
34.开源 vs 闭源:Llama / Qwen / DeepSeek 生态博弈
开源 vs 闭源:Llama / Qwen / DeepSeek 生态博弈
《大模型知识与部署》系列 · No.34 / 35
适合人群:技术决策者、AI 工程师、投资人
阅读时间:约 25 分钟
写在前面
系列前 33 篇我们讲的都是技术——架构、训练、部署、应用。这一篇换个视角,聊产业:
开源大模型 vs 闭源大模型,谁会赢?
这个问题没有标准答案,但 2026 年的格局已经比 2023 年清晰得多。回顾几个关键节点:
2022.11 ChatGPT ── 闭源开局
2023.02 LLaMA-1 ── 开源被迫加入
2023.07 Llama 2 ── 商用开源
2024.03 Claude 3 / GPT-4 Turbo ── 闭源 SOTA
2024.04 Llama 3 ── 开源追上 GPT-3.5
2024.12 DeepSeek V3 ── 开源接近 SOTA
2025.01 DeepSeek R1 ── 开源推理震撼业界
2025.夏 Llama 4 / Qwen3 ── 开源持续推进
2026.中 Claude 4.7 / GPT-5 ── 闭源仍领先
2026.末 下一代 DeepSeek / Qwen ── ?
如果你做过相关工作,下面这些问题应该不熟:
- 开源和闭源的差距到底有多大?
- 我的业务该选开源还是闭源?怎么决策?
- 中国大模型为什么是开源主力?
- 开源真的能持续追上闭源吗?
- 下一波颠覆会从哪里来?
读完本文你将能:
- 看懂 2026 年大模型产业格局
- 给业务做"开源 vs 闭源"理性决策
- 理解中美大模型路线的不同
- 预判未来 2-3 年的演变
我们开始。
一、2026 年大模型产业格局
1.1 主要玩家分类
┌────────────────────────────────────────┐
│ 闭源旗舰 │
│ ├─ OpenAI(GPT-5, o3) │
│ ├─ Anthropic(Claude 4.7) │
│ ├─ Google(Gemini 2.5 Pro) │
│ └─ xAI(Grok 3) │
├────────────────────────────────────────┤
│ 开源旗舰 │
│ ├─ Meta(Llama 4) │
│ ├─ 阿里(Qwen3 系列) │
│ ├─ DeepSeek(V3 / R1) │
│ ├─ Mistral(Mixtral / Magistral) │
│ ├─ 智谱(GLM-4.5) │
│ ├─ Microsoft(Phi 系列) │
│ └─ Google(Gemma 3) │
├────────────────────────────────────────┤
│ 半开源(权重不开源但 API 商业) │
│ ├─ Cohere │
│ ├─ Reka │
│ └─ AI21 │
└────────────────────────────────────────┘
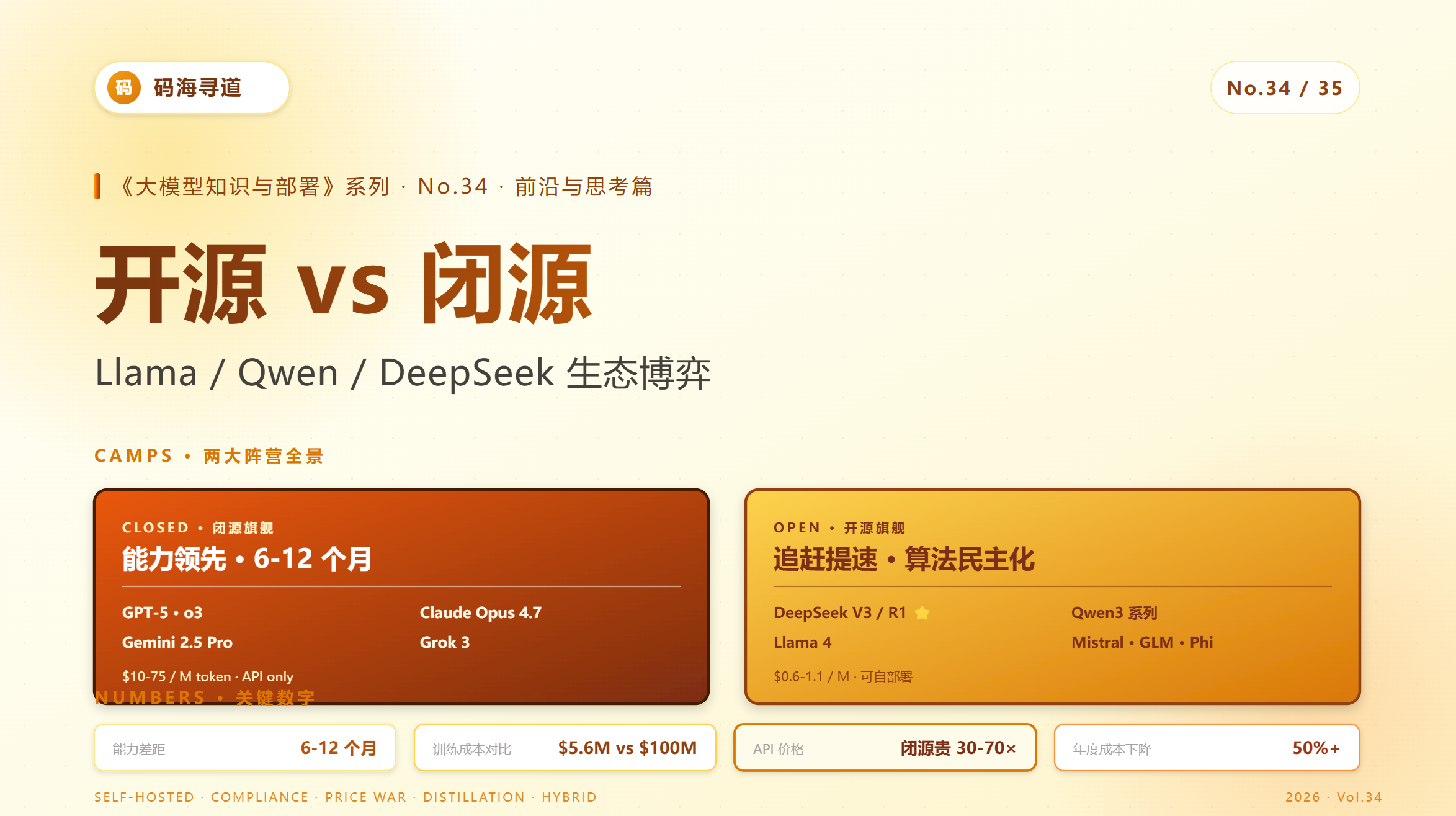
1.2 能力对比(2026.05)
我们用统一 benchmark(MMLU-Pro、GPQA、SWE-Bench、AIME)对照:
| 模型 | 综合能力 | 开源? | 价格(输出) |
|---|---|---|---|
| GPT-5 | 100(基准) | ❌ | $40/M |
| Claude Opus 4.7 | 99 | ❌ | $75/M |
| Gemini 2.5 Pro | 96 | ❌ | $10/M |
| DeepSeek V3 / R1 | 92 | ✅ | API $1.1/M |
| Qwen3-Max | 90 | △(部分) | - |
| Llama 4 405B | 87 | ✅ | 自部署 |
| Mixtral 8x22B | 80 | ✅ | 自部署 |
关键观察:
- 闭源仍领先:约 6-12 个月差距
- 开源差距在缩小:从 2023 年 24 个月缩到 6-12 个月
- DeepSeek 是开源逼近 SOTA 的核心
- 价格差异巨大:闭源贵 30-70×
1.3 关键时间线
能力等价 差距
GPT-3.5 ─── Llama 1 12 个月
GPT-4 ─── Llama 3 12 个月
GPT-4o ─── Qwen2.5 6 个月
o1 ─── DeepSeek R1 4 个月 ⭐ 创纪录
Claude 4 ── DeepSeek V4 ?? ?
追赶速度持续加快——这是开源派最大的信心来源。
二、闭源派的优势
2.1 能力上限
闭源始终保持 6-12 个月领先。原因:
- 更强的训练算力:OpenAI、Google 拥有数万张 H100/B200
- 更优的数据:闭源训练数据保密 + 优质
- 更深的人才:顶级研究员集中
- 更长的迭代经验:从 GPT-2 到 GPT-5
2.2 工程化程度
闭源 API 的工程化远超开源自部署:
| 维度 | 闭源 API | 开源自部署 |
|---|---|---|
| SLA | 99.9%+ | 看团队 |
| 全球加速 | ✅ | 自建 |
| 限流 + 计费 | 完善 | 自建 |
| 安全过滤 | 完善 | 自建 |
| 多模态 | 完整 | 部分 |
| 长上下文质量 | 高 | 中 |
| Tool Use | 高 | 中 |
2.3 用户体验
- 延迟稳定:CDN 全球加速
- 新功能首发:computer use、推理模型、视频生成
- 生态集成:Cursor、ChatGPT、Claude.ai 等强体验
2.4 闭源派的代表
OpenAI
- 优势:先发 + 生态 + 推理模型(o 系列)+ Computer Use
- 劣势:价格高 + 数据合规问题
Anthropic
- 优势:Claude Code + Agent + 安全性
- 劣势:相对较小 + 价格高
- 优势:长上下文 + 多模态 + 价格亲民 + 训练算力(TPU)
- 劣势:文字质量略弱(在追赶)
xAI
- 优势:实时数据 + 算力规模(10 万卡集群)
- 劣势:模型质量追赶中
三、开源派的崛起
3.1 为什么开源能追上
原因 1:算法民主化
DeepSeek V3 / R1 把训练方法完全公开——任何团队都能复现:
- MLA + MoE 架构
- DualPipe 训练
- FP8 训练
- GRPO 强化学习
- Auxiliary-loss-free 负载均衡
开源不只是给权重,是把"配方"也给出来。
原因 2:成本下降
- DeepSeek V3 用 557 万美元做出顶级模型
- 对比 GPT-4 训练成本 ~$100M
- 成本差 20×——任何有训练算力的团队都能做
原因 3:中国生态
中国开源大模型成为生力军:
- DeepSeek:性价比 + 推理模型
- 阿里 Qwen:中文最强 + 全系列
- 智谱 GLM:稳定 + 企业级
- 百川 / 月之暗面 / 零一:各有特色
中国团队不藏私——这是开源能持续追上的关键。
原因 4:合成数据 + 蒸馏
Phi / DeepSeek-R1-Distill 证明:
- 用 GPT-4 / Claude 的输出蒸馏小模型
- 小模型能力快速接近大模型
闭源大模型反而成了开源的"老师"。
3.2 开源派的代表
Meta(Llama)
- 优势:生态最广 + 商用 License
- 劣势:训练数据偏英文 + 大投入但增量贡献慢
阿里(Qwen)
- 优势:中文最强 + 全系列尺寸(0.5B 到 110B)+ 多模态
- 劣势:海外认可度不及 Llama / DeepSeek
DeepSeek
- 优势:算法创新 + 极致性价比 + 推理模型先驱
- 劣势:团队小 + 推出节奏慢于大厂
Mistral
- 优势:欧洲合规 + MoE 设计成熟
- 劣势:中文一般 + 商业产品化弱
微软(Phi)
- 优势:小模型最强 + 端侧友好
- 劣势:大模型不参与
四、开源 vs 闭源的工程化决策
4.1 决策矩阵
| 业务特征 | 推荐 |
|---|---|
| 数据合规严格(金融、医疗、政企) | 开源自部署 |
| 快速迭代验证 | 闭源 API |
| 小流量 / MVP | 闭源 API |
| 大流量 ToC(月费 > $50K) | 开源自部署 |
| 极致能力需求 | 闭源(Claude / GPT-5) |
| 中文场景 | 开源 Qwen / DeepSeek |
| 代码 / 数学 | DeepSeek R1 / Claude |
| 长上下文 | Gemini / Claude |
| 多模态 | GPT-5 / Gemini |
| 预算极有限 | DeepSeek API / 自部署 Qwen |
| 国产化合规 | Qwen / DeepSeek + 910C |
4.2 不同行业的实战选择
互联网公司
原型期:Claude / GPT API
大流量:自部署 Qwen / DeepSeek
关键场景:Claude / GPT API + 自部署混合
金融机构
合规要求高 → 自部署
首选:Qwen3-72B / DeepSeek V3(国产合规)
不能用闭源 API(数据不出域)
政企
强制国产化 → 自部署
首选:Qwen / DeepSeek + 910C 硬件
软件栈:vLLM / SGLang 国产分支
创业公司
< 100 万 ARR → 全 API(闭源 / DeepSeek API)
100 万 - 1000 万 → 混合(闭源 + 自部署)
1000 万+ → 自部署为主
4.3 一个被忽视的事实:API 也是「半开源」
很多人不知道:
- DeepSeek API 价格比自部署还便宜
- Qwen API 在阿里云上比自部署成本更低(中小流量)
- 闭源 API 中 Gemini Flash 也极便宜
结论:
“开源 vs 闭源"不等于"自部署 vs API”。
开源模型也能用 API(如 DeepSeek API),闭源模型只能 API。决策时要双维度考虑。
五、中美大模型路线分化
5.1 美国路线
特点:
- 闭源旗舰为主:OpenAI / Anthropic / Google
- 大算力堆叠:B200 集群、千亿美元投入
- 生态主导:ChatGPT / Claude / Gemini App
- 商业模式:API + 订阅 + 企业服务
关键玩家:
- 巨头:OpenAI、Anthropic、Google、Meta
- 算力:NVIDIA、Broadcom、AMD
- 应用:Cursor、Replit、Perplexity、Notion
5.2 中国路线
特点:
- 开源为主:Qwen / DeepSeek / GLM / Llama 中文化
- 算力受限:H100 出口管制 + 国产卡崛起
- 应用爆发:通过 API 价格战推广
- 商业模式:低价 API + 企业定制 + 国产化合规
关键玩家:
- 模型:阿里、DeepSeek、智谱、月之暗面、百川、字节豆包
- 算力:华为昇腾 910C、寒武纪、海光
- 应用:通义、文心、KiMi、豆包、智谱清言
5.3 关键差异
| 维度 | 美国 | 中国 |
|---|---|---|
| 主流模式 | 闭源 | 开源 |
| 价格 | 高 | 极低(价格战) |
| 训练算力 | 充足(B200) | 受限(H100/国产卡) |
| 数据 | 英文为主 | 中文优势 |
| 推理模型 | o3 等 | DeepSeek R1 等 |
| 商业化 | API + 订阅 | 多元(含国产合规) |
5.4 为什么中国是开源主力
几个非技术原因:
- 算力限制反推算法创新(DeepSeek 路线)
- 没有 OpenAI 这种"绝对领先者" → 大家平等竞争
- 国产化政策驱动 → 开源便于内部使用
- 市场分散 → 没有形成 OpenAI 式垄断
六、未来 2-3 年走向
6.1 趋势 1:差距继续缩小
预判:
- 2026 末:开源差距 4-6 个月
- 2027:开源差距 < 6 个月成为常态
- 2028:某次开源可能反超(如 DeepSeek R3)
关键变量:
- 训练算力的开放程度
- 算法是否继续公开
- 国产硬件能否支持训练大模型
6.2 趋势 2:垂直化分工
- 闭源:聚焦顶级能力 + Agent + Computer Use
- 开源:聚焦自部署 + 垂直行业 + 端侧
6.3 趋势 3:API 价格战继续
2023:GPT-4 输出 $60/M
2024:GPT-4o $15/M
2025:DeepSeek V3 $1.1/M
2026:Gemini 2.5 Flash $0.6/M
预计:单位智能成本年降 50%+
结果:
- 闭源 API 价格被拉下来
- 自部署的"成本临界点"被推高
- 越来越多业务"全用 API"
6.4 趋势 4:MoE / 推理 / 端侧 三大方向
未来 2-3 年大模型架构创新主要在:
- MoE:模型容量与算力分离
- 推理模型:Test-Time Scaling
- 端侧:小模型 + 蒸馏
开源在这三个方向都不落后。
6.5 趋势 5:智能基础设施重构
2023:拼参数
2024:拼上下文 + 多模态
2025:拼推理
2026:拼 Agent + Computer Use
2027 预计:拼模型 + 世界模型(physical AI)
2028 预计:??
每一代都有新维度。开源闭源博弈也会随之演变。
七、不同角色的应对策略
7.1 AI 工程师
- 必须双修:闭源 API + 开源自部署都要会
- 关注算法创新:MoE、推理、Agent
- 保持灵活:避免锁死一家
- 建立评估能力:能客观评测各模型
7.2 技术决策者
- 混合架构:不要 ALL-IN 一家
- 国产备份:海外服务断供风险考虑
- 关注成本曲线:每年成本降 50% 是设计前提
- Pilot 多家:保持选项
7.3 创业公司
- 早期用 API:聚焦产品 + 用户
- 中期监控成本:评估自部署临界点
- 数据资产化:自有数据 + 微调是壁垒
- 不要做基础模型:除非有顶级团队
7.4 投资人
- 底层模型:寡头 + 国家队
- 基础设施:vLLM、向量库、Agent 框架等仍有机会
- 垂直应用:法律、医疗、教育、金融
- 端侧 + 实体:机器人、AR 眼镜等新形态
八、争议话题
8.1 开源真的"完全开放"吗?
很多"开源"模型其实有限制:
- Llama:>700M 用户的公司不能商用
- 部分模型:训练数据不公开
- 部分模型:权重开源但不允许蒸馏
真正完全开源:MIT / Apache 2.0 协议(如 Qwen3、DeepSeek)。
8.2 蒸馏是不是"偷"
OpenAI 在 2025 年起强调"不允许用 GPT 输出训练竞品"。但实际上:
- 用闭源生成 SFT 数据已经普遍
- 难以技术上完全防止
- 法律边界仍在博弈中
8.3 闭源会赢吗
悲观派认为:
- 顶级研究员都在闭源公司
- 算力差距会拉大
- 闭源会用 Computer Use 等高门槛能力拉开
乐观派认为:
- 开源已经追到 4-6 个月差距
- 中国不断推出新创新
- 商业上闭源价格战难持续
我的判断:
未来 5 年是「开源闭源共存」——各有不可替代的场景。完全替代不会发生。
九、下一篇预告
第 35 篇:大模型安全 - 越狱、提示注入与防御(系列收官)
我们整个系列以"安全"作结——这是大模型工程化绕不开的最后一道关卡。包括:
- 越狱攻击与防御
- Prompt Injection
- 数据泄漏风险
- Agent 时代的新威胁
- 红队测试
- 监管现状
读完最后一篇,整个 35 篇系列正式收官!
结语:开源闭源博弈是 AI 产业的「常态」
读完本文你应该明白:
- 闭源仍领先 6-12 个月,但差距持续缩小
- DeepSeek 算法公开是开源追赶的关键
- 中国是开源主力——非技术因素叠加
- API 价格战还会持续——每年降 50%+
- 混合架构是 2026 年标配:API + 自部署
- 不要 ALL-IN 一家:模型 / 厂商 / 路线都要备份
- 未来 5 年开源闭源共存
下一篇我们继续,也是最后一篇:
- 第 35 篇:大模型安全 - 越狱、提示注入与防御 —— 系列收官!
我们下篇见。
📮 关于「码海寻道」
这里是一个聚焦 AI 工程化、大模型部署、后端架构实战的技术专栏。
写最一线的踩坑经验,做最务实的技术拆解。如果这篇文章对你有启发,欢迎点赞、转发、关注。我们下篇见。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)