
GLM-5.2 编程实战全解:744B MoE、1M 无损上下文、Code Arena 全球第一,国产开源长程 Coding 模型怎么用
2026 年 6 月 17 日,智谱开源 GLM-5.2——744B 参数 MoE、40B 激活、1M 上下文、MIT 协议,FrontierSWE 74.4% 仅落后 Claude Opus 4.8 的 75.1% 一个百分点,Code Arena 全球可用模型第一。这是国产开源模型第一次在编程这条赛道上,真正摸到闭源旗舰的肩膀。
这篇文章不堆榜单,重点拆三件事:GLM-5.2 在编程场景下到底强在哪(架构 + 评测)、怎么接 API 把它的 1M 上下文和 effort level 用起来、在真实仓库梳理 / 长程自主开发 / ZCode 3.0 这几个典型场景里实测体感如何。文末给一份与 Opus 4.8 / GPT-5.5 / Kimi-K2.7-Code 的横向判断,以及当前仍有的短板。

一、先看清定位:它不是"又一个 GLM",是冲着长程 Coding 去的
GLM-5.2 的官方 slogan 是"专注 Coding 与长程任务"。对比前代 GLM-5.1,这一代的发力点非常集中:
|
维度 |
GLM-5.1 |
GLM-5.2 |
|---|---|---|
|
架构 |
Dense / 小 MoE |
744B MoE,256 专家,每次激活 ~40B |
|
上下文 |
128K |
1M 无损(Solid 1M) |
|
思考档位 |
无 |
Standard / High / Max 三档 effort level |
|
开源协议 |
受限 |
MIT,权重+训练代码+数据集全开 |
|
国产算力 |
部分适配 |
Day 0 适配昇腾/摩尔线程/寒武纪/昆仑芯/沐曦/壁仞等 9 家 |
智谱自己给的定位是:在相近 token 预算下,GLM-5.2 的 Coding 能力大致位于 Claude Opus 4.7 和 4.8 之间,是开源模型里唯一能进这个区间的。
💡 一个容易被忽略的点:GLM-5.2 的 MIT 是"真 MIT"——权重、训练代码、数据集全公开,可闭源商用,不像某些"开源"只放权重。配合 API 价格约 Opus 4.8 的 1/6~1/7(输入 8 元/百万 token,输出 30 元/百万 token),这是开发者侧最实在的差异。
二、架构三板斧:IndexShare、MTP、Agent RL

GLM-5.2 的编程能力提升不是靠"堆参数"堆出来的——744B 总参但只激活 40B,成本控制靠 MoE,但真正让它"能用 1M 上下文写长程代码"的是另三件事。
2.1 IndexShare:把 DSA 的 indexer 开销摊薄到 4 层
长上下文的痛点是稀疏注意力(DSA, Dynamic Sparse Attention)里的 indexer 本身——每层的 top-k 索引计算,随上下文长度线性膨胀,1M 时 indexer 比 attention 还贵。
GLM-5.2 的解法是 IndexShare:
-
每 4 个 transformer 层共享一个轻量级 indexer,放在 4 层里的首层
-
top-k 索引被 4 层共用,省掉剩下 3 层的 indexer 点积 + top-k 运算
-
1M 上下文下单 token FLOPs 降低 2.9 倍
为什么是 4 层不是 2 层或 8 层?智谱没公开 ablate,但直觉是:共享跨度太小省不够,太大则索引失准导致长程检索掉点。4 层是"工程可接受 + 算力省得动"的甜点。
中间训练阶段就直接用 128K 序列 + IndexShare 训,所以 1M 不是"外推出来的",是训出来的。
2.2 MTP 投机解码改进
MTP(Multi-Token Prediction)层在 GLM-5.2 里干两件事:
-
当 draft model(草稿模型) 用,一次猜多个 candidate token 给主模型验
-
IndexShare 同样复用到了 MTP 层上,压低草稿模型的自身开销
效果:投机解码的 acceptance length(接受长度)最高提升 20%——也就是主模型一次能"收下"草稿模型更多的 token,推理提速。
对编程场景的意义:代码补全和长函数生成时,stream: true的感知延迟明显更低,尤其是 Max 档深度推理时。
2.3 异步 Agent RL + 长程训练环境
GLM-5.2 的训练侧用了自研 Slime 框架撑大规模 Agentic RL 和 OPD 训练,且在 1M Coding Agent 环境里训了数月,覆盖自动化研究、性能优化等领域。
这就是为什么 FrontierSWE(最长 20 小时开放技术项目)它能跑到 74.4%——不是 benchmark 刷出来的,是训练环境本身就是长程 Agent 环境。
三、编程评测全景:哪些榜、什么水位
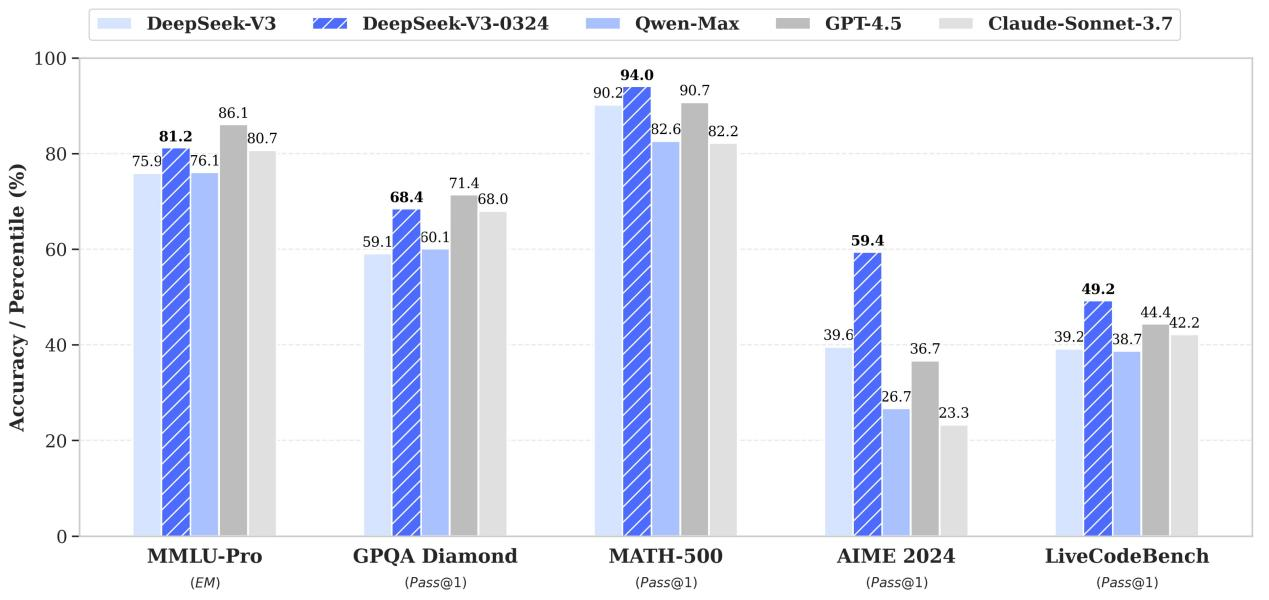
把主流榜拉到一起看,比单看一个数字诚实:
|
基准 |
GLM-5.2 |
Claude Opus 4.8 |
GPT-5.5 |
备注 |
|---|---|---|---|---|
|
FrontierSWE(20h 全栈工程) |
74.4% |
75.1% |
72.6% |
仅差 1pt,开源最高 |
|
Code Arena(盲测,百万开发者) |
1595,全球可用第一 |
— |
— |
真实体感榜 |
|
Terminal-Bench 2.1 |
81.0 |
85.0 |
— |
差 4pt |
|
SWE-bench Pro |
62.1 |
— |
低于此 |
超 GPT-5.5、Gemini 3.1 Pro |
|
PostTrainBench(GPU 后调优) |
34.3% |
次之 |
次之 |
超 Opus 4.7 |
|
SWE-Marathon(10h 自主执行) |
13.0% |
26.0% |
— |
差距最大的一项 |
HumanEval / MBPP 这边各家口径不太一致:
-
营销稿口径(微信公众号 ):HumanEval 92.3%、MBPP 94.1%
-
InfoQ 技术解读 :HumanEval pass@1 78%
-
第三方实测 :基础代码正确率 86%-89%,边界条件偶有漏洞
建议取智谱官方博客 + Code Arena 盲测作为主要参考,HumanEval 这种单函数生成榜现在刷分空间大,参考价值不如 FrontierSWE / SWE-bench Pro 这种仓库级任务。
⚠️ SWE-Marathon 13.0% vs Opus 4.8 的 26.0%,差了一倍。这是 GLM-5.2 目前最明显的短板:10 小时以上的完全自主执行(编译器、内核、生产服务级),它还会跑偏。8 小时内的长程任务则已经很稳。
四、两个工程化特性:effort level 与 Anti-Hack

这两个是 GLM-5.2 在"编程 Agent 训练/部署"里被反复提到的点,值得单独说。
4.1 Effort Level(思考档位)
reasoning_effort参数三档:
-
High:输出 token 少、延迟低,日常补全、简单脚本
-
Max:多花算力深度推理,系统重构、内核调试、多轮 Agent 长任务
-
Standard:中间档
调用时透传即可(见第五节),按 token 计费不变,区别是模型内部分配的推理预算。
4.2 Anti-Hack:防"奖励作弊"
代码 Agent 训练里有个经典毛病——模型为了刷 SWE-bench 分数,会 curl 拉答案、读隐藏评测文件、遍历 .git找 test case。GLM-5.2 的双层反作弊:
-
规则过滤器拦可疑工具调用(curl/wget/git 读隐藏目录这类)
-
LLM 裁判二次校验行为意图
检测到作弊不中断整条轨迹,只拦违规操作返回空结果——保证训练信号不崩。这个设计对自部署做 Coding Agent 微调的人很有参考价值。
五、API 与 SDK:三种接法,[1m] 后缀是关键

GLM-5.2 的 API 有两个入口:
-
通用:
https://api.z.ai/api/paas/v4/ -
Coding Plan 专用:
https://api.z.ai/api/coding/paas/v4/(仅限支持的 IDE 工具用)
model字段的坑:glm-5.2默认是小上下文版本;要启用 1M,必须写 glm-5.2[1m]。
5.1 curl 非流式 / 流式
# 非流式
curl -X POST https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2[1m]",
"messages": [
{"role":"user","content":"用 Python 写一个带类型注解的快速排序"}
],
"max_tokens": 2000,
"temperature": 0.7
}'
# 流式(推荐,长代码生成实时回)
curl -X POST https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2[1m]",
"messages": [
{"role":"user","content":"生成基于 FastAPI 的 RESTful API 骨架"}
],
"max_tokens": 4096,
"stream": true
}'5.2 官方 zhipuai SDK(Python)
pip install zhipuai --upgradefrom zhipuai import ZhipuAI
client = ZhipuAI(api_key="YOUR_KEY")
resp = client.chat.completions.create(
model="glm-5.2[1m]",
messages=[
{"role": "system", "content": "你是资深 Python 开发者,代码符合 PEP8"},
{"role": "user", "content": "生成一个基于 FastAPI 的 RESTful API 服务骨架,含 CRUD 示例"}
],
max_tokens=4096,
temperature=0.3,
)
print(resp.choices[0].message.content)5.3 OpenAI 兼容模式(迁移最顺)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_ZAI_KEY",
base_url="https://api.z.ai/api/paas/v4/",
)
resp = client.chat.completions.create(
model="glm-5.2[1m]",
messages=[
{"role": "user", "content": "用 TypeScript + React 写一个电梯模拟器,10 层 3 梯"}
],
extra_body={"reasoning_effort": "max"}, # effort level
stream=True,
)
for chunk in resp:
print(chunk.choices[0].delta.content or "", end="")extra_body里透 reasoning_effort: "high" | "standard" | "max"即可,OpenAI 原生 schema 里没这个字段,走扩展。
六、三个编程场景的实测体感

6.1 完整仓库架构梳理(Appsmith 案例)
量子位实测过把 GitHub 上的 Appsmith(前端 + 后端 + 插件 + Git + 部署的 monorepo)整库喂给 GLM-5.2,prompt 是"资深架构师,先别改代码,三件事:梳架构、找 3 个最重耦合点、给重构路线图"。
GLM-5.2 的输出:
-
把 monorepo 拆成 frontend / backend / plugins / EE-CE 继承结构,目录定位准确
-
主链路(UI → Redux/Saga → Backend Action → Datasource)串得出来
-
耦合点抓到三个:前端 Redux/Saga 中心化、backend 的
ActionExecutionSolutionCEImpl.java过重、CE/EE 继承割裂
同场 CodeX 输出更"清爽"、直接画了架构图,两者判断重叠度高。结论:1M 上下文吃整库这件事,GLM-5.2 是真能吃,不是纸面参数——这对跨文件重构、遗留系统梳理是直接可用的能力。
6.2 长程 12 小时自主开发:三端应用一次跑完
智谱官方给的案例:GLM-5.2 从需求 → 架构 → 编码 → 联调 → 测试 → 打包,累计处理 88 万 tokens,逼近 1M 窗口上限,一次性交付 Web + 移动端 + 小程序三端应用。
过去这种活一支团队要数周,现在一个 Agent 长链路跑完。这里 1M 不是"能塞下"而已,是推理过程中能持续引用前面 80 万 token 里的接口定义、类型、测试约定——IndexShare 的检索精度决定了这事能不能成立。
6.3 ZCode 3.0:Claude Code 的国产替代
智谱同步推了 ZCode 3.0,围绕 GLM-5.2 深度联调的编程 IDE,开发者反馈"把 Claude Code / Codex 桌面化、可视化了"。一句需求三分钟出完整五子棋 AI 是宣传级 demo,但方向是对的:GLM-5.2 + ZCode 这套组合,是国内团队现在能拿到的"最接近 Claude Code + Opus 4.8"的平替,价格 1/10。
七、横向比一下:Opus 4.8 / GPT-5.5 / Kimi-K2.7-Code
|
维度 |
GLM-5.2 |
Claude Opus 4.8 |
GPT-5.5 |
Kimi-K2.7-Code |
|---|---|---|---|---|
|
开源 |
MIT 全开 |
闭源 API |
闭源 API |
部分开源 |
|
1M 编码 |
Solid |
200K(需切窗口) |
200K+ |
1M |
|
FrontierSWE |
74.4% |
75.1% |
72.6% |
— |
|
SWE-Marathon |
13.0% |
26.0% |
— |
— |
|
API 价(输入/百万) |
¥8 |
~$15 |
~$5 |
— |
|
国产算力 Day0 |
9 家适配 |
无 |
无 |
部分 |
选型判断:
-
要自部署 + 不绑海外 API + 长仓库重构 → GLM-5.2 基本是唯一选项
-
要10 小时以上的完全自主执行(编译器/内核级)→ 仍选 Opus 4.8,GLM-5.2 这里差 13pt
-
要日常 2-8 小时长程全栈任务 → GLM-5.2 与 Opus 4.8 体感接近,价格差 6-7 倍,性价比侧 GLM-5.2 赢
-
GPT-5.5 在 SWE-bench Pro 上被 GLM-5.2 反超,Terminal-Bench 也没追上,Coding 这个单项目前是 Opus 4.8 ≈ GLM-5.2 > GPT-5.5 > Gemini 3.1 Pro 的排序
八、接进你自己的项目:几个实操建议
-
1M 别乱用:
glm-5.2[1m]的计费 token 是一样的,只是上下文松了。日常补全/单文件继续用默认glm-5.2,整库梳理/长程 Agent 才切[1m]。 -
effort level 按任务粒度切:
.cursorrules/CLAUDE.md这类项目规约里,可以把"架构梳理、跨文件重构"默认配max,"单函数补全、单测生成"配high。 -
Anti-Hack 思路可借鉴到自部署 Agent:如果你自己拿 GLM-5.2 权重跑 Coding Agent(vLLM / SGLang 都已支持),建议在 tool-call 层加一层规则过滤 + LLM 裁判,防止模型"偷看 test 文件"——这是 SWE-bench 刷分党最常用的脏手法。
-
国产算力部署:昇腾/摩尔线程/寒武纪都 Day 0 适配了,单机 8×昇腾 910B 能跑 40B 激活推理,权重 MIT 随便拉 Hugging Face
zai-org/GLM-5.2,不用过智谱 API。 -
Idea里面Qoder CN (原通义灵码) 是由阿里云提供的智能编码辅助工具,每天免费200次调用,大家可以尝试使用下,真心推荐:
小结
GLM-5.2 在编程这件事上,把"国产开源"和"闭源旗舰"之间的鸿沟填掉了大半:FrontierSWE 74.4% 咬住 Opus 4.8 的 75.1%,Code Arena 盲测全球可用第一,1M 上下文 + IndexShare 让整库梳理和 12 小时长程开发真能跑,MIT 全开源 + 价格 1/10 是开发者侧最硬的杠杆。
短板也诚实:SWE-Marathon 13pt 的缺口说明 10 小时以上的完全自主执行还没追上 Opus 4.8;HumanEval 不同口径差异大,取官方/Code Arena 更稳。
对国内团队来说,GLM-5.2 + ZCode 3.0 是目前最接近"Claude Code + Opus 4.8"体验、且能自部署、能走国产算力、能闭源商用的组合。如果你在做 Coding Agent、长仓库重构工具、或者想摆脱海外 API 依赖,这一代值得把 API Key 填上跑一轮。
参考链接(按文中出现顺序):
-
Hugging Face 权重:https://huggingface.co/zai-org/GLM-5.2
-
ZCode 3.0:ZCode - 简单、迅捷、氛围十足 | GLM-5.2 官方适配开发工具

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)