
Claude Sonnet 5 发布,性能接近 Opus 4.8,价格只有60%
Anthropic 又发新模型了,Claude Sonnet 5。
Sonnet 系列里最强的 agentic model,也是新一代主力模型。
按照 Anthropic 的定位,Sonnet 5 面向的是日常高频工作流,主打编码、工具调用、浏览器/终端使用、规划、知识工作。
老规矩,先看下模型表现。
Sonnet 5 比 Sonnet 4.6提升明显,很多指标已经贴近 Opus 4.8。
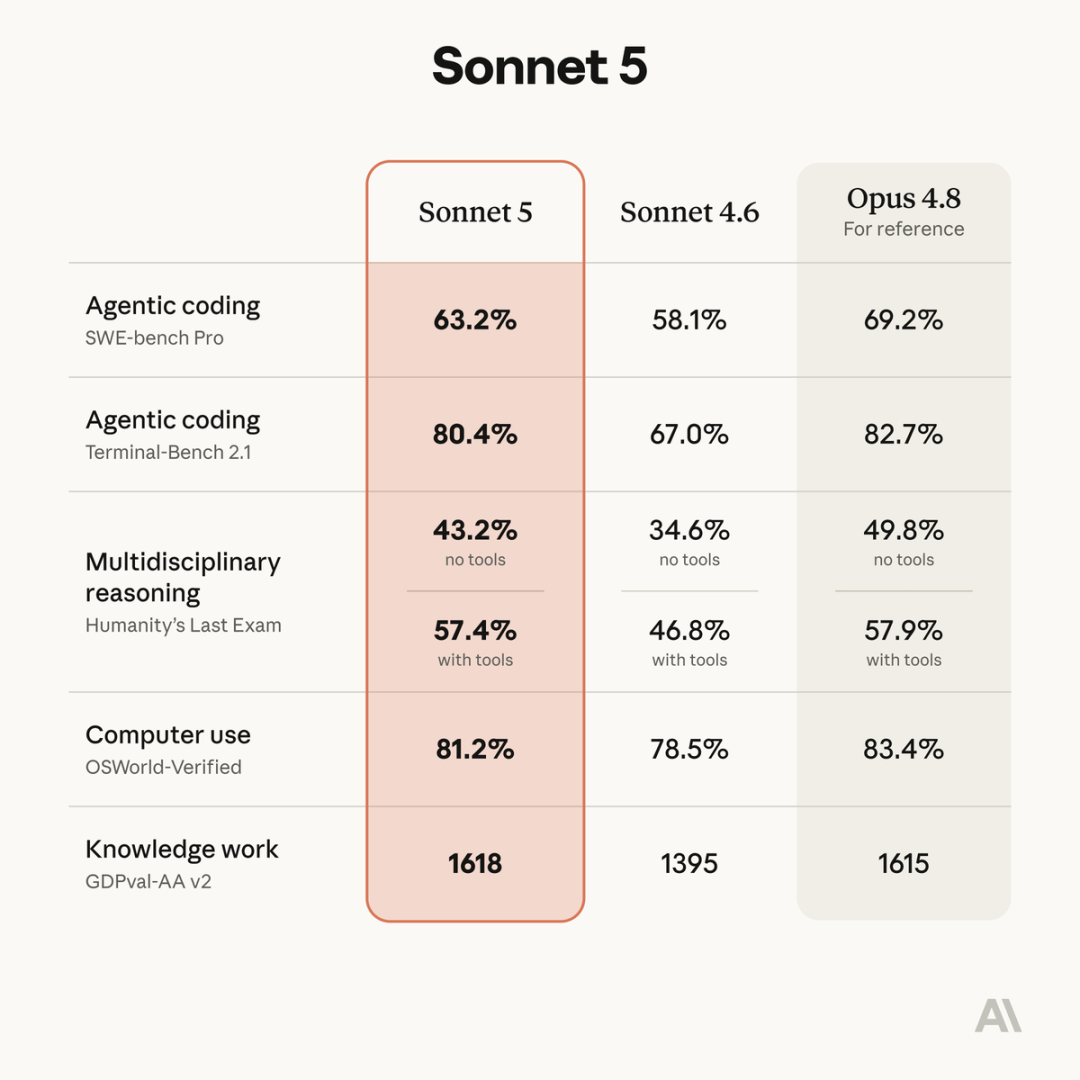
在 agentic coding 上,Sonnet 5 的 SWE-bench Pro 得分是 63.2%,高于 Sonnet 4.6 的 58.1%,距离 Opus 4.8 的 69.2% 还有差距。
多学科推理也有明显提升。
Humanity’s Last Exam 不用工具时,Sonnet 5 是 43.2%,Sonnet 4.6 是 34.6%,Opus 4.8 是 49.8%。
开工具之后,Sonnet 5 直接到 57.4%,已经非常接近 Opus 4.8。
计算机使用能力也有进步。
OSWorld-Verified 上,Sonnet 5 是 81.2%,Sonnet 4.6 是 78.5%,Opus 4.8 是 83.4%。
同时,单任务成本Sonnet 5 的曲线已经贴近 Opus 4.8,API价格更低的情况下,Sonnet 5或可以作为 Opus 4.8 的替代选项。
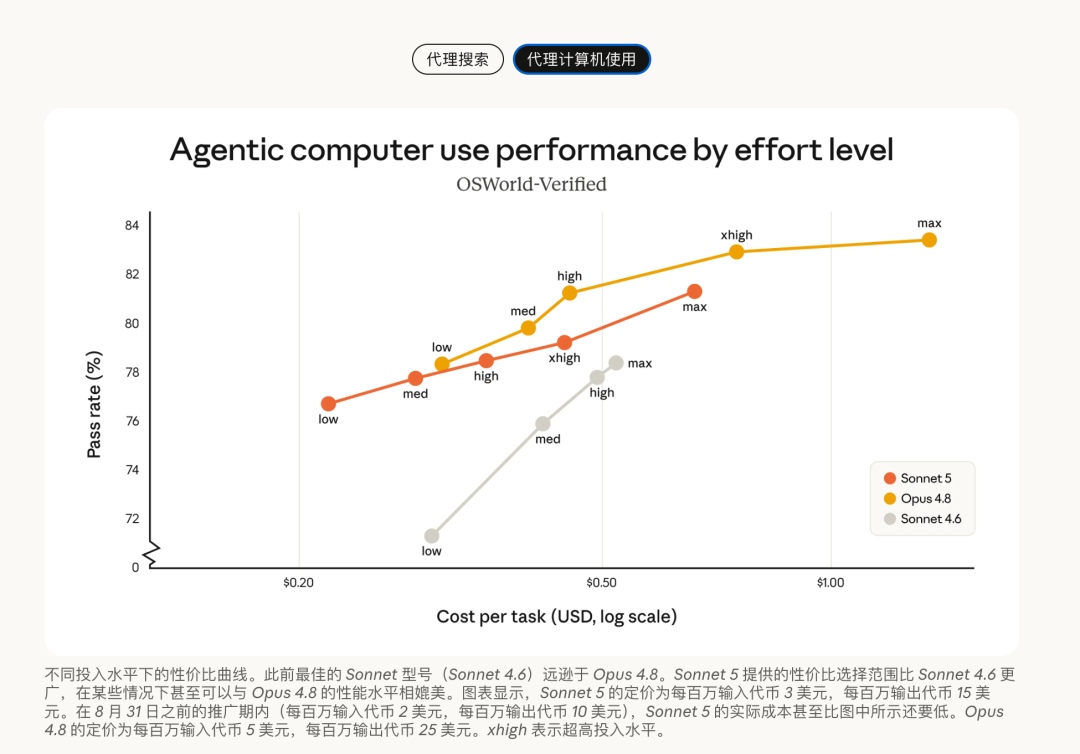
这对应浏览器、桌面、终端这类操作场景。对 AI agent 来说,这类能力比普通聊天重要得多。
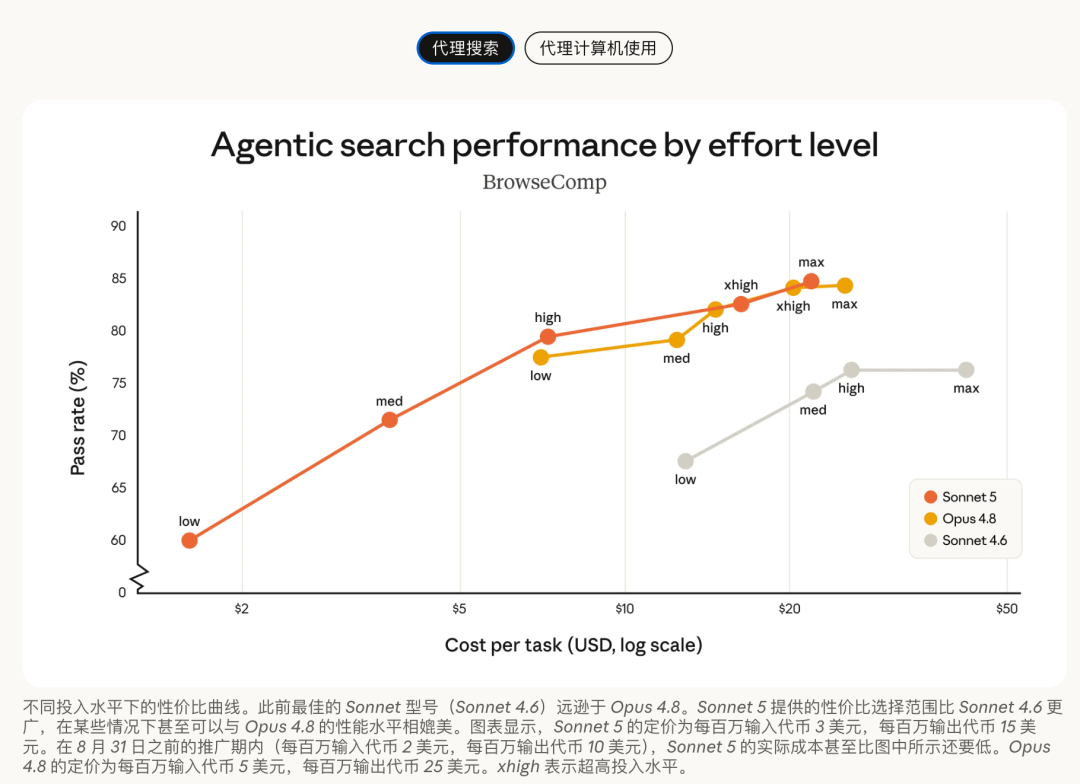
Agentic search 搜索任务下,Sonnet 5 在 high / xhigh / max 档,也是接近 Opus 4.8的表现。在部分 effort 档位上,Sonnet 5 用更低成本拿到接近 Opus 4.8 的效果。
再看第三方榜单。
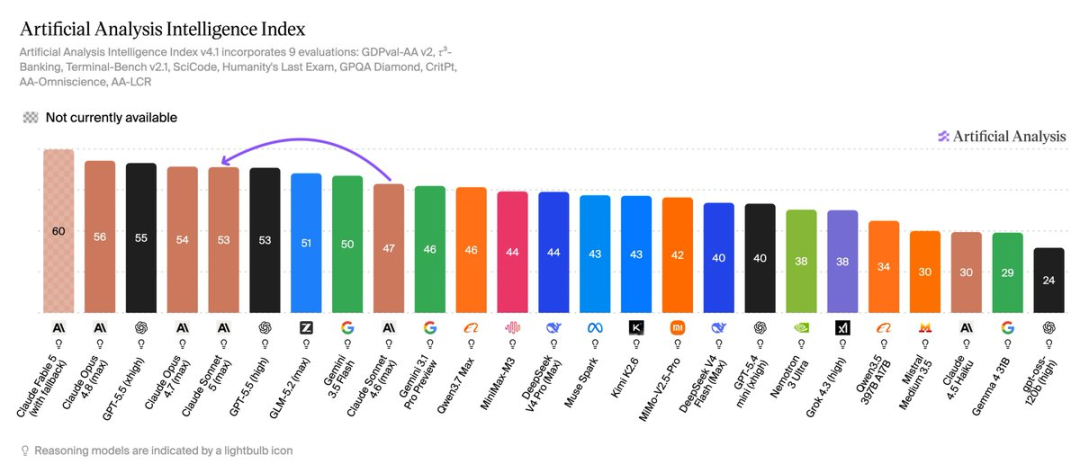
Artificial Analysis Intelligence榜单排名结果里,Claude Sonnet 5 max 得分 53。
这个分数和 GPT-5.5 high 同档,低于 Claude Opus 4.8 high 、GPT-5.5 xhigh、Claude Opus 4.7 max。
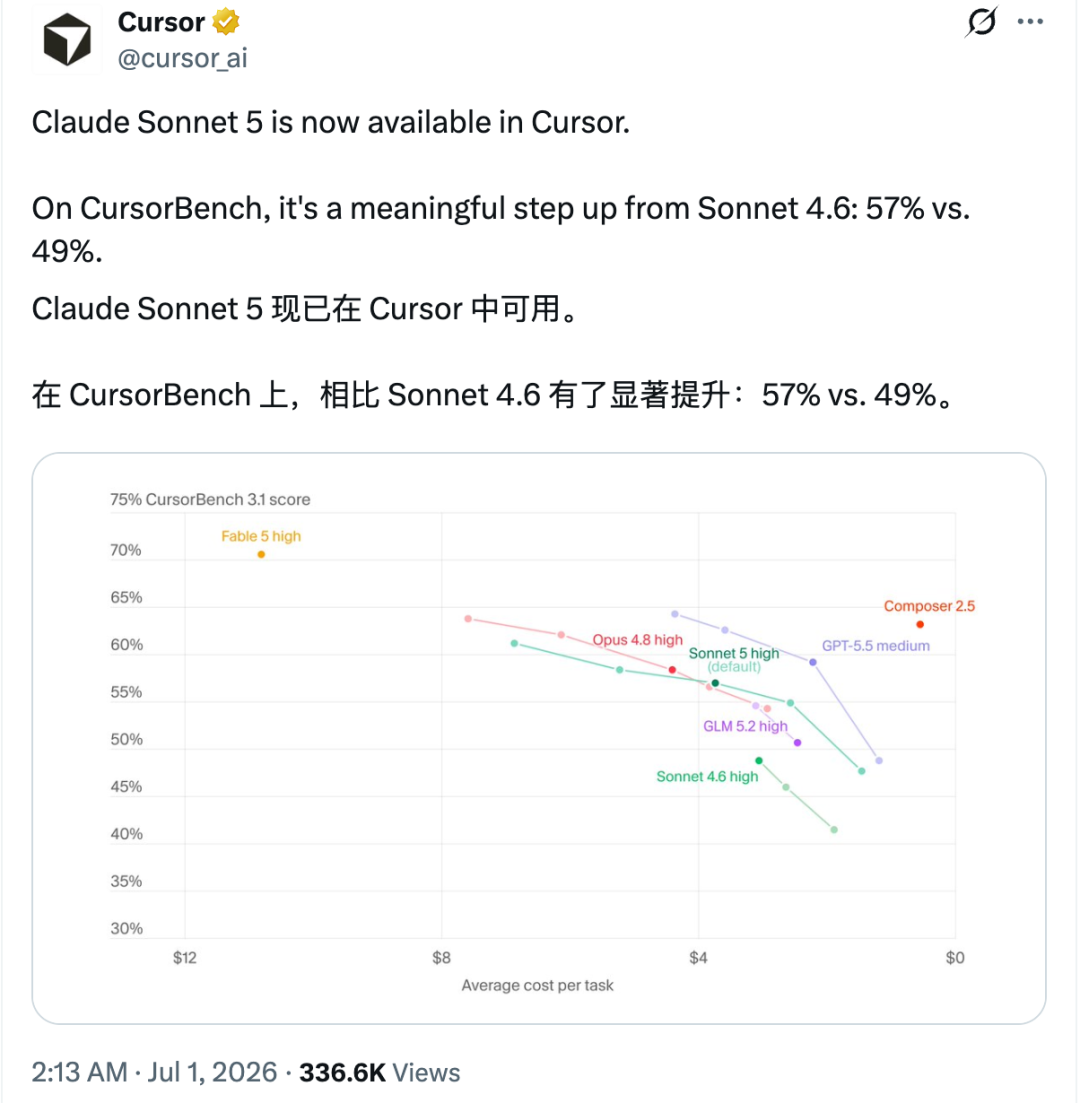
Cursor 官方宣布,Claude Sonnet 5 现在已经在 Cursor 中可用。
同时他们给了一组 CursorBench 3.1 数据,Sonnet 5 是 57%,Sonnet 4.6 是 49%,相比 Sonnet 4.6 是明显升级。
Sonnet 5 high default 的位置,在 CursorBench 3.1 上已经接近 Opus 4.8 high,但平均单任务成本更低。
Sonnet 5 的标准价格是 Opus 4.8 的 60%,发布初期还有更低的优惠价。
2026 年 8 月 31 日前,Sonnet 5 的价格为每百万输入 token 2 美元、每百万输出 token 10 美元,约为 Opus 4.8 的 40%。

有推特网友跑了一个对比case,通过 CLI 在 UltraCode 模式下运行了Opus 4.8和 Sonnet 5两个模型, 任务是给 Sonnet 5构建一个单一 HTML 登录页面。
效果明显Opus 4.8更胜一筹,但是Sonnet 5速度更快、花费更少。
Claude Sonnet 5:
-
tokens使用量:20.9k 输入,14.2k 输出
-
总成本:3.36美元
-
耗时:2 分 11 秒
Claude Opus 4.8 Ultracode:
-
tokens使用量:96.3k 输入,73.8k 输出
-
总费用:20.66美元
-
经过的时间:20 分 15 秒
但是另一组数据表现相反。
按 Cost per Intelligence Index Task 算,Claude Sonnet 5 max 单任务成本是 2.29 美元,Claude Opus 4.8 max 是 1.80 美元,GPT-5.5 xhigh 是 1.03 美元,GLM-5.2 max 是 0.48 美元。
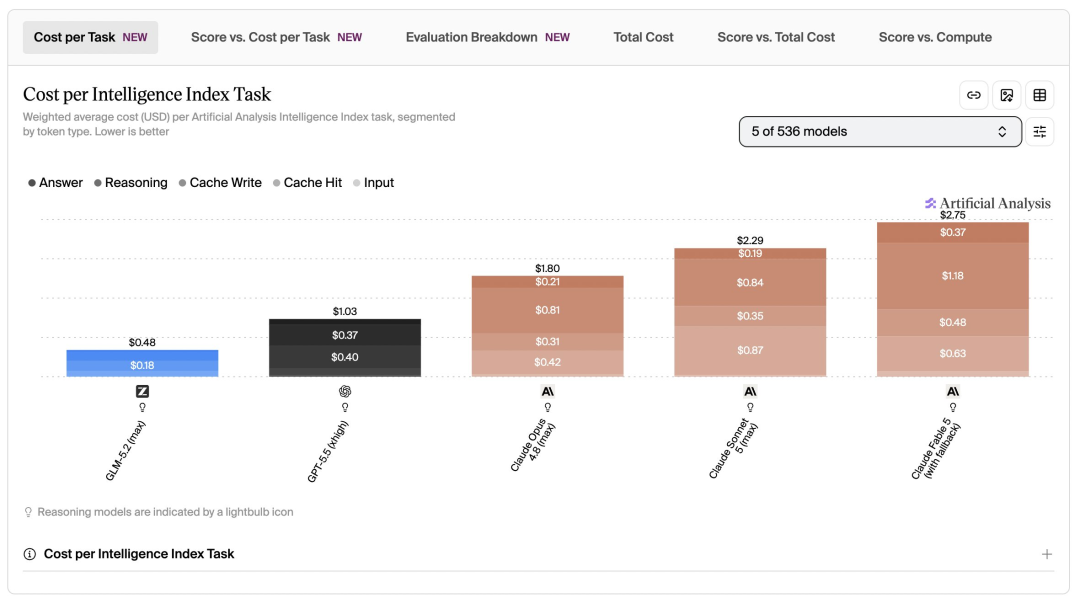
这说明一件事,不能只看 API 单价。
Sonnet 5 的标价低于 Opus 4.8,但在具体 benchmark 任务里,实际成本还会受输出量、推理量、缓存和调用方式影响。
这次Sonnet 5 也是全平台上线,直接被推成主力默认模型。
Claude Free 和 Claude Pro 用户默认模型会切到 Sonnet 5。
Max、Team、Enterprise 用户也能用。
Anthropic 同步上调了 Chat、Cowork、Claude Code 与 Claude Platform 的速率限制,以适配更高 effort 等级带来的 token 消耗。
另外,Claude API、Claude Platform on AWS、Amazon Bedrock 新 Messages API、Google Cloud、Microsoft Foundry preview等平台都可以使用,基本覆盖现在主要的企业和云平台渠道。
开发者侧,Claude Code 和 Claude Platform API 都支持 Sonnet 5。
上下文窗口也直接拉满。
Sonnet 5 默认支持 1M token context window。
这对 agent 任务很关键。长任务里不只是要塞很多资料,还要保留过程状态,比如改过哪些文件、跑过哪些命令、哪些方案已经失败、用户补充过什么限制。
需要注意的是,Sonnet 5 启用了更新后的分词器(tokenizer),同样的文本会被切成更多 token。
Anthropic也 表示促销价的设计意图,是让从 4.6 迁移到 5 的实际成本「大致持平」。
安全方面,Anthropic 的安全评估显示,Sonnet 5 整体优于 Sonnet 4.6:
在代理安全方面,它更善于拒绝恶意请求、抵御提示注入(prompt injection)中的劫持企图,幻觉率与谄媚(sycophancy)倾向也更低。
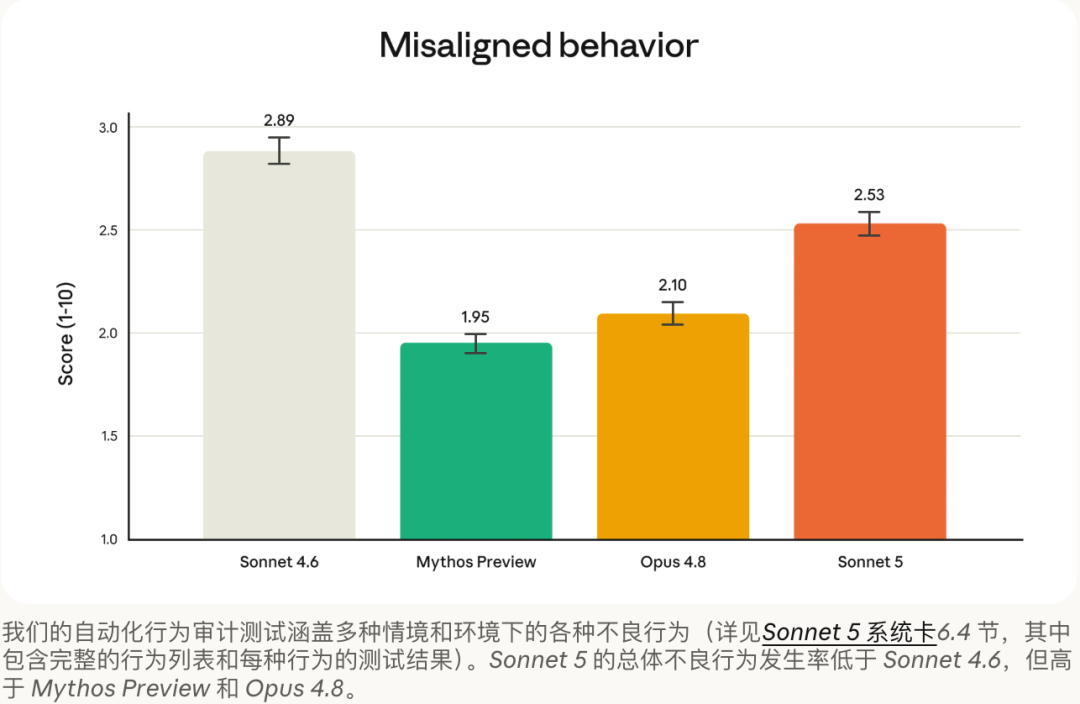
在覆盖广泛失准行为的自动化行为审计中,Sonnet 5 的总体得分更「安全」。不过相比能力更强的 Opus 4.8 与 Claude Mythos Preview,它在该项评估上的失准行为率仍略高一些。
Sonnet 5的定位很清晰,让agentic能力从必须上贵模型变成中端模型即可。
对成本敏感、又需要稳定执行多步任务的团队,它大概率会成为新的默认选项;而真正吃准确率的高难任务,Opus 4.8 仍是首选。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)