
立刻检查你的Codex!隐形 SSD 杀手:OpenAI Codex CLI 日志 Bug 深度解析与自查指南
隐形 SSD 杀手:OpenAI Codex CLI 日志 Bug 深度解析与自查指南
一个看似无害的 SQLite 日志文件,可能正在悄悄“烧穿”你的固态硬盘。
⚡️ 一键临时止血(先退出 Codex 再执行)
如果你只想立刻阻止 Codex 继续磨损你的 SSD,先完全退出 Codex 进程,然后将下面整段命令粘贴到终端执行(适用于 macOS / Linux):
DB="$HOME/.codex/logs_2.sqlite"
# 1. 备份(带时间戳)
cp "$DB" "$DB.bak.$(date +%Y%m%d%H%M%S)"
cp "$DB-wal" "$DB-wal.bak.$(date +%Y%m%d%H%M%S)" 2>/dev/null || true
cp "$DB-shm" "$DB-shm.bak.$(date +%Y%m%d%H%M%S)" 2>/dev/null || true
# 2. 创建拦截触发器,静默丢弃所有新日志写入
sqlite3 "$DB" "CREATE TRIGGER IF NOT EXISTS codex_block_logs_insert BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE); END;"
# 3. 清空并截断 WAL 文件
sqlite3 "$DB" "PRAGMA wal_checkpoint(TRUNCATE);"
echo "止血完成。如果返回 0|0|0,说明 WAL 已清空。"
Windows 用户请参考正文中的手动步骤,或使用 WSL 执行上述命令。
执行完毕后,Codex 将不再向 logs 表写入任何新日志。这仅是本地临时方案,会彻底禁用该数据库的日志记录,但能立刻停止对 SSD 的异常磨损。 后续请务必升级到官方修复版本并删除触发器(命令见正文)。
下面,我们详细拆解这个 Bug 的来龙去脉、危害原理以及完整的手动修复与验证过程。
最近,OpenAI 的终端 AI 编程工具 Codex CLI 被曝出一个堪称“硬件杀手”级别的 Bug:它会在后台以 每秒约 5MB 的速度疯狂写入日志,而表面文件大小却毫无异常。按此速率,一年累计写入量可达 640TB,足以在不到一年内耗尽一块普通消费级 NVMe 固态硬盘的全部写入寿命。更令人不安的是,这个问题自今年 4 月起就已存在,直到近期才因社区用户的精确量化报告而引爆舆论。
今天这篇文章,带你彻底搞懂这个 Bug 的来龙去脉、为什么它能骗过那么多开发者,以及你该如何立刻自查并紧急止血。
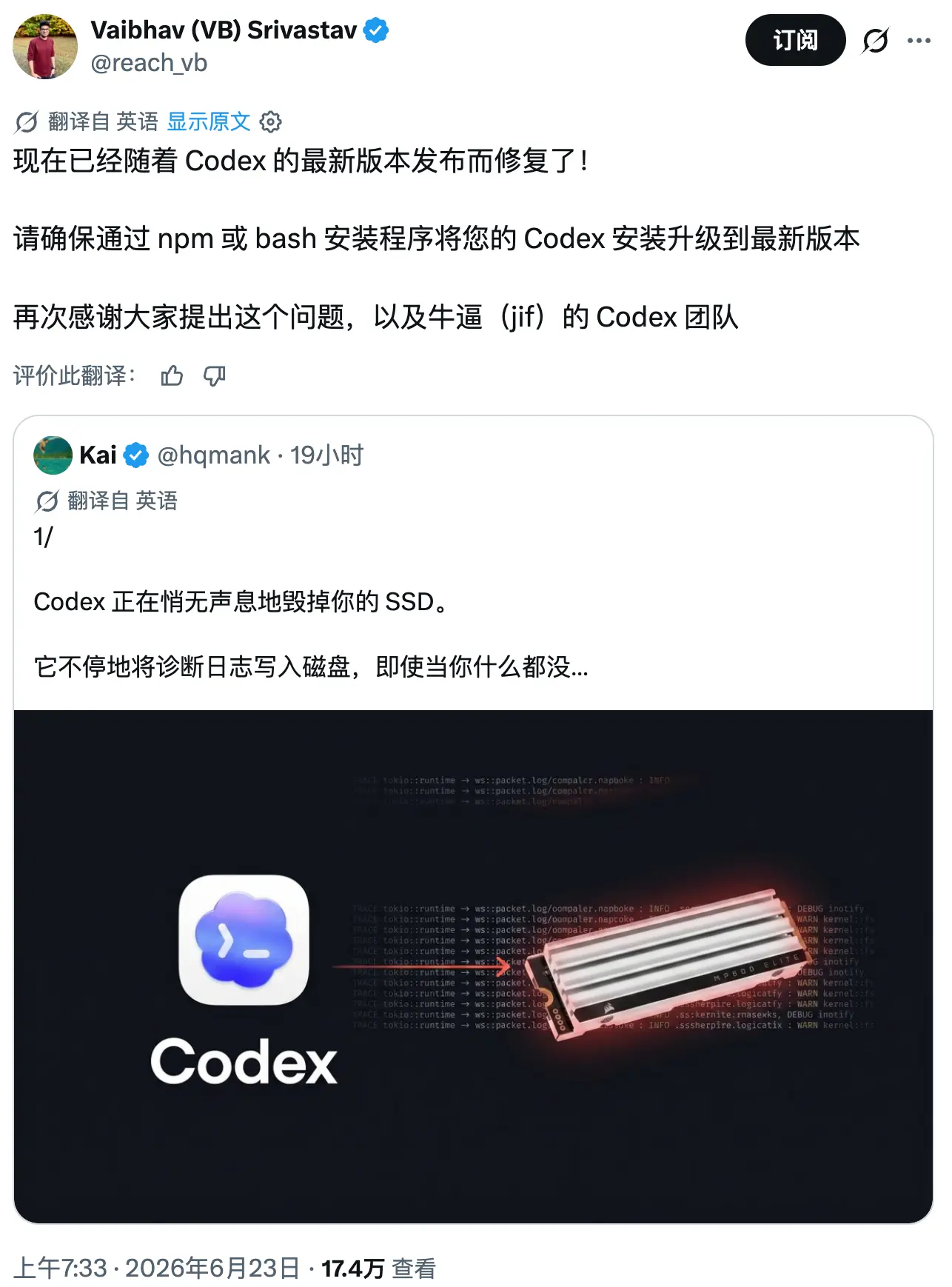
一、Bug 从何而来?——被遗忘的 TRACE 级别
Codex CLI 在运行时,会将诊断日志记录到本地的一个 SQLite 数据库文件 ~/.codex/logs_2.sqlite 中。问题的根源在于,该日志系统被 硬编码为 TRACE 级别。
TRACE 是日志体系中最为详尽的等级,它会事无巨细地记录几乎所有底层事件:原始的 WebSocket 数据包、系统文件(如 passwd、ld.so.cache)的打开事件、内部状态变更等等。据分析,这个设置是在某个 PR 中为方便内部调试而引入的,却在未做任何调整的情况下直接推送给了所有终端用户。
更糟糕的是,Codex 完全忽略了标准环境变量 RUST_LOG,这意味着用户没有任何简单的官方途径来调低日志级别,只能眼睁睁看着它疯狂写盘。
二、为什么你很难察觉到?——“文件不大,但路已跑烂”
当听到“疯狂写盘”时,很多人的第一反应是去查看文件大小。结果发现:
- 文件才几百 MB,好像没事?
- 日志行数没涨,好像没事?
- 磁盘剩余空间没少,好像也没事?
这正是该 Bug 最阴险的地方。 Codex 的日志系统采用的不是简单的追加写入,而是一个持续「写入 → 删除 → 再写入」的循环模式:每分钟执行数万次 INSERT 和 DELETE 操作。表面上,数据库文件大小和记录行数保持稳定;但在这平静的表象之下,SSD 的实际写入量(TBW,Total Bytes Written)正在飞速累积。
打个比方:
- 文件大小好比停车场里此刻停了多少辆车。
- TBW 则是这条路上从早到晚一共跑过了多少辆车。
一个程序反复写入、删除、整理数据库的 WAL(Write-Ahead Log,预写日志),最后文件可能还是那几百 MB,但 SSD 的闪存颗粒已经被反复擦写了无数轮。SQLite 的 WAL 机制还会造成写入放大——每次事务不仅要写主数据库,还要写 WAL 文件和回滚日志,进一步加剧了磨损。
衡量一下这个写入量的实际意义:一块典型的 1TB 消费级 NVMe SSD,其 TBW 额定值通常在 600TB 左右。Codex 以 5MB/s 基线写入(峰值可达 16MB/s),一年下来足以让它寿终正寝。而 SSD 寿命耗尽的表现往往不是缓慢降速,而是可能突然变为只读模式或彻底无法识别,导致数据丢失。
三、立刻自查:你的 SSD 中招了吗?
我让 Codex 自查了一次自己的 SQLite 日志写盘 bug。提示词很简单:
“帮我检查 ~/.codex/logs_2.sqlite 是否因 TRACE 日志持续高频写盘;如果中招,先备份,再用 SQLite trigger 拦截 logs 表 insert,并 checkpoint/truncate WAL,最后采样确认 MAX(id) 和 WAL 不再增长。”

无论你是否感觉到了系统变慢,只要近期高频使用过 Codex CLI,都建议立即做一次快速诊断。
macOS / Linux 检测命令
在终端中依次执行:
DB="$HOME/.codex/logs_2.sqlite"
# 1. 查看文件大小及 WAL 文件状态
ls -lh "$DB" "$DB-wal" 2>/dev/null
# 2. 查看 logs 表当前总行数(COUNT) 与 历史最大写入序号(MAX(id))
sqlite3 "$DB" "SELECT COUNT(*), MAX(id) FROM logs;"
# 3. 按日志级别分类统计(看 TRACE 是否占大头)
sqlite3 "$DB" "
SELECT level, COUNT(*)
FROM logs
GROUP BY level
ORDER BY COUNT(*) DESC;
"
Windows 路径与检测方法
Windows 下的路径类似,一般为 %USERPROFILE%\.codex\logs_2.sqlite。你可以用类似逻辑在 WSL 或安装了 sqlite3 的环境下进行检查,或使用 GUI 工具打开数据库执行上述 SQL。
重点观察信号(隔30秒再查一次)
连续执行两次,对比变化。如果看到以下现象,请高度警惕:
COUNT(*)基本没变,但MAX(id)持续上涨logs_2.sqlite-wal文件的修改时间和大小不断变化TRACE级别的日志数量占绝对大头- 日志内容中包含大量 SSE / WebSocket / streaming 等高频事件
关键解读:
COUNT(*)是当前还剩多少行,MAX(id)是曾经写到第几条。如果行数稳定但 ID 一直涨,说明系统在背后不断“写入一批 → 删除一批 → 再写入”,这正是本 Bug 的典型特征。
四、紧急止血:本地临时修复方案
在 OpenAI 官方修复完全推送到你使用的版本之前,可以手动“阉割”掉这个有害的日志写入。操作前请务必完整退出 Codex 进程。
1. 备份日志数据库(以防万一)
DB="$HOME/.codex/logs_2.sqlite"
cp "$DB" "$DB.bak.$(date +%Y%m%d%H%M%S)"
cp "$DB-wal" "$DB-wal.bak.$(date +%Y%m%d%H%M%S)" 2>/dev/null || true
cp "$DB-shm" "$DB-shm.bak.$(date +%Y%m%d%H%M%S)" 2>/dev/null || true
2. 创建拦截触发器,静默丢弃所有新日志写入
sqlite3 "$HOME/.codex/logs_2.sqlite" "
CREATE TRIGGER IF NOT EXISTS codex_block_logs_insert
BEFORE INSERT ON logs
BEGIN
SELECT RAISE(IGNORE);
END;"
这个触发器会让任何尝试插入 logs 表的操作都无提示地被忽略。
3. 清理并截断 WAL 文件
sqlite3 "$HOME/.codex/logs_2.sqlite" "PRAGMA wal_checkpoint(TRUNCATE);"
正常情况下会返回 0|0|0,表示 WAL 已被成功清空。
4. 再次采样验证效果
DB="$HOME/.codex/logs_2.sqlite"
sqlite3 "$DB" "SELECT COUNT(*), MAX(id) FROM logs;"
stat "$DB-wal" 2>/dev/null
sleep 30
sqlite3 "$DB" "SELECT COUNT(*), MAX(id) FROM logs;"
stat "$DB-wal" 2>/dev/null
如果 30 秒后 MAX(id) 不再增长,WAL 文件未再更新,则说明止血生效。
如何恢复日志写入?
如果后续排查需要日志,可随时删除触发器:
sqlite3 "$HOME/.codex/logs_2.sqlite" "DROP TRIGGER IF EXISTS codex_block_logs_insert;"
注意: 这个临时方案会让 Codex 此后完全不写 logs 表。若你需要利用本地诊断日志,请慎用,优先升级到已修复的官方版本。
五、官方修复与社区迂回方案
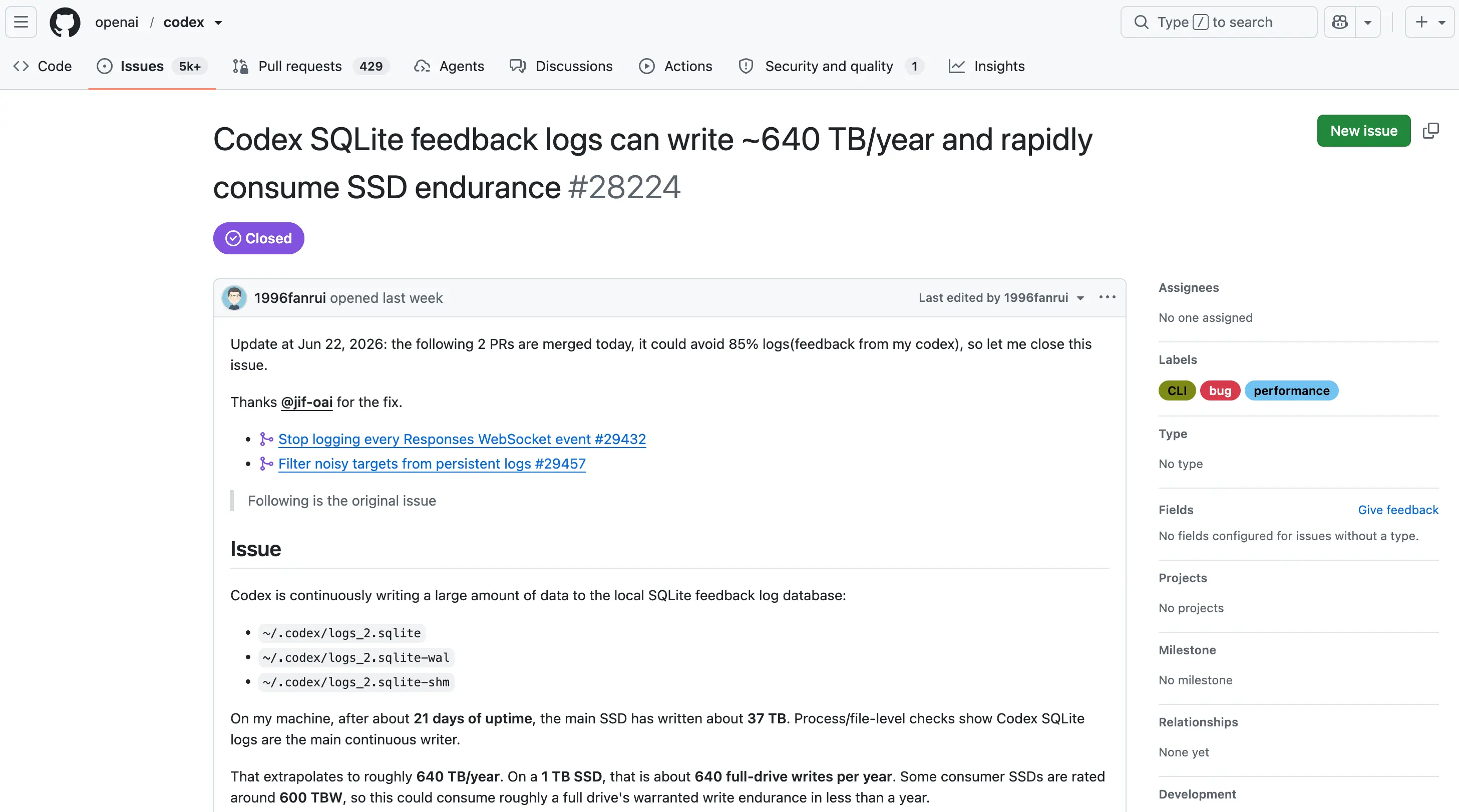
OpenAI 响应较快,已通过合并 PR #29432 和 #29457,将 SQLite 日志默认级别从 TRACE 降至 INFO,据称可减少约 85% 的日志写入量。所有用户应尽快升级到最新版 Codex CLI。
在补丁推送期间,社区还摸索出一个更彻底的应急方案:将 logs_2.sqlite 软链接到 /tmp。因为多数 Linux/macOS 系统的 /tmp 挂载为 tmpfs(内存文件系统),写入不会触碰物理硬盘,且该文件不包含用户对话数据,重启丢失无任何影响。不过,这仍是权宜之计,根治还得靠官方升级。
六、更深层的警示:当 AI 助手拥有“写盘自由”
这次事件暴露的远不止是一个配置失误。它提醒我们:
随着 AI 编码助手深度嵌入日常开发环境,它们获得的系统权限和数据访问范围正在急剧扩大。 一个普通的代码编辑器不会以每秒 5MB 的速度向你的磁盘写入数据,但一个需要监听文件变化、建立代码索引、记录 WebSocket 通信的 AI 代理,实际上已成为系统中最活跃的进程之一。
尤其在 Codex 的 /goal 模式下,它拥有完整的文件系统读写权限和自主决策能力。一个日志级别的配置错误,就足以让一个旨在提升效率的工具,悄无声息地变成硬件寿命的终结者。这为所有 AI 工具开发者敲响了警钟:权限越大,对底层资源(尤其是不可再生的硬件寿命)的敬畏之心就应当越强。
最后,再次提醒每一位 Codex 重度用户:现在就花 2 分钟自查一下,你的 SSD 可能正在被看不见的“日志风暴”磨损。 别等数据丢失再后悔。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)