
Claude Sonnet 5 深度解读:Agent 能力下沉 Sonnet 级,逼近 Opus 究竟意味着什么?
2026 年 6 月 30 日,Anthropic 正式发布 Claude Sonnet 5。这不仅是 Sonnet 系列的例行升级,更标志着「Agent 能力平民化」时代的真正开启。本文将深度剖析 Sonnet 5 的技术突破、定价策略、社区争议及其对 AI 开发者生态的深远影响。
一、发布全景:一条蓄谋已久的「降维打击」之路
2026 年 6 月 30 日,Anthropic 正式发布 Claude Sonnet 5。当天起,它成为 Free 和 Pro 计划用户的默认模型,同时面向 Max、Team 和 Enterprise 用户开放。在 Claude Code 终端和 Native API 平台上,开发者可以通过 claude-sonnet-5 模型标识符直接调用。
表面看,这是一次常规的模型代际更新——Sonnet 4.6 的继任者,参数更大、性能更强。但如果把时间线拉长,Sonnet 5 的发布节点极其微妙:
- 6 月 9 日,Anthropic 下架了全球争议巨大但推理能力顶级的 Fable 5;
- 6 月 10 日,旗舰 Mythos 5 转为仅限企业(Glasswing)渠道;
- 同月,OpenAI 的 GPT-5.6 Sol/Terra/Luna 三兄弟进入内测阶段,150 万 token 上下文窗口呼之欲出;
- 7 月中旬,DeepSeek V4 正式版即将发布,推理效率碾压同行;
- 与此同时,Anthropic 正以 9650 亿美元估值推进 IPO 流程,65 亿美元的 H 轮融资箭在弦上。
在这个时间窗口,Anthropic 需要一个「性价比旗舰」来守住开发者市场的大盘——既不能像 Fable 5 那样因为安全争议被自废武功,又不能像 Opus 4.8 那样因为定价过高劝退中小企业。Sonnet 5 的定位由此变得无比清晰:用 Sonnet 级的价格,输出 Opus 级的 Agent 能力。
Anthropic 官方的表述毫不含糊:「Claude Sonnet 5 是迄今最具 Agent 特性的 Sonnet 模型。它能制定计划、使用浏览器和终端等工具自主运行,达到的水准在几个月前还需要更大、更昂贵的模型才能实现。」
二、技术参数与基准测试:数字不会说谎,但也不会说全
2.1 能力矩阵
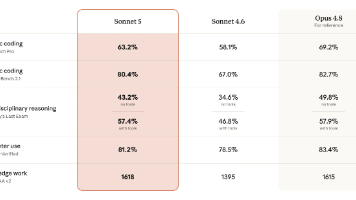
Anthropic 在系统卡和官方博客中公布了一组基准测试数据,我们可以将其整理为如下矩阵:
| 基准测试 | Sonnet 5 | Sonnet 4.6 | Opus 4.8 | 提升幅度(vs 4.6) |
|---|---|---|---|---|
| SWE-bench Pro(Agent 编码) | 63.2% | 58.1% | 69.2% | +5.1pp |
| Terminal-Bench 2.1(Agent 编码) | 80.4% | 67.0% | 82.7% | +13.4pp |
| Humanity's Last Exam(无工具) | 43.2% | 34.6% | 49.8% | +8.6pp |
| Humanity's Last Exam(带工具) | 57.4% | 46.8% | 57.9% | +10.6pp |
| OSWorld-Verified(计算机使用) | 81.2% | 78.5% | 83.4% | +2.7pp |
| GDPval-AA v2(知识工作) | 1618 | 1395 | 1615 | +223 分 |
几个关键发现:
第一,知识工作维度首次超越 Opus 4.8。GDPval-AA v2 的 1618 分比 Opus 4.8 的 1615 分还高出 3 分,这是 Sonnet 系列历史上第一次在知识工作类基准上跨过 Opus 线。对于将 Claude 用于文档分析、报告撰写、法律审查等场景的企业用户来说,这是一个信号:不必再为纯粹的知识工作场景支付 Opus 的溢价。
第二,Agent 编码进步显著但仍有差距。SWE-bench Pro 从 58.1% 提升到 63.2%,Terminal-Bench 2.1 更是跃升 13.4 个百分点。但如果你的核心瓶颈需要 70% 以上的 SWE-bench 得分,Opus 4.8 依然是首选。
第三,Humanity's Last Exam 带工具模式下仅差 Opus 4.8 半个百分点(57.4% vs 57.9%)。这意味着在「AI 辅助人类解决最困难问题」的场景中,Sonnet 5 近乎等效于 Opus 4.8。
2.2 成本-性能曲线:Effort 机制的博弈
Anthropic 在 Sonnet 5 的发布中重点展示了一个新概念——成本-性能散点图(Cost-Performance Curve)。通过调整 Effort Level(努力水平),开发者可以在同一个模型上获得不同档次的性能。
在 Agent 搜索评估 BrowseComp 上,Sonnet 5(橙色线)相比 Sonnet 4.6(灰色线)是严格意义上的全面提升,且覆盖了远比 Opus 4.8(黄色线)更宽的成本-性能选择范围:
- 中等努力水平:性价比大幅领先 Opus 4.8;
- 高努力水平:在某些任务上可以匹配 Opus 4.8 的能力水平;
- 极高努力水平:可能在特定维度上超越。
这个设计的精妙之处在于:开发者不再需要在「Sonnet 不够用」和「Opus 太贵」之间二选一。通过 Effort 滑块,你可以在同一个模型上实现从「经济模式」到「极限模式」的全频谱覆盖。
但这里也埋下了一个坑——这一点我们稍后在「账单刺客」环节展开。
2.3 上下文窗口:依然是 200K
Sonnet 5 的上下文窗口保持 200K token,没有跟随 Opus 4.8 的 1M token。Anthropic 对此的解释是定位分层:长上下文 + 深度推理走 Opus 线,高频 Agent 工作流走 Sonnet 线。但考虑到 GPT-5.6 的 150 万窗口和 DeepSeek V4 的 100 万窗口正在到来,200K 是否会成为 Sonnet 系列的硬天花板,值得持续关注。
三、Agent 能力:从「被动辅助」到「主动执行」
3.1 自主工作流的质变
Sonnet 5 最核心的升级,不是任何一项基准测试的分数,而是它作为 Agent 的行为模式发生了质变。官方收录的 13 条早期测试反馈中,最值得提炼的是以下几点:
「完成任务,而不是停在中途。」 Lovable 的测试发现,Sonnet 5 能把「更新 Salesforce 账户层级 + 发送产品发布通知」这类过去会卡在半路的任务,端到端执行完成。这对应的是 Agent 研究的核心问题——持续执行(Sustained Execution)。过往的 Sonnet 模型在复杂多步任务中常常在第三步、第四步就「迷失」,丢失任务目标。Sonnet 5 在这一点上的改进,很可能来自对长链工具调用轨迹训练的强化。
「不求自证的自我检验。」 一位 Rust 工程师描述了 Sonnet 5 最具代表性的行为:收到 bug 调查指令后,它自主编写了复现测试、实现了修复、然后将修复暂存(stash)以确认 bug 回归——全过程无需任何额外提示。这说明 Sonnet 5 内化了「测试驱动修复」的工程师最佳实践,不再是简单地「写出代码,希望它正确」。
「挑战 brownfield 代码。」 Founding Engineer 的反馈一针见血:Sonnet 5 最擅长的是竞态条件、隐藏测试、没人愿意碰的遗留代码。它能追踪到故障的根因而非表面症状,并能交付持久修复。这暗示 Sonnet 5 在因果推理链的长度和对代码库上下文建模的深度上有了实质性提升。
3.2 CursorBench 实锤:真实场景 57%
比 Anthropic 内部基准更有说服力的是第三方独立评测。Cursor 团队发布的 CursorBench v3.1 是一个基于真实多文件重构任务的基准测试。Sonnet 5 的得分为 57%,而 Sonnet 4.6 仅为 49%。
翻译成人话:在实际的多文件编程任务中,Sonnet 5 已经能够独立完成超过一半的复杂重构工作,无需人工干预。
3.3 与 Claude Code 终端的深度集成
Sonnet 5 发布的同一天,Anthropic 同步升级了 Claude Code 终端工具。新的 Claude Code 能与 Sonnet 5 的 Agent 能力深度耦合:模型可以自主进行工作流规划、执行后用内部验证机制检查输出质量,并能编排终端命令和浏览器操作的组合调用。
对开发者而言,这意味着:给 Claude Code 一个「修复 Issue #372」的指令,它可以自己去看代码、定位问题、生成修复、写测试、运行 CI,最后提交一个审阅就绪的 PR。
四、API 定价背后的商业逻辑
4.1 定价明细
| 阶段 | 输入价格 | 输出价格 | 对比参照 |
|---|---|---|---|
| 介绍期(至 2026.8.31) | $2/MTok | $10/MTok | 约 Opus 4.8 的 40% |
| 标准定价(2026.9.1 起) | $3/MTok | $15/MTok | 约 Opus 4.8 的 60% |
| Opus 4.8(参照) | $5/MTok | $25/MTok | 基准 |
表面来看,Sonnet 5 的价格比 Opus 4.8 便宜 40%-60%,是一个极具吸引力的性价比选择。
4.2 隐形成本:Tokenizer 变更
但 Anthropic 官方声明中的一个脚注(Footnote 2)暴露了一个关键细节:
「Sonnet 5 使用了更新的分词器(Tokenizer),同样的输入可能映射到更多的 Token:根据内容类型,大约是 1.0–1.35 倍。」
这意味着什么?假设你用 Sonnet 4.6 时,一条 prompt 消耗 1000 token。同样的 prompt 在 Sonnet 5 下可能消耗 1350 token。虽然单位 token 价格保持不变或略有降低,但实际账单可能不降反升,最高膨胀 35%。
这种「明降暗升」的定价策略引发了开发者的强烈不满。有网友将其总结为:「价格看着没变,账单直接涨飞了。」
4.3 企业级账单的真实冲击
Uber 的案例被多次引用:5000 名工程师开通 Claude Code 试用后,重度用户的月度人均账单飙涨至 500–2000 美元。四个月内烧光全年 AI 编程预算,CTO 被迫紧急叫停并重新评估财务模型。
更扎心的是微软:Windows 与 M365 团队在 2026 年 6 月全员停用 Claude Code,全面迁回 GitHub Copilot——直接原因就是无法承受的 Token 成本。
当 5000 人团队的四个月支出被一个 Agent 编程工具烧穿,这已经不是「优化 prompt」能解决的问题,而是模型定价体系本身需要重新审视。
五、社区反馈全景:吹爆、吐槽、观望三派之争
5.1 吹爆派:Agent 编程的天花板
Reddit 和 Hacker News 上有大量正面反馈来自高强度后端开发者。最有代表性的一条:
「它只用了一会儿,就修复了一个把 Opus 4.8 卡了好几天的严重 Bug。」
这类反馈的共同特征是:评价者不是在做标准化基准测试,而是在处理真实的、混乱的、需要深层工程理解的代码库。在这些场景中,Sonnet 5 展现出了超出基准分数的「工程直觉」。
CursorBench 的 57% 得分也印证了这一点——这个分数意味着在真实项目中,超过一半的复杂多文件重构可以交给 Sonnet 5 独立完成。
5.2 吐槽派:「Max 推理模式」是个账单刺客
Sonnet 5 的 Max 推理模式(最高努力水平)被社区集中吐槽。核心问题是:模型在这种模式下会陷入高成本的「过度思考」——燃烧大量 Token 进行推理链堆叠,但输出质量的提升不成比例。
一位开发者的实测数据非常触目惊心:
- 用 Sonnet 5 Max 模式完成一个长程 Agent 任务:$2.29
- 用 Opus 4.8 完成同一个任务:$1.80
Sonnet 5 反而更贵 15%!
Hacker News 上的技术用户 doctoboggan 在分析了 Anthropic 官方的成本-性能散点图后得出了一个扎心的结论:
「在同等花销下,Opus 4.8 的表现反而更好。如果中等努力水平不够,你应该换模型而不是提高努力水平。」
Anthropic 自己也间接承认了这一点:成本-性能曲线显示,在极高努力水平下,Sonnet 5 的效率急剧下降。Extra High Effort 更多是一种理论上的边界选择,而非实际推荐的工程选项。
5.3 观望派:国产模型的性价比碾压
这一次,最响亮的批评声来自对比评测。一张在中文技术圈疯传的 GitHub 截图——来自 LLM Benchmark Dashboard 的私有题库评测——将争议推向了高潮。
在逻辑、数学和编程推理的硬核测试中:
| 模型 | 得分 | 测试成本(人民币) | 平均耗时 |
|---|---|---|---|
| MiniMax-M3 | 61.95 | ¥11.64 | 887 秒 |
| Qwen3.7-Plus | 与 Sonnet 5 持平 | ¥11.71 | 1156 秒 |
| Sonnet 5 | 与 Qwen 持平 | ¥71.96 | 404 秒 |
三个事实一目了然:
- 极限分数上,Sonnet 5 已无绝对统治力;
- 成本 6 倍于国产模型;
- 耗时虽短,但在需要深度推理的场景中,「快」反而意味着思考不够。
LisanBench 创始人在 X 上的辣评浏览量破 67 万:
「Sonnet 5 应该被扔进垃圾桶,它比 DeepSeek 贵了整整 57 倍。」
更夸张的真实案例:有开发者用 DeepSeek 跑一整天工作流,Token 消耗超 2400 万,账单仅 ¥11.73;而同一天用中转站调 Claude,花了 ¥1700。11 块 vs 1700 块——145 倍的鸿沟已经不是性价比的讨论范畴,而是两个完全不同的定价范式。
六、安全争议:当「太乖」也是一种翻车
6.1 道德审查器的双刃剑
Sonnet 5 内置了一个比前代更严格的「道德审查器」。Anthropic 在发布会上自豪地宣布:
「Sonnet 5 在编写 Firefox 漏洞利用代码的测试中考了零分。」
这让 Hacker News 上的安全工程师集体破防。一位高赞评论写道:
「这就像一家安全公司在骄傲地宣布:看,我们故意让这个模型变笨、变残废了,这样它就肯定不会惹麻烦。」
对于网络安全攻防演练、渗透测试、白帽子工程师来说,过度安全对齐不是保护,而是让工具失去了实用价值。
6.2 安全与实用的平衡术
坦率地说,Anthropic 的处境确实两难。一边是 IPO 前的合规压力,一边是开发者对「能用」的强烈需求。Sonnet 5 选择了「宁可误拦,不可漏放」的保守策略——Cyber Verification Program 的防护级别虽低于 Fable 5,但依然默认开启网络安全防护,且拒绝大量无关的正当请求。
好在 Anthropic 留了一手:通过 Cyber Verification Program 申请通过后,可以解除部分限制。但这对占绝大多数的中小开发者和个人用户来说,准入门槛仍然过高。
七、对开发者生态的深远影响
Sonnet 5 的发布不是一个孤立事件,而是反映着 AI 行业的深层结构性变化。
7.1 Agent 价格的「民主化」
Sonnet 5 将 Agent 能力带入 $2/MTok 的价格区间(介绍期),意味着中小团队第一次可以用 Sonnet 级的预算部署 Opus 级的 Agent。这会加速三个趋势:
- CI/CD 中集成 AI Code Review 的主流化;
- 自动化测试生成的普及;
- 「AI 驱动的遗留代码重构」从概念验证进入生产。
7.2 多模型架构将成为标配
Sonnet 5 的「Max 模式陷阱」和国产模型的价格优势,共同指向了一个结论:单一模型的「全能信仰」已经过时。 未来的最佳实践是:
- 高频轻量任务 → Haiku 4.5 或国产模型;
- 复杂 Agent 工作流 → Sonnet 5 中低努力水平;
- 需要极限推理 → Opus 4.8 或 DeepSeek V4;
- 特定领域(中文、逻辑) → Qwen、MiniMax、GLM。
Smart Routing / Model Router 不再是一个「nice to have」,而是成本控制的刚需。
7.3 Token 预算管理成为工程硬技能
Uber 的 4 个月烧穿全年预算、微软的全员迁回 Copilot,标志着 Token 成本管理从「财务部门关心的事」变成了「每个工程师要关心的事」。Prompt 缓存、输出压缩(caveman 类工具)、Compaction Loop、结构化输出、语义缓存——这些技术的组合运用,直接决定一个 AI 驱动的产品是盈利还是烧钱。
7.4 国产开源模型从追赶者变为竞争者
Qwen3.7-Plus 在逻辑推理上与 Sonnet 5 打平、MiniMax-M3 在极限推理上登顶,这不是偶然。华为昇腾 950 芯片因 DeepSeek V4 需求爆火、LongCat-2.0 的 1.6 万亿参数 MoE 模型全程不用 NVIDIA 芯片——中国 AI 生态正在从「能用」走向「好用」。对于中国开发者来说,「Sonnet 5 还是国产模型」已经不再是一个默认选项,而是一个需要认真核算的真实选择题。
八、结语
Claude Sonnet 5 是一面镜子,照出了 2026 年 AI 行业的核心张力:
它确实更强了——Agent 能力、编码水平、知识工作全方位提升,CursorBench 57% 的真实分数让多文件重构的半自动化成为现实。
但它也更贵了——Tokenizer 变更导致的实际账单膨胀、Max 模式的「过度思考」陷阱,让开发者不得不在性能和成本之间做更精细的权衡。
它不再无敌——Qwen、MiniMax、DeepSeek 在各自优势领域的逼近甚至超越,意味着 Anthropic 的护城河正在收窄。
对于开发者而言,最理性的策略不是「选最好的模型」,而是「为每一个场景选最合适的模型,并管好你的 Token 成本」。Sonnet 5 是一个强大的选项,但不再是唯一的选项。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)