
从API接入到模型切换:Anthropic出口管制解除后的技术选型指南
2026年7月1日,美国商务部撤销对Anthropic旗下Claude Fable 5和Mythos 5的出口管制,7月2日起恢复全球访问。这场持续19天的监管拉锯战表面落幕,但对依赖海外大模型API调用的技术团队,真正的架构决策窗口才刚刚打开。
本文从纯技术视角出发,系统梳理事件背景下的三种技术路线——多供应商API接入架构、开源模型API迁移、私有化部署,并提供可落地的代码示例和架构方案。
一、事件回顾:技术视角的关键时间线

核心变化:Anthropic承诺多层级安全防护 + 常态化自查 + 上线前风险测试 + 漏洞主动上报四重合规框架。这意味着后续版本更新可能引入额外请求头或安全校验参数。
二、技术路线一:多供应商API接入架构设计
2.1 架构目标
在不改变业务逻辑的前提下,实现多个大模型API供应商的无缝切换,任一供应商不可用时自动故障转移。
2.2 实现方案:统一路由层
核心思路是构建一个API网关抽象层,将上游请求路由到不同的模型供应商:
import aiohttp
import asyncio
from typing import Optional, Dict, Any
class LLMRouter:
"""多供应商大模型API路由层"""
def __init__(self):
self.providers = {
"anthropic": {
"base_url": "https://api.anthropic.com/v1",
"api_key": "sk-ant- ***",
"model": "claude-fable-5",
"weight": 0, # 当前不可用时的降权策略
"fallback": ["deepseek", "openai"]
},
"deepseek": {
"base_url": "https://api.deepseek.com/v1",
"api_key": "sk-ds-** *",
"model": "deepseek-v4-chat",
"weight": 1,
"fallback": ["qwen"]
},
"qwen": {
"base_url": "https://dashscope.aliyuncs.com/api/v1",
"api_key": "sk-qw- ***",
"model": "qwen-max",
"weight": 1,
"fallback": []
}
}
self.health_cache: Dict[str, bool] = {}
async def health_check(self, provider: str) -> bool:
"""主动健康探测,缓存30秒"""
config = self.providers.get(provider)
if not config:
return False
try:
async with aiohttp.ClientSession() as session:
async with session.get(
f"{config['base_url']}/models",
headers={"Authorization": f"Bearer {config['api_key']}"},
timeout=aiohttp.ClientTimeout(total=5)
) as resp:
return resp.status == 200
except:
return False
async def chat_completion(self, messages: list, preferred: str = "anthropic") -> Optional[Dict[str, Any]]:
"""带故障转移的推理请求"""
candidates = [preferred] + self.providers[preferred]["fallback"]
for provider in candidates:
if await self.health_check(provider):
config = self.providers[provider]
# 调用具体供应商API
result = await self._call_provider(provider, config, messages)
if result:
return result
return None
async def _call_provider(self, provider: str, config: dict, messages: list) -> Optional[Dict]:
payload = {
"model": config["model"],
"messages": messages,
"max_tokens": 4096,
"temperature": 0.7
}
headers = {"Authorization": f"Bearer {config['api_key']}", "Content-Type": "application/json"}
try:
async with aiohttp.ClientSession() as session:
async with session.post(
f"{config['base_url']}/messages",
json=payload,
headers=headers,
timeout=aiohttp.ClientTimeout(total=30)
) as resp:
if resp.status == 200:
return await resp.json()
# HTTP 403/503 → 标记不健康,触发fallback
self.health_cache[provider] = False
return None
except:
return None
2.3 架构优势
**热切换 **:健康检查缓存30秒,检测到异常后自动沿fallback链降级
**权重策略 **:可对同一供应商配置多个可用model,按weight轮询
**扩展性 **:新增供应商只需在providers字典中添加配置项
2.4 关键扩展:熔断与限流
在实际生产环境中,健康检查后直接fallback存在"惊群效应"风险——当主供应商恢复时,所有实例同时切回,可能导致瞬间打满API配额。建议加入熔断器模式
import time
from collections import deque
class CircuitBreaker:
"""基于滑动窗口的熔断器,防止雪崩效应"""
def __init__(self, failure_threshold: int = 5, recovery_timeout: int = 60):
self.failure_threshold = failure_threshold
self.recovery_timeout = recovery_timeout
self.failure_window: deque = deque(maxlen=failure_threshold)
self.last_failure_time: float = 0
self.state = "CLOSED" # CLOSED → OPEN → HALF_OPEN
def record_failure(self):
self.failure_window.append(time.time())
self.last_failure_time = time.time()
if len(self.failure_window) >= self.failure_threshold:
window_span = self.failure_window[-1] - self.failure_window[0]
if window_span < 30: # 30秒内失败次数超阈值
self.state = "OPEN"
def allow_request(self) -> bool:
if self.state == "CLOSED":
return True
if self.state == "OPEN":
if time.time() - self.last_failure_time > self.recovery_timeout:
self.state = "HALF_OPEN"
return True
return False
# HALF_OPEN状态允许试探性请求
return True
将此熔断器集成到LLMRouter的_call_provider中,可有效防止因供应商API抖动导致的级联故障。
2.5 运维考量
**API密钥轮换 **:建议集成密钥管理服务(如Vault/AKMS),密钥有效期不超过7天
**请求级别监控 **:每条请求记录供应商、响应时间、HTTP状态码,接入Prometheus + Grafana看板
**成本分摊 **:多供应商架构下需要按provider打标,便于后续成本归因分析
三、技术路线二:开源模型API迁移实战(DeepSeek V4 / Qwen接入对比)
3.1 选型指标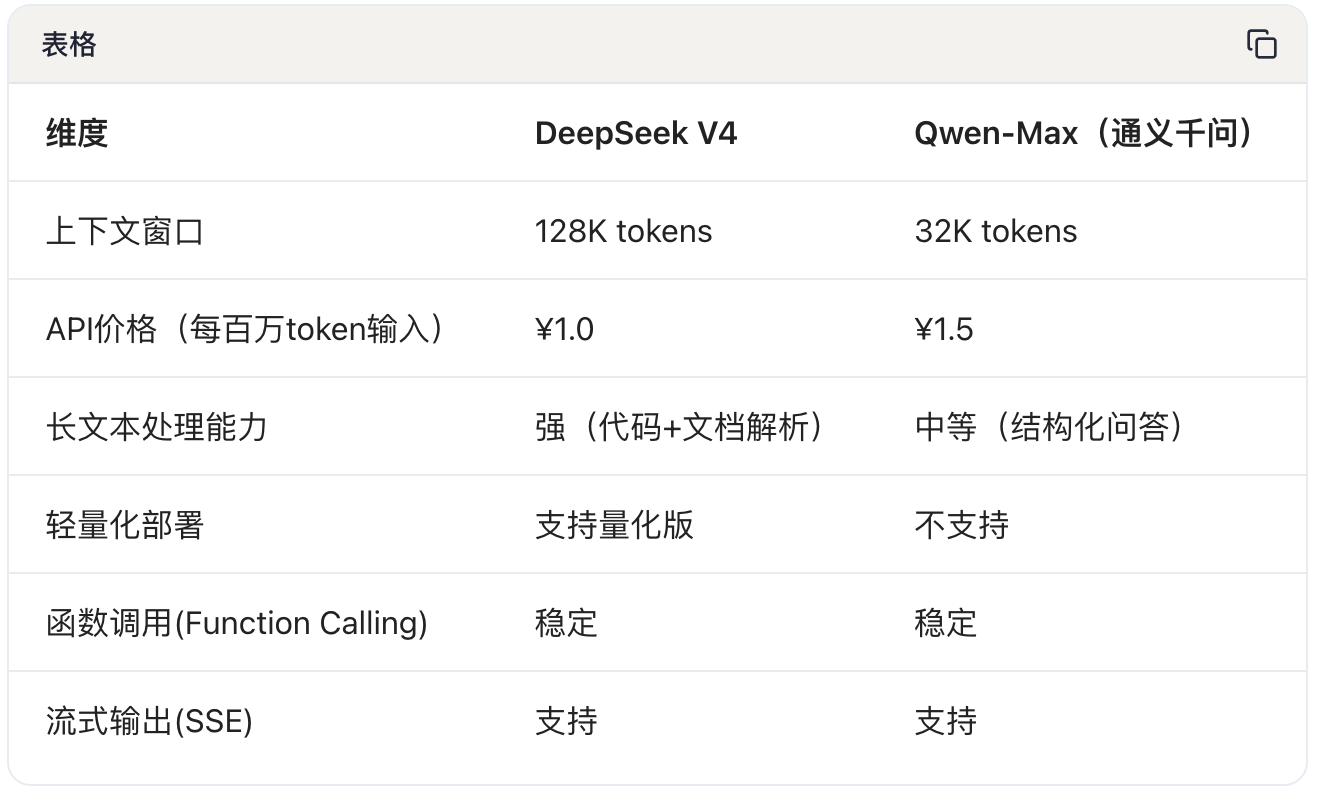
3.2 迁移适配实战
从Claude API迁移到DeepSeek V4或Qwen,核心差异在消息格式和请求参数上。以下适配器可抹平差异:
class ModelAdapter:
"""统一模型适配层:将应用层请求格式转换为各供应商API格式"""
@staticmethod
def adapt_messages(messages: list, target: str) -> list:
"""消息格式转换:Claude格式 ↔ OpenAI兼容格式"""
if target in ("deepseek", "qwen"):
# Claude的messages格式:role为"human"/"assistant"
# 转换为OpenAI兼容格式:role为"user"/"assistant"
adapted = []
for msg in messages:
role_map = {
"human": "user",
"assistant": "assistant",
"system": "system"
}
adapted.append({
"role": role_map.get(msg.get("role", "user"), "user"),
"content": msg.get("content", "")
})
return adapted
return messages # Claude原生格式
@staticmethod
def adapt_response(response: dict, source: str) -> dict:
"""响应格式标准化:统一输出text内容"""
if source == "anthropic":
return {"content": response.get("content", [{}])[0].get("text", "")}
elif source == "deepseek":
return {"content": response["choices"][0]["message"]["content"]}
elif source == "qwen":
return {"content": response["output"]["text"]}
return response
@staticmethod
def build_system_prompt(provider: str, task: str) -> str:
"""为不同模型定制System Prompt"""
base = "你是一个专业的技术助手,请准确、简洁地回答问题。"
if provider == "deepseek":
return f"{base} 注意:DeepSeek V4在代码生成场景下偏好逐步推理,请分步骤输出。任务:{task}"
elif provider == "qwen":
return f"{base} 通义千问支持结构化JSON输出,建议使用JSON Schema约束输出格式。任务:{task}"
return base
3.3 迁移流程:从Claude到开源模型的自动化测试管道
迁移不是一次性替换,而是逐场景验证的过程。建议建立以下自动化测试流水线:
1. 录制阶段:将生产环境Claude请求/响应对(含System Prompt、用户输入、预期输出)录制为测试集
2. 回放阶段:用DeepSeek V4和Qwen分别对同一输入生成输出
3. 质量评估:对模型输出做4维度评分——准确率(Factual)、相关性(Relevance)、格式合规(Format)、延迟(Latency)
4. 灰度放量:按5%→20%→50%→100%逐步切流,每个阶段稳定运行至少24小时
以下是集成了质量评估的迁移脚本核心逻辑:
import json
from typing import List, Dict, Tuple
class MigrationEvaluator:
"""模型迁移效果评估器"""
def __init__(self, test_set_path: str):
with open(test_set_path, 'r') as f:
self.test_cases: List[Dict] = json.load(f)
def evaluate_response(self,
expected: str,
actual: str,
latency_ms: float) -> Dict[str, float]:
"""4维度评分(0-1分)"""
# 维度1:准确率(关键词覆盖率)
expected_tokens = set(expected.split())
actual_tokens = set(actual.split())
precision = len(expected_tokens & actual_tokens) / max(len(actual_tokens), 1)
# 维度2:格式合规(JSON格式是否一致)
format_score = 1.0
try:
exp_json = json.loads(expected)
act_json = json.loads(actual)
format_score = 1.0 if type(exp_json) == type(act_json) else 0.5
except:
pass # 非JSON场景不扣分
# 维度3:延迟评分(<500ms满分,>5000ms零分)
latency_score = max(0, 1 - (latency_ms - 500) / 4500)
# 维度4:相关性(基于输出长度是否合理)
len_ratio = len(actual) / max(len(expected), 1)
relevance = min(len_ratio, 1 / max(len_ratio, 0.01)) if len_ratio > 0 else 0
relevance = min(relevance, 1.0)
return {
"precision": round(precision, 3),
"format": round(format_score, 3),
"latency": round(latency_score, 3),
"relevance": round(relevance, 3),
"overall": round((precision + format_score + latency_score + relevance) / 4, 3)
}
def batch_test(self, source: str, target: str) -> Dict:
"""对比两个模型的批量评分结果"""
results = {"source": source, "target": target, "cases": []}
for case in self.test_cases[:20]: # 首批测试20个样本
result = self.evaluate_response(
case["expected"],
case["actual"],
case.get("latency_ms", 1000)
)
results["cases"].append(result)
return results
3.4 迁移注意事项
**长文本场景 **:DeepSeek V4的128K上下文窗口覆盖绝大多数文档解析场景,而Qwen的32K在处理超长文档时需配合分片策略
**函数调用 **:两者均支持Function Calling,但参数Schema定义上有细微差异(DeepSeek要求strict=True,Qwen使用parameters直接约束),需在Adapter层做映射
**输出一致性 **:不同模型对同一Prompt的输出风格不同,建议在测试集上用BLEU/ROUGE评分验证质量差异,再决定是否切换
四、技术路线三:私有化部署技术方案
4.1 部署架构
对于对数据主权有强要求的企业,私有化部署是最终方案。以下是典型架构:
┌─────────────────────────────────────────────────────┐
│ 负载均衡层 │
│ Nginx / OpenResty (SSL终止+路由) │
└─────────────────────┬───────────────────────────────┘
│
┌─────────────────────▼───────────────────────────────┐
│ 推理服务层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ GPU Node1│ │ GPU Node2│ │ GPU Node3│ ← vLLM │
│ │ H100×8 │ │ H100×8 │ │ A100×8 │ 引擎 │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ 并发推理 + KV Cache │
└─────────────────────┬───────────────────────────────┘
│
┌─────────────────────▼───────────────────────────────┐
│ 服务治理层 │
│ Prometheus(监控) + Grafana + 模型热加载/热更新 │
└─────────────────────────────────────────────────────┘
4.2 关键实现要素
**推理引擎选型 **:推荐vLLM或TGI(Text Generation Inference),支持PagedAttention KV Cache管理,可将H100单卡推理吞吐提升3-5倍。vLLM的continuous batching特性在混合负载场景下优势明显——短查询和长生成任务共享GPU资源,提升整体利用率。
**量化方案 **:模型大小是私有化部署的首要瓶颈。以下为常见量化方案对比: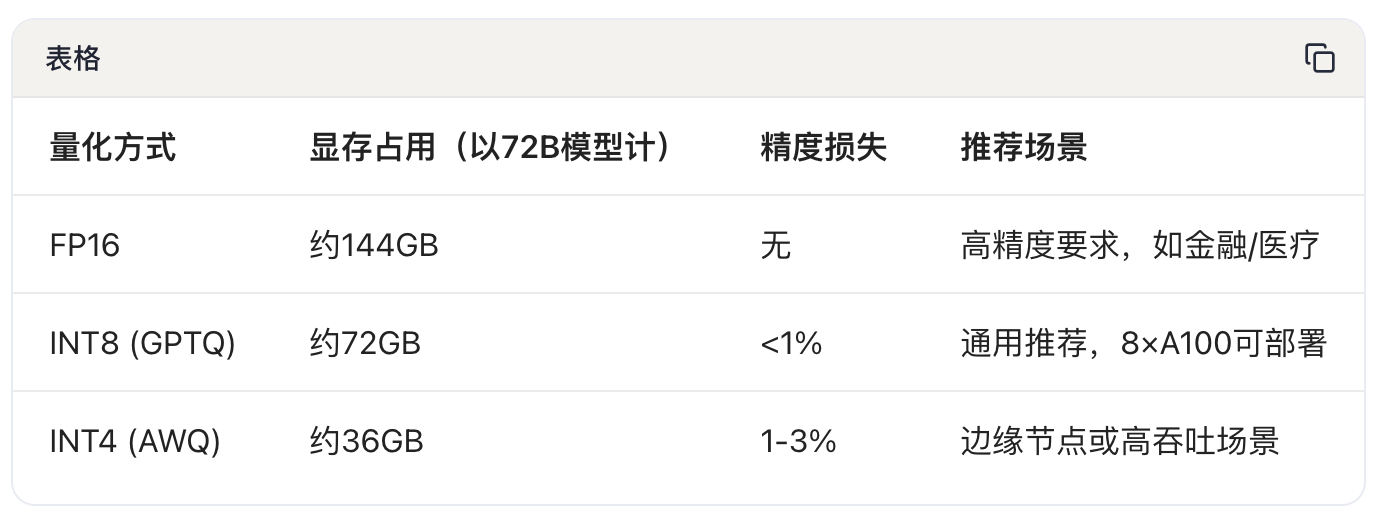
**模型选择 **:当前可私有化部署的中文优质模型包括Qwen-72B(Apache 2.0许可)、DeepSeek-V4-Base(MIT许可)。以8×H100节点为例,Qwen-72B的INT8量化部署可达约1500 tokens/s的推理吞吐,DeepSeek-V4-Base因其MoE架构特性,同等硬件条件下推理速度可再提升40-60%。
最小成本估算 :
单节点(8×A100 80G):约¥60-80万/台(含服务器),支持Qwen-32B满血部署
推理成本:约¥0.05-0.15/百万token(含电费+运维),远低于按量调用的API价格
4.3 部署示例(基于vLLM + Docker)
# 1. 启动vLLM推理服务(以Qwen-72B-GPTQ量化版为例)
docker run --gpus all \
-p 8000:8000 \
-v /data/models:/models \
vllm/vllm-openai:latest \
--model /models/Qwen-72B-GPTQ \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.9 \
--max-model-len 32768 \
--quantization gptq \
--dtype float16 \
--api-key "your-private-key"
# 2. 客户端调用(与OpenAI兼容格式)
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-private-key" \
-d '{
"model": "/models/Qwen-72B-GPTQ",
"messages": [{"role": "user", "content": "解释出口管制的技术影响"}],
"max_tokens": 1024,
"temperature": 0.7
}'
**适用场景判断 **:
**总调用量 > 500万tokens/天 **:私有化部署的边际成本开始低于API按量调用
**数据合规要求明确 **:海外业务涉及用户隐私数据、金融、医疗等敏感领域
**延迟敏感型应用 **:私有化部署可控制在50ms以内的P99推理延迟
五、技术选型决策建议
5.1 混合架构建议
三种路线不互斥,推荐按业务场景分层组合:

5.2 架构审计清单
建议团队按以下清单对现有AI服务架构做一次审计:
当前调用的模型API是否仅有单一供应商?
API调用层是否已抽象为统一路由接口?
是否实现了自动故障转移机制并经过压测?
各供应商API的请求/响应格式是否有适配层做隔离?
关键业务是否至少有两条可切换的模型路径?
从API调用切换到私有化部署,数据流是否需要重新设计?
结语
从技术角度看,Anthropic出口管制事件揭示了一个不可逆的趋势:** 大模型API的可用性不再是默认值**。无论你选择多供应商路由架构、迁移到开源模型生态,还是走向私有化部署,核心原则始终是——抽象出一层技术中间件,将业务逻辑与特定模型供应商解耦。
对于技术团队而言,最务实的做法不是押注某一条路线,而是按业务场景分层构建:核心链路走多供应商架构保障可用性,高成本非核心场景走开源API降低成本,数据敏感场景走私有化部署掌控数据主权。这三条路线的技术栈并不冲突,将LLMRouter和ModelAdapter两层抽象做扎实后,切换成本将大幅降低。
这不是一次性的架构改造,而是需要持续维护的工程实践。
本文技术方案基于开源生态组件(vLLM、aiohttp、OpenAI兼容协议),方案中的价格数据参考公开API定价及硬件市场行情,实际部署成本因配置和规模而异。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)