
Claude Code 实战:用小项目验证核心能力
聊《Claude Code 实战:用小项目验证核心能力》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
上周我把手头那个跑了半年的 Python 数据清洗脚本重构了一遍。不是因为它写错了,而是随着数据源接口的变更,原来的硬编码逻辑变得像一团乱麻。我没有急着动手改代码,而是先拉起了 Claude Code(基于 Claude 3.5 Sonnet 模型),做了一次完整的结对编程复盘。
很多人问我:“AI 编程到底能不能替代人?”我的回答很直接:**它不能替代你的架构决策,但它能极大压缩“理解代码”和“生成样板代码”的时间。**
这次复盘,我不谈那些花哨的概念,只讲在实际项目中,Claude Code 是如何介入、又是哪里让我不得不手动干预的。以下是我在一个中型 Python 项目中,利用 Claude Code 进行代码库阅读、需求拆解、重构及测试搭建的真实路径。
目录
- 为什么选这个小项目?
- 代码库阅读:让 AI 成为你的“新同事”
- 需求拆解:从模糊想法到具体指令
- 重构与测试:补上缺失的一环
- 使用边界:什么时候该停下来?
- 总结
为什么选这个小项目?
选择这个数据清洗模块作为测试对象,是因为它具有典型性:
1. **逻辑耦合度高**:数据预处理、格式校验、异常处理混在一起。
2. **测试覆盖率低**:原本只有 20% 的单元测试,且多为边界情况,缺乏业务逻辑覆盖。
3. **文档缺失**:主要靠 Git Commit 记录猜测意图。
这正是 AI 结对编程最能发挥价值的场景:快速理解上下文,辅助补充测试,并安全地进行重构。
代码库阅读:让 AI 成为你的“新同事”
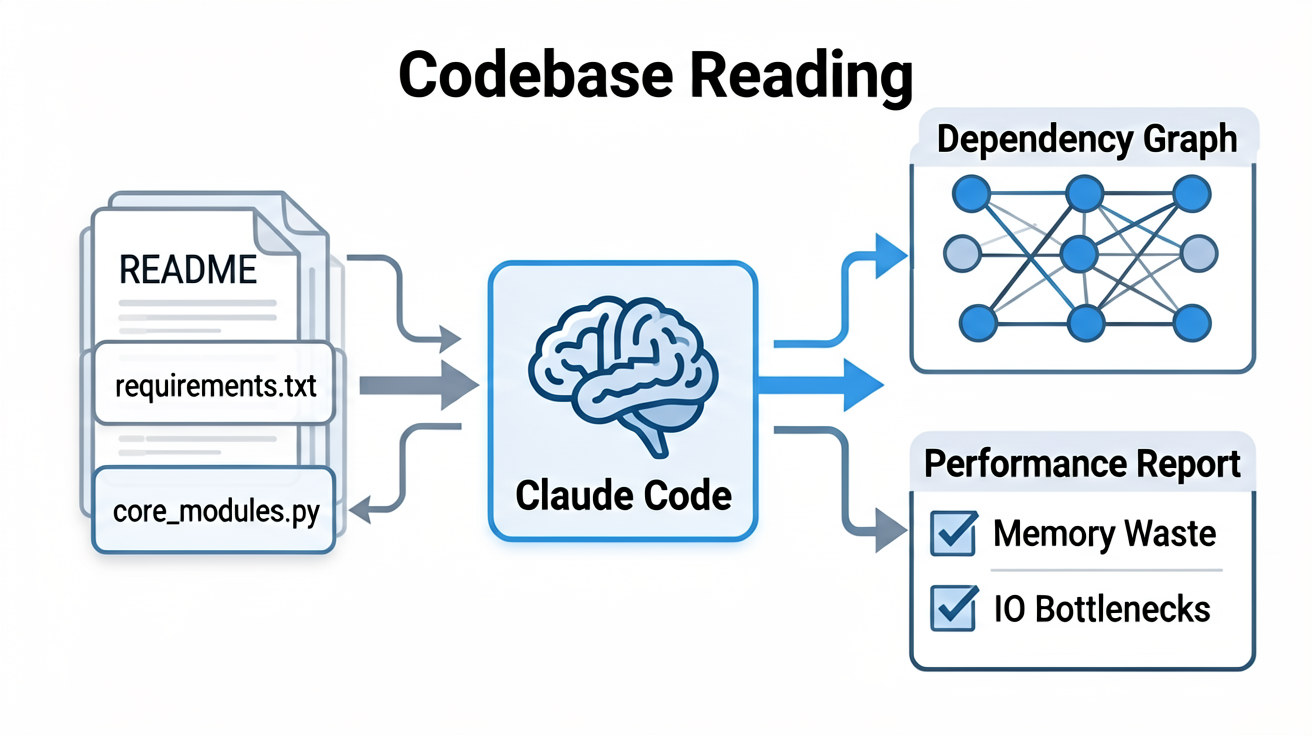
在动刀之前,我先做了一个简单的操作:将项目根目录下的 `README`、`requirements.txt` 以及核心模块文件一次性添加到 Claude Code 的上下文中。
传统的做法是我自己花半天时间梳理调用链,而 Claude Code 能在几秒内给出一个结构化的概览。
> **踩坑提醒**:不要把所有文件都扔进去。对于大型项目,上下文窗口虽然大,但噪音也会增加。我只保留了核心业务逻辑文件和配置项,排除了第三方依赖和无关的静态资源。
当我询问:“这段代码的主要数据流向是什么?”时,它不仅画出了流程图,还指出了两个潜在的性能瓶颈:一个是未使用的列表推导式导致的内存浪费,另一个是重复的文件 IO 操作。
这种“旁观者清”的视角,比我独自 debugging 时要高效得多。但我并没有完全信任它的结论,而是通过追问细节来验证其准确性。例如,它会建议将 `if-else` 分支改为策略模式,但这在我的简单场景中可能属于过度设计。
**取舍建议**:AI 擅长提供多种方案,但你需要根据项目的规模和维护成本来决定采纳哪一项。

需求拆解:从模糊想法到具体指令
重构的目标很明确:**提高可测试性**。但这个目标太宽泛,直接让 AI “重构代码”往往得到一堆不可读的结果。
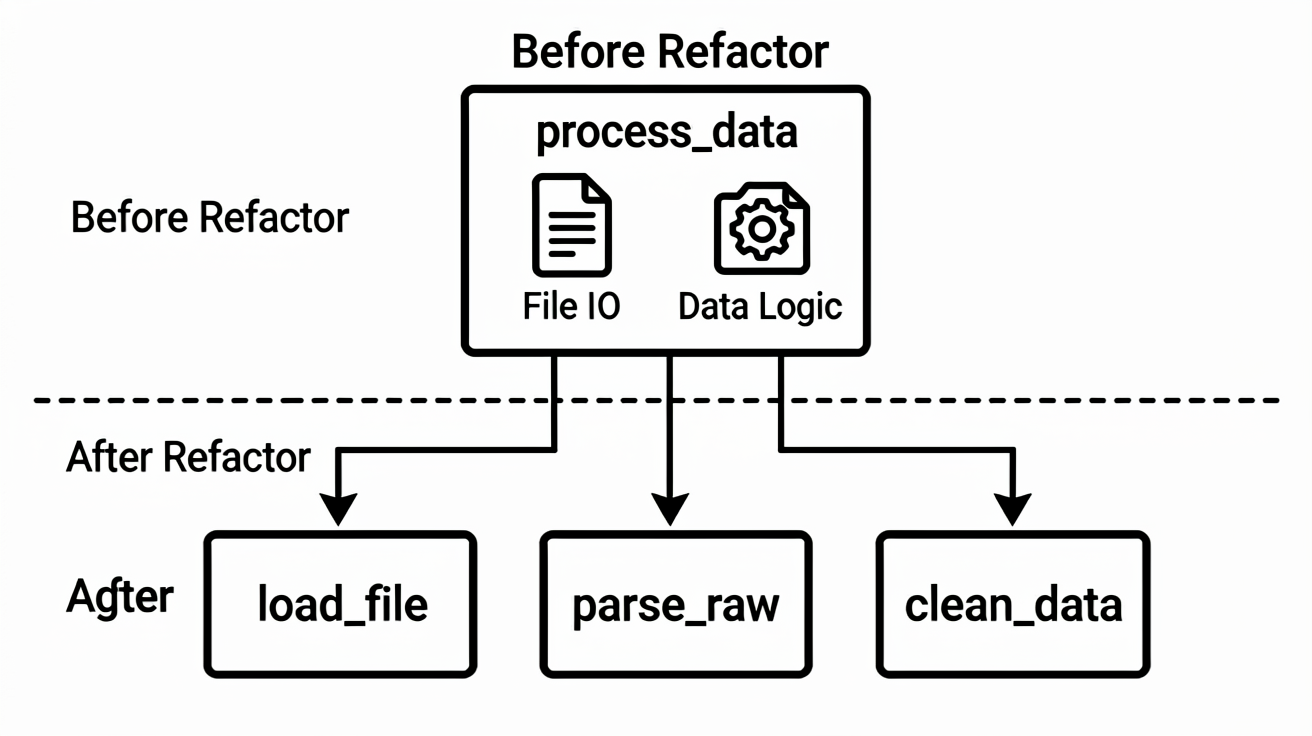
我采用了分步拆解的策略。首先,我将业务逻辑与 I/O 操作解耦。
# 重构前:混合了数据处理和文件操作
def process_data(file_path):
with open(file_path) as f:
raw_data = f.read()
# 复杂的清洗逻辑...
return cleaned_data
# 重构后:分离关注点
def load_file(path): ...
def parse_raw(raw_string): ...
def clean_data(parsed_objects): ...在这个过程中,我让 Claude Code 帮忙生成具体的接口定义,并编写对应的类型注解。我给出的 Prompt 非常具体:
> “请将 `process_data` 函数拆分为三个独立的功能函数:`load_file` 负责读取,`parse_raw` 负责字符串解析为 JSON,`clean_data` 负责数据清洗。请确保每个函数都有明确的输入输出类型,并添加错误处理。”
AI 生成的代码结构清晰,但有一个细节我手动修正了:它在 `parse_raw` 中使用了全局变量来缓存解析结果,这在小脚本中没问题,但在并发场景下会有竞态条件。我随后添加了局部作用域的限制。
重构与测试:补上缺失的一环
这是我最满意的部分。原有的代码几乎没有测试,重构风险极高。我让 Claude Code 基于新的函数签名,自动生成单元测试用例。
我特别强调了异常场景的覆盖:
import pytest
def test_parse_raw_with_invalid_json():
"""测试无效 JSON 输入的异常处理"""
invalid_input = "{ 'key': 'value' }" # 注意这里是单引号,非标准 JSON
with pytest.raises(ValueError, match="Invalid JSON"):
parse_raw(invalid_input)
def test_clean_data_empty_list():
"""测试空列表输入"""
assert clean_data([]) == []AI 不仅生成了正常的断言,还敏锐地捕捉到了我之前忽略的一个边界情况:当输入文件为空时,`load_file` 应该返回什么?它建议抛出 `EmptyFileError` 而不是静默失败,这在日志追踪上更有意义。
**实战建议**:在生成测试代码时,一定要检查 `pytest` 的断言消息是否清晰。AI 有时候会生成过于晦涩的错误提示,手动微调一下 `match` 参数能让调试更直观。
使用边界:什么时候该停下来?
尽管体验不错,但我也遇到了一些局限性。
1. **深层业务逻辑的理解偏差**:当涉及到特定的行业规则(如金融领域的特殊舍入算法)时,AI 往往会套用通用规则,导致细微的逻辑错误。这类核心业务逻辑,必须由人把关。
2. **跨文件引用的复杂性**:如果项目中有大量的动态导入或元类机制,Claude Code 可能会产生幻觉,引用不存在的属性。此时,最好将其限制在单一文件或清晰的模块边界内进行重构。
3. **上下文遗忘**:在多轮对话中,如果对话过长,早期的约束条件可能会被淡化。建议在关键步骤后,定期让 AI 总结当前的修改状态,并确认是否符合初衷。
**我的判断标准**:如果 AI 给出的代码需要我反复验证其正确性,且耗时超过我自己编写的两倍,那就停止使用,回归原生开发。
总结
这次重构经历让我对 Claude Code 的定位有了更清晰的认知:它是一个强大的**“辅助加速器”**,而非**“自动驾驶仪”**。
- **它适合**: boilerplate 代码生成、现有代码的理解与解释、边界测试用例的补充、以及初步的重构方案设计。
- **它不适合**:复杂的业务逻辑决策、涉及敏感数据的深层架构设计、以及对精度要求极高的数学算法实现。
对于正在评估是否引入 AI 编程工具的团队或个人,我建议从一个小型的、非核心的模块开始试点。不要试图一步到位地重写整个系统,而是像这次一样,通过“阅读-拆解-测试”的小循环,逐步建立对 AI 输出的信任和审查习惯。
真正的提效,不在于让 AI 写出完美的代码,而在于让你更快地发现代码中的问题,并更有信心地进行改进。在这个过程里,你依然是那个掌舵的人,只是船速更快了,视野更宽了。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。

如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)