审查 Mock 逻辑:AI 生成的 Mockito when(...).thenReturn(...) 经常过于理想化。我会手动检查是否覆盖了 throw new RuntimeException() 的情况。
3. 覆盖率指标:在团队 CI 流水线中,我设定了一个规则:AI 生成的代码必须伴随新的测试文件,否则合并请求(MR)自动驳回。
团队使用建议:标准化与边界
如果你是 Tech Lead,不要禁止员工用 AI,而是要规范它。
1. 代码审查(Code Review)的红线:
- 任何由 AI 生成的复杂业务逻辑,必须在 PR 描述中标注 AI-Assisted。
- 审查者必须逐行阅读,特别是涉及权限控制、数据敏感性的部分。
2. 避免隐私泄露:
- 严禁将生产环境的真实数据、API Key、数据库密码粘贴到 prompt 中。
- 建议使用脱敏后的数据样例。我在项目中编写了一个简单的脚本,在调用 Codex 前自动替换环境变量中的敏感字符串。
3. 统一 Prompt 模板:
团队内部共享一套 Prompt 模板库。例如:
`text
[Role] Senior Java Developer
[Task] Refactor method X to improve performance
[Constraints] Keep API signature unchanged, add logging
[Output] Only code blocks, no markdown explanations
`
总结:如何把这段经历写进简历?
回到最开始提到的“面试表达”。当面试官问:“你如何评估 AI 编码工具的价值?”
你可以这样回答:
> “在我的上一个电商库存服务项目中,我主导引入了 Codex 辅助开发。起初我们尝试用它自动生成所有 CRUD,结果发现维护成本过高。后来我调整了策略,建立了基于 CONTEXT.md 的上下文管理机制,并将 AI 定位为‘测试用例生成器’和‘样板代码加速器’。
>
> 成果上:我们将单元测试的覆盖率从 45% 提升到了 78%,且开发重复性接口的时间缩短了 30%。
> 反思上:我也意识到 AI 在处理复杂分布式事务时的局限性,因此我们在 CI 流程中增加了人工审查节点,确保关键链路的安全。这段经历让我明白,AI 不是银弹,而是杠杆,关键在于如何使用。”
这种回答,既有技术深度,又有工程思维,还有真实的数据支撑,远比说“我用 AI 写了个 Hello World”要有力得多。
最后,记住一点:代码的质量,永远取决于你对业务的理解,而不是 AI 的能力。 AI 只是把你的思考速度加快了十倍,但方向错了,跑得越快死得越惨。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。

如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)