
使用claude太烧钱?如何选择压缩和缓存?
LLMLingua-2 提示词压缩效果评估报告
评估对象:AppAIRouterService 提示词压缩(第 1 层 LLMLingua-2)
压缩模型:microsoft/llmlingua-2-xlm-roberta-large-meetingbank
被测大模型:GLM-5.2、Qwen3.7-max(经 ccswitch 走 Claude Code / Anthropic Messages API)
结论一句话:压缩仅在「首轮 + 长文本」场景有正收益;多轮 / 命中缓存场景压缩会打断缓存前缀,反而增加成本,应跳过。
一、背景与链路
- 客户端经 ccswitch 走 Claude Code,使用 Anthropic Messages API。
- 请求中夹带大量
system提示与tools定义,这两者是 Anthropic 协议的顶层字段,不在messages数组内,因此:- 压缩插件(基于
countPromptTokens(messages))压不到 system / tools; - 但它们每轮都会带上,是输入的绝对大头。
- 压缩插件(基于
- 好在 GLM-5.2 / Qwen3.7-max 支持隐式前缀缓存,重复的 system / tools 除首次外基本命中缓存(
cache_read),走最低价。 - 真正可被压缩的仅是
messages里的对话内容,量不大。
二、实测数据
2.1 Claude Code 场景(Qwen3.7-max,含大额缓存)
| 指标 | 样本 1 | 样本 2 |
|---|---|---|
| 模型总输入 token | 37021 | 35584 |
| 其中缓存命中(cache_read) | 34531(93%) | 34271(96%) |
| 压缩可见输入(beforeTokens) | 8893 | 7257 |
| 压缩节省 token | 658 | 649 |
| 节省 / 总输入 | 1.78% | 1.82% |
| 压缩耗时 | 4107 ms | 3742 ms |
| 输出 token(压缩无关) | 72 | 1369 |
结论:输入 93%~96% 是走缓存的 system/tools,压缩够不着;压缩只在对话正文里省了约 1.8%,却付出约 4 秒延迟。ROI 明确为负。
2.2 短对话对比实验(GLM-5.2,压缩组 vs 未压缩组,各 3 轮,内容相同,rate=0.5)
未压缩组
| 轮次 | 总输入 | 总输出 | 缓存命中 | 花费(元) |
|---|---|---|---|---|
| 第1轮 | 108 | 1.27k | 0 | 0.036452 |
| 第2轮 | 1.48k | 1.30k | 0 | 0.048372 |
| 第3轮 | 2.89k | 1.42k | 1408 | 0.054344 |
| 合计 | 0.139168 |
压缩组(rate=0.5)
| 轮次 | 总输入 | 总输出 | 缓存命中 | 花费(元) |
|---|---|---|---|---|
| 第1轮 | 56 | 1.15k | 0 | 0.032564 |
| 第2轮 | 694 | 1.14k | 0 | 0.037556 |
| 第3轮 | 1.33k | 1.11k | 0 | 0.041780 |
| 合计 | 0.111900 |
关键观察:
- 未压缩组第 3 轮命中缓存 1408 token;压缩组因每轮改写历史,缓存命中恒为 0——证实压缩会打断缓存前缀。
- 本例中压缩组总花费(0.1119)仍略低于未压缩组(0.1392),省约 19.6%。原因是轮次少、历史短、缓存命中量还不大,压缩省的 token 尚未被缓存折扣反超。
- 这是临界点附近的现象。随轮次增加、缓存命中量增大,缓存的省钱效应会反超压缩(见第三节量化)。
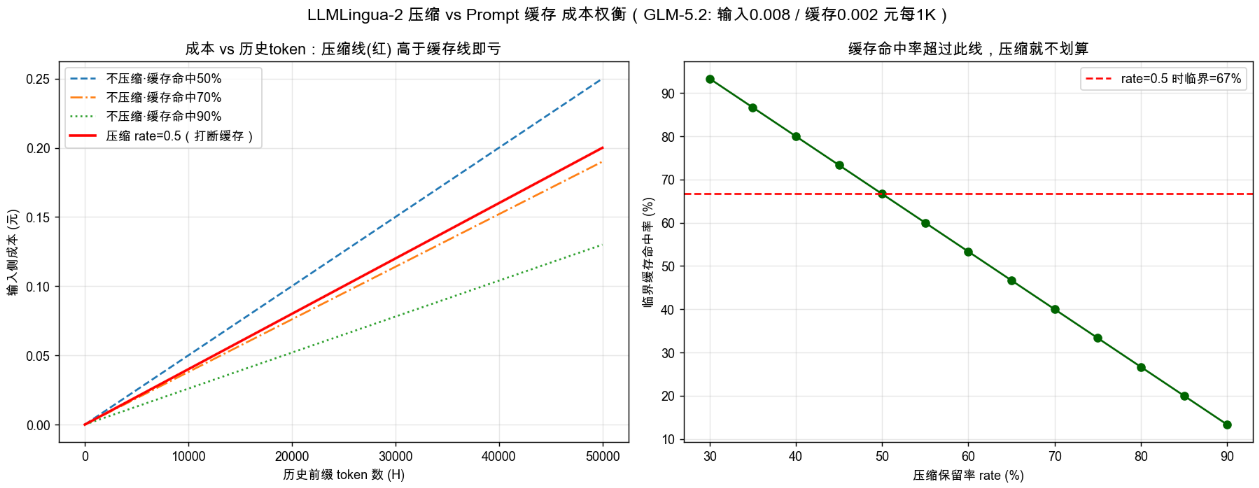
三、压缩 vs 缓存 成本临界点(GLM-5.2 价格量化)
价格:输入 0.008 元/1K,缓存命中 0.002 元/1K,压缩率 rate=0.5。
3.1 成本模型
对历史前缀 H token:
- 不压缩+命中缓存:
H × (命中率×0.002 + (1-命中率)×0.008) / 1000 - 压缩(打断缓存):
H × rate × 0.008 / 1000
3.2 临界点:只看缓存命中率,与 token 规模无关
两种方式成本都随 H 线性增长,交点只由斜率(命中率、rate)决定。解析解:
临界缓存命中率 = 原价×(1-rate) / (原价 - 缓存价)
= 0.008×(1-0.5) / (0.008 - 0.002)
= 66.7%
| 缓存命中率 | 结论 |
|---|---|
| < 66.7% | 压缩更省 |
| > 66.7% | 走缓存更省,压缩反而亏 |
3.3 不同 rate 的临界命中率
| 压缩保留率 rate | 临界缓存命中率 |
|---|---|
| 0.3(压掉70%) | 87.5% |
| 0.5(压掉50%) | 66.7% |
| 0.8(压掉20%) | 26.7% |
rate 越保守,越容易亏。
3.4 与实验数据对照
- GLM 三轮实验:第3轮命中率 ≈ 1408/2890 ≈ 49% < 66.7% → 压缩略赢 ✓
- Claude Code 场景:命中率 93%~96% ≫ 66.7% → 压缩明确亏 ✓
配套脚本 cache_vs_compress.py,曲线图 cache_vs_compress.png。
四、压缩质量人工评估
| 场景类型 | 压缩质量 | 说明 |
|---|---|---|
| 单轮日常问答 | 良好 | 冗余词删除,核心语义保留,答案无明显下降 |
| 长文本摘要/改写 | 良好 | 天然容忍压缩 |
| 多轮强关联对话(指代前文、依赖数值) | 有风险 | 历史被压后指代对象/精确数值可能丢失 |
| 精确信息(代码、数字、专有名词) | 需谨慎 | 删词破坏精确性,skipStructured 已对代码/JSON 生效 |
整体:满足日常普通提问;对需要精确上下文关联的对话,存在部分信息丢失。
五、结论与落地策略
5.1 核心结论
- 压缩收益场景单一:仅在「首轮 + 无缓存 + 长文本」有正收益。
- 压缩与缓存冲突:改写历史会打断上游前缀缓存,命中率越高损失越大;GLM-5.2 下缓存命中率超过 66.7% 压缩即亏。
- 压缩管不到大头:Claude Code 的 system/tools 不在 messages,且已走缓存最低价;输出 token 压缩也无关。
5.2 推荐策略:仅首轮压缩
- 首轮:命中率≈0(无历史缓存)→ 远低于临界 → 压缩长文本稳赢。
- 非首轮:命中率快速冲过临界(Claude Code 直接 90%+)→ 压缩必亏 → 跳过。
首轮判定:messages 中不含任何 assistant 消息即为首轮(多轮会带上一轮 assistant 回复;首轮模型尚未回复)。
5.3 配置建议
| 配置项 | 建议值 | 说明 |
|---|---|---|
firstTurnOnly |
true | 非首轮跳过压缩,保护缓存前缀 |
minTokens |
2000+ | 首轮短对话也不压,仅长文本触发(当前测试值 20 仅用于调试) |
protectLastUserMessage |
true | 保护用户当前问题不被压缩 |
skipStructured |
true | 代码/JSON 跳过 |
shadowMode |
true | 影子模式只记录不替换,验证无损后再放量 |
5.4 为什么不能用「缓存命中率」做实时门控
缓存命中率(cache_read_input_tokens)只在模型响应中返回,是事后数据;而压缩必须在请求发出之前决策。无法为获取命中率先发一次请求,决策窗口早已错过。因此:
- 66.7% 临界命中率仅用于事后评估/复盘:拿已跑完的日志判断「这批请求该不该压」,验证策略正确性。
- 不能用于实时门控。
实时决策只能依赖「请求前就能确定的信号」,即 messages 结构:
- 首轮(无 assistant 历史):命中率必然≈0 → 低于任何临界 → 压缩安全;
- 非首轮(有历史):命中率大概率高 → 超过临界 → 跳过。
所以「仅首轮压缩」本质是:用请求前可确定的「首轮」信号,作为请求后才知道的「缓存命中率高」风险的先验代理。这是唯一工程可落地的方案。
六、附:临界点曲线图

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)