
坑01|阿里云 Embedding 限流踩坑——RPS/TPM/batch 三重锁,滑动窗口怎么救场
踩坑实录 · 坑01 · 阿里云 Embedding 限流踩坑-苦猿踩坑系列
前言:三重锁,大多数人只看见最外面那把
我先说一句可能让你心里咯噔一下的话——
阿里云 text-embedding 的限流,是三把锁叠在一起的。
而绝大多数人,只看见最外面那把。
那把最显眼的锁,叫 batch_size ≤ 10——单次请求最多塞 10 条文本。文档里写得明明白白,谁都知道。
我也是。
前阵子做一个 RAG 知识库项目,要给上百本产品手册做向量化入库。我老老实实把 batch_size 卡到 5(留一半余量),分批循环往阿里云灌数据,心里还美滋滋——这事稳了。
然后?
然后跑到第 4000 条切片的时候,报错开始像潮水一样涌进来。
TPM 超了。
RPS 排队。
我试着换 text-embedding-async-v1 异步接口救场,结果发现——异步接口的限流更狠,单用户并发只能跑 3 个作业。

那一晚我盯着官方文档那行小字看了很久,突然想明白一件事:
云厂商卖的不是"无限算力",是"被精密切分的配额"。 你以为买的是水龙头,其实买的是一个带流量计的水表。
这篇,我把这三重锁一一把钥匙讲清楚,最后给一个我线上在跑的滑动窗口救场方案。
PART 01:第一重锁——batch_size ≤ 10,最显眼但也最温柔
先说最外面这把锁。
阿里云 text-embedding 的同步接口(v1 到 v4 都一样),单次请求最多 10 条文本。
这个限制太显眼了,显眼到几乎所有教程都会提一嘴。我项目里的真实写法是这样的:
# 批次大小配置:留一半余量,防 token 上限溢出
batch_size = 5
# 按批次遍历,避免一次性处理过多数据
total = len(texts_to_embed)
for i in range(0, total, batch_size):
batch_texts = texts_to_embed[i:i + batch_size]
# 构造输入文本、调用 embedding、绑定向量...
docs_embeddings = generate_embeddings(input_texts)batch_size = 5 而不是顶到 10,是因为除了"条数上限",还有个隐藏的"单次 token 上限"。一条长文本可能就把 token 额度吃掉大半,10 条长文本一起塞进去,照样炸。
但我想说的是——
batch 这把锁,其实是最温柔的。
因为它是一次性约束。你分批循环,一次 5 条、一次 5 条,慢慢灌,它就拦不住你。它更像入口的安检,查一下你包大不大,不会真把你挡在门外。
真正的杀手,是里面那两把。
batch 是入口的安检,限流才是大厅里的保安。

PART 02:第二重锁——RPS=30,每秒 30 次的天花板
第二把锁,叫 RPS(Requests Per Second)= 30。
text-embedding v1 到 v4,所有同步模型,每秒最多调用 30 次。一刀切,没有商量。
听起来挺多?30 次/秒,一分钟 1800 次,够用了吧?
不够。因为你一旦上多线程,这 30 次会在零点几秒内被打满。
举个我自己踩过的场景——
我想加速入库,开了个线程池,并发 10 路,每路 batch_size = 5。我心算了一下:10 路并发,每路一次请求,1 秒打 10 次请求,离 30 还远着呢,稳。
错。
线程池的任务调度不是匀速的。10 个线程几乎在同一瞬间一起发请求,紧接着第二批、第三批……1 秒内打过去 50 次请求,直接触发限流。
报错长得像这样:Throttling.RateQuota / 429 Too Many Requests。
这里有个特别反直觉的点,我栽过跟头,必须单独拎出来讲——
RPS 数的是"调用次数",不是"文本条数"。
所以你以为"把 batch_size 设小一点就更安全",结果恰恰相反。
batch_size = 5,意味着 10 条数据要发 2 次请求。
batch_size = 1,意味着 10 条数据要发 10 次请求。
batch 越小,RPS 压力越大。
这两把锁是反向拧的:batch 锁逼你"分小批",RPS 锁又惩罚"分小批"。你要是只盯着第一把锁,必然在第二把锁上撞墙。
这也是为什么——你不能裸跑多线程,必须加节流器。
PART 03:第三重锁——TPM=120 万 + async 并发≤3,最隐蔽也最致命
到了第三把锁,才是真正让我那一晚崩溃的地方。
它叫 TPM(Tokens Per Minute)= 1,200,000,每分钟最多消耗 120 万个输入 token。
注意——只算输入 token,不算输出(embedding 本来也没什么输出 token,向量不算)。
120 万,听着天文数字。但你算笔账就知道它的可怕:
一条中等长度的 PDF 切片,算 500 token。
一秒打满 RPS 30 次 × batch 10 条 = 300 条/秒 = 15 万 token/秒。
一分钟 = 900 万 token。
120 万的额度,8 秒就烧完了。
剩下的 52 秒,全在限流里排队。
我跑那批上百本产品手册的时候,前几分钟 RPS 控得好好的,进度条嗖嗖往前走。然后突然——大面积报错。
TPM 爆了。
你以为这就完了?我那一晚还干了一件更蠢的事——
我去翻 async 异步接口想救场。
text-embedding-async-v1,名字多性感啊。异步嘛,听起来就该是不限流、随便跑的存在。
我点开它的限流配置,差点一口老血喷屏幕上——
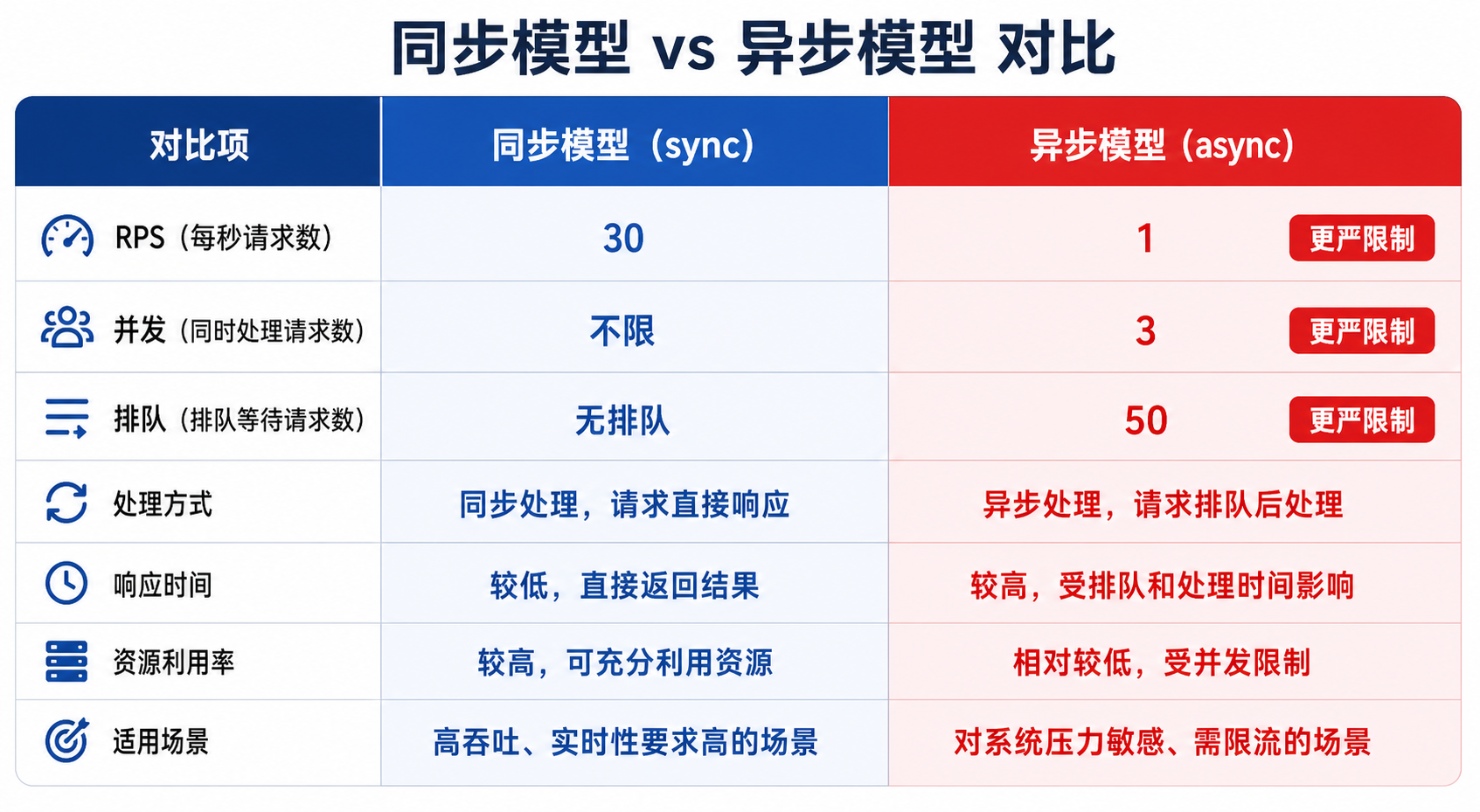
| 限流项 | sync v1~v4 | async-v1 |
|---|---|---|
| RPS(每秒请求数) | 30 | 1 |
| 单用户并发作业 | — | ≤ 3 |
| 排队+运行作业总数 | — | ≤ 50 |
| Batch API 免限流 | ✅ | ❌ |
RPS 只有 1。
同一时间只能跑 3 个作业。
排队超过 50 个就拒绝新作业。
我以为换了个更宽的赛道,结果发现这条赛道是单行道、还限速 1。
这是最阴的一刀——你以为换了赛道,结果赛道更窄。
async 接口唯一适合的场景,是那种"我就跑几万个、慢慢来、不赶时间"的离线批处理。但凡你想快一点,它比 sync 还坑。
最后再补一刀——表格最后一行那个"Batch API 免限流"。
sync v1~v4 调用 Batch API(注意是另一个产品,不是同步接口)时不受这套限流约束。但 async-v1 没有这个豁免。
也就是说,如果你真的有海量数据要灌,走 sync 模型 + Batch API 才是正解,不是 async。这个信息藏在表格备注的小字里,不踩坑你根本不会注意到。
限流文档里最小的字号,往往是最大的坑。
PART 04:救场解法——一个 40 行的滑动窗口限流器
三重锁讲完了,现在给解法。
思路其实很简单——在每次调用 embedding 之前,先问一下限流器:我现在能发吗?不能发就 sleep 等一会儿。
这就是限流器(throttle)。我项目里写了一个 40 行的滑动窗口实现,线上在跑,稳定救场。
完整代码在这里:
# app/utils/rate_limit_utils.py
import time
from typing import Deque
def apply_api_rate_limit(
request_times: Deque[float],
max_requests: int,
window_seconds: int = 60
) -> None:
"""
通用滑动窗口 API 速率限制器。
核心逻辑:维护请求时间戳双端队列,
窗口内请求数超上限则自动等待,防止触发第三方 API 限流。
"""
current_time = time.time()
# 1. 清理滑动窗口外的过期请求时间戳
while request_times and current_time - request_times[0] >= window_seconds:
request_times.popleft()
# 2. 窗口内请求数达上限,计算并阻塞等待剩余时间
if len(request_times) >= max_requests:
sleep_duration = window_seconds - (current_time - request_times[0])
if sleep_duration > 0:
time.sleep(sleep_duration)
# 等待后重新清理过期请求(sleep 期间可能有请求过期)
current_time = time.time()
while request_times and current_time - request_times[0] >= window_seconds:
request_times.popleft()
# 3. 记录当前请求时间戳,加入滑动窗口队列
request_times.append(current_time)调用现场长这样——在批量入库的循环里,每次发请求前先过一道限流器:
from collections import deque
from app.utils.rate_limit_utils import apply_api_rate_limit
request_times = deque() # 关键:外部初始化,跨循环复用
for img_file, image_path, context in targets:
# 发请求前先节流:60 秒窗口内最多 25 次
apply_api_rate_limit(request_times, max_requests=25, window_seconds=60)
# 然后才是真正的 API 调用
summary = summarize_image(image_path, ...)这段代码我在线上两个场景都在用——VL 大模型做图片摘要、阿里云 embedding 做向量入库,同一套限流器。
讲四个关键设计点,这四个点每一个都是我踩坑后才补上的:
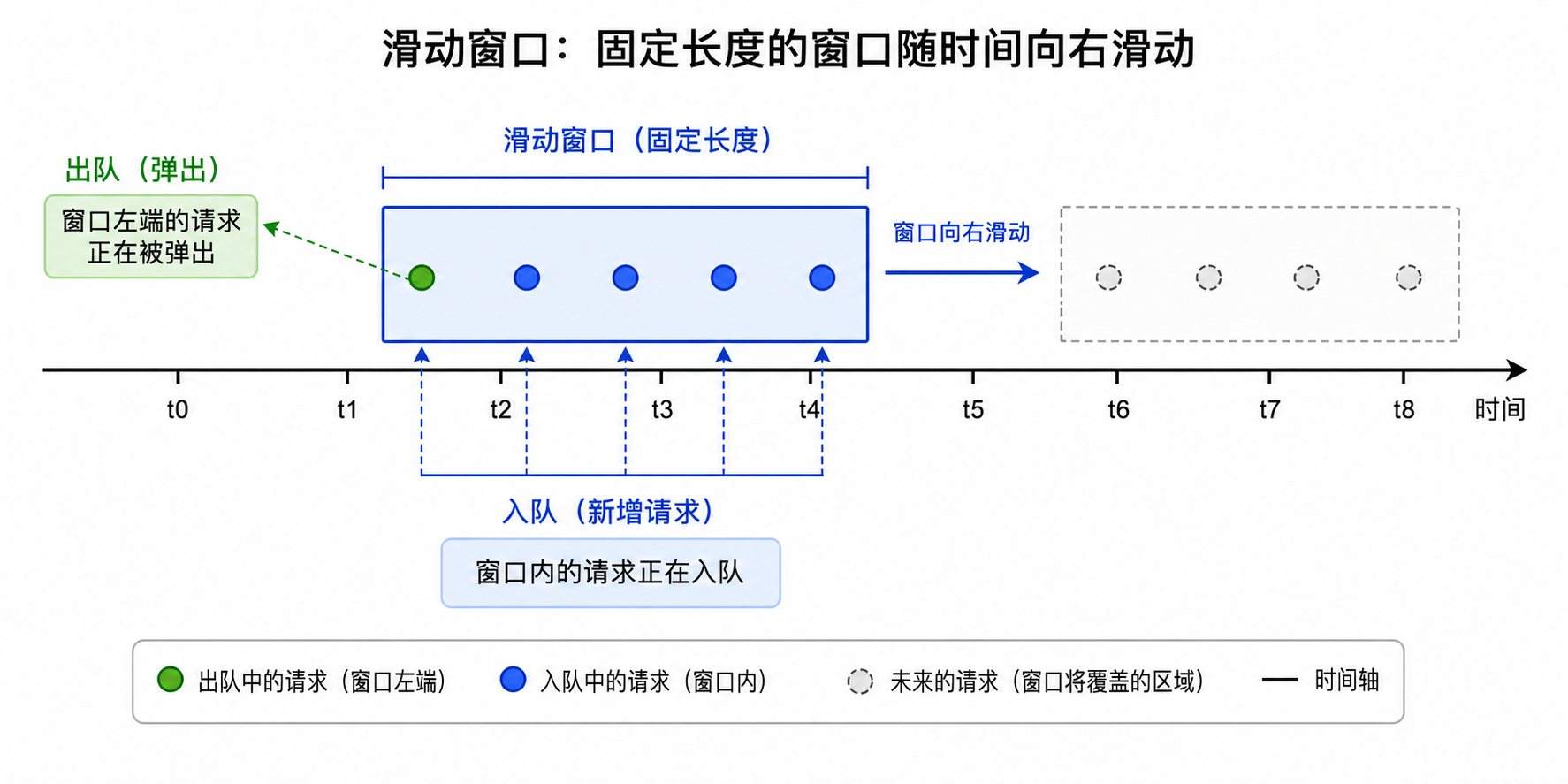
1. 为什么用滑动窗口,不用固定窗口?
固定窗口有个经典 bug:窗口边界瞬间会双倍突发。比如"每分钟 30 次",固定窗口在 00:59 打 30 次、01:01 又打 30 次——1 秒内打了 60 次,云厂商照样把你 ban 了。
滑动窗口没有边界,它永远看"过去 60 秒内"有多少请求,所以不会出现这种瞬间双倍突发。
2. 队列必须外部初始化、跨调用复用
这是新手最容易踩的坑。如果你在限流器函数内部 request_times = deque(),每次调用都是一个新队列,永远显示"窗口内 0 个请求",限流器形同虚设。
队列必须是外部传入的、跨循环复用的同一个对象。我代码注释里专门标了这一行。
3. max_requests 留 buffer,别顶满
RPS 上限是 30,我限流器设的是 25,不是 30。
为什么不顶满?因为限流器自己有计算开销、网络有抖动、云厂商的计数也不一定精确卡在 30。顶满 30,等于在悬崖边上跳舞。留 5 个的 buffer,是给突发和误差留的呼吸空间。
4. sleep 之后要重新清理过期时间戳
代码里这一段很容易被读漏:
if sleep_duration > 0:
time.sleep(sleep_duration)
current_time = time.time() # ← 别忘了更新当前时间
while request_times and current_time - request_times[0] >= window_seconds:
request_times.popleft() # ← sleep 期间又有请求过期了,要重新清time.sleep 醒来后,时间已经往前走了,队列头部可能有新的过期时间戳。不重新清理,下一轮限流判断就是错的。
把这四点都照顾到,这套 40 行的代码就能稳稳挡住三重锁里的 RPS 这一刀。
至于 TPM 那一刀——限流器救不了。120 万 token/分钟是硬配额,你只能靠"降低单条 token 量"(更激进的切片)或者"走 Batch API 豁免通道"来绕。那是另一个坑,留到以后讲。
限流不是和云厂商博弈,是和"自己的并发冲动"博弈。
结尾:第一天就该把限流器写进公共工具类
回头看这一晚上的折腾,我最大的教训不是"阿里云限流狠",而是——
我本该在写 RAG 的第一天,就把限流器写进公共工具类。
而不是等撞了 TPM、撞了 RPS、撞了 async 并发,才回头去补这 40 行代码。
云厂商的限流,从来不是 bug,是商业模式的一部分。他们卖的是被精密切分的配额,每一档价格对应一档流量。你越早认清这件事,就越早能把架构搭对——限流器、重试退避、失败队列,这些"看起来不产生价值"的代码,恰恰是生产环境和玩具项目的分水岭。
写到这里,我想给所有正在做 RAG / 向量入库的同学一句话——
限流器不是性能优化,是生产环境的呼吸阀——平时看不见,缺氧的时候,它救你一命。
batch_size 是安检口,RPS 是闸门,TPM 是水表。
三个都过,数据才能流进向量库。
互动时间:你在用哪家云的 embedding?阿里云、OpenAI、智谱、还是本地部署?撞过哪种限流?评论区聊聊,点赞够多的话,我把各家厂商的限流数字整理成一张对比表发出来。
— END —
苦猿 · 陪你踩完每一个坑

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)