
调查研究-207 Claude Sonnet 5 发布:Agent 能力下放后,模型路由要从“强弱分层“改成“执行分层“
Claude Sonnet 5 发布:Agent 能力下放后,模型路由要从"强弱分层"改成"执行分层"
TL;DR
- 场景:Anthropic 于 2026 年 6 月 30 日发布 Claude Sonnet 5 并设为 Claude 平台默认模型;定位"迄今最具 Agent 能力的 Sonnet 模型",主攻编码、工具调用、浏览器/终端使用、规划、知识工作等高频 Agent 任务。
- 结论:强 Agent 能力正在从昂贵旗舰下放到中档价位;模型路由不能再按"模型强弱"分层,要按"执行属性"分层——对话层、工具层、执行层、审查层、兜底层,并改用 cost per successful task 而非 token 单价作为核心度量。
- 产出:Agent 时代模型路由的判断框架 + Sonnet 5 / Opus 4.8 / 本地 Qwen-vLLM 的分工模型 + 一组可落地的安全与权限边界清单。
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| Claude Sonnet 5 发布(2026-06-30) | ✅ 已验证 | 美东时间周二发布,设为 Claude 平台默认模型 |
| Sonnet 5 官方定位:“迄今最具 Agent 能力的 Sonnet 模型” | ✅ 已验证 | anthropic.com/news/claude-sonnet-5 |
| Sonnet 5 设为 Claude 平台默认模型 | ✅ 已验证 | Free / Pro / Max / Team / Enterprise 全量开放 |
接入 Claude Code / Claude Platform / API(claude-sonnet-5) |
✅ 已验证 | 同步登陆 Amazon Bedrock、Google Vertex AI |
| 首发价:输入 $2 / 输出 $10 每百万 token(截至 2026-08-31) | ✅ 已验证 | Anthropic 官方定价页面 |
| 标准价:输入 $3 / 输出 $15 每百万 token(2026-09-01 起) | ✅ 已验证 | 同上 |
| Opus 4.8 常规价:输入 $5 / 输出 $25 每百万 token | ✅ 已验证 | Anthropic 官方定价页面 |
| 优惠期相对 Opus 4.8 便宜约 60% | ✅ 已验证 | Anthropic 官方表述 |
| SWE-bench Pro:Sonnet 5 = 63.2% / 4.6 = 58.1% / Opus 4.8 = 69.2% | ✅ 已验证 | Anthropic Sonnet 5 发布会公开数据 |
| Terminal-Bench 2.1:Sonnet 5 = 80.4% | ✅ 已验证 | Anthropic 发布会公开数据 |
| OSWorld-Verified:Sonnet 5 = 81.2% / 4.6 = 78.5% / Opus 4.8 = 83.4% | ✅ 已验证 | Anthropic 发布会公开数据(评分口径已更新) |
| Humanity’s Last Exam:Sonnet 5 = 43.2%(无工具)/ 57.4%(有工具) | ✅ 已验证 | Anthropic 发布会公开数据 |
| 默认启用网络安全防护(与 Opus 4.7 / 4.8 同级) | ✅ 已验证 | Anthropic 安全评估,未做专项网络安全训练 |
| 支持 prompt caching 与 batch processing | ✅ 已验证 | Anthropic 官方文档 |
| tokenizer 变更:同内容 token 量约为 1.0–1.35×(同 Opus 4.7) | ✅ 已验证 | Anthropic 发布会脚注 |
| Agent 路由框架:按执行属性分层(对话/工具/执行/审查/兜底) | ⚠️ 待验证 | 本文作者推导,基于行业实践,非官方建议 |
| cost per successful task 作为核心度量 | ⚠️ 待验证 | 本文作者推导,非官方指标 |
TL;DR
Claude Sonnet 5 的重点不只是"Sonnet 又变强了",而是一个更值得开发者关注的信号:
强 Agent 能力正在从昂贵的旗舰模型,
下放到更适合高频调用的中档模型。
Anthropic 在 2026 年 6 月 30 日发布 Claude Sonnet 5。官方把它定位为目前最具 agentic 能力的 Sonnet 模型,强调它可以规划、使用浏览器和终端等工具,并在部分任务上接近或匹配 Opus 4.8 的能力水平。
价格也说明了它的产品位置。Sonnet 5 API 在 2026 年 8 月 31 日前是首发价:输入 2 美元 / 百万 token,输出 10 美元 / 百万 token。从 2026 年 9 月 1 日开始,标准价调整为输入 3 美元 / 百万 token,输出 15 美元 / 百万 token。作为对比,官方页面给出的 Opus 4.8 常规价格是输入 5 美元 / 百万 token,输出 25 美元 / 百万 token。
这意味着 Sonnet 5 更像是一个"云端强执行层",而不是普通聊天模型的升级版。它对代码 Agent、浏览器 Agent、企业流程 Agent、本地 Qwen / vLLM 加云端强模型的混合路由系统,都有直接启发。
本文的核心结论是:
Agent 时代的模型路由,不能只按模型强弱分层。
更应该按任务的执行属性分层:
对话层、工具层、执行层、审查层、兜底层。
1. 发生了什么:Sonnet 5 被放到了"高频 Agent 执行层"
如果只看名字,Claude Sonnet 5 像是 Claude 家族一次正常迭代。
但这次发布真正有价值的地方,是 Anthropic 没有只强调单轮问答、数学、代码 benchmark,而是反复把 Sonnet 5 放在 agentic tasks、coding、tool use、computer use、knowledge work 这些场景里解释。
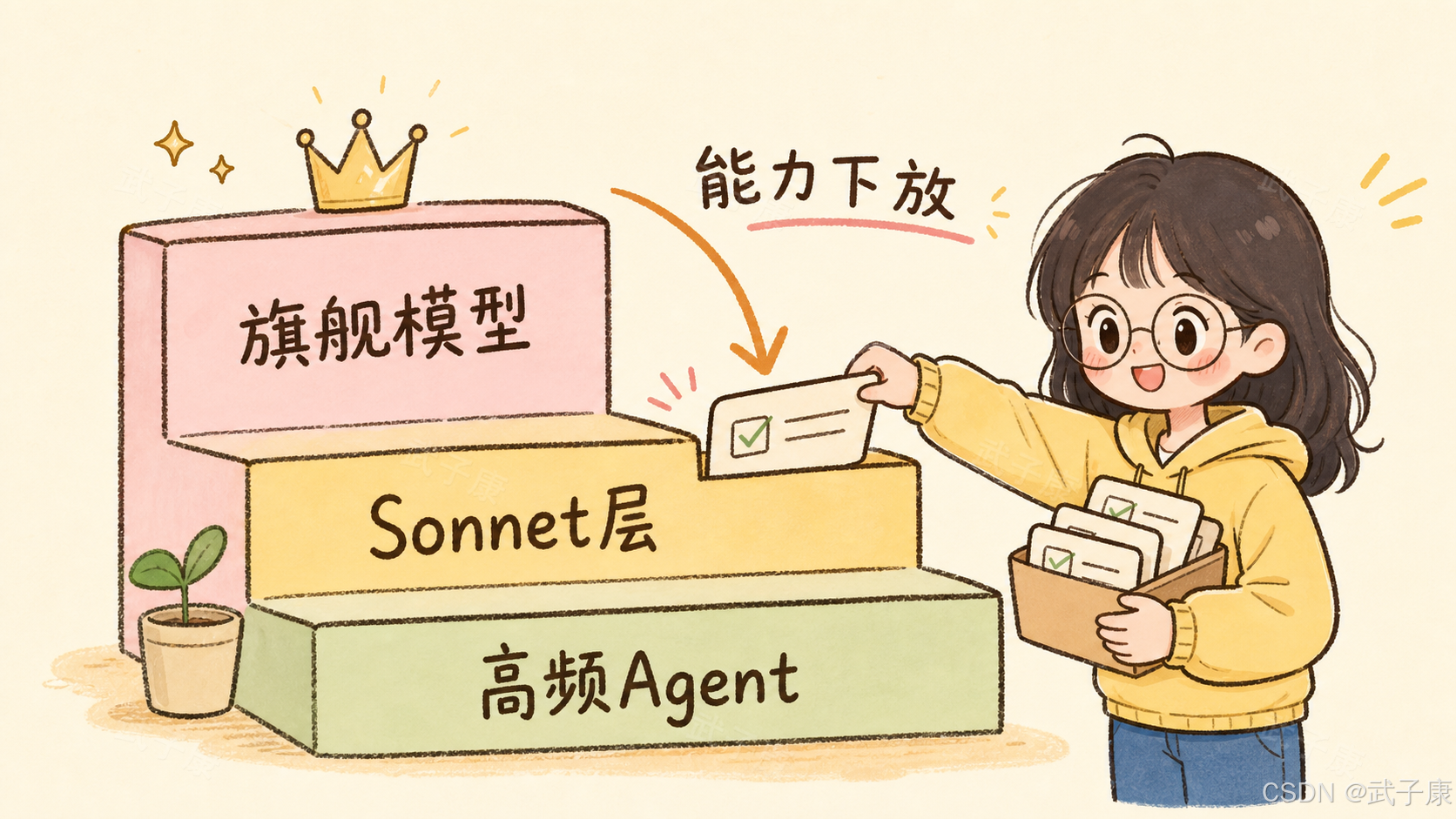
官方新闻稿里给出的定位很直接:Sonnet 5 是目前最具 Agent 能力的 Sonnet 模型,可以做规划、使用工具、以更自主的方式推进任务。官方还提到,过去几个月里最明显的 Agent 能力提升主要出现在 Opus 档模型上,而 Sonnet 5 正在缩小这个差距。
这句话背后有一个产品判断:
旗舰模型继续拉高上限,
中档模型开始承担日常执行。
过去,很多复杂 Agent 任务默认要上最贵模型。原因很简单:Agent 不只是回答问题,它要读文件、查资料、调用工具、执行命令、观察结果、修复错误、继续推进。如果模型状态保持差、工具调用不稳、失败后不会恢复,任务就会卡在半路。
Sonnet 5 的意义在于,Anthropic 正在把这类"执行型智能"做进 Sonnet 这一档价格和速度层级里。
2. 为什么这不是简单的"中档模型变强了"
很多模型发布文章会重点看榜单:
推理更强了吗?
数学更强了吗?
代码更强了吗?
上下文更长了吗?
这些指标当然重要,但它们不完全等于 Agent 能力。
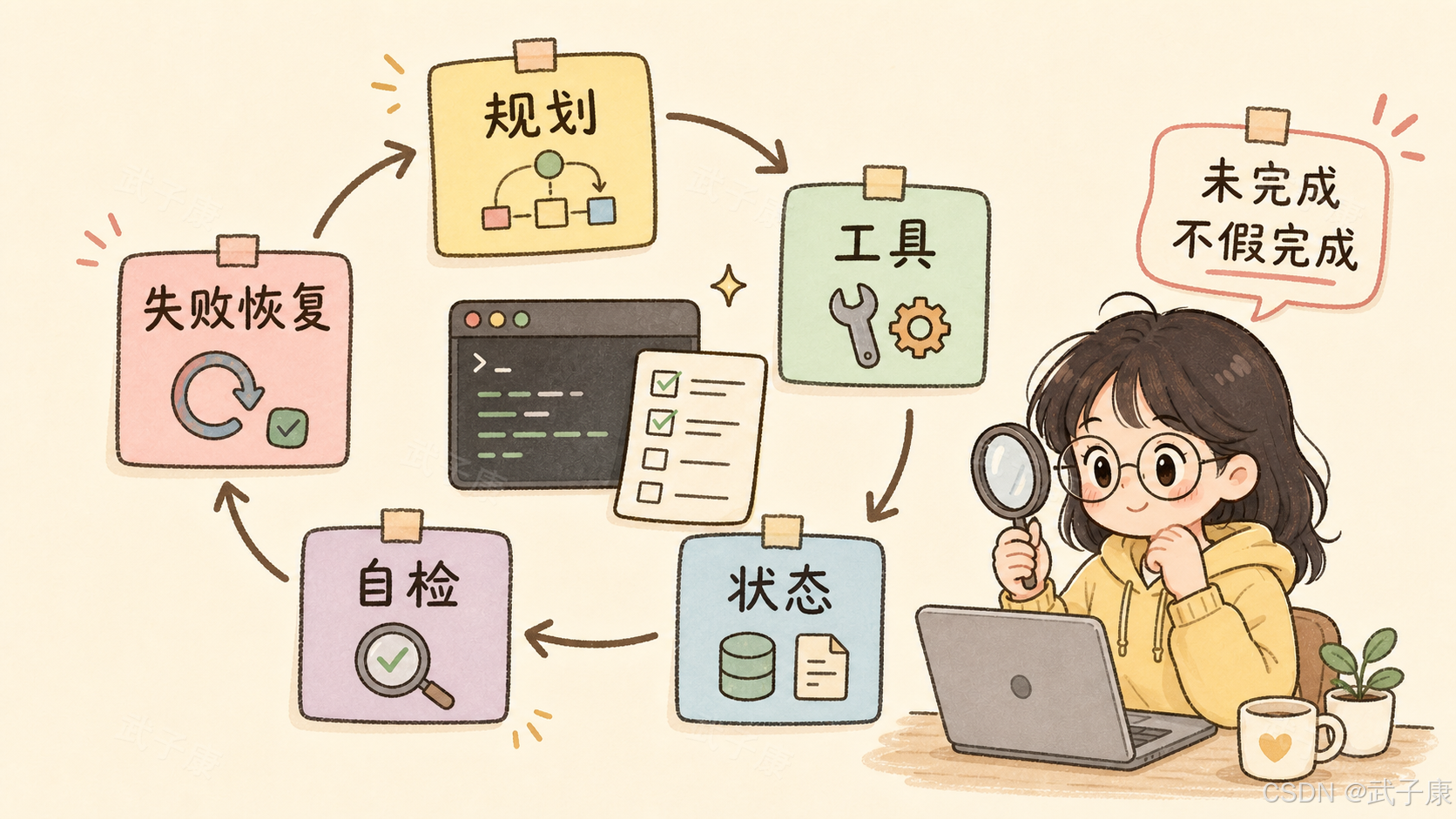
真正能用于 Agent 的模型,至少要过五道关。
第一,能把目标拆成步骤。
用户说"帮我修这个 bug",模型不能只猜原因。它需要先理解项目结构,再定位入口,再复现问题,再改代码,再跑测试。
第二,能正确使用工具。
工具调用不是会生成 JSON 就够了。真正困难的是判断什么时候该查文件,什么时候该跑命令,什么时候该搜索资料,什么时候该停下来等用户确认。
第三,能维持任务状态。
Agent 任务经常跨很多轮操作。如果模型忘记自己刚改了什么、命令返回了什么、测试失败在哪里,就容易重复劳动,甚至把已经验证过的信息推翻。
第四,能处理失败。
真实工程环境里,命令会失败,依赖会冲突,测试会报错,文件路径会找错。强 Agent 的差别不在于永不失败,而在于能根据反馈继续推进。
第五,能避免假完成。
这是 Agent 系统里最危险的问题之一。模型没有真正跑通,却说"已经完成"。Anthropic 在 Opus 4.8 发布时就强调过类似问题:Opus 4.8 更倾向于标记不确定性,也更不容易让代码缺陷在未说明的情况下通过。
所以,Sonnet 5 的价值不是"便宜一点的 Opus"。更准确地说,它说明 Agent 能力正在产品化、工程化、规模化。
3. Agent 成本为什么会改变产品形态
聊天模型的成本通常还能控制,因为一次问答可能只有几千 token。
Agent 不一样。
一个代码 Agent 为了完成一个任务,可能要读几十个文件,跑多次命令,生成多轮 patch,反复分析测试日志。一个浏览器 Agent 为了完成一次调研,可能要打开多个网页、抽取信息、比较来源、生成结论。一个企业流程 Agent 为了处理一个工单,可能要查 CRM、查知识库、写邮件、更新记录、做权限判断。
这类任务的 token 消耗不是线性增长,而是很容易膨胀。
假设一个 Agent 任务消耗:
输入 token:50 万
输出 token:3 万
用 Sonnet 5 首发价计算:
输入成本:0.5 * 2 = 1 美元
输出成本:0.03 * 10 = 0.3 美元
合计约 1.3 美元
用 Sonnet 5 标准价计算:
输入成本:0.5 * 3 = 1.5 美元
输出成本:0.03 * 15 = 0.45 美元
合计约 1.95 美元
用 Opus 4.8 常规价计算:
输入成本:0.5 * 5 = 2.5 美元
输出成本:0.03 * 25 = 0.75 美元
合计约 3.25 美元
单次任务差距看起来只是几美元,但如果每天跑几百次、几千次 Agent 任务,差距就会变成真实的产品毛利差距。
这里还没有计算 prompt caching、batch processing、失败重试、人工返工、审查成本。官方定价文档显示 Sonnet 5 支持 prompt caching,缓存命中输入价格更低;官方也提到 prompt caching 和 batch processing 能继续降低成本。
因此,Agent 商业化的关键不是"能不能回答",而是:
能不能稳定、便宜、可控地完成任务?
模型很强但太贵,只适合少数高价值任务。模型足够强且便宜,才可能成为日常自动化的执行层。
4. 不要只看 token 单价,要看成功单价
很多人比较模型,会直接比较 API 价格。
Agent 场景里,这个比较方式不够。
更合理的指标是 cost per successful task,也就是"每完成一个任务的成本"。
一个便宜模型,如果经常失败、重复调用、改错代码、需要人工返工,最终成本可能比贵模型更高。一个贵模型,如果一次完成、少走弯路、会自检、能跑通测试,反而可能更便宜。
所以看 Sonnet 5 的正确姿势不是:
它比 Opus 便宜多少?
而是:
它在什么任务上,能以更低总成本完成闭环?
这会影响模型路由的设计。
过去的模型路由常见分法是:
简单任务走小模型。
复杂任务走大模型。
本地任务走本地模型。
高质量任务走云端模型。
Agent 时代这个分法太粗。
更合理的路由应该维护一组执行画像:
chat_quality
coding_quality
tool_call_reliability
long_task_reliability
context_efficiency
cost_per_success
failure_recovery_score
latency
cache_friendliness
risk_level
最后决定路由的,不是"哪个模型最强",而是"哪个模型在这个任务类型下,每成功一次的综合成本最低"。
5. 对本地 Qwen / vLLM 路由器的启发
如果你已经在本地部署 Qwen、vLLM、ASR、TTS,或者正在做本地语音 Agent,Sonnet 5 这类模型会逼着你重新设计路由系统。
以前的路由可能是:
简单问题走本地模型。
复杂问题走云端大模型。
闲聊走便宜模型。
代码走强模型。
但 Agent 执行不是这么分的。
更合理的路由应该看这些问题:
任务是否需要多步规划?
任务是否需要调用外部工具?
任务是否需要读写文件?
任务是否需要运行命令?
任务是否允许失败重试?
任务失败成本有多高?
用户是否需要快速首响?
任务是否可以异步执行?
上下文是否超过本地模型舒适区?
是否需要模型自己检查结果?
是否需要最终由另一个模型审查?
举个例子。
用户说:“今天青岛天气怎么样?”
本地模型识别意图,调用天气工具即可。没有必要上 Sonnet 5。
用户说:“帮我分析这个项目的 WebRTC 语音链路,找出潜在 bug,并给出改造方案。”
这就不是普通问答。它需要读代码、理解架构、追踪调用链、判断并发问题、网络问题、异常处理问题。这个任务可以交给 Sonnet 5 或 Opus 级模型。
用户说:“直接帮我修复这个 bug,跑测试,确保不破坏现有逻辑。”
这就是典型 Agent 执行任务。模型能力的重点不是文案,而是工具调用、失败恢复、验证闭环。
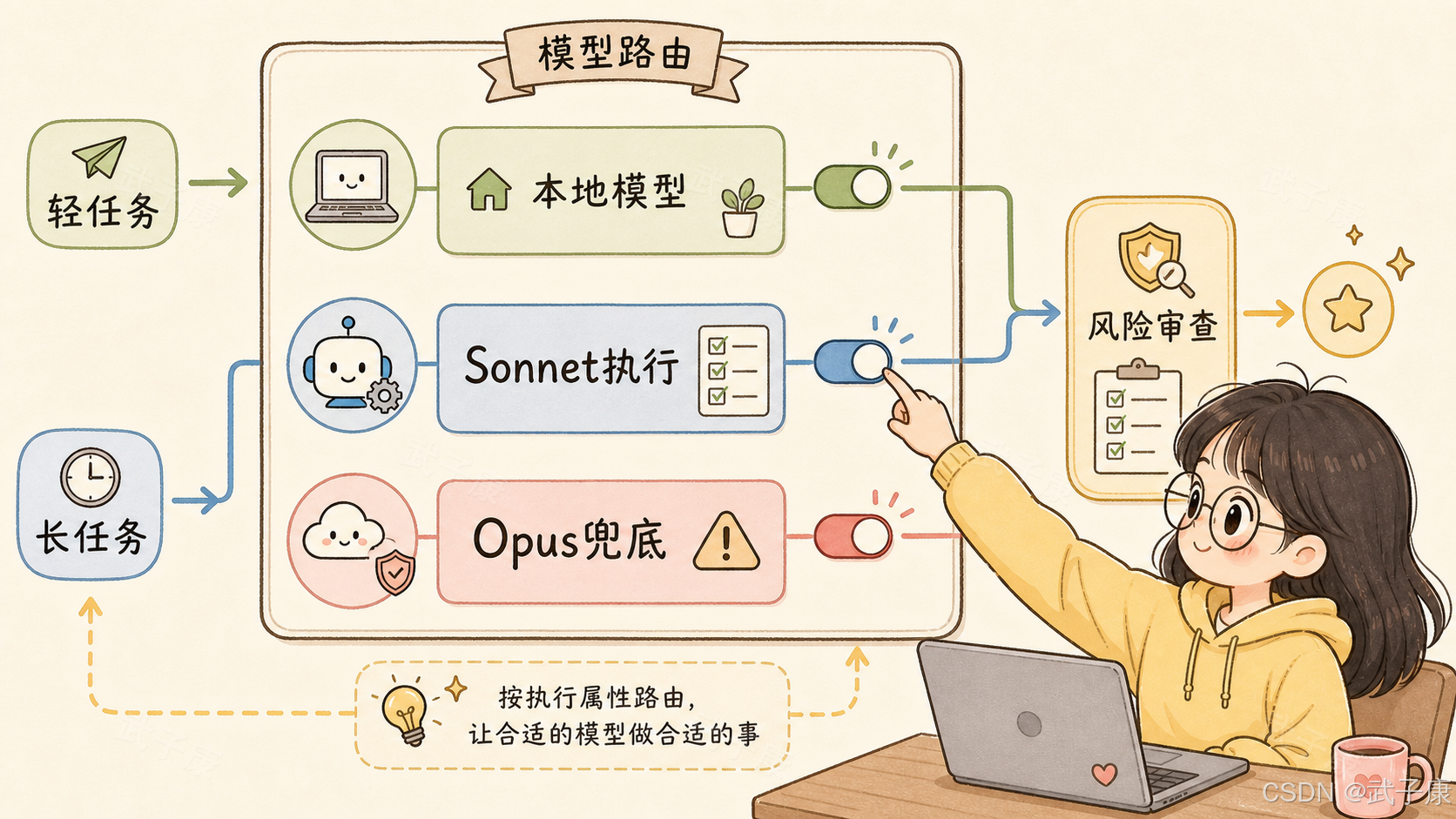
在一个真实 AI 系统里,模型可以这样分工:
本地 Qwen / vLLM:
低延迟对话、简单意图识别、轻量工具路由、常规问答。
本地中小模型:
高频、低风险、可预测任务。
Claude Sonnet 5:
多文件代码修改、长链路调研、浏览器操作、终端操作、流程自动化。
Opus 级模型:
高价值、高不确定性、高风险任务,例如复杂架构判断、关键代码审查、困难故障定位。
真正的分层不是"小模型、强模型、最强模型",而是:
对话层、工具层、执行层、审查层、兜底层。
6. 对 AI 产品的影响
第一,代码 Agent 会继续降价。
Claude Code、Cursor、Devin、Codex 这类产品的成本核心之一,就是模型调用成本。只要 Sonnet 级模型能承担更多执行任务,产品就可以把更多 Agent 能力下放给普通用户,而不是只放在高价套餐里。
第二,企业自动化会更容易落地。
企业内部很多流程并不需要最强推理模型,但需要稳定执行:查表、写报告、改配置、生成工单、同步 CRM、检查合同、汇总数据。Sonnet 5 这类模型适合做这类"中高复杂度但高频"的执行层。
第三,本地模型不会被淘汰,但定位会更清晰。
本地模型的优势仍然是低延迟、隐私、可控、低边际成本。云端强模型的优势是复杂任务成功率。未来不是本地和云端二选一,而是本地模型做前置路由、实时交互和轻任务,云端 Agent 模型做复杂执行。
第四,模型评测会从"智商榜"转向"任务闭环榜"。
未来开发者更关心的问题会是:
能不能连续工作 30 分钟不跑偏?
能不能正确使用终端?
能不能读懂大型代码库?
能不能修复测试失败?
能不能发现自己没完成?
能不能少用 token 完成同样任务?
能不能在失败后恢复,而不是从头乱来?
这些指标比单轮 benchmark 更接近真实生产力。
7. 风险没有消失,权限边界反而更重要
Agent 能力下放,也意味着风险下放。
模型越会使用工具,越能执行长期任务,就越需要权限边界、审计日志、沙箱环境、回滚机制、人工确认点。
尤其是代码 Agent 和企业 Agent,不能因为模型变便宜就直接放权。
一个成熟的 Agent 系统,至少要有几层保护:
读写权限分离
危险命令拦截
文件修改 diff 审查
工具调用日志
任务预算限制
失败重试上限
关键操作人工确认
模型输出和真实执行状态分离
最终结果验证
Anthropic 在 Sonnet 5 新闻稿里也提到安全评估:Sonnet 5 相比 Sonnet 4.6 在 Agent 安全方面有改进,也启用了网络安全相关防护。与此同时,官方仍然建议需要更少防护的网络安全工作使用 Opus 4.8。
从工程角度看,这说明一个现实:
模型只是 Agent 系统的一部分。
真正可用的 Agent,是有状态、有权限、有观察、有回滚、有评估、有成本控制的执行系统。
8. 结论:Agent 不再只是旗舰模型的炫技能力
Claude Sonnet 5 的发布,说明一个趋势正在加速:
前沿模型的 Agent 能力,
正在从旗舰模型独占,
扩散到更便宜、更适合高频调用的中档模型。
这会让复杂任务自动化的单位成本下降,也会让 Agent 产品从演示走向日常使用。
对开发者来说,最重要的启发不是"马上把所有任务切到 Sonnet 5",而是重新设计模型路由:
不要只按强弱分层。
要按任务类型和执行属性分层。
不要只看 token 单价。
要看每次成功任务的成本。
不要只评估回答质量。
要评估工具调用、长任务稳定性、失败恢复和验证闭环。
本地 Qwen / vLLM 仍然适合做低延迟、低成本、可控的基础层。Claude Sonnet 5 这类模型更适合做云端强执行层。Opus 级模型则适合做高价值、高风险、高不确定性的最终兜底。
未来的 AI 系统,不会是一个模型打天下。
它会更像一个调度系统:
便宜模型负责感知和分流。
中档 Agent 模型负责执行。
旗舰模型负责判断和兜底。
本地模型负责实时交互和隐私边界。
Claude Sonnet 5 的真正信号是:
Agent 不再只是旗舰模型的炫技能力,
而开始变成可以规模化部署的基础能力。
参考来源
- Anthropic: Introducing Claude Sonnet 5, 2026-06-30,
https://www.anthropic.com/news/claude-sonnet-5 - Claude Platform Docs: Pricing,
https://platform.claude.com/docs/en/about-claude/pricing - Anthropic: Introducing Claude Opus 4.8,
https://www.anthropic.com/news/claude-opus-4-8
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| Agent 任务"假完成":模型没真正跑通却说成功 | 缺乏最终验证步骤,模型倾向于直接宣称 done | 检查命令真实返回 / 测试结果 / 文件实际修改 | 加 diff 审查 + 测试用例执行;强制模型标注未确认项 |
| 简单任务被路由到 Opus 级,token 账单爆炸 | 路由仅按"模型强弱"分层 | 统计每个任务的 cost per success | 改为按执行属性分层(对话/工具/执行/审查/兜底) |
| Agent 上下文失控,token 量随轮次指数增长 | 多轮递归累积 + 缺乏任务预算 | 监控 prompt_tokens / completion_tokens 趋势 | 启用 prompt caching + 设置任务 token 上限 + 关键状态外置 |
| 工具调用失败后模型卡死或乱试 | 缺乏失败恢复策略 | 查看失败重试日志 | 设失败重试上限 + 显式工具失败处理 prompt + 关键步骤人工确认 |
| 危险命令被执行(rm -rf、修改系统文件等) | 权限边界缺失 | 审计工具调用日志 | 沙箱环境 + 危险命令拦截列表 + 读写权限分离 |
| Sonnet 5 切换后账单明显上涨 | 新 tokenizer 使同内容 token 量升至 1.0–1.35× | 比对相同 prompt 的 token 消耗 | 对自身用例做基准测试;优惠期定价大致维持成本中性 |
| 网络安全类任务由 Sonnet 5 执行,存在越权风险 | Sonnet 5 网络攻击能力高于 4.6,未做专项训练 | 检查任务是否涉及漏洞利用、渗透测试 | 默认安全防护已启用;高敏感任务改用 Opus 4.8 或 Mythos |

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)