
Codex Agent 模式完全指南:让 AI 协助完成科研数据分析任务
Codex Agent 模式完全指南:让 AI 协助完成科研数据分析任务
上周五下午,我收到一封邮件。
合作者发来一份实验数据,让我帮忙看看有没有显著性差异,周一组会要用。
我打开表格看了一眼:六组实验,每组三十个样本,Excel 里三个 Sheet,每个 Sheet 几百行。按照以前的流程,我要导入数据、检查缺失值、判断统计方法、跑分析、画图、写结论。认真做下来,至少要占掉一整个下午。
但那天我还有实验要跑。
于是我换了一种做法:把数据交给 Codex 的 Agent 模式,写清楚交付物,然后去做实验。
一个半小时后回来,桌面上多了一个文件夹。里面有清洗后的数据、统计分析结果、几张图和一份分析报告。我检查了二十分钟,改了三处小问题,再发给合作者。
这就是 Agent 模式最吸引人的地方:它不是让 AI 回答得更漂亮,而是让 AI 能围绕一个目标持续执行,最后交付一组可以验收的结果。
先看这张路线图:Agent 模式真正改变的,是你和 AI 的协作位置。
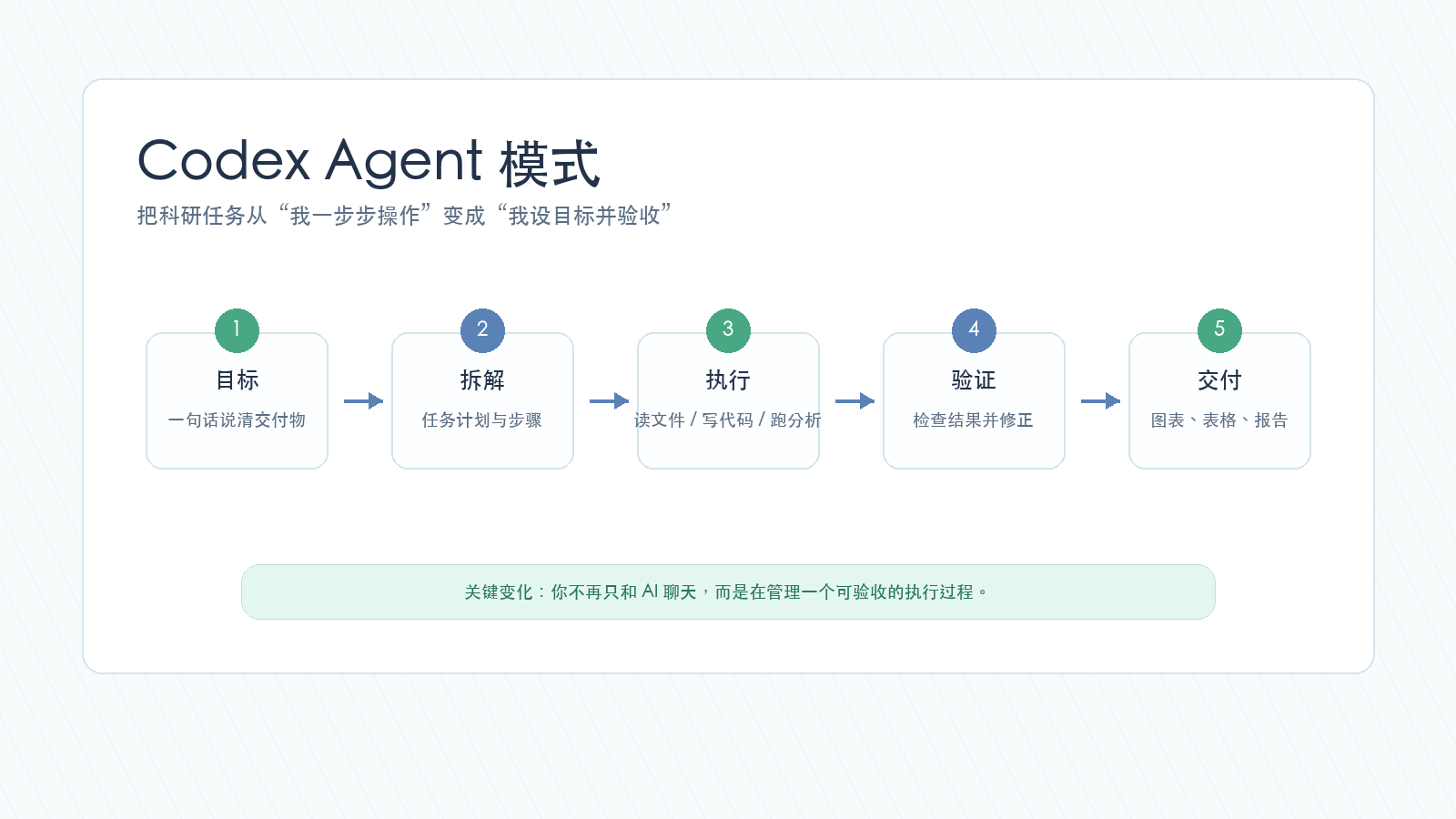
你从“每一步都亲自操作的人”,变成了“提出目标、设定边界、验收结果的人”。
这篇文章,我把 Codex Agent 模式的配置方法、三个科研实战场景、Prompt 写法和避坑经验完整整理出来。
先说结论:Agent 模式适合什么任务
Agent 模式最适合有明确交付物的任务。
比如数据分析、文献元数据整理、批量改文件、生成图表、写初版报告。这类任务的共同点是:过程可以拆分,结果可以检查,中间可能需要读文件、写代码、运行命令。
它不适合完全开放、没有验收标准的问题。比如“帮我想一个很厉害的研究方向”,这种任务更适合先用普通模式讨论,再用 Plan 模式收敛方案。
判断是否适合 Agent 模式,只看一句话:如果这个任务最后应该产出文件、表格、图或报告,就值得让 Agent 试试。
Agent 模式是什么
Codex 里常见的工作方式,可以分成三类。
普通模式是问答。你问一句,它答一句,适合解释概念、改写文字、快速查思路。
Plan 模式是先出方案。你让它设计执行路线,确认之后再让它动手,适合风险稍高或步骤不确定的任务。
Agent 模式是目标驱动执行。你给一个目标,它会拆任务、调用工具、执行命令、检查结果,并在需要你判断的时候停下来。
下面这张对比卡,可以直接帮你判断该用哪种模式。

Agent 模式的关键词是“自主”,但这里的自主不是完全放手。
更准确地说,它是“在你设定的边界内自主执行”。你仍然要负责目标、边界和最终判断。
Agent 模式和普通模式有什么区别
技术上,Agent 模式多了三层能力。
第一是任务分解。它会把一个大目标拆成多个小步骤,再按顺序推进。
第二是自我验证。每完成一个阶段,它会检查输出是否符合要求。如果代码报错、图表不清楚、文件没有生成,它会尝试修复。
第三是工具调用。它能自己决定什么时候读文件、写脚本、运行命令、查看结果,而不是每一步都等你提示。
这三个能力叠在一起,就会出现一种很不一样的体验。
普通模式下,你说“帮我分析这份数据”,它可能会先问你用什么统计方法。Agent 模式下,它会先读数据,判断字段类型和数据质量,再告诉你它准备怎么做。
你不需要把每个操作步骤都写出来,但你必须把“交付标准”写清楚。
配置 Agent 模式:先把边界设好
Agent 模式是 Codex 的内置能力,不需要额外安装。
不过在正式拿它处理科研任务之前,建议先检查四件事。
第一,确认 Agent Mode 已开启。打开 Codex,进入设置里的 Features,确认 Agent Mode 开关处于开启状态。
第二,设置权限级别。Agent 会执行读写文件、运行命令等操作,所以权限策略很重要。我的习惯是:日常操作可以自动执行,删除文件、修改系统设置、联网安装依赖等敏感动作必须确认。
第三,添加默认规则。比如:
使用 Agent 模式时,每完成一个主要步骤,请汇报进度。遇到不确定的统计方法、文件覆盖、依赖安装或数据解释,请先停下来问我。数据分析任务优先使用 Python,并保留可复查的中间文件。
第四,打开 Agent 面板。右侧面板会显示当前任务正在做什么、已经完成什么、下一步准备做什么。这个面板是你验收过程的窗口,建议一直开着。
下面这张清单可以作为开工前检查。

配置不是为了限制 Agent,而是为了让它在正确的边界里发挥作用。
实战一:实验数据统计分析
科研人最容易用上 Agent 的场景,是实验数据分析。
假设你有一份 Excel:三组实验,对照组、处理组 A、处理组 B,每组测了某个指标的变化值。数据里有缺失值,也有少量异常值。
我会这样写需求:
分析这份数据。先检查数据质量,包括缺失值、异常值和分组数量。然后判断三组之间是否有显著差异。如果需要两两比较,请输出事后检验结果。交付物包括:数据质量说明、统计结果表格、箱线图和一段可放进报告里的结论。不确定的统计方法先问我。
这个 Prompt 的重点不是“帮我分析”,而是把交付物说清楚。
Agent 接到任务后,通常会先读表格,汇报数据结构。比如共有多少行、多少列、每组样本量是否一致、是否存在缺失值和异常值。
接着,它会进入方法选择。对于简单独立分组数据,它可能会先检查正态性和方差齐性,再选择 ANOVA 或非参数检验。
下面这张图,把一个相对稳妥的数据分析链路拆成了 6 个节点。
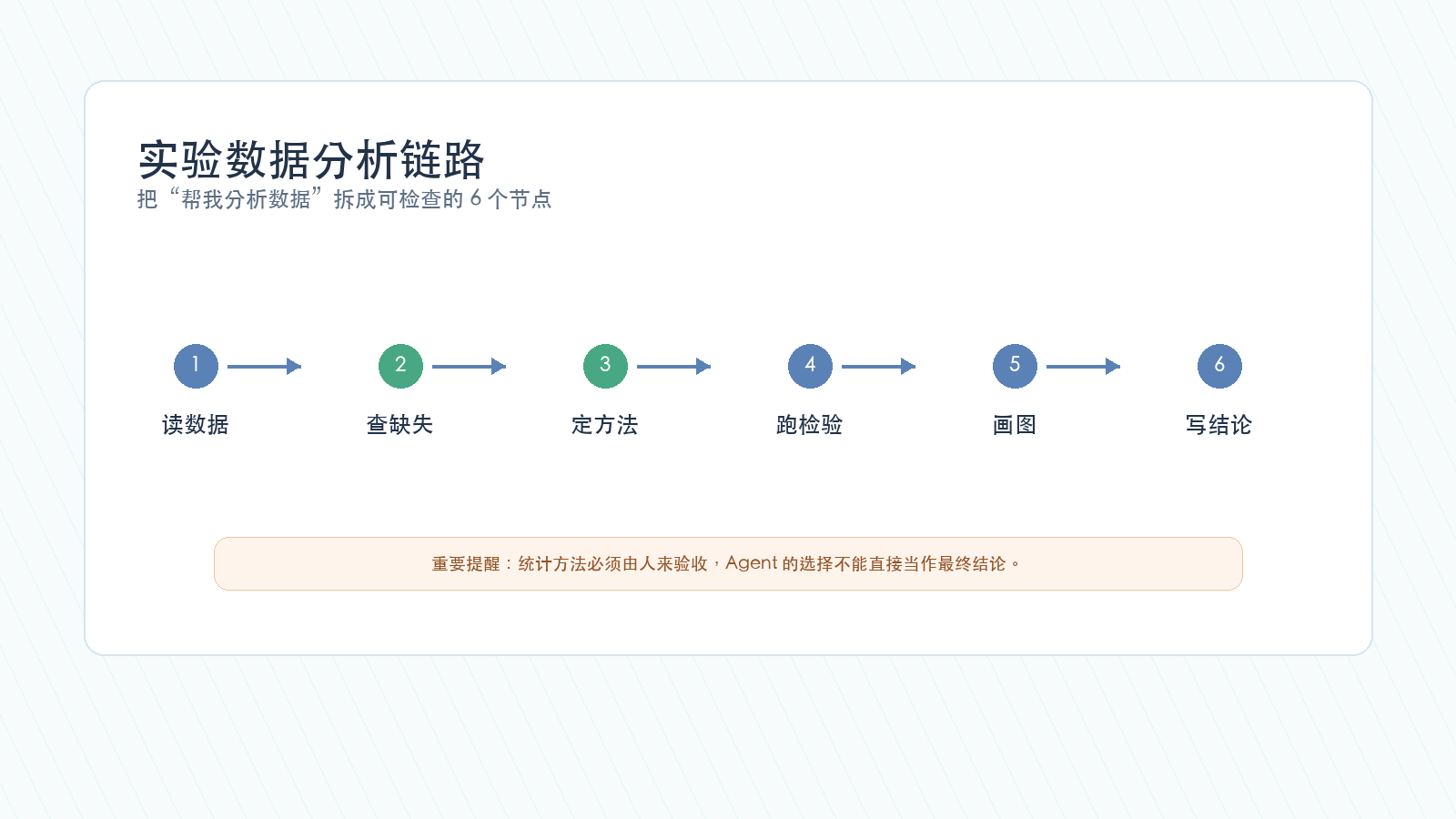
这里最重要的不是 Agent 能不能跑出 p 值,而是你能不能看懂它为什么选这个方法。
如果数据结构复杂,比如重复测量、配对设计、嵌套设计、多因素设计,统计方法就不能让 Agent 自己拍板。你应该在 Prompt 里明确要求:“先给出统计方案,我确认后再运行。”
实战二:文献信息批量获取与整理
第二个适合 Agent 的场景,是文献信息整理。
注意,这里说的是整理公开的文献元数据,不是获取非公开全文。
比如你想整理 PubMed 上某个关键词的前 100 篇文献,可以这样写:
在 PubMed 上搜索
protein-ligand binding affinity deep learning,获取前 100 篇文献的公开信息。整理成 CSV,字段包括标题、作者、年份、期刊、DOI 和摘要。只使用公开 API 和合规访问方式。如果需要邮箱等 API 参数,请先问我。
Agent 通常会先写脚本,通过公开 API 获取结果。如果 API 要求提供邮箱,它应该停下来问你,而不是随便填一个。
拿到数据后,它会整理字段、去重、保存 CSV。有时它还会顺手做年份分布和期刊分布,这类补充分析如果有用就保留;如果偏离目标,就让它删掉。
下面这张流程图,适合贴在文献整理类任务旁边看。
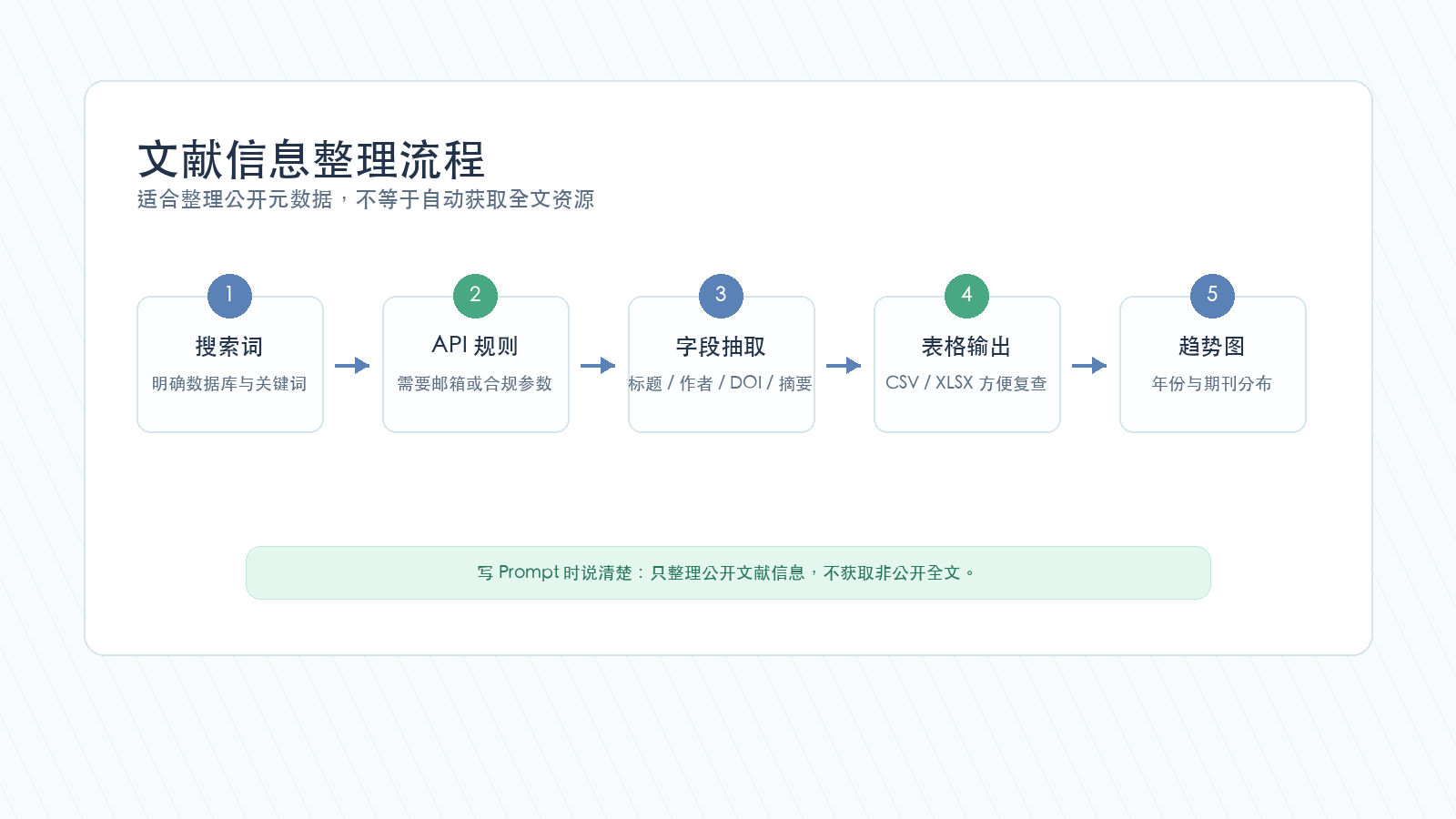
这个场景的边界要说清楚:只整理公开信息,不获取非公开全文,不违反数据库规则。
实战三:数据可视化与报告生成
第三个场景,是把分析、作图和报告放进同一个任务里。
比如你有一份蛋白质表达数据,可以这样写:
分析这份蛋白质表达数据。先检查数据结构和缺失值。然后按 fold change > 2 且 p < 0.05 的标准筛选差异表达蛋白。画火山图和热图,最后写一份 1000 字以内的 Markdown 分析报告。所有输出放到一个新文件夹里,不要修改原始文件。
这个任务很适合 Agent,因为它有明确的交付物:清洗数据、差异分析表、火山图、热图、报告。
Agent 运行过程中,可能会自己发现问题。比如第一次火山图标签重叠,它可以调整标签位置后重新画;热图聚类不清楚,它可以尝试改配色或排序。
但报告里的生物学解释,仍然需要你验收。
下面这张图,把一次任务最后应该交付的东西列出来。
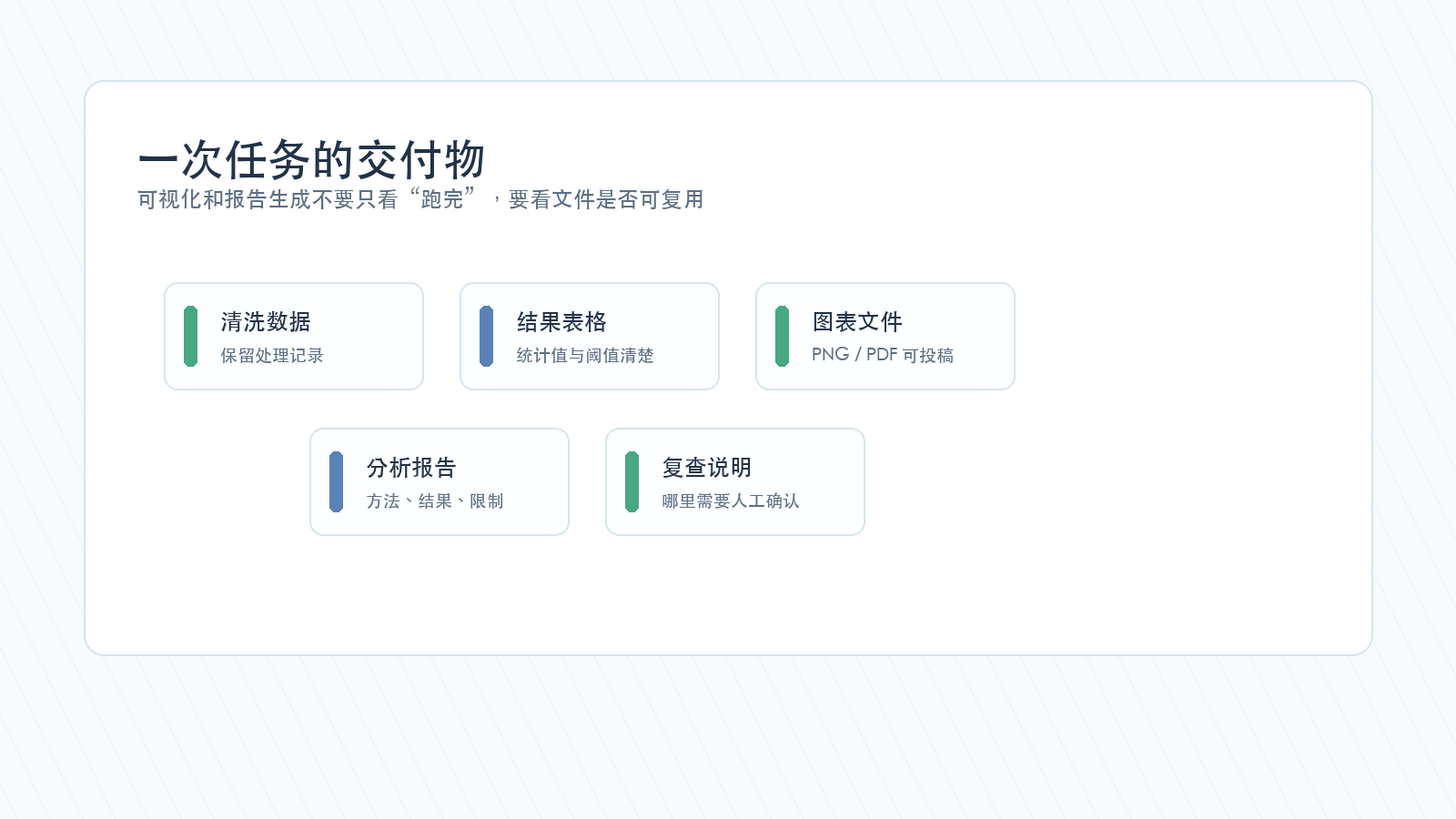
如果最后只得到一段聊天回复,而没有可复查的文件,那这个 Agent 任务就还没有真正完成。
Agent 模式的 Prompt 写法
我用 Agent 模式时,最常用的是“五要素 Prompt”。
第一,目标:这次任务要解决什么问题。
第二,交付物:最后要输出哪些文件、图表或报告。
第三,格式:CSV、XLSX、PNG、PDF、Markdown,尽量写清楚。
第四,边界:不要修改原始文件,不要覆盖已有结果,不确定先问。
第五,验收:先做哪一步,我确认后再继续;哪些结论需要人工复核。
把这五件事写清楚,Agent 就不容易跑偏。

一个可直接套用的模板是:
你要完成的目标是:……
输入文件是:……
交付物包括:……
输出格式要求:……
执行边界:……
遇到以下情况先问我:……
每完成一个主要阶段,请汇报结果和下一步计划。
大任务不要一次跑到底。尤其是科研数据分析,建议分成“数据清洗、方法确认、正式分析、图表生成、报告整理”几个阶段验收。
常见问题与避坑
第一个问题:Agent 跑着跑着卡住了。
通常是某个步骤遇到了它处理不了的情况。打开 Agent 面板,看它卡在哪一步。你可以手动补充信息,也可以让它跳过当前步骤继续。
第二个问题:Agent 选的分析方法不对。
这很常见。Agent 选方法是基于它对数据结构的理解,如果你的实验设计比较复杂,它可能会低估问题。解决办法是:把方法写进 Prompt,或者先让它给统计方案,你确认后再跑。
第三个问题:Agent 生成的代码报错。
Agent 会根据报错信息尝试修复。一般的小问题,它能自己改掉。如果连续修了几次还不行,就不要让它原地循环了,直接让它解释报错原因和下一步方案。
第四个问题:Agent 做了你没要求的事。
Agent 有时会过度补充。比如你只要一张图,它顺手写了一份报告。多做的东西有用就留下,没用就明确说:“删掉这部分,我只保留图表和数据表。”
第五个问题:Agent 输出看起来很完整,但结论可能不可靠。
这是最需要警惕的一点。文件齐全不等于科学结论正确。统计方法、异常值处理、样本分组、生物学解释,都要人工复核。
最后这张边界卡,建议你在第一次使用 Agent 做科研任务时对照看一遍。

总结:你从操作者变成验收者
Agent 模式最有价值的地方,不是让 AI 说得更多,而是让 AI 做得更多。
你给目标,它拆任务、执行、验证、交付。你从“操作者”变成“验收者”。
对科研人来说,这意味着很多重复性工作可以交给 AI 先跑起来:数据清洗、初步统计、文献元数据整理、图表生成、报告初稿。
但它不意味着你可以跳过判断。
Agent 可以帮你节省操作时间,却不能替你承担科学判断。真正稳妥的用法,是把它当成一个会执行的助手,而不是一个自动给出最终结论的权威。
如果你还没试过,可以从一个低风险任务开始:拿一份示例数据,让 Agent 先做数据质量检查和初步图表。看它怎么拆任务、怎么汇报、怎么交付。
等你熟悉它的节奏,再把更复杂的科研工作流逐步交给它。
有使用 Agent 模式处理科研任务的经验,欢迎在评论区交流。尤其是数据分析、文献整理、批量作图这几类场景,很值得互相借鉴。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)