
《Claude Code 工程化实战》第 3 讲 CLAUDE.md 记忆系统
📌 本讲摘要
本讲是"记忆层"的第一讲、核心目的是把"Claude Code 没记忆、所以每次都从零开始"这个根本问题讲透。Claude Code 的记忆系统由四个层级组成、按优先级从低到高是:用户级(
~/.claude/CLAUDE.md)、项目级(./CLAUDE.md)、本地级(./CLAUDE.local.md)、规则目录(./.claude/rules/*.md)。高层级覆盖低层级同名内容、合并后的总 prompt 在每次启动 Claude Code 时自动注入上下文。本讲的三条主线:第一、“为什么要分四级?”——它们对应"个人偏好 / 团队规范 / 个人项目笔记 / 分类规则"四种不同的治理粒度、单一文件无法同时满足。第二、“CLAUDE.md 应该写什么?”——四条原则:精简(CLAUDE.md 本身吃 token)、具体(不要写"代码要规范"、要写"用 ruff 强制 line-length=100")、回答 WHY/WHAT/HOW、使用渐进式披露(主体精简、细则下沉到 rules/)。第三、“怎么避免把记忆写崩?”——给出一组反例 vs 正例、以及"每周五下午 5 点审查一次 CLAUDE.md"的可执行节奏。
学完本讲、你应该能为自己的项目写出一份 200 行内、覆盖"项目目标 / 技术栈 / 代码风格 / 禁区 / 常用命令"五大要素的 CLAUDE.md、并能用
claude --debug看到它真的被加载了。
📖 详细内容
为什么 Claude Code 需要"记忆"?
这是一个看似废话、实则核心的问题。Claude Code 的本质是一个无状态的 LLM 调用包装器:每次你启动 claude、它读到的"世界"就是"当前目录的文件 + 你的 prompt"、没有"上次我们聊到哪了"的概念。你在周一告诉它"我们这个项目用 uv 管理依赖、不用 pip"、到了周三它已经忘了——你必须再说一遍。
这就是 CLAUDE.md 存在的原因。它是 Claude Code 的"项目入职文档"、在每次启动时自动加载到 system prompt。效果上、它把 Claude Code 的"每次重置"变成"每次都从入职第一天读起"、从而让 LLM 的"无状态"特性不再是个缺陷。
很多团队低估了这件事的工程意义。一个 5 万行代码的微服务项目、新人(包括 AI)需要消化的隐含信息包括:用了什么 ORM、单元测试用什么框架、哪个目录是给财务团队保留的、PR 必须跑通哪些检查、commit message 怎么写……这些信息如果靠每次对话口述、既慢又容易漏。CLAUDE.md 一次性沉淀、每次都生效。
从工程治理角度、CLAUDE.md 还有一个隐含价值:它把"项目惯例"从"老员工的脑子里"外化到"机器可读的文本"、新人(包括 AI)不再需要"师徒制"才能学会。文档化本身就是治理。
四级记忆层级:从个人偏好到分类规则
Claude Code 的记忆不是单一文件、而是四个层级的文件树。它们按加载顺序(低优先级先加载、高优先级后加载、可覆盖低优先级)组成最终注入上下文的 system prompt:
层级 1:用户级 (~/.claude/CLAUDE.md)
位置在用户家目录下、跨项目生效。典型的内容:个人编码偏好(“我偏好 type hint 优先于 docstring”)、个人快捷命令(“请用 ripgrep 不用 grep”)、个人禁区(“不要替我发邮件、推 git”)。这是你作为"独立开发者"的偏好、不带项目属性。
治理粒度: 全局。一般 50-200 行就够、超过 500 行就该拆。
层级 2:项目级 (./CLAUDE.md)
位置在项目根目录、与代码一起提交到 git。典型内容:项目目标、用户画像、技术栈、目录结构、代码风格、PR 流程、禁区(“不要碰 src/billing/”)、常用命令(测试、lint、build)。这是"项目 DNA"、新人(包括 AI)读完就能上手。
治理粒度: 团队共享。必须 commit 到 git、所有协作者都受益。
层级 3:本地级 (./CLAUDE.local.md)
位置也在项目根目录、但加入 .gitignore、不进版本库。典型内容:本机特有的路径(“我的 dev DB 在 localhost:5433、不是默认端口”)、个人项目笔记(“我刚发现 fastapi 的一个边界行为、记住一下”)、调试用提示(“现在在排查 race condition、所有改动都跑 3 次”)。
治理粒度: 个人、只对本机有效。适合临时性、个人性的项目笔记。
层级 4:规则目录 (./.claude/rules/*.md)
位置在 .claude/rules/ 目录下、按主题拆成多个 .md 文件。典型拆分:rules/python-style.md(PEP 8 细则)、rules/db-migration.md(迁移流程)、rules/security.md(安全审计清单)、rules/api-design.md(RESTful 规范)。每个文件可以加 frontmatter 声明生效条件(比如"只在 src/api/ 下生效")。
治理粒度: 主题分类。当 CLAUDE.md 主体超过 300 行时、就该拆出 rules/。
| 层级 | 位置 | 进 git? | 典型内容 | 行数建议 | 加载优先级 |
|---|---|---|---|---|---|
| 用户级 | ~/.claude/CLAUDE.md |
n/a(在家目录) | 个人编码偏好、个人快捷命令、个人禁区 | 50-200 | 最低 |
| 项目级 | ./CLAUDE.md |
✅ 必入 | 项目目标、技术栈、目录结构、代码风格、禁区、常用命令 | 100-300 | 中 |
| 本地级 | ./CLAUDE.local.md |
❌ 必须 gitignore | 本机特殊路径、个人项目笔记、调试上下文 | 20-100 | 中 |
| 规则目录 | ./.claude/rules/*.md |
✅ 必入(分类版) | 按主题拆分的细则(数据库迁移、错误处理、安全、API 风格) | 每个 50-200 | 追加到末尾 |
合并规则与优先级
四级从低到高合并:用户级 → 项目级 → 本地级 → 规则目录。同名配置项、本地级覆盖项目级、项目级覆盖用户级。规则目录的所有 .md 文件按文件名排序后追加到末尾。最终的合并结果会作为 system prompt 的一部分、在每次启动 Claude Code 时注入到上下文窗口。
可以用 claude --debug 命令查看实际的合并结果(详见实战代码段)。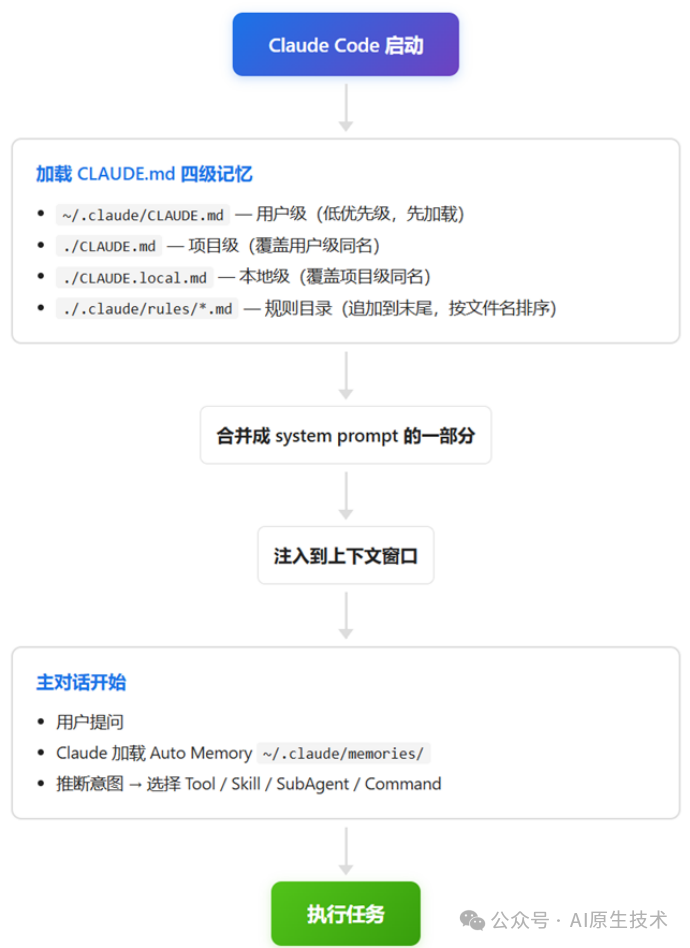
CLAUDE.md 的编写原则:四条铁律
CLAUDE.md 不是写得越多越好。Claude Code 的上下文窗口是有限的(默认 200K tokens、但每次对话都会消耗),CLAUDE.md 本身占用的部分就是"机会成本"——你写 1000 行的 CLAUDE.md、意味着留给真正对话的空间少了 1000 行对应的容量。原则有四条:
原则 1:精简
能 50 行讲清楚的事不要写 200 行。每个项目 CLAUDE.md 在 100-300 行之间最佳;超过 500 行就该拆出 rules/。精简的方法:用列表不用段落、用代码块不用描述、只写"AI 不知道的事"(AI 已经知道 Python 怎么写、不需要你再说一遍)。
原则 2:具体
不要写"代码要规范"、要写"用 ruff,line-length=100、启用 isort"。不要写"测试要全面"、要写"pytest、覆盖率门槛 80%、新代码必须 100%“。越具体、AI 越不需要猜。判断标准:把这条规则删掉、AI 会犯什么错?如果会犯具体可描述的错、就保留;如果只是"更好"而非"必须”、就删掉。
原则 3:回答 WHY/WHAT/HOW
好的 CLAUDE.md 不仅是"做什么"、还包括"为什么"。例:“我们用 uv 不用 poetry(because:uv 比 poetry 快 10 倍、CI 节省 3 分钟/次)”。AI 知道 WHY 后、在边缘情况下能自己判断;只知道 WHAT 时、遇到规则没说的情况就会乱猜。
- WHAT: 具体行为(用什么工具、跑什么命令、禁止什么操作)。
- WHY: 行为背后的原因(为什么不用 poetry、为什么不让 AI 碰 src/billing/)。这让 AI 在"规则没说"的情况下仍能做出合理判断。
- HOW: 执行细节(具体命令、具体参数、具体路径)。
原则 4:渐进式披露
CLAUDE.md 主体只写"最高频 20% 的规则"、剩下的 80% 拆到 rules/ 或外部文档(用"参见 docs/xxx.md"引用)。Claude Code 支持"按需加载":它会根据当前任务自动决定要不要读 rules/ 下的某个文件、而不需要你每次手动指定。
渐进式披露的实现要点:CLAUDE.md 主体不超过 300 行;每条 rules/*.md 控制在 50-200 行;用清晰的文件名让 AI 一眼看出"这个 rules 文件管什么"(比如 rules/db-migration.md 比 rules/rules1.md 好);rules 文件首行用一句话说明"本文件何时被加载"。
一个反例 vs 一个正例
看一个真实项目中常见的"错误"CLAUDE.md:
# 项目说明
这是一个 Web 项目。请写好代码,注意测试,做好文档。
## 技术
- 后端:Python
- 前端:React
- 数据库:PostgreSQL
## 注意事项
- 注意性能
- 注意安全
- 注意代码质量
这个 CLAUDE.md 等于没写。它只告诉了 AI"这项目用 Python"(AI 看 requirements.txt 就知道了)、其他全是空话。AI 看完后行为不会有任何变化。
同一个项目的"正确"CLAUDE.md:
# CLAUDE.md —— OrderFlow 订单系统
## 项目目标
OrderFlow 是 B2B 订单流转系统,服务 200+ 中小电商客户,日均处理 50K 订单。
核心约束:**订单一旦支付,不能丢**。
## 技术栈
- Python 3.12 + FastAPI 0.115
- PostgreSQL 15(主库)+ Redis 7(缓存/锁)
- SQLAlchemy 2.0(async)+ Alembic 迁移
- 前端:React 18 + TypeScript 5(由前端组维护,不要碰)
- 部署:Kubernetes + ArgoCD
## 目录结构(只列"AI 经常动"的)
- src/orders/ # 订单核心逻辑
- src/payments/ # 支付集成(高风险,改动前必须 review)
- src/billing/ # 财务(交给财务组,**绝对禁区**)
- migrations/ # Alembic 迁移
- tests/unit/ # 单元测试
- tests/integration/ # 集成测试
## 代码风格
- ruff(line-length=100,target-version=py312)
- mypy strict 模式
- 优先 type hint 优先于 docstring
- 公开函数必须有 docstring(Google 风格)
## 禁区(碰之前先问)
- src/billing/ 整个目录(财务组专用)
- 任何修改 migrations/ 已发布文件的 PR(必须新建迁移文件)
- 涉及 user_pii 字段的代码改动(隐私合规)
## 常用命令
- 跑测试: `make test`(等价于 pytest -x --cov=src --cov-fail-under=80)
- 跑 lint: `make lint`(等价于 ruff check . && mypy src)
- 起 dev: `docker compose up -d && uvicorn src.main:app --reload`
- 跑迁移: `alembic upgrade head`(永远不要手动改 migrations/ 里的文件)
## 渐进式披露:详细规范按主题拆分
- 数据库迁移规范:见 [rules/db-migration.md](.claude/rules/db-migration.md)
- 错误处理规范:见 [rules/error-handling.md](.claude/rules/error-handling.md)
- 安全审计清单:见 [rules/security.md](.claude/rules/security.md)
两份 CLAUDE.md 字数相近(都约 100 行)、但后者让 AI 的行为产生 10 倍差异:它知道项目的"绝对禁区"、知道测试覆盖率门槛、知道迁移文件不能手动改。这些都是"不写出来 AI 就会犯的错"。
| 原则 | 反例 | 正例 |
|---|---|---|
| 精简 | 800 行的 CLAUDE.md、什么都写 | 200 行主体 + 拆出 rules/ |
| 具体 | “代码要规范” | “用 ruff,line-length=100、启用 isort” |
| WHY/WHAT/HOW | “我们用 uv” | “我们用 uv 不用 poetry(uv 比 poetry 快 10 倍、CI 节省 3 分钟/次)” |
| 渐进式披露 | 所有规则挤在 CLAUDE.md 主体 | 主体写高频 20%、细则在 rules/ 按需加载 |
Auto Memory:跨会话的自动记忆
CLAUDE.md 是"显式"记忆——你写什么它记什么。但还有一种"隐式"记忆:Auto Memory。当 Auto Memory 开启时、Claude Code 会在以下场景自动写一条记忆到 ~/.claude/memories/:
- 场景 1: 你纠正了 Claude 的错误(“不对、这里用 uv 不用 poetry”)——Claude 会自动写一条"项目用 uv 不用 poetry"到记忆库。
- 场景 2: Claude 重复犯了同一个错——会自动写一条"以后处理 X 任务时、先做 Y"作为提醒。
- 场景 3: 你让 Claude 长期跟踪某个项目——Claude 会写"用户正在做 Z 项目、关注点包括 A/B/C"。
Auto Memory 的本质是"LLM 自我反省的副产品"——它把"我之前犯过这个错"沉淀成可复用的记忆。但要注意:Auto Memory 是"基于概率"的、不是 100% 准确。AI 可能会记住错的偏好(比如你某次临时用了 pip、它会记住"用户偏好 pip")。所以关键性规则必须显式写在 CLAUDE.md 里、不要依赖 Auto Memory。
建议:Auto Memory 当作"草稿本"用、关键规则显式写 CLAUDE.md。两层都启用、效果最好。
记忆系统与其他模块的关系
CLAUDE.md 不是孤立的、它和后续模块深度耦合。理解这些耦合能帮你避免"单点失败":
与 SubAgents 的关系
SubAgent 会继承主对话加载的 CLAUDE.md、除非子代理目录里有自己的 CLAUDE.md(子代理级的覆盖主对话)。所以:写子代理时、在子代理目录放一份"子代理专用"的 CLAUDE.md、比让主 CLAUDE.md 写得很长更好。
与 Rules 的关系
Rules 是 CLAUDE.md 的"分类版"。CLAUDE.md 写主体、Rules 写细则。两者都进 system prompt。区别:Rules 支持 frontmatter 声明生效条件(“只在 src/api/ 下生效”),CLAUDE.md 不支持。
与 Skills 的关系
Skills 的 description 字段会引用 CLAUDE.md 里的项目背景(比如"用 uv 不用 poetry")。CLAUDE.md 写清楚了、Skill 的 description 才能写准确。
与 Hooks 的关系
Hooks 经常需要读 CLAUDE.md 来"理解项目"(比如 PreToolUse 拦截"修改 src/billing/"就需要 CLAUDE.md 声明这个目录是禁区)。
这个关系链意味着:CLAUDE.md 写错了、会污染下游所有模块;CLAUDE.md 写好了、下游模块的描述/配置都可以更精简。第 3 讲看似只是"一个文件"、实际上是"整个工程治理的根"。
🛠️ 实战代码
📄 第 3 讲配套:一个真实可用的 CLAUDE.md 最小完整版
# CLAUDE.md —— <项目名>
## 1. 项目目标
- 服务谁:<用户群体>
- 解决什么问题:<一句话核心价值>
- 关键约束:<3-5 条不可妥协的约束,例如"数据不能丢"/"延迟必须 < 100ms">
## 2. 技术栈
- 语言:<版本>
- 框架:<核心框架 + 版本>
- 数据库:<主库 + 缓存>
- 部署:<运行环境>
## 3. 目录结构(只列"AI 经常动"的)
- src/<module1>/ # <职责>
- src/<module2>/ # <职责>
- src/<禁区>/ # <为什么是禁区>
## 4. 代码风格
- linter:<工具名 + 关键配置>
- formatter:<工具名 + 关键配置>
- type checker:<严格程度>
- 命名约定:<几条最重要的>
## 5. 禁区(碰之前先问)
- <目录/文件 1>:<为什么>
- <操作类型 1>:<为什么>
## 6. 常用命令
- 跑测试:`<命令>`
- 跑 lint:`<命令>`
- 起 dev:`<命令>`
- 跑迁移:`<命令>`
## 7. 渐进式披露
- 详细规范见 [.claude/rules/](.claude/rules/)
- API 文档见 [docs/api.md](docs/api.md)
📄 第 3 讲配套:验证 CLAUDE.md 真的被加载了
# 方法 1:用 --debug 启动 Claude Code,看实际注入的 system prompt
claude --debug
# 启动后看输出里的"system prompt"部分,
# 应该能看到你的 CLAUDE.md 内容被合并注入
# 方法 2:在对话里直接问 Claude
# > 请告诉我,你读到了几个 CLAUDE.md?分别是什么内容?
# Claude 会列出它加载的所有 CLAUDE.md(用户级/项目级/本地级)
# 方法 3:用 /memory 命令(如果版本支持)
# > /memory
# Claude 会展示当前会话加载的所有记忆文件路径
# 方法 4:把"加载验证"作为 CLAUDE.md 自身的一部分
# 在 CLAUDE.md 末尾加:
# ## 自检
# 每次启动时,在第一条响应里报告:你读到了哪些 CLAUDE.md? 来自哪几个层级?
📄 第 3 讲配套:CLAUDE.local.md 的典型场景
# CLAUDE.local.md —— 只在本机生效,不入 git
## 本机特殊配置
- 数据库:localhost:5433(不是默认 5432,因为我本地有旧项目占用了 5432)
- Redis:localhost:6380
- 测试用的 S3 mock 在 ~/mock-s3/
## 当前调试上下文
- 正在排查订单超时的 race condition
- 涉及文件:src/orders/timeout.py、src/payments/callback.py
- 改了之后跑 `make test-orders` 3 次,确认无 flaky
## 个人偏好
- 解释代码时,先用一句话说意图,再贴代码
- 不要主动加我不需要的 type hint
- 涉及 SQL 的改动,先列 SQL 再写 Python
📄 第 3 讲配套:用 Rules 拆分类规范
# 在项目根目录建分类规则目录
mkdir -p .claude/rules
# 按主题拆 CLAUDE.md 里的细则
touch .claude/rules/db-migration.md
touch .claude/rules/error-handling.md
touch .claude/rules/security.md
touch .claude/rules/api-design.md
touch .claude/rules/frontend-style.md
---
# .claude/rules/db-migration.md
# 加载条件:任何涉及 migrations/ 目录或 alembic 命令的任务
---
# 数据库迁移规范
## 绝对禁止
- 不要手动修改已经合并到 main 的迁移文件
- 不要在迁移里写数据回填(SQLAlchemy 迁移应该只改 schema)
## 正确流程
1. 新建迁移: `alembic revision --autogenerate -m "add user_phone"`
2. 在 upgrade()/downgrade() 里只写 schema 变更
3. 数据回填单独写一个一次性脚本
4. 跑 `alembic upgrade head` 验证
5. PR 标题前缀:`[migration]` 方便 reviewer 识别
⚠️ 常见坑
⚠️ CLAUDE.md 写成"百科全书"
最常见的错误:把 CLAUDE.md 当成项目文档、什么都往里塞——架构图、API 列表、数据库 schema、部署流程……结果一个 CLAUDE.md 写了 1000 行、占满了上下文窗口、真正对话的空间被挤掉。判断标准:CLAUDE.md 超过 500 行就该拆。CLAUDE.md 写的应该是"AI 不知道就会犯的错"、不是"项目的所有信息"。
⚠️ 写"模糊规则"
“注意代码质量”、“测试要全面”、“考虑性能”——这类规则等于没写。AI 读完不知道该做什么具体动作。规则必须具体到"可执行":工具名、参数、阈值、具体行为。判断标准:把这条规则给一个新来的 AI 工程师、他能立刻知道"下一步做什么"吗?如果不能、就是模糊规则。
⚠️ CLAUDE.local.md 不加 .gitignore
本地级记忆包含本机特有的路径(“我的 dev DB 在 localhost:5433”)、调试上下文、个人偏好——这些信息提交到 git 会污染团队。其他协作者拉下来会看到一堆"和我无关"的配置、甚至和他们的环境冲突。务必在 .gitignore 里加
CLAUDE.local.md。这是团队协作的硬规矩。
⚠️ 写完不更新
CLAUDE.md 不是写一次就完事。项目在演化:新框架、新禁区、新命令。如果 CLAUDE.md 三个月没更新、它就已经是"历史档案"而不是"项目 DNA"了。建议:每周五下午 5 点、花 15 分钟审查 CLAUDE.md——删掉过时的、补上新的、合并重复的。让 CLAUDE.md 保持"当下有效"的状态。
💡 一句话备忘
CLAUDE.md 是项目的"宪法":写得短而精、胜过写得长而空。下游所有模块的整洁、都依赖这一份文件的克制。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 5
5 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)