
Claude Science 让实验笔记本成为产品,Sciverse 要做的是它背后的科学证据数据层
导语
Claude Science 最值得关注的地方,不是 Claude 又会了一点科学,而是它把科研工作流产品化了:数据、代码、计算、图表、论文、审稿意见和溯源记录必须连成一条链。问题也随之出现:这样的科学工作台,底层需要什么样的数据基础设施?我的判断是,它需要的不是更多搜索接口,而是一层统一治理过的、可被 Agent 直接消费的科学证据数据层。
正文
Claude Science 的真正信号:实验笔记本正在变成产品
如果把 2026 年 6 月 30 日开放测试的 Claude Science 只看成“一个更懂科学的 Claude”,就低估了它的产品含义。
它更像是一本新型实验笔记本:研究人员提出问题,系统连接数据库,调用代码环境,运行分析,生成图表,保存产物,并把自然语言解释、代码、环境、文件和对话记录放进同一条工作链路里。
这件事的重点不是“AI 能不能回答生物学问题”。通用模型早就能生成看起来合理的解释。真正关键的是:当研究人员要从原始数据走到图表、手稿和审稿意见时,每一步能不能留下可检查的记录。
这也是 Claude Science 这类产品带来的行业信号:
科研 AI 的竞争,正在从“谁更会回答”转向“谁能把可信数据、专业工具、计算资源、溯源记录和人类判断连成工作流”。
但这也暴露出一个更底层的问题:如果下游工作台要连接 60 多个科学数据库,要调用不同 subagent 处理论文、基因组、蛋白质、分子、图表、PDF 和代码,那么它不可能长期靠每个 Agent 自己临时拼接数据源。
它需要一个被统一接入、统一治理、统一结构化、统一证据化的数据层。
这就是 Sciverse 可以切入的位置。
Claude Science 是下游工作台,Sciverse 是上游证据
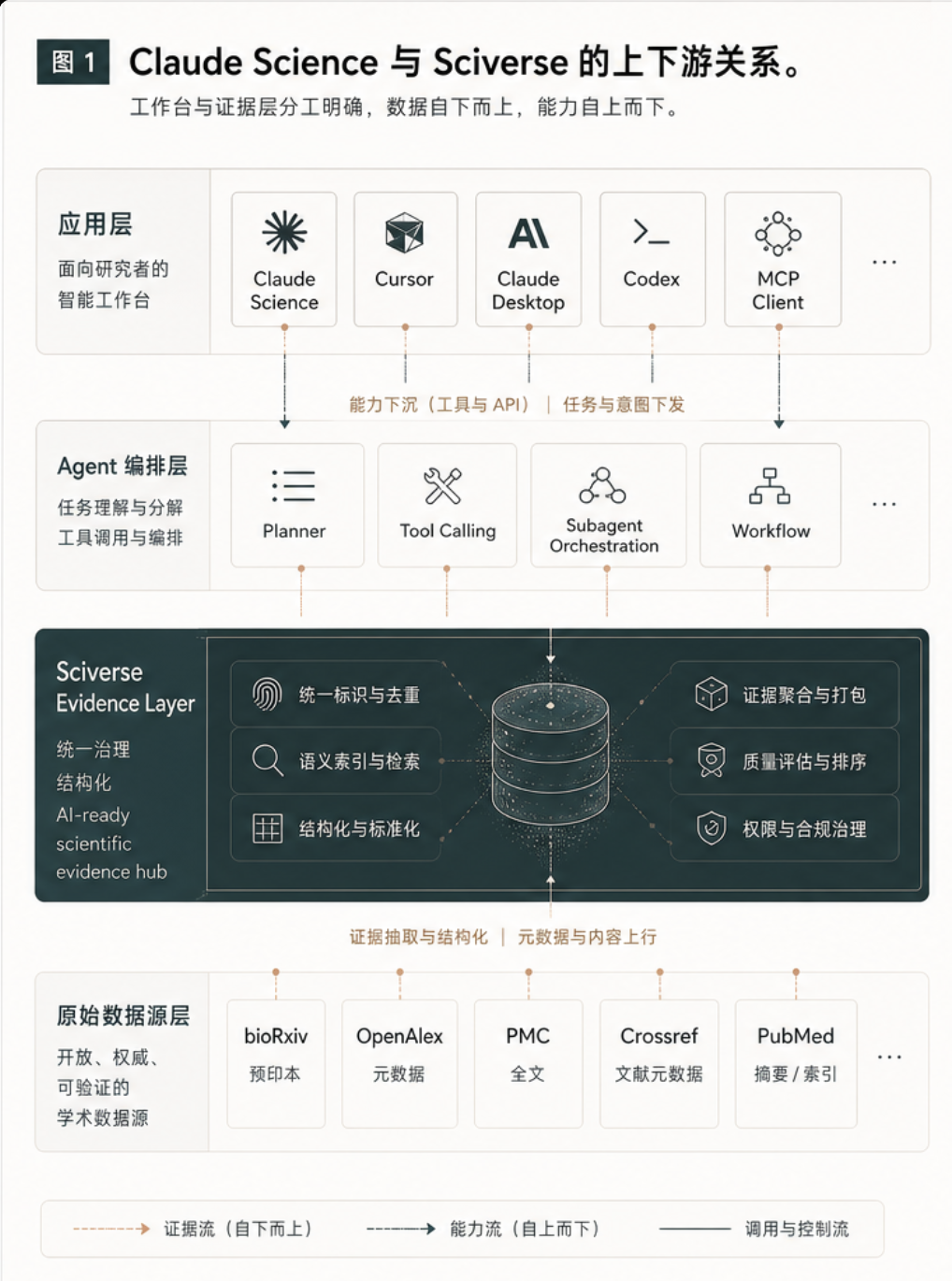
可以把两者放在不同层级理解:
| 层级 | 代表形态 | 核心问题 |
|---|---|---|
| 下游应用层 | Claude Science、Cursor、Claude Desktop、Codex、MCP Client | 研究人员如何提出任务、运行分析、生成产物、审查记录 |
| Agent 编排层 | 多个 subagent、tool calling、MCP server、workflow engine | 谁去检索、谁去筛选、谁去读全文、谁去取图表 |
| 证据数据层 | Sciverse | 异构科学数据如何变成 Agent 可引用、可追溯、可组合的 evidence |
| 原始来源层 | bioRxiv、OpenAlex、PMC、Crossref、PubMed 等 | 数据分散、字段不一、权限不同、全文与元数据割裂 |
Claude Science 这类产品解决的是“科学工作台”的问题。Sciverse 更适合解决它下面一层的问题:把分散的科学数据源整理成 AI-ready evidence。
这里的 AI-ready 不是一句营销词,它至少包含五件事:
- 数据源被统一接入,而不是每个 Agent 单独写爬虫或适配器。
- 元数据被规范化,作者、年份、期刊、DOI、来源、引用等字段能被结构化查询。
- 原文被切成可引用 chunk,而不是只返回论文标题或摘要。
- chunk 能通过
doc_id + offset回到原文上下文。 - 论文里的 Figure / Table 资源能在需要时继续被读取。
换句话说,Sciverse 不应该被包装成“又一个文献搜索 API”。它更像是科研 Agent 的可信证据数据层。
为什么下游科学工作台不能直接面对所有数据源
以 bioRxiv、OpenAlex、PMC 为例,它们各自都很重要,但它们给 Agent 带来的数据形态并不一样。
| 数据源 | 强项 | 对 Agent 的挑战 |
|---|---|---|
| bioRxiv | 生物学预印本,适合追踪最新研究 | 预印本状态、版本、正文结构、引用可靠性需要额外治理 |
| OpenAlex | 大规模开放学术图谱,works、authors、sources 等元数据丰富 | 更偏 metadata 和 graph,全文 evidence chunk 不是核心公开链路 |
| PMC | 生物医学与生命科学全文开放档案,适合获取可读全文 | XML、全文结构、图表资源、许可证和可用性需要解析与治理 |
| Crossref | DOI、出版与注册元数据基础设施 | 非全文证据层,适合做 DOI 与出版元数据对齐 |
| PubMed | 生物医学文献索引和检索基础设施 | 检索与索引强,但 Agent 仍需要额外链路读上下文和证据 |
如果下游产品让多个 subagent 直接面对这些源,系统很快会变复杂:
- 一个 subagent 查 OpenAlex 拿 metadata。
- 一个 subagent 查 PMC 读全文。
- 一个 subagent 去 bioRxiv 找预印本。
- 一个 subagent 解析 PDF 或 XML。
- 一个 subagent 找 Figure / Table。
- 一个 subagent 再把这些结果合并成手稿证据。
这套架构能跑 demo,但长期会遇到三个问题:
- 字段不可比:不同来源的 title、author、journal、date、DOI、license、version 字段不一致。
- 证据不可追溯:metadata 能告诉你论文存在,却不一定告诉你结论来自原文哪一段。
- 工作流不可审计:Agent 最后写出的结论,很难回看它到底用了哪个来源、哪个 chunk、哪个上下文和哪张图。
所以 Sciverse 的价值不是替代所有数据源,而是把这些源治理成下游 Agent 能用的统一证据接口。
Sciverse 的五个接口如何承接这类工作台
Sciverse 当前最重要的不是单个搜索框,而是五个接口组成的证据链。
| 接口 | 作用 | 在 Claude Science 类工作台中的角色 |
|---|---|---|
agentic-search |
自然语言语义检索,返回可引用 evidence chunk | 让科研 Agent 直接获得可引用证据,而不是只拿论文列表 |
meta-search |
结构化元数据检索,支持作者、年份、期刊、学科等筛选 | 构建候选论文池、筛选方向、补齐 DOI/年份/期刊等信息 |
meta-catalog |
查看可用元数据字段 | 给筛选 UI、subagent planner、自动查询生成器提供字段目录 |
content |
按 doc_id + offset 读取原文上下文 |
把命中 chunk 放回原文语境,减少断章取义 |
resource |
读取论文内 Figure / Table 图片资源 | 给多模态科研 Agent 提供图表证据与实验结果材料 |
推荐链路可以这样理解:
Claude Science / Cursor / Claude / Codex / MCP Client
↓
Research Workflow Orchestrator
↓
多个 subagent:检索、筛选、读全文、取图表、核查引用
↓
Sciverse Evidence Layer
↓
agentic-search -> meta-search -> content -> resource
↓
bioRxiv / OpenAlex / PMC / Crossref / PubMed / 其他科学数据源
在这个架构里,Sciverse 不是最终写结论的 Agent。它负责把证据整理成下游 Agent 能够安全使用的形态。
这点很重要:科学结论仍然要由研究人员判断,Sciverse 提供的是证据、上下文、元数据和资源入口。
从“多源检索”到“Evidence Pack”
对科研 Agent 来说,真正好用的返回结果不应该只是一组链接,而应该是一个 Evidence Pack。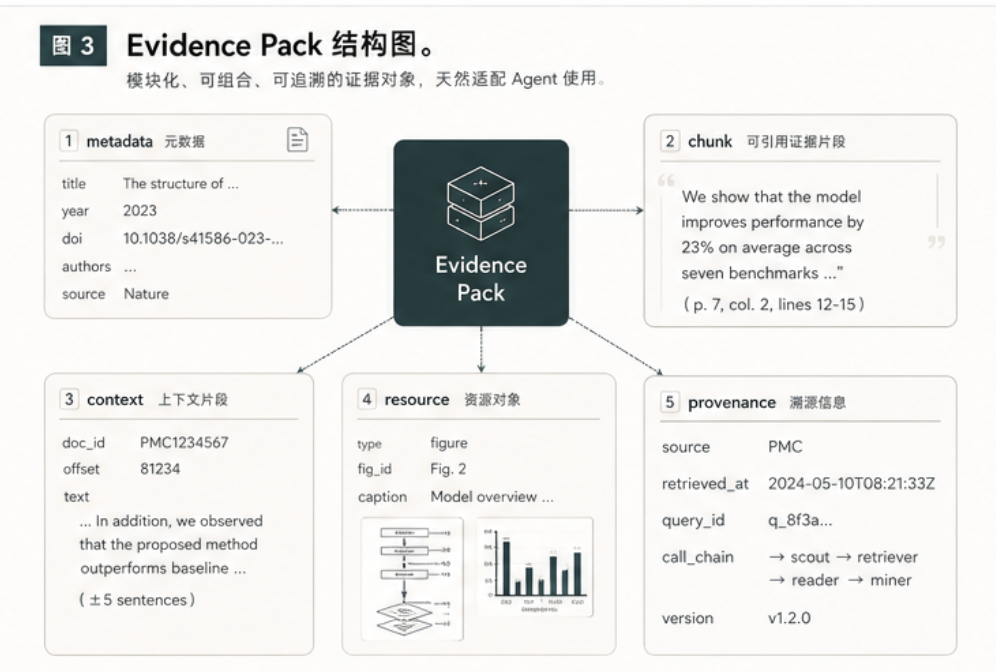
一个最小 Evidence Pack 可以包含:
| 字段 | 说明 |
|---|---|
query |
原始研究问题 |
doc_id |
Sciverse 内部文档标识 |
title |
论文标题 |
doi |
DOI,若可用 |
year |
发表年份,若可用 |
venue |
期刊或来源,若可用 |
chunk |
命中的 evidence chunk |
offset |
chunk 在文档中的位置 |
page |
页码,若可用 |
context |
通过 content 扩展出的原文上下文 |
resources |
Figure / Table 资源,若可用 |
provenance |
来源、调用链、时间戳、接口记录 |
这才是下游科学工作台真正需要的东西。
因为 Claude Science 类产品最终要做的不是“搜索一下”,而是把证据带入分析、图表、手稿和审稿流程。
一句话概括:
下游工作台负责让科学家完成任务,Sciverse 负责让 Agent 拿到可检查的科学证据。
一个可改造的最小调用示例
下面的 Python 示例展示如何把 Sciverse 当成 Evidence Pack 层来用:先用 agentic-search 找 evidence chunk,再用 content 读取上下文。如果上下文里有 Figure / Table 资源引用,再用 resource 获取资源。
import os
import time
import requests
BASE_URL = "https://api.sciverse.space"
API_KEY = os.environ.get("SCIVERSE_API_TOKEN")
if not API_KEY:
raise RuntimeError("Missing SCIVERSE_API_TOKEN")
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
def request_json(method, path, **kwargs):
response = requests.request(
method,
f"{BASE_URL}{path}",
headers=headers,
timeout=60,
**kwargs,
)
if response.status_code == 429:
raise RuntimeError("Rate limited by Sciverse API. Retry with exponential backoff.")
response.raise_for_status()
return response.json()
research_question = (
"What evidence supports using foundation models for protein structure "
"or molecular design workflows?"
)
search_result = request_json(
"POST",
"/agentic-search",
json={
"query": research_question,
"top_k": 5,
"source_types": ["pdf", "web"],
"mode": "balanced",
},
)
hits = search_result.get("hits") or search_result.get("results") or []
if not hits:
raise RuntimeError("No evidence returned. Check query or latest API docs.")
first_hit = hits[0]
doc_id = first_hit.get("doc_id")
offset = first_hit.get("offset", 0)
if not doc_id:
raise RuntimeError("Search hit does not include doc_id. Verify response schema in latest docs.")
content_result = request_json(
"GET",
"/content",
params={
"doc_id": doc_id,
"offset": offset,
"limit": 2048,
},
)
resources = (
content_result.get("resources")
or content_result.get("figures")
or content_result.get("tables")
or []
)
resource_result = None
if resources:
first_resource = resources[0]
file_name = first_resource.get("file_name") if isinstance(first_resource, dict) else None
if file_name:
time.sleep(1)
resource_result = request_json(
"GET",
"/resource",
params={"file_name": file_name},
)
evidence_pack = {
"query": research_question,
"evidence": {
"doc_id": first_hit.get("doc_id"),
"title": first_hit.get("title"),
"chunk": first_hit.get("chunk") or first_hit.get("text"),
"page": first_hit.get("page"),
"offset": first_hit.get("offset"),
"score": first_hit.get("similarity") or first_hit.get("score"),
},
"context": {
"text": content_result.get("text"),
"next_offset": content_result.get("next_offset"),
},
"resource": resource_result,
"provenance": {
"search_endpoint": "/agentic-search",
"content_endpoint": "/content",
"resource_endpoint": "/resource" if resource_result else None,
},
}
print(evidence_pack)
这段代码可以放进 Claude Desktop、Cursor、Codex 或 MCP server 的工具层里。更完整的系统里,还可以加一个 meta-search 步骤,用来补齐年份、期刊、作者、DOI、citation count 等元数据。
多 subagent 架构:Sciverse 可以把复杂度往下收
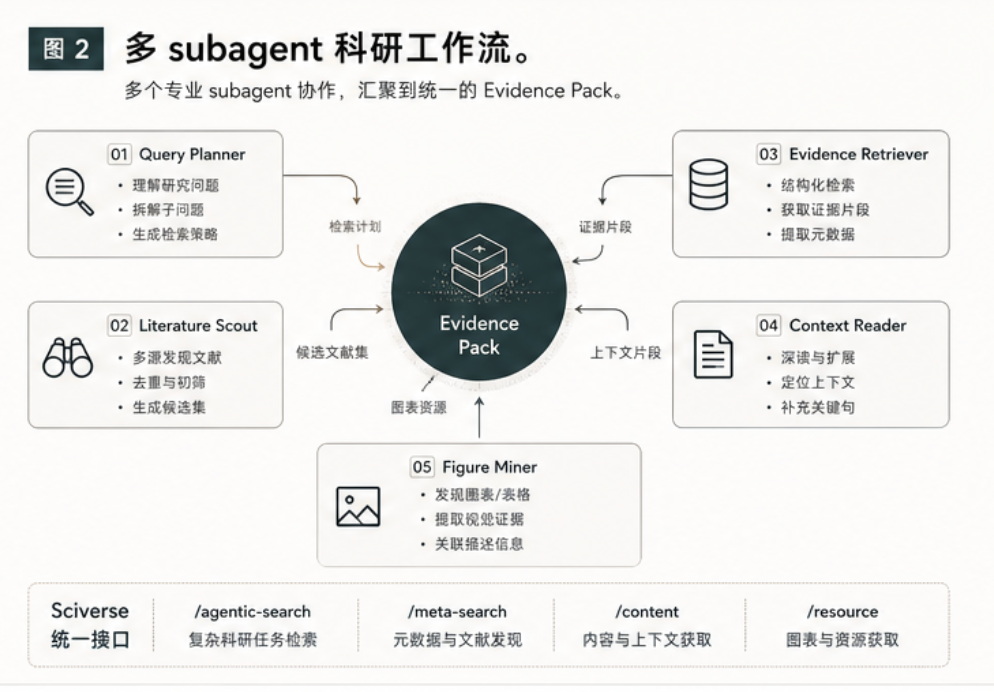
一个合理的科研工作台不会只有一个 Agent。它更可能是多个 subagent 协作:
| Subagent | 输入 | 输出 | 依赖 Sciverse 能力 |
|---|---|---|---|
| Query Planner | 用户研究问题 | 检索计划与字段约束 | meta-catalog |
| Literature Scout | 主题、时间范围、领域 | 候选论文池 | meta-search |
| Evidence Retriever | 科学 claim 或研究问题 | 可引用 chunk | agentic-search |
| Context Reader | doc_id + offset |
原文上下文 | content |
| Figure/Table Miner | resource reference | 图表资源 | resource |
| Claim Reviewer | 手稿段落 + Evidence Pack | 支持/矛盾/不足判断 | 全链路 provenance |
如果没有统一证据层,这些 subagent 每个都要理解不同数据源的接口、字段和限制。长期看,这会把下游产品变成一堆源适配器。
Sciverse 的更好位置,是把源适配器、元数据治理、全文切分、上下文定位和图表资源抽象到同一层里,让下游 Agent 面对统一接口。
这也是“AI-ready 化”的核心含义:不是简单把论文塞进向量库,而是把论文变成有结构、有来源、有位置、有上下文、有资源引用的证据对象。
为什么这比普通 RAG 更重要
普通 RAG 常见的问题是:检索出来一段文本,模型就开始写。
科研 RAG 不能这样。它至少要回答四个问题:
- 这段话来自哪篇论文?
- 它在原文什么位置?
- 上下文是否支持这个解释?
- 如果关键证据在图表里,能不能继续读 Figure / Table?
Sciverse 的接口链路对应的正是这四个问题:
agentic-search:找到可引用 chunk
meta-search:补齐论文元数据
content:回到原文上下文
resource:继续读取图表证据
这和 OpenAlex、Crossref、PubMed、PMC、bioRxiv 的关系不是替代关系,而是治理关系。
原始来源负责提供科学资料。Sciverse 负责把这些资料转成 Agent 更容易调用和核查的证据形态。Claude Science 这类下游工作台则负责把证据带入真实研究流程。
可复现评测方案
本文未进行实测跑分,仅提供可复现评测方案。
如果要验证 Sciverse 是否适合作为 Claude Science 类工作台的上游证据层,可以设计下面的实验。
查询集
| 查询类型 | 示例 |
|---|---|
| 最新预印本追踪 | “recent preprints about foundation models for protein design” |
| 元数据筛选 | “papers from 2023 to 2026 about single-cell foundation models” |
| 证据核查 | “evidence that AI-generated citations are invalid or hallucinated” |
| 图表读取 | “papers with figures comparing protein structure prediction methods” |
| 综述生成 | “literature review evidence pack for AI-assisted drug discovery workflows” |
对比对象
- Sciverse
- OpenAlex
- Semantic Scholar
- Crossref
- PubMed / PMC
- 通用搜索 API 或普通向量库 RAG
评测维度
| 维度 | 记录方式 |
|---|---|
| Metadata 完整度 | 是否返回标题、作者、年份、期刊、DOI、引用数 |
| Evidence 粒度 | 是否直接返回可引用 chunk |
| 上下文能力 | 是否能从命中结果继续读取原文上下文 |
| 图表能力 | 是否能继续获取 Figure / Table |
| Provenance | 是否保留 doc_id、offset、page、source 等字段 |
| Agent 成本 | 从用户问题到 Evidence Pack 需要多少步 |
| 审稿可用性 | 手稿中的 claim 是否能回链到证据 |
记录模板
| 查询 | 工具 | 返回对象 | 是否含 evidence chunk | 是否可读上下文 | 是否可取图表 | 备注 |
|---|---|---|---|---|---|---|
| protein design foundation models | Sciverse | evidence + metadata | 是 | 是 | 条件支持 | 以最新文档为准 |
| protein design foundation models | OpenAlex | works metadata | 非核心 | 非核心 | 非核心 | 适合论文池和图谱 |
| protein design foundation models | PMC | full text / XML | 需自行解析 | 可自行解析 | 需自行解析 | 适合开放全文来源 |
| protein design foundation models | Crossref | DOI metadata | 否 | 否 | 否 | 适合出版元数据 |
| protein design foundation models | 通用搜索 API | 网页结果 | 不稳定 | 不稳定 | 不稳定 | 需额外治理 |
不要用这个实验伪造准确率、延迟或成本。真正有价值的是记录:一个下游科研 Agent 要拿到可审计 Evidence Pack,需要多少额外工程。
结尾 CTA
Claude Science 这类产品证明了一件事:科研 AI 正在从聊天界面进入真实实验流程。下一步的竞争,不只是模型能力,而是谁能把数据库、论文、代码、图表、计算和审稿记录变成可信链路。
如果你正在做科研 Agent、科学 RAG、文献综述助手、claim checker,或者想把 Cursor、Claude、Codex、MCP 接入科研工作流,Sciverse 更适合被放在底层:作为统一治理过的科学证据数据层。
从接口上看,可以先从三条链路开始:
科研 RAG
agentic-search -> content -> resource
论文筛选
meta-catalog -> meta-search -> content
Evidence Pack
agentic-search -> meta-search -> content -> resource -> Agent workflow
真正值得做的,不是让 Agent 看起来更会说科学,而是让它说出的每一句科学判断,都能回到证据、上下文和图表。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)