
【晓天衡宇评测社区】大语言模型6月榜单发布:Claude Fable 5领跑,国产模型进入密集竞争区!

 晓天衡宇评测社区持续关注大模型的发展动态,近期针对国内外主流大语言模型进行了全面评测。
晓天衡宇评测社区持续关注大模型的发展动态,近期针对国内外主流大语言模型进行了全面评测。
榜单从智能体、代码、通用、推理四个维度,并基于20+主流评测基准,对国内外主流大语言模型进行了全面评测,现公布晓天衡宇大语言模型6月评测榜单。
本文基于Top 10评测结果进行解读,完整26个模型的全量排名和维度得分,欢迎访问晓天衡宇评测社区进行查看。


欢迎点击👉🏻晓天衡宇评测社区查看完整榜单

结论1:Claude Fable 5问鼎,海外闭源模型占据头部优势
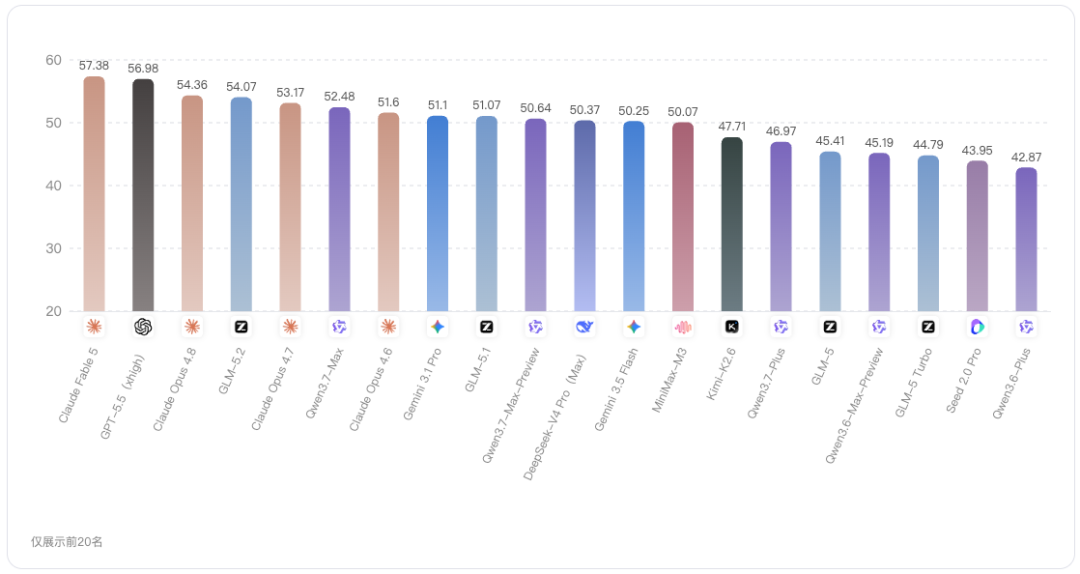
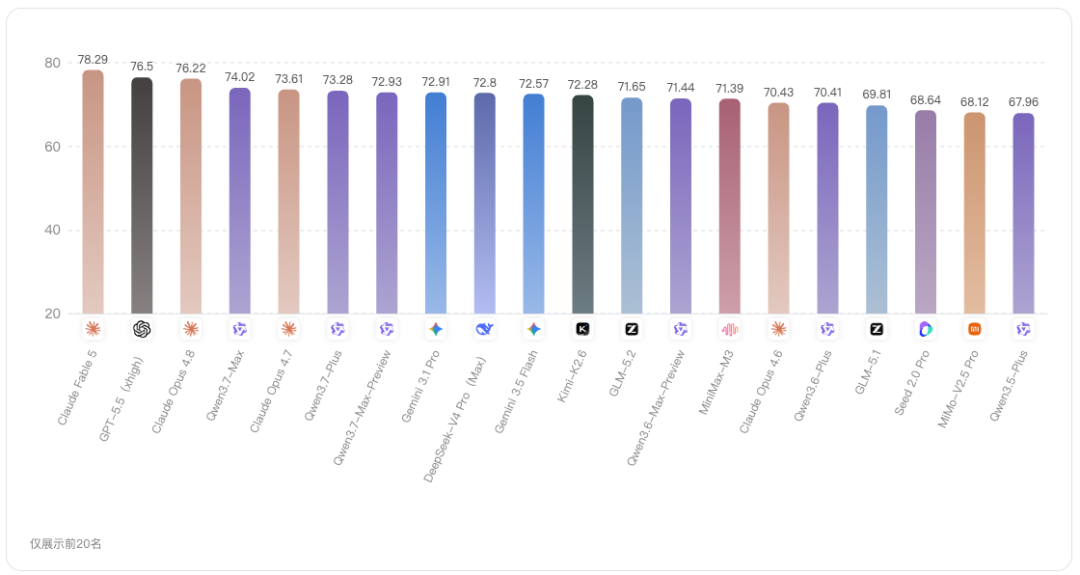
本期榜单中,Claude Fable 5以70.72分位列第一,是本次评测中唯一总分超过70分的模型,综合领先优势较明显。
从Top 3模型看,Claude Fable 5、GPT-5.5(xhigh)、Claude Opus 4.8均为海外闭源模型,说明在本次评测集下,头部综合能力仍主要由海外闭源模型占据。
不过,第二名的GPT-5.5(xhigh)得到68.35分,第三名Claude Opus 4.8得分67.39分,两者分差不足1分,更适合看作同一头部梯队内的同水平竞争。
结论2:推理成为当前最强维度,智能体仍是全场共性短板
从四大能力维度看,推理以70.49分的行业均分领跑,其次是代码(67.68分)、通用(64.35分),智能体均分仅46.92分,是本次评测中表现最低的维度,没有模型在智能体维度突破60分,即便是榜首Claude Fable 5,智能体得分也只有57.38分。
由此可见,当前模型距离稳定完成复杂任务拆解、多步执行、工具调用和长期任务闭环仍有较大提升空间。
结论3:中游模型进入密集竞争区,国产模型差距正在收窄,但具体能力项存在差异
本期榜单第5至第10名总分分差仅2.04分,说明中游区间竞争非常激烈。在这个区间内涵盖多款国产模型,也包括部分海外模型,单纯用排名先后判断强弱已经不够准确。
以Top 10中的GLM-5.2、Qwen3.7-Max和Gemini 3.1 Pro为例,三者总分分别为64.53、64.32和64.18,最大分差只有0.35分,基本属于同一竞争梯队,但三者能力特点并不相同:GLM-5.2的智能体相对更高,Qwen3.7-Max的推理更突出,Gemini 3.1 Pro的通用更有优势。
因此,中游模型的关键看点不是“谁高0.1分”,而是不同模型在具体能力项上的差异。

评测维度
本榜单基于智能体、代码、通用、推理四个维度进行综合评估,基于加权分数计算模型的平均得分进行排序。
其中, 智能体占比最高,为35%,代码与推理各占25%,通用占15%,本期榜单并不只是看模型会不会答题,而是更强调模型在复杂任务执行、代码能力、通用能力和推理表现上的综合能力。
维度一:智能体(权重35%)
-
知识库智能体交互能力:考察模型与知识库进行多轮交互、准确检索并整合信息的能力。
-
网页浏览与信息检索能力:考察模型在中文网页环境中浏览、定位和提取目标信息的能力。
-
搜索增强推理能力:考察模型结合搜索结果进行深度推理和复杂问答的能力。
-
动态规划能力:考察模型在购物等动态场景中进行多步骤规划与决策的能力。
维度二:代码编程(权重25%)
-
多语言软件工程能力:考察模型在多种编程语言下完成软件工程任务的能力。
-
终端任务代码能力:考察模型在终端环境中执行代码任务的能力。
-
竞赛编程能力:考察模型解决竞赛级编程题目的能力。
-
自主代理端到端代码能力:考察模型作为自主代理完成端到端编码任务的能力。
-
科学计算编程能力:考察模型进行科学计算和数值编程的能力。
维度三:通用(权重15%)
-
知识:考察模型在广泛知识领域的准确性。
-
指令遵循:考察模型精确遵循复杂指令的能力。
-
幻觉:考察模型抵抗幻觉、避免生成虚假信息的能力。
-
长上下文:考察模型在长上下文条件下的信息检索与理解能力。
-
记忆:考察模型在多轮对话中的长期记忆保持能力。
维度四:推理(权重25%)
-
科学推理:考察模型在研究生难度科学问题上的推理能力。
-
数学推理:考察模型在高难度数学竞赛题目中的推理和解题能力。
-
逻辑推理:考察模型在形式逻辑、语言理解和规划类推理任务中的表现。
-
场景推理:考察模型在真实世界场景中进行推理和规划的能力。
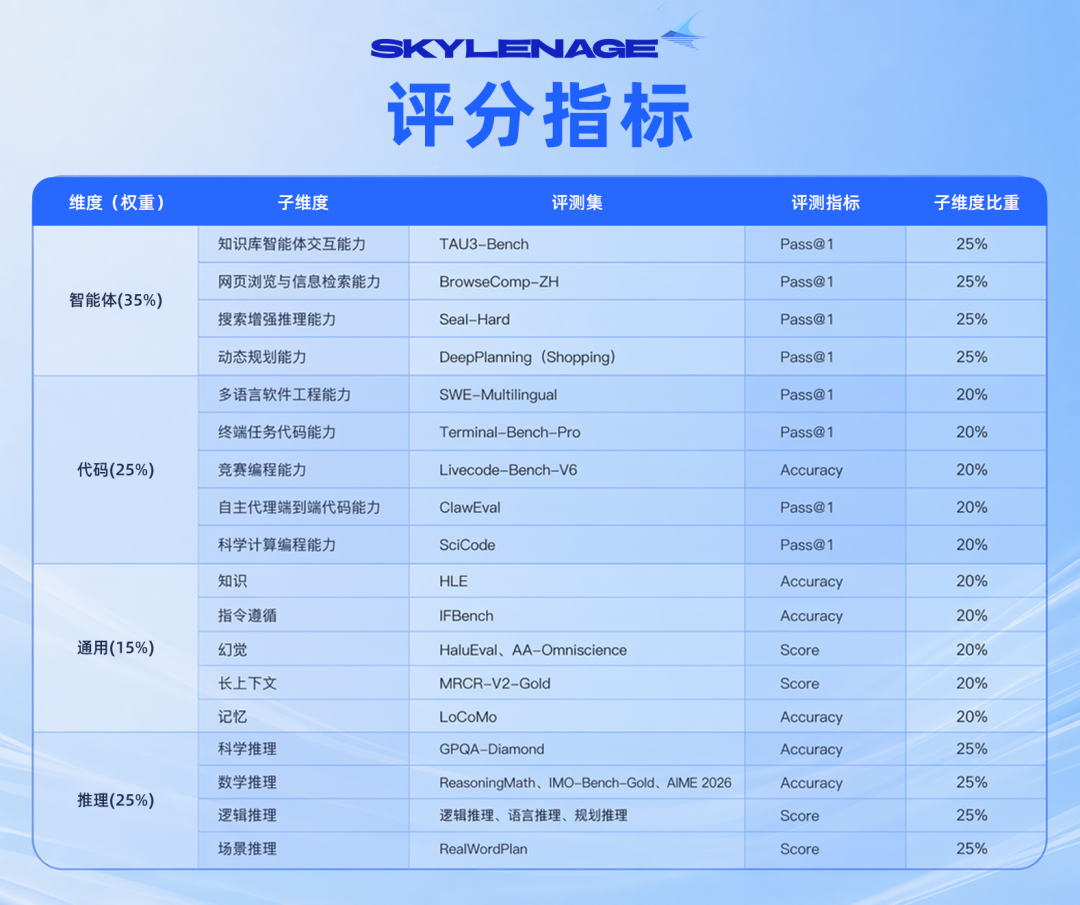
评分指标一览表,并附有对应具体的评测集
评分方法
本次6月大语言榜单统一采用客观评分,无需主观打分,不使用ELO对战打分,且每次评估、任何打分均可一比一复现。
具体的评分方式分为三种,分别是:
-
Pass@1:模型一次生成即通过的比例,适用于代码任务和智能体任务。
-
Accuracy:回答准确率,适用于知识问答和推理类任务。
-
Score:综合评分,适用于需要多维度评判的主观类任务。

整体来看,本期榜单呈现出一个清晰趋势:推理和代码已经成为头部模型竞争的强项,通用仍能体现模型之间的基础能力差异,而智能体则是当前所有模型共同需要突破的关键短板。
-
智能体(Agentic)
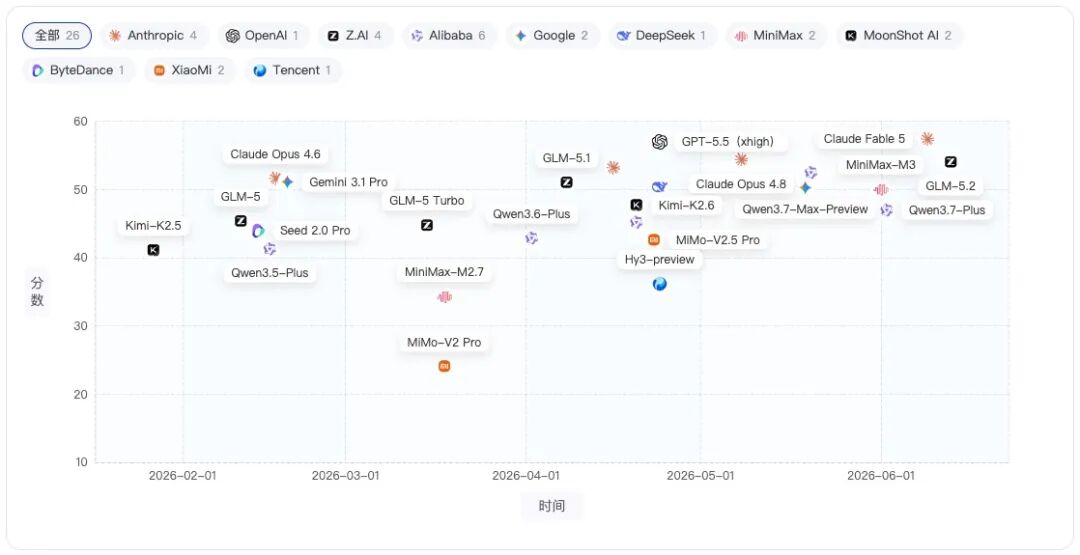
智能体维度趋势图
智能体是本次评测中均分最低的维度,行业均分仅46.92分,即便是总榜第一的Claude Fable 5,智能体得分也只有57.38分;第二名GPT-5.5(xhigh)为 56.98分,二者只差0.40分。
这说明,在智能体维度上,头部模型之间的差距并没有被明显拉开,相比代码、通用和推理,智能体更像是当前模型的共同薄弱项。
从Top 10看,智能体得分较高的模型包括:
-
Claude Fable 5:57.38
-
GPT-5.5(xhigh):56.98
-
Claude Opus 4.8:54.36
-
GLM-5.2:54.07
-
Claude Opus 4.7:53.17
值得注意的是,GLM-5.2虽然总分排名第5,但智能体得分达到54.07,接近 Claude Opus 4.8,并高于Qwen3.7-Max、Gemini 3.1 Pro等同分段模型,这说明在中游模型中,GLM-5.2的任务执行类能力有一定相对优势。
-
代码(Coding)
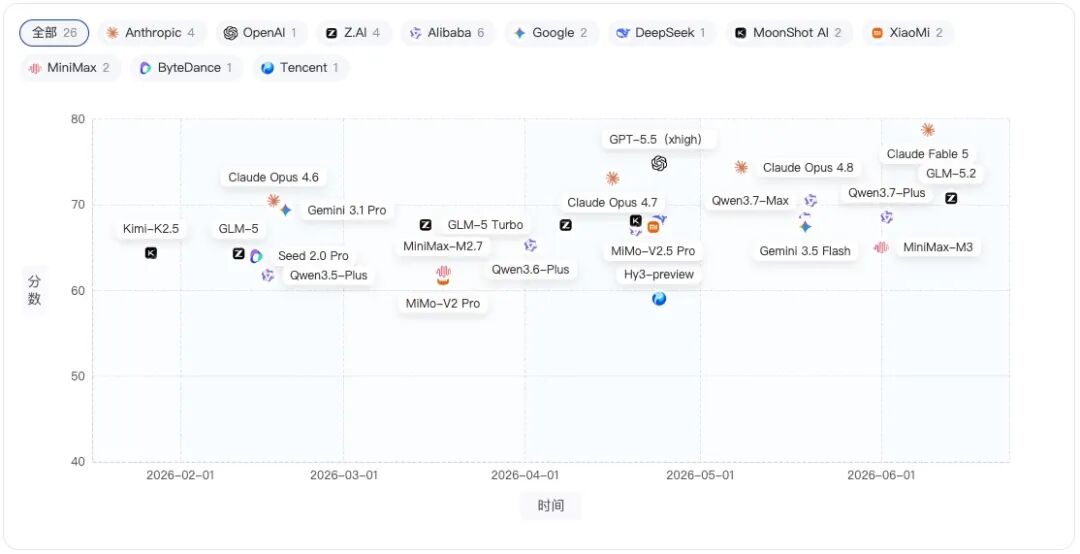
代码维度趋势图
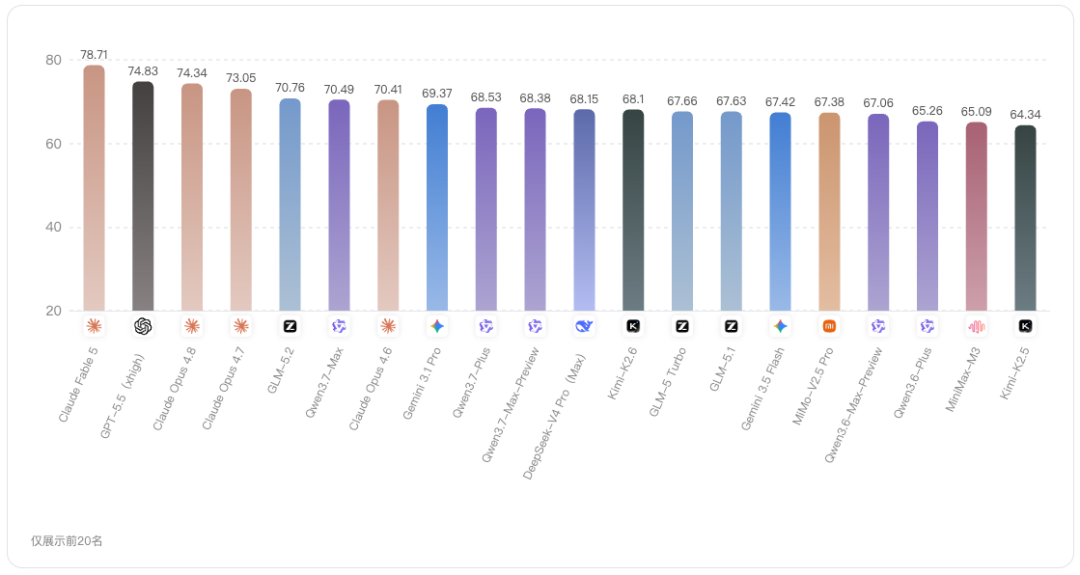
代码维度行业均分为67.68分,整体高于通用和智能体,说明代码能力已经成为当前大模型相对成熟的能力项之一。
在Top 10中,Claude Fable 5的代码得分为78.71分,是当前展示模型中的最高分;GPT-5.5(xhigh)为74.83分,Claude Opus 4.8为74.34分,两者非常接近;Claude Opus 4.7为73.05分,也处于较高水平。
从分差看,Claude Fable 5领先第二名GPT-5.5(xhigh)3.88分,领先 Claude Opus 4.8的分差是4.37分,这个差距比智能体维度更明显,说明 Claude Fable 5的总分优势,很大程度上来自代码这样高权重能力项的领先。
中游模型中,GLM-5.2、Qwen3.7-Max、Claude Opus 4.6的代码得分都在70分左右:
-
GLM-5.2:70.76
-
Qwen3.7-Max:70.49
-
Claude Opus 4.6:70.41
这说明在代码维度上,中游模型与头部模型之间存在差距,但并不是断层式落后,尤其是GLM-5.2与Qwen3.7-Max,在代码能力上已经接近70分线,具备一定竞争力。
-
通用(General)
通用维度趋势图
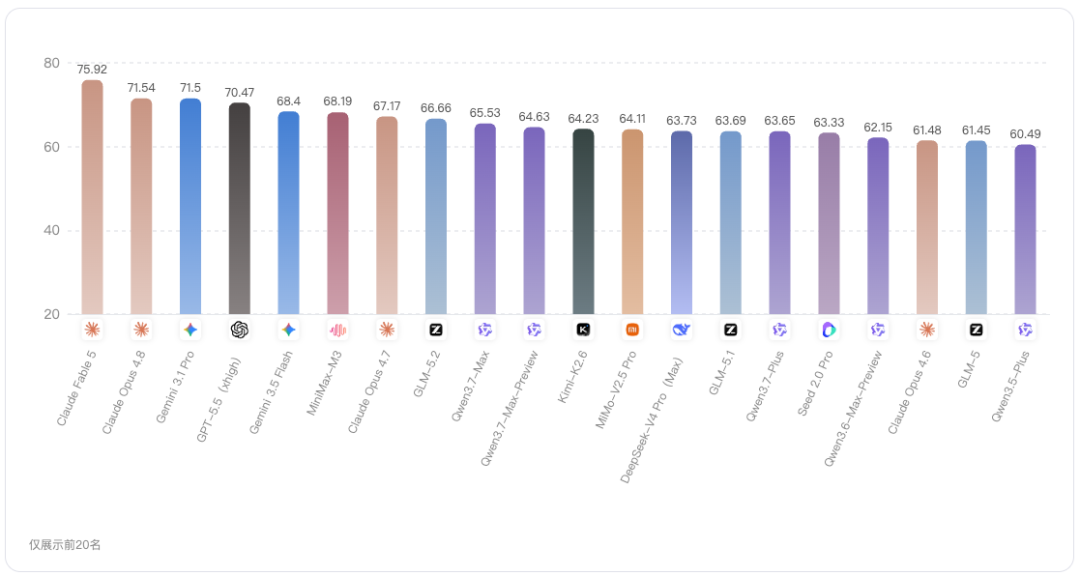
通用维度行业均分为64.35分,处于四个维度中的中间位置。这个维度更适合观察模型在通用理解、基础问答、综合表达等任务上的表现。
在 Top 10 中,Claude Fable 5的通用得分为75.92分,明显领先其他模型;第二梯队中,Claude Opus 4.8为71.54,Gemini 3.1 Pro为71.50,GPT-5.5(xhigh)为70.47。
这里有一个值得关注的点:Gemini 3.1 Pro虽然总分排名第7,但通用得分达到 71.50,几乎与Claude Opus 4.8的71.54持平,并高于GPT-5.5(xhigh)的70.47,这说明Gemini 3.1 Pro在通用能力项上有明显亮点,不能仅用总分排名来判断其价值。
相反,Claude Opus 4.6的通用得分为61.48,在Top 10中偏低,这也解释了为什么它虽然代码有70.41、推理有70.43,但总分仍位于第10,因为通用和智能体两项共同拉低了综合表现。
-
推理(Reasoning)
推理维度趋势图
推理是本次四个维度中行业均分最高的一项,达到70.49分,这说明推理能力已经成为当前大模型整体表现最成熟的方向之一。
在Top 10中,Claude Fable 5的推理得分为78.29,排名最高;GPT-5.5(xhigh)为76.50,Claude Opus 4.8为76.22。头部三款模型在推理上都超过76分,形成比较清晰的高分区。
中游模型中,Qwen3.7-Max的推理得分为74.02,表现非常突出,甚至高于 Claude Opus 4.7的73.61、GLM-5.2的71.65和Gemini 3.1 Pro的72.91。这说明Qwen3.7-Max虽然总分排名第 6,但在推理维度上具备较强竞争力。
此外,Qwen3.7-Max-Preview的推理得分也达到72.93,高于Gemini 3.5 Flash的72.57和Claude Opus 4.6的70.43,对于关注推理任务的用户来说,虽然这类模型即使总分不是最靠前,但也值得结合具体任务进一步观察。

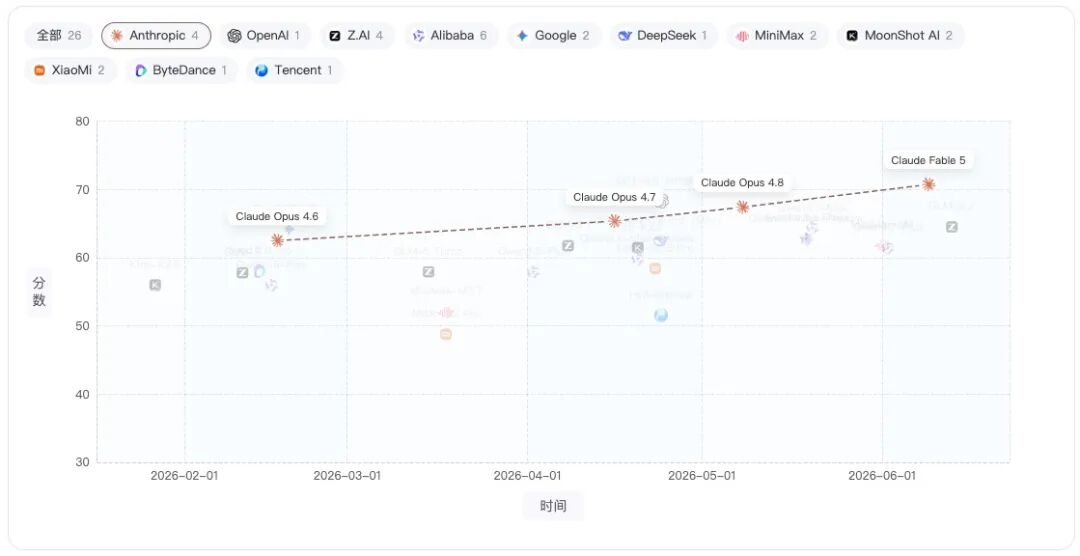
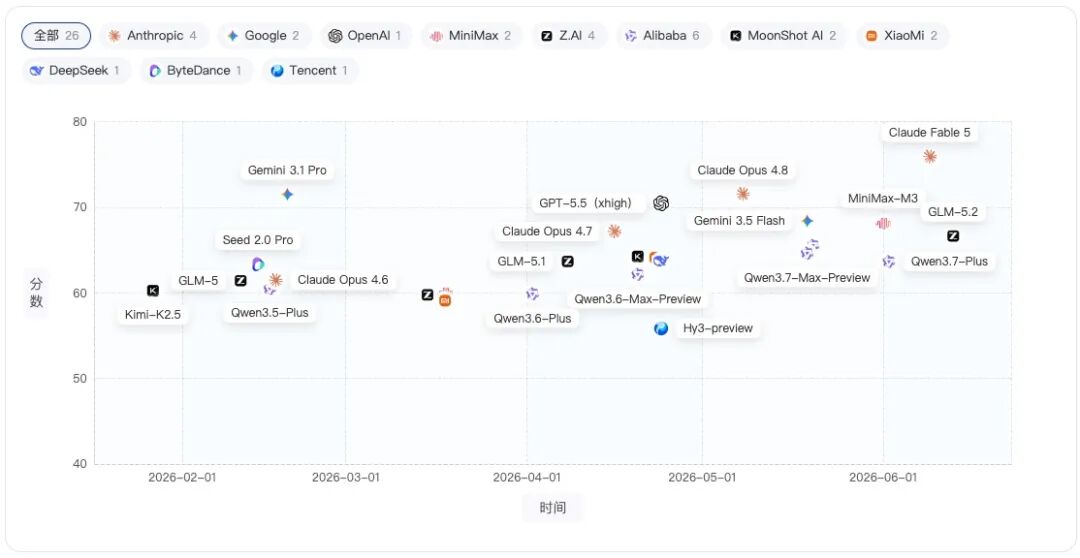
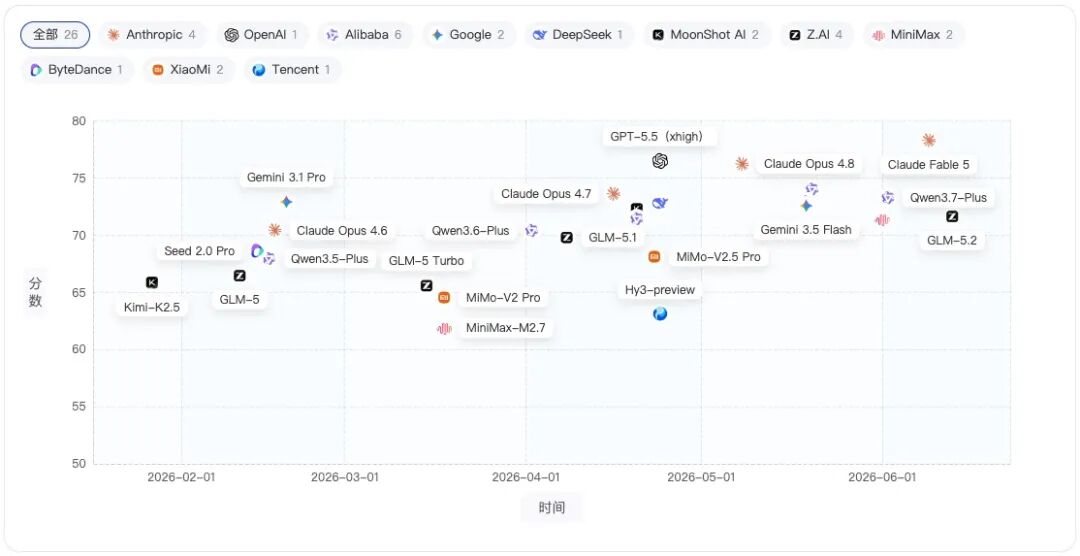
Anthropic:Claude Opus 4.6 → Claude Opus 4.7 → Claude Opus 4.8 → Claude Fable 5
Anthropic 的 Claude系列从Opus 4.6到Fable 5呈现持续上行趋势,最新 Claude Fable 5已明显站上当前榜单头部位置,体现出连续版本迭代带来的综合能力提升。
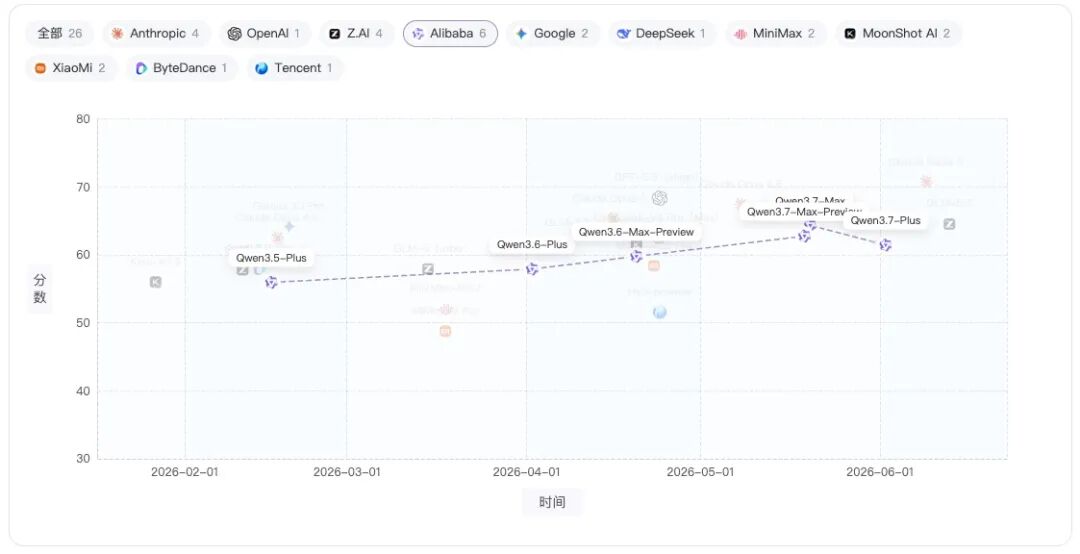
Alibaba:Qwen3.5-Plus→Qwen3.6-Plus→Qwen3.6-Max-Preview → Qwen3.7-Max-Preview→Qwen3.7-Max→Qwen3.7-Plus
Alibaba的Qwen系列整体呈稳定爬升趋势,3.7版本已进入较高分段,说明其在近期版本迭代中持续缩小与头部模型的差距。
Google:Gemini 3.1 Pro → Gemini 3.5 Flash
Google的Gemini系列两个版本分数整体接近,Gemini 3.5 Flash相比Gemini 3.1 Pro没有形成明显上扬,更像是不同的模型定位,保持在相近能力区间。
Moonshot AI:Kimi-K2.5 → Kimi-K2.6
Moonshot AI的Kimi系列从K2.5到K2.6分数明显上涨,显示新版本在综合能力上有较清晰的提升。
Z.AI:GLM-5 → GLM-5 Turbo → GLM-5.1 → GLM-5.2
Z.AI的GLM系列经历短暂波动后持续走高,GLM-5.2相比早期版本已进入更高分段,说明后续版本迭代带来了较稳定的能力增益。
MiniMax:MiniMax-M2.7 → MiniMax-M3
MiniMax从M2.7到M3出现明显跃升,分数跨越幅度较大,是升级收益较突出的模型线之一。
XiaoMi:MiMo-V2 Pro → MiMo-V2.5 Pro
XiaoMi的MiMo系列从V2 Pro到V2.5 Pro分数稳步提升,说明新版本在综合评测表现上有一定进步,但整体仍处于中游竞争区间。
其他:GPT-5.5(xhigh)、DeepSeek-v2pro(max)、Seed 2.0 Pro、Hy3-preview
GPT-5.5(xhigh)、DeepSeek-v2pro(max)、Seed 2.0 Pro和Hy3-preview当前仅有单个版本入榜,暂时无法判断版本演进趋势,更适合作为各厂商当前代表模型的横向对比样本。
说明:
本文中提到的模型排名、分数及能力分析,均基于晓天衡宇评测社区2026年6月大语言模型综合评测结果。评测结果受评测集构成、任务类型、评分方法、模型版本及调用参数等因素影响,仅代表模型在本次评测条件下的表现,不等同于模型在所有真实业务场景中的绝对能力排序。

-
【模型能力-推理速度】分析
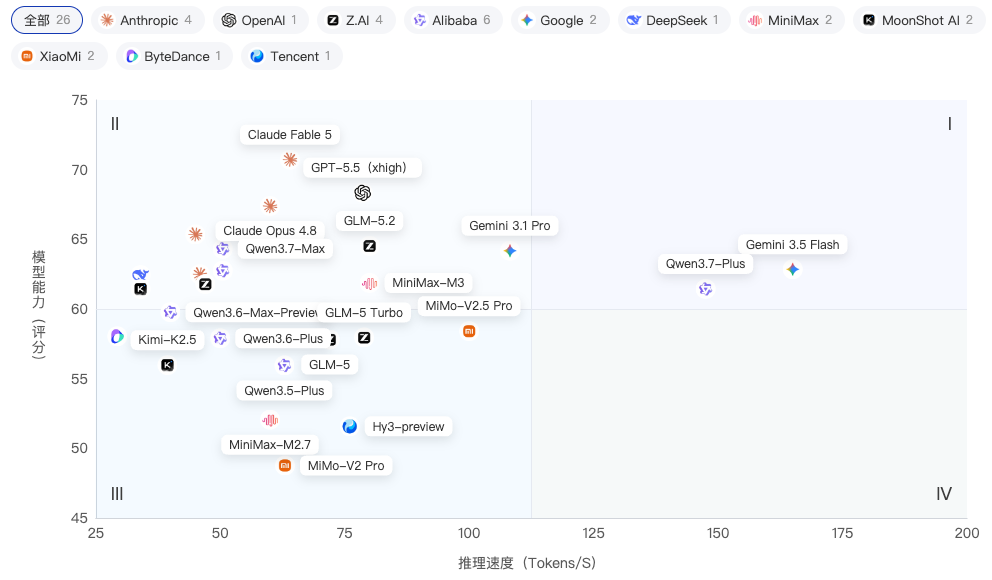
散点图以推理速度为横轴、综合能力为纵轴,呈现典型的"能力-效率"博弈格局。
第一象限(高速高能):Gemini 3.5 Flash(165.0 Tokens/s,62.85分)和Qwen3.7-Plus(147.5,61.44分)兼具速度与能力,是当前最佳效率模型。
第二象限(低速高能):Claude Fable 5(64.0,70.72分)、GPT-5.5(78.6,68.35分)和Claude Opus 4.8(60.0,67.39分)牺牲速度换取深度推理,集中在45-80速度区间但能力均超67分。值得关注的是GLM-5.2(80.0,64.53分),兼具中高速与国产最高能力,处于两个象限的交界位置。
第三象限(低速低能):Seed 2.0 Pro(29.3,58.04分)速度与能力均处末位。
第四象限(高速低能):MiMo-V2.5 Pro(100.0,58.41分)速度极快但能力偏弱。
整体分布揭示:当前超高能力(>67分)与超高速度(>100 Tokens/s)仍难兼得,但58-65分区间已有多款速度破80的均衡模型出现。
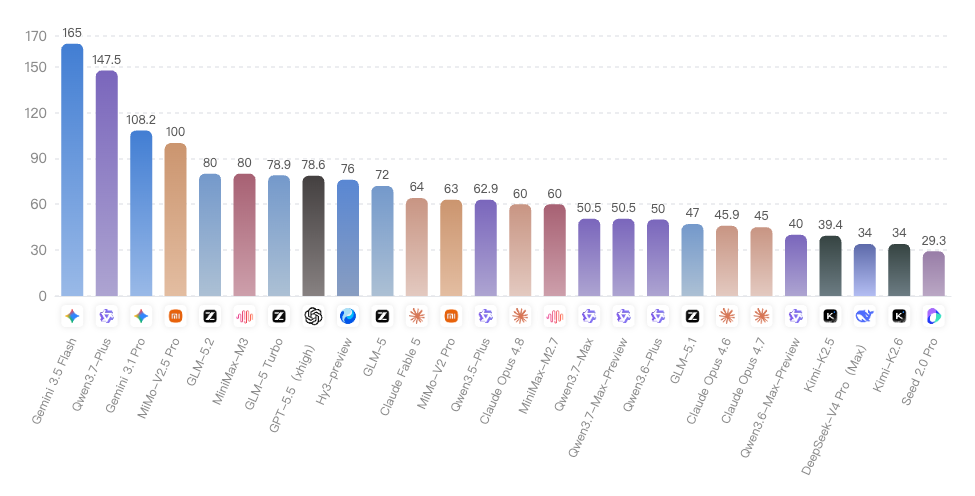
推理速度呈三级阶梯分布,头尾差值达135.7。
第一梯队(>100 Tokens/s):Gemini 3.5 Flash以165.0大幅领跑,Qwen3.7-Plus(147.5)紧随其后,Gemini 3.1 Pro(108.2)和MiMo-V2.5 Pro(100.0)同处百级区间,四者均以推理优化见长。
第二梯队(60-100):MiniMax-M3(80.0)、GLM-5 Turbo(78.9)、GPT-5.5(78.6)等11款模型密集分布,构成主力区间。
第三梯队(<60):Claude系列集中在45-64区间整体偏慢,DeepSeek-V4 Pro和Kimi系列均为34,Seed 2.0 Pro以29.3垫底。
速度与能力存在显著trade-off——榜首Claude Fable 5速度仅64.0,速度冠军Gemini 3.5 Flash能力排第7(64.66分),高能力模型倾向更深层推理计算。
-
【模型能力-推理成本】分析
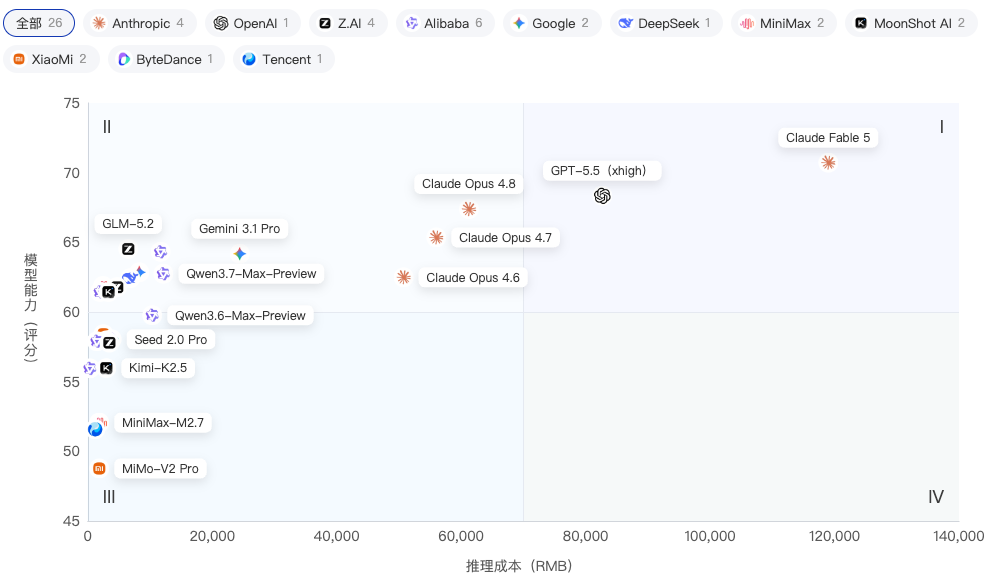
以本次评测产生的实际推理总成本(RMB)为横轴、综合能力为纵轴,散点图揭示了完成全部评测任务的真实花费与模型能力之间的关系。
高成本高能力区:Claude Fable 5评测总成本最高(119,000元)且能力最强(70.72分),GPT-5.5(82,688元,68.35分)和Claude Opus 4.8(61,250元,67.39分)紧随其后,三者均为海外闭源模型,评测总花费集中在6-12万区间。
中等成本区:Gemini 3.1 Pro(24,413元,64.18分)和Qwen3.7-Max(11,700元,64.32分)提供了较好的能力成本比,后者以不到前三名1/5的花费获得接近的能力水平。
低成本高效区:MiniMax-M3(2,450元,61.87分)以极低评测成本进入前12;Qwen3.7-Plus(1,969元,61.44分)和DeepSeek-V4 Pro(6,825元,62.43分)同样展现出优秀的成本效率。
极致低成本:Qwen3.5-Plus仅330元,Hy3-preview仅1,188元。该指标综合反映了Token消耗量与API单价的乘积效应,是衡量模型实际使用经济性的核心参考。API定价呈极端长尾分布,头尾相差超127倍。
-
【模型能力-模型参数】分析
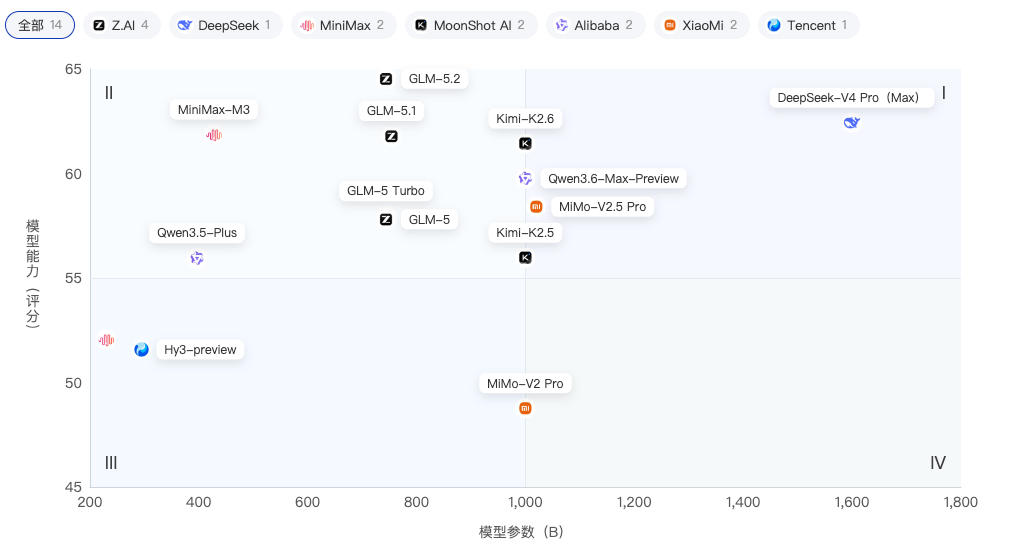
以模型参数量(B)为横轴、综合能力为纵轴,散点图基于13款公开参数量的模型进行分析。参数最大的DeepSeek-V4 Pro(1600B)得分62.43位列第11,并非能力最强,说明参数规模已非决定性因素。
高参高能区:Kimi-K2.6和MiMo-V2.5 Pro均为1000B,前者61.43分后者58.41分,同参数下表现分化。
中参高效区:GLM-5.1(754B,61.79分)和GLM-5 Turbo(744B,57.96分)参数接近但得分差4分,体现训练策略差异;MiniMax-M3以428B获得61.87分,参数效率极为突出。
低参区:MiniMax-M2.7(230B,52.06分)为最小参数模型,能力受限。
整体趋势表明:在600B以上区间,参数增加带来的能力增益已明显递减;400-800B区间是当前性能与效率的最佳平衡点。架构创新、数据质量和训练方法对最终能力的贡献已超过单纯的参数堆叠。
-
【模型能力-Token消耗】分析
-
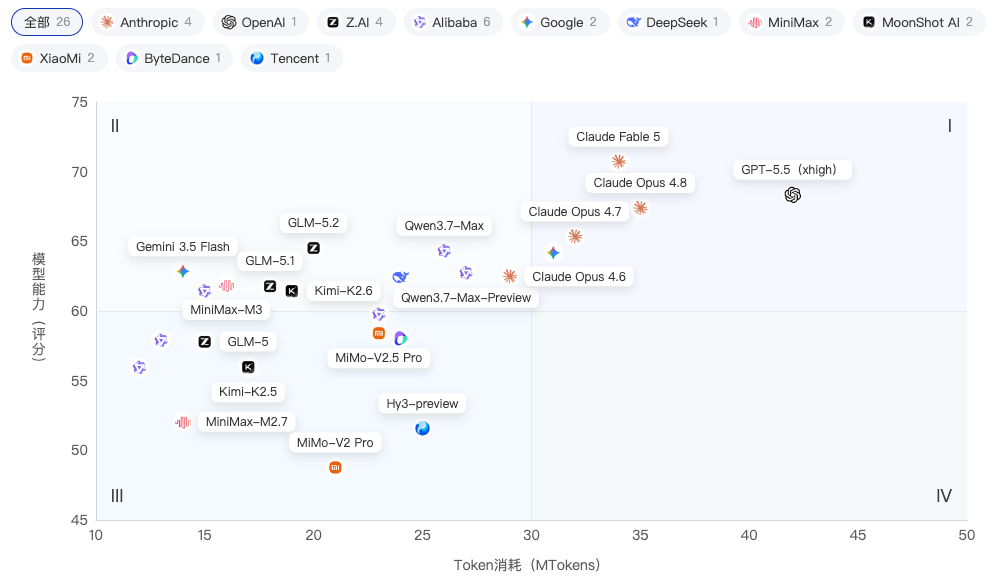
以本次评测实际消耗的Token量(MTokens)为横轴、综合能力为纵轴,散点图展示了各模型完成全部评测任务所需的Token资源与最终能力产出的关系。
高消耗高能力区:GPT-5.5完成评测消耗最高(42 MTokens,68.35分),Claude Fable 5(34 MTokens,70.72分)以更少Token消耗获得更高分数,评测效率更优。Claude Opus 4.8(35 MTokens,67.39分)与Claude Opus 4.7(32 MTokens,65.35分)同属高消耗阵营。
高效率代表:Gemini 3.5 Flash仅消耗14 MTokens即获62.85分,Qwen3.6-Plus以13 MTokens获57.90分,Qwen3.5-Plus以最低的12 MTokens获55.95分,三者在评测中展现出极佳的Token利用效率。
低效区域:Hy3-preview消耗25 MTokens但仅获51.58分,MiMo-V2 Pro消耗21 MTokens仅获48.77分,评测资源消耗与能力产出不成正比。
该指标反映模型在实际评测场景下的资源开销,Token消耗越低意味着同等评测条件下推理成本越小。
-
【模型性价比-API价格】分析
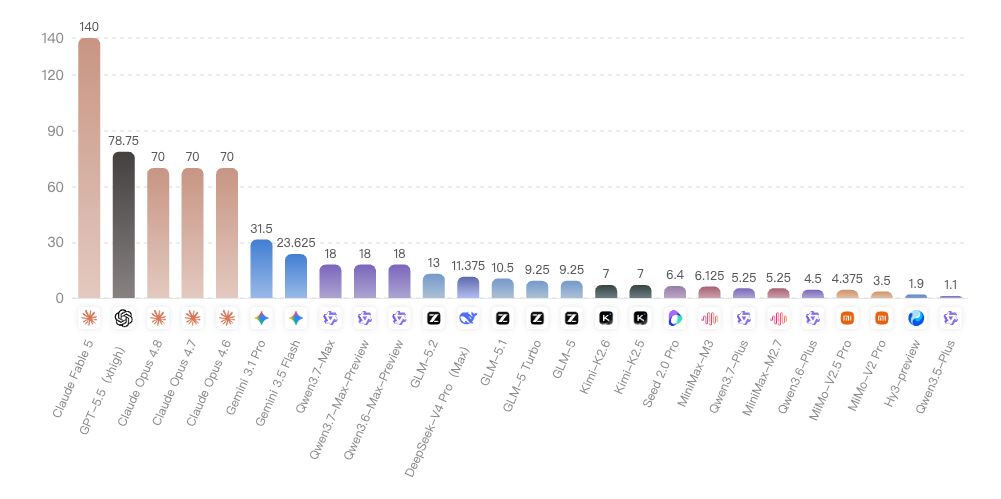
API定价呈极端长尾分布,头尾相差超127倍。
高价区(>60元):Claude Fable 5以140元独占高位,GPT-5.5(78.75元)和三款Claude Opus(均70元)构成海外高端定价带,5款均为海外闭源。
中价区(10-35元):Gemini 3.1 Pro(31.5元)、Gemini 3.5 Flash(23.6元)、Qwen3.7-Max(18元)和DeepSeek-V4 Pro(11.4元)分布其中,Qwen系列以18元获第6名能力,性价比突出。
低价区(<10元):聚集15款模型,GLM系列(9.25元)、Kimi系列(7元)、MiniMax-M3(6.1元)为代表,Qwen3.5-Plus(1.1元)最低。
整体来看,大模型API定价已形成明确的三档格局,高端市场由海外厂商主导,而国产模型凭借成本优势在中低价区形成密集竞争,同等能力下成本仅为海外的1/5至1/10。

6月大语言评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)