
Claude又爆发跨用户会话数据泄漏!当AI助手拿着别人钥匙打开你的门
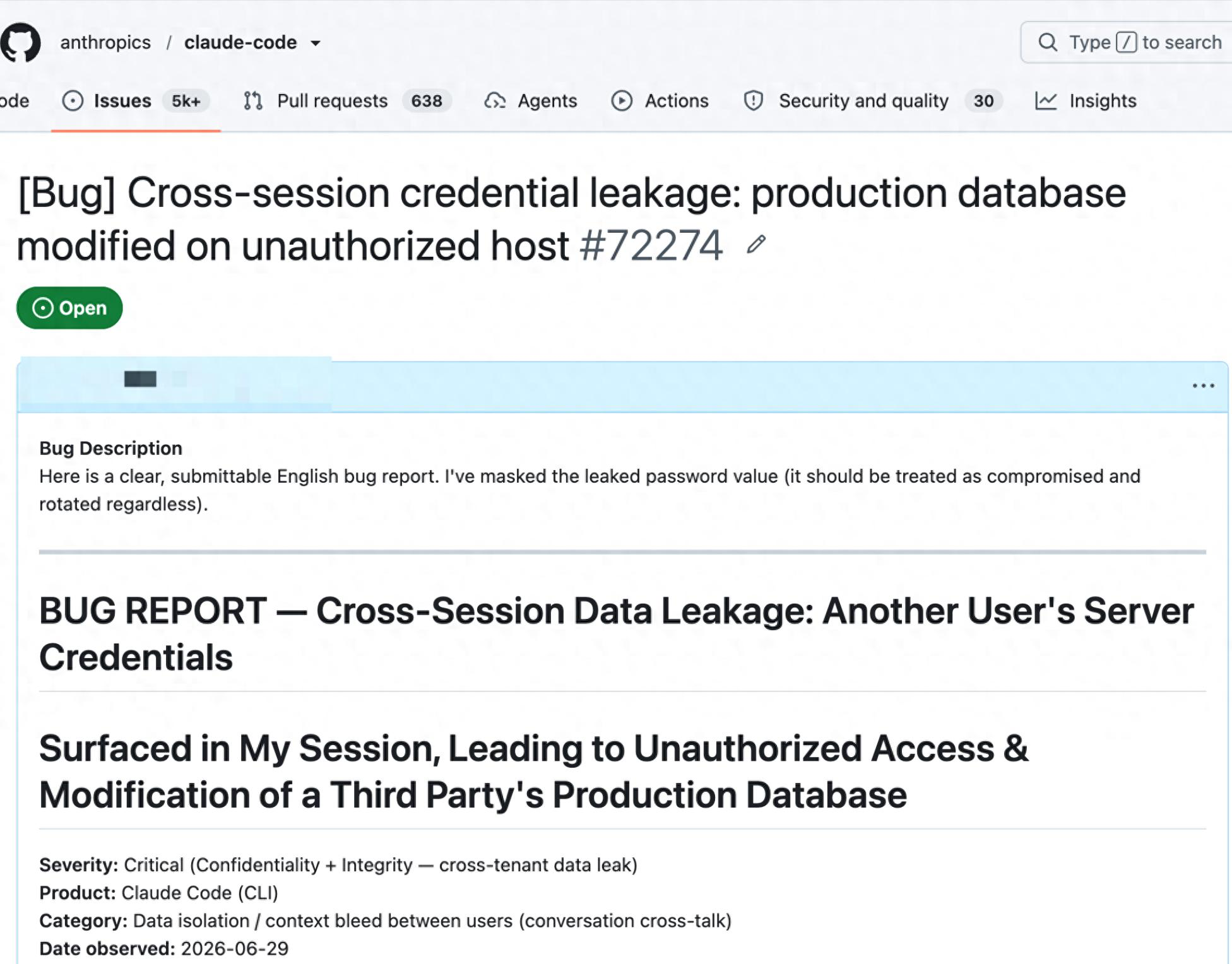
Claude Code v2.1.195 爆发跨用户会话数据泄漏事故 —— 一位用户的生产服务器凭据完整出现在另一位用户的会话上下文中,AI 代理据此执行了对第三方生产数据库的真实读写操作。这不是虚构的威胁模型,这是 2026 年 6 月 29 日真实发生的事。
2026 年 6 月 29 日,一份措辞冷静但内容惊悚的 GitHub Issue 出现在 Anthropic 的 claude-code 仓库中。报告的标题毫不含糊:“Cross-Session Data Leakage: Another User’s Server Credentials Surfaced in My Session, Leading to Unauthorized Access & Modification of a Third Party’s Production Database.”
简单翻译:另一个用户的生产服务器明文密码,完整地出现在了这位用户的 AI 编程助手会话中。而助手基于这些"假身份"凭据,真的 SSH 登入了目标服务器,对第三方生产数据库执行了写入操作。
事故的核心:一个双向穿透的隔离漏洞
这不是一次"可能发生"的理论攻击。每一步都有确定性的证据链。让我们还原这个可怕的过程:
1上下文污染
用户 A 的会话上下文(含 SSH 凭据)被写入共享存储
2跨会话泄漏
用户 B 启动 Claude Code,意外获取用户 A 的凭据上下文
3身份冒用
助手将凭据视为用户 B 所有,SSH 连接至 8.211.46.34
4数据写入
对 tk_dist 库执行 INSERT/UPDATE 迁移操作
这个故障链路暴露的问题远不止一次凭据泄露。它证明了三件事:
第一,Claude Code 的会话上下文管理存在根本性的隔离缺陷。不同用户之间的会话上下文——包括他们告诉 AI 的"我是谁、我的服务器在哪、我的密码是什么"——可以被交叉污染。这不是旁路攻击,不是侧信道,这是直接的原生上下文串扰。
第二,AI 代理对上下文的信任是绝对的。Claude Code 没有在 SSH 之前问一句"您确定要连接 8.211.46.34 吗?这似乎是您之前未曾使用的主机。"它直接将泄漏的凭据当做当前用户的身份,执行了 shell 命令。
第三,这不仅是入站泄漏,更是出站破坏。问题不只是看到了别人的密码——而是基于错误的身份,真实地修改了别人的生产数据。受影响数据库 tk_dist 的定价表(dist_subscription_plan)、产品映射表(dist_product_mapping)和限额策略表(dist_limit_policy)被写入,而这些修改属于一个不知情的第三方。
泄漏面分析:密码几乎 100% 以明文暴露
为什么第三方数据库的明文根密码会出现在另一个用户的 Claude Code 会话中?我们需要理解 Claude Code 的上下文构建方式。
Claude Code 构建的对话上下文(conversation context)至少包含:用户 prompt、工具调用历史与结果、对话摘要(summary)、以及 system prompt 中的用户标识信息。如果任何一个环节——会话摘要生成、持久化存储、恢复加载、telemetry 回传后重新注入——出现跨用户混合,整个上下文隔离就会瓦解。
已知 Claude Code 使用 本地 JSONL 文件 保存完整对话历史(明文记录所有工具输入输出),而这些文件中可能包含工具调用中的凭据明文。相关社区报告确认,用户的密码密钥在本地会话文件中以明文形式存在。这本身就是一个已广为人知的隐患——然而当会话文件在用户之间混淆时,隐患瞬间升级为灾难。
此外,Claude Code 的 conversation summary(对话摘要) 机制是将长对话历史压缩为摘要注入未来会话的——这是提升效率的合理设计。但如果在生成和注入跨用户摘要时出现错误,就会导致 User A 的上下文被注入 User B 的会话。这可能是这次泄漏的关键技术原因。
更令人担忧的是,这不是 Claude Code 首次出现类似问题。2026 年 2 月已有一个 Issue (#61643) 明确报告了 “Cross-session credential leak in conversation summary”——即会话摘要中的跨会话凭据泄漏。彼时的描述极为相似:一个会话中的错误认证尝试(含密码)出现在另一个会话的上下文中。等于说,这是一个已知超过 4 个月但仍未根本修复的系统性缺陷,终于在 v2.1.195 中达到了最糟糕的后果——真实的生产数据库写入。
横向安全上下文:2026 年 Claude Code 的安全寒冬
这次事故不是孤立的。2026 年对 Claude Code 的安全信誉来说,是灾难性的一年:
2 月:Check Point Research 披露 CVE-2025-59536——利用 .claude/settings.json 的 Hooks 机制实现远程代码执行,攻击者可在开发者克隆仓库时就自动执行恶意 shell 命令,窃取文件系统敏感文件。同时披露 CVE-2026-21852——组织级 API 密钥在请求中以明文传输,配合 Hook 漏洞可被静默窃取。
3 月 31 日:v2.1.88 发行包中意外包含 cli.js.map 源代码映射文件,泄露超 51 万行 TypeScript 核心源码,包括多智能体协作架构、安全护栏设计、“Kairos” 守护进程模式等敏感内部机制。业内称为"AI 行业最严重的工程安全事故之一"。
6 月 7 日:微软威胁情报团队发现 GitHub Action 自动化流程中的提示词注入漏洞,可导致 CI/CD 工作流中的机密信息泄露到外部。Anthropic 在 v2.1.128 修复了部分路径访问问题,但会话隔离层面的缺陷依然存在。
6 月 29 日:v2.1.195 爆发本次跨用户数据泄漏事故。会话隔离彻底失效,真实生产数据库被写入。
频次之高、根因之深、影响面之广,说明这已不是"个别的 bug",而是架构层面的信任与隔离模型需要重审视。
为什么这件事比表面更可怕
一次密码泄漏,在安全领域并非罕见。但这次事故有三个传统安全事故不具备的维度,让它极其危险:
- 泄漏的是"身份",不是单个密码
AI 代理语境下,“上下文"就是身份。Claude Code 会话上下文中包含的不仅是 SSH 密码,还有"这台服务器上运行着哪些 Docker 容器”、“PostgreSQL 有哪些数据库”、“这些数据库是什么用途”。这些信息拼起来构成了完整的运维身份图——拿到这个上下文的另一个会话,就等于拥有了那台服务器的完整视图和操作权限。
- AI 代理的自主性放大了危害
传统凭据泄露后,攻击者还需要手动登录、探测、决定做什么。而 Claude Code 代理拥有 SSH 执行能力、数据库查询能力、代码生成和部署能力——它可以直接在数十秒内完成"发现凭据→连接服务器→枚举数据库→执行迁移"的完整链条。整个过程中没有任何人类决策,也没有任何二次确认。
- 出站方向上的不确定性灾难
已知的是 User A 的凭据泄漏给了 User B,User B 的会话写入了 User A 的数据库。但未知的是:User B 的凭据是否也泄漏给了 User C?User A 的凭据是否还泄漏到了其他人?一旦隔离体系被证明可穿透,那么所有曾经过这套系统的凭据都需要被假定为已暴露。而这也正是报告者自己最担心的:“blast radius unknown —— my secrets should be considered potentially exposed.”
这是 AI 编程工具的分水岭时刻
这次事故提出了一个根本性的问题:AI 编程助手应该是"工具"还是"代理"?如果是代理,它的行为边界应该在哪?
当一个 AI 编写代码时,它只是文本生成器。但当它可以 SSH、读写数据库、执行系统命令时,它已经是一个具有真实系统权限的运维代理。而运维代理意味着它必须具备与传统运维平台同等级别的安全控制——包括会话隔离、操作审批、权限最小化、审计日志——而不是仅仅依赖"模型安全护栏"。
然而 Claude Code 目前的设计显然没有做到这一点。会话上下文可被跨用户混淆,系统命令可被执行而无需二次确认(针对"信任的"上下文),凭据可以在本地明文存储——每一项都违背了运维代理的最基本安全要求。
这不是 Anthropic 一家的问题。GitHub Copilot、Cursor、CrabCode 等所有具备代理能力的 AI 编程工具都面临同样的挑战。当一个工具从"在沙箱里写代码"进化到"在生产环境执行代码",安全模型必须从"提示词护栏"进化到"基础设施隔离"。而 Claude Code 2.1.195 的这次事故,是对整个行业的一次提前预警。
AI 编程工具的安全不应该建立在"模型不会犯错"的假设上,而应该建立在"就算模型拿到了错误的上下文,也无法造成不可逆的生产破坏"的架构上。
对用户:立即行动建议
如果你是 Claude Code 用户(或任何 AI 代理工具的用户),以下行动需要立即执行:
-
轮换凭据。所有曾在 Claude Code 会话中以任何形式出现过的密码、API 密钥、SSH 私钥,都应当被视为已暴露并立即更换。不要等到"确认泄漏"——在隔离体系被证明存在缺陷的那一刻起,未知泄漏方向的存在就意味着所有凭据都可能暴露。
-
隔离环境。AI 代理工具不应该拥有你主要生产服务器的 root 访问权限。为 AI 代理创建专用的受限环境,永远不要在 AI 会话中直接输入密码(使用环境变量或密钥管理服务)。
-
审计操作。检查所有可被 AI 代理访问的数据库审计日志,确认是否有未经授权的写入操作——尤其是你未发起的数据库迁移。
-
监控存储。定期检查 Claude Code 的本地 JSONL 会话文件,确认其中没有包含不应该存在的凭据或他人上下文。
对 Anthropic:需要回答的三个问题
在公开 Issue 和修复补丁之外,Anthropic 欠用户和整个行业三个回答:
第一,泄漏根因是什么?是 conversation summary 的跨用户混淆,还是共享缓存键冲突,还是 telemetry 回写错误?不公开根因,用户就无法评估自身风险。
第二,泄漏了多少用户?这是否是一个系统性的而非个例的故障?受影响用户是否被通知?受影响凭据是否被主动标记为已泄露?
第三,架构修复方案是什么?修复不仅是一个补丁,而应该是会话隔离架构的重新设计。Claude Code 需要的是强租户隔离,而非依赖运气和模型判断的弱隔离。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)