
AI 时代的瓶颈与 Perplexity
1.AI 的瓶颈不是模型能力,是电力基础设施
2.模型不是产品,Orchestration才是关键
3.30人团队可以创造高盈利公司
4.AI Agent 带来的收入最终会超过广告收入
一、为什么"进攻"才是正确答案
1.1 “赢的渴望"胜于"失败的恐惧”
Aravind 被问及"你更被失败的恐惧驱动,还是被胜利的渴望驱动"时,他的回答是后者,原因是:
“我一无所有。我从未想象过自己能做成这些事情。我的人生已经超越了任何想象。”
1.2 永远保持进攻姿态
信奉的原则:
- 永远不要防守
- 全力以赴
- 持续进攻
当被问到"今天你在哪些方面不够激进"时,他承认早期在社交媒体上对 Google 的批评过于高调,但那是刻意的策略——因为 Google 根本不在乎一个"小公司"的批评,这反而帮助 Perplexity 获得了关注
1.3 AI 领域没有舒适区
“在 AI 领域,没有人能坐享其成。即使是 Anthropic,如果他们认为 Claude Code 已经赢了,6-12 个月后他们可能就不存在了”
这是这个领域"令人不舒服"的事实——没有谁能放松。
二、Perplexity 如何改变了 Google
Aravind 表示:
“Perplexity 改变 Google.com 的程度,超过了 Google 历史上任何产品经理所做的。”
他指出,现在 Google 的 AI Mode 看起来和 Perplexity 一模一样:
- 字体
- 引用格式
- 行内文本和超链接
- 建议的后续问题
整个体验都在模仿 Perplexity,但"质量仍然不如"
2.2 为什么这是好事
他并不为此感到不快,原因在于:
- 2024年底早就预料到这会发生
- "答案引擎"只是起点,不是终点
- 前沿在转移——从"回答问题"到"替你工作"
“AI 的前沿不再是回答问题,而是真正出去为你完成任务。”
用户订阅 Perplexity Pro 或 Max,不是为了获取答案,而是为了:
- 获得复杂的研究报告
- 使用能代替他们执行任务的 Agent
三、真正的瓶颈:电力与基础设施
3.1 电力是第一瓶颈
Aravind 反复强调:当今最大的问题是电力短缺。
建设一个数据中心不仅仅是购买芯片,需要:
- 购置或租赁土地
- 与电力供应商/电网合作
- 处理冷却系统
- 获得各种许可
所有这些都比购买芯片慢得多。
3.2 数据中心建设的物理限制
他提到:
- 40% 的数据中心项目因为公众阻力而无法推进
Blackwell架构的模型(如 Llama)已经很"可怕"Rubin 架构(明年)会更强大- 模型训练需要百万级 GPU
“物理基础设施的建设时间总是限制前沿能力。”
3.3 公众阻力来自哪里
他认为数据中心的阻力被误导了:
- 人们错误地认为数据中心消耗大量水资源
- 电费上涨归咎于数据中心建设
- 实际原因是多方面的:就业担忧、财富不平等恐惧、环境问题等
这导致电力成为持续的瓶颈。
3.4 未来的瓶颈预测
当被问及"三年后我们没讨论的瓶颈是什么"时,他的回答是:电力将继续是瓶颈。
除非数据中心的建设方式发生根本性变化,否则这种情况不会改变。
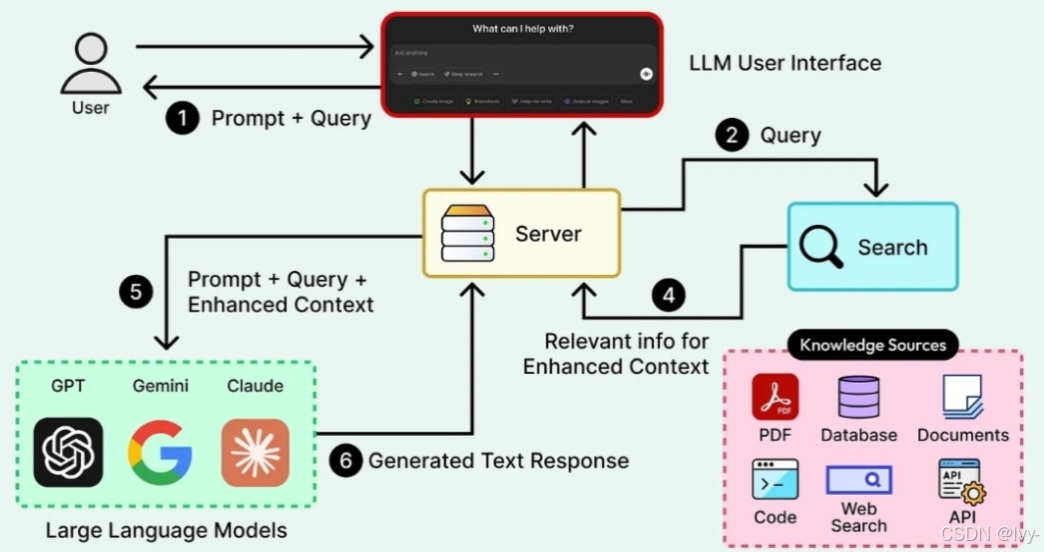
四、编排问题:AI 的真正价值所在
4.1 模型不再是产品
Greg Brockman 最近发推说"模型不再是产品",Aravind 完全同意这个观点:
“如果你只是一个模型 Token 的转售商,你没有业务。因为模型会被商品化。”
即使你是模型构建者,如果你只是转售原始模型输出,也没有业务。
4.2 Agent Harness
以 Codex 或 Perplexity Computer 为例,它们是编排系统:
- 将模型与 Agent 工具结合
- 定义 Agent 循环如何运行
- 管理技能、子 Agent 和连接器
- 决定访问哪些工具
没有 Harness,模型的内置智能无法被有效转化为有价值的输出 Token。
4.3 Perplexity 的差异化
编排策略:
- 跨模型编排:Anthropic 和 OpenAI 不能声称做到这一点——你不会在 Claude Code 的 Harness 里找到 GPT-5,也不会有 Claude Opus 4.7/8 在 Codex 里
- 但会在 Perplexity Computer 里找到两者
- 跨工具和连接器编排
4.4 指标:每瓦每用户的 Token 价值
“谁用最少的电力生产最有价值的输出 Token,谁就创造最大价值。”
这是一个编排问题
4.5 24/7 AI 如何实现
大多数人担心 AI 会"做疯狂的事情",但真正的担忧是成本——没有人能负担得起一直运行前沿 AI。
解决方案:
- 本地模型处理日常任务
- 服务端模型处理复杂任务
- 编排层协调两者
“构建一个持续学习的本地模型,在必要时才调用服务端前沿模型”
五、Agent 的使用与价值创造
5.1 权力用户的行为
Perplexity Computer 上有用户每月花费超过 10,000 美元。这不是浪费钱,他们的业务就是靠这些 Agent 循环运转的。
这些用户创建的多 Agent 层级和 Agent 循环,看起来像是自己的软件架构。
5.2 区分高价值用户的关键
使用 Agent 做重复性 cron 任务 vs 一次性任务:
- 一次性任务:委托一个任务,完成即止
- 持续任务:AI 持续监控,触发事件时自动执行
例子:
- 每次收到入站邮件自动分类
- 检测到延迟尖峰时自动进行根因分析
- 识别并通知相关工程师
5.3 规模预测
这些产品不会拥有 1 亿用户。但它们产生的收入将超过 Google 或 Meta 的广告收入。
5.4 Token 支出占工资比例的演变
Marc Benioff 提到 Salesforce 在 Anthropic 上花费 3 亿美元(约占开发者工资的 3.8%)
Aravind 预测:
- 如果保持在 3.8%,Anthropic/OpenAI 不会是 5 万亿美元公司
- 如果达到 100%(如 Brandon McCarthy 预测),他们将成为 10 万亿美元公司
但成本可能下降,因为:
- 开源模型性能提升,价格更低
- 更好的 Harness 弥补模型差距
永远会为前沿付费,但前沿在不断变化
六、基础设施层的价值
6.1 为什么 Micron 可能比 Meta 更有价值
Aravind 认为 Micron(内存供应商)在未来 6-12 个月可能比 Meta 更有价值:
- HBM 内存价格已经涨了 5 倍
- 瓶颈定价
- 内存是当前最稀缺的资源之一
6.2 CPU 的回归
由于 Agent 大量使用 CPU:
- Agent 生成代码后,在 CPU 上执行
- 下载文件、处理数据、生成图表、托管网站——全部在 CPU 上运行
“Agent 使用 CPU 的比例比人类还高。”
这让 Intel 和 AMD 重新成为受益者。
6.3 数据中心供应商的可持续性
CoreWeave 等公司可以持续,但:
- 不能只是服务器租赁商
- 需要在软件层进行编排
- 需要获得 100,000 GPU 的容量保证
- 需要创新发电层
AWS 的名字是"Amazon Web Services",不是"Amazon Servers"——软件编排才是价值所在
6.4 推理层能否独立存在
可以,但有条件:
- 假设需要 100 亿美元收入(约 10 亿美元利润)
- 开源模型必须持续强大
- 如果开源与前沿差距超过 12-15 个月,这些公司就会失去商业模式
七、出口管制
7.1 短期效应
出口管制帮助美国保持领先:
- 创造了开源与前沿之间 12 个月的差距
- 让
中国公司无法获得最新的 GPU 和 HBM
7.2 长期风险
原因:
- 中国被迫在硬件层垂直整合
- 他们在华为栈上构建
- 架构更加内存高效
- KV Cache 创新——可以放在 SSD 上,不需要 HBM
- 训练算法不依赖高带宽互联
建立完全不同的推理架构和存储架构
7.3 AI 的物理维度
Aravind 认为美国低估了中国的能力,因为 AI 不只是数字的,还包括:
电力 ,许可证 ,劳动力 ,专业知识 ,建设速度,晶圆厂,机器人,芯片,能源利用…
中国在这些领域都有优势
7.4 TSMC 在美国的角色
- TSMC 正在亚利桑那州建设工厂
- 投资 1500 亿美元
- 已经投入 400-600 亿美元
- 美国政府持有 Intel 10% 股份
八、小团队创造大价值
8.1 Perplexity 的示范效应
- 400 人创造 200 亿美元公司
- 理论上:40 人可以创造 10-20 亿美元公司
- 4000 人可能创造 2000 亿美元
8.2 创业门槛的改变
“如果你曾经无法创业的原因是’需要雇佣很多人、需要租办公室’——这种情况在历史上第一次改变了。”
现在你可以:
- 和一两个朋友开始
- 真正有机会创建一个 10 亿美元的公司
Perplexity 自己起步时获得了约 100 万美元的云计算积分。
8.3 Perplexity 的"Billion Dollar Build"计划
他们正在向任何有可信路径创建 10 亿美元公司的团队提供 100 万美元云计算积分。
8.4 未来企业结构
最佳公司会:
- 更加精简高效
- 员工数量大幅减少
- 但每个团队价值更高
“我宁愿有 100 万人分成 1000 个团队,每个团队值几亿美元。”
九、广告模式的未来
9.1 为什么聊天界面不适合广告
- 发现模式不同:旅行/购物需要"探索",而非"对话"
- 用户意图不同:浏览 Instagram vs 问 ChatGPT 问题
- 信任问题:
当你需要准确答案时,广告会破坏信任
9.2 客观 vs 主观判断
| 类型 | 决策特点 | 商业模式 |
|---|---|---|
| 客观决策 | 基于事实和数据 |
Agent 颠覆 |
| 主观决策 | 基于审美和感受 | 广告支撑 |
旅行、购物、时尚——大多数仍然是主观的。任何基于客观判断的交易都会被 Agent 颠覆。
9.3 对 Meta 的影响
Meta 正在推出 $200/月的 Agent 产品,这说明他们意识到订阅模式才是出路。
十、Agent 流量时代的互联网
10.1 Cloudflare 的数据
Agent 流量已经超过人类流量,这个变化来得比预期更快。
10.2 网站不会消失
Aravind 认为:
- 网站不会消失
- 设计仍然重要
- 广告模式不会完全死亡
因为:
- 主观内容(时尚、家具)仍然需要人类浏览
- Agent 流量会替代客观搜索,但不会替代所有互联网活动
十一、OpenAI 的 IPO 问题
11.1 为什么 OpenAI 没准备好 IPO
他明确表示OpenAI 没有为 IPO 做好准备,原因:
- 虽然是主导消费产品,但没有钱
- ChatGPT 已经被商品化
- 收入来源:用户订阅 + Codex(代码执行)
11.2 消费 AI 没有钱
“在非广告领域——订阅或使用量计费——钱在前沿。今天的前沿是替你完成任务。”
11.3 Perplexity 的 IPO 时间表
- 目标:2028 年或更早
- 收入增长比盈利能力更重要
- 公开市场目前更看重
收入增长而非利润
十二、Perplexity 的技术路线
12.1 自训练模型
Perplexity 正在:
- 基于
顶级开源模型进行后训练 - 目标是减少对前沿模型 Token 的依赖
- 保持前沿模型用于新能力探索
“今天产品中已有的功能,我们期望完全依赖自己拥有和服务的模型。这将是降低成本和增加利润的最佳方式。”
12.2 收入与成本
- 自今年年初以来收入增长超过 3 倍
- 成本消耗减少超过 50%
- Anthropic 模型进步对他们是好事
- OpenAI 竞争降低同等能力成本,也是好事
12.3 开源模型的持续改进
“如果开源模型停止变得强大,如果它们与前沿的差距超过 15-18 个月,那这些推理公司就没有商业模式。”
十三、对竞争对手的看法
13.1 Google 的 AI 问题
Google 具备所有成为最低成本 Token 生产者的条件:
- 自有 TPU
- 自有数据中心
- 自有网络
- 自有电力采购
但他们严重低估了代码模型的重要性,目前在前沿之外。
13.2 Anthropic 的生存危机
“如果 Anthropic 认为 Claude Code 已经赢了——6-12 个月后他们可能就不存在了。”
**前沿模型提供商只有在前沿时才有价值。**如果 6 个月没有新能力,就是危险的信号。
13.3 对 Cursor 的评价
当被问及 San Francisco 的 AI 聚会上有人说 Perplexity 是"最容易失败"的公司时:
“Cursor 可能会被收购。xAI 是我的孩子。”
而 Perplexity:
- 收入增长 3 倍
- 成本消耗减少 50%
“大多数参加这些聚会的人实际上不构建任何有用的东西。”
十四、关于财富与公平
14.1 财富分配的思考
他承认对财富不平等的担忧,但认为解决之道是**广泛分配利益**。
他分享了一个真实故事:
- 一位 Uber 司机看了他的 YouTube 采访
- 学会了如何用 AI 从零开始构建 Web 应用
- 现在做 App 获得的被动收入比开 Uber 还多
- 他减少了开车时间,因为更喜欢编程
14.2 信念
“如果你持续只报道负面消息——AI 和不平等——人们只会想到坏事。所以,如果你认为自己做得不错,就应该多谈谈积极的可能性。”
“普通人更需要的是看到可能性,然后受到激励去行动。”
14.3 财富观
“财富不会激励我。影响力才会。”
十五、学到的
15.1 Elon Musk 的特质
- 极度专注——Twitter 上的表现可能具有误导性
- 每次只关注一个限制性问题
- 忽略其他一切
“这种能力——只关注当下的限制因素,忽略其他一切——非常难学。”
15.2 Jensen Huang 的特质
- 对真相极度渴求
- 每天醒来告诉自己"我很糟糕"
- 公司值 5 万亿美元,却用"
公司 30 天内可能倒闭"的思维经营
“这就是成为 Jensen Huang 所需的。”
15.3 共同点
两人都有宏大的长期愿景:
- Musk 的太空计划:火星殖民地,百万居民
- 财富只是副产品
“如果你的成功定义是’赢得比赛然后卖掉公司’,然后就待在家里——你的孩子不会受到激励去行动。”
十六、AI 时代最重要的技能
16.1 问更好的问题
Aravind 在毕业典礼演讲中提到:AI 时代定义的技能是"问更好的问题"。
16.2 没人问的核心问题
“假设你有大量 Agent 可用,你会做什么?”
这不是技术问题,而是目的问题。
16.3 框架:10 年 vs 10 个月
“如果有人告诉你一件事需要 10 年,问:‘什么能让它 10 个月完成?’”
十七、对垂直 AI 实验室的看法
17.1 不相信大多数"新实验室"
太多只是"为了建实验室而建实验室",没有差异化。
17.2 什么才是值得的
值得投资的垂直模型
- 质疑 Transformer 架构本身
- 质疑是否需要基于 Nvidia GPU
- 针对机器人等特定领域的模型
DeepSeek 是一个例外——他们:
- 是水平模型,不是垂直模型
- 不是从大实验室分拆出来的
- 但他们
提出了非常不同的技术赌注
十八、Perplexity 如何成为 3 万亿美元公司
18.1 路径
“编排层。准确性和编排——这是自公司成立以来一直坚持的两个目标。”
编排层将涵盖:
- 设备
- 芯片
- 模型
- 工具
- 文件
- 连接器
18.2 他自己被问到的终极问题
问:你会拿 SpaceX、Anthropic 还是 OpenAI?
答:SpaceX。
“Anthropic 和 OpenAI 做的事情,其他公司也在做。但 SpaceX 是唯一建造太空基础设施的公司。”
十九、对毕业生的建议
保持好奇心
具体而言:
- 不要被 FOMO(错失恐惧)驱动,试图在短期内最大化收益
- 不要因为看到前沿实验室赚大钱而觉得自己是失败者
还有很多可以构建的东西
附录
| 术语 | 解释 |
|---|---|
| Agent Harness | Agent 编排系统,定义 Agent 循环如何运行、管理工具和连接器 |
| Token Value Per Watt | 每瓦电力产生的 Token 价值,关键效率指标 |
| Orchestration | 编排,跨模型、工具、设备协调任务的能力 |
| HBM (High Bandwidth Memory) | 高带宽内存,GPU 训练的关键组件 |
| KV Cache | Transformer 中的键值缓存,优化推理效率 |
| Agent Loop | Agent 循环,AI 持续监控和响应事件的机制 |
| Cron Jobs | 定时任务,Agent 自动执行重复性工作 |
总结:十个核心takeaways
- 电力是真正的瓶颈——比模型能力更重要
- 模型是商品,编排是差异化——Perplexity 能在同一个产品中使用 Claude 和 GPT
- 前沿在移动——从"回答问题"到"替你工作"
- 小型团队可以做大公司——400 人可以创造 200 亿美元
- 出口管制短期帮美国,长期帮中国——迫使中国垂直整合
- 内存和 CPU 是新瓶颈——Micron 可能比 Meta 更有价值
- 广告不适合聊天界面——信任和用户意图模式不匹配
- 自训练模型降低成本——Perplexity 的策略
- 问问题是核心技能——不是技术能力,而是提出正确问题的能力
- 永远不要防守——这是 Aravind 的信条,也是 AI 时代生存的关键

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)