
Codex + Zotero:把文献管理变成可检索、可整理、可复查的工作流
Codex + Zotero:把文献管理变成可检索、可整理、可复查的工作流
先问你一个问题。
你电脑里的 Zotero 文献库,现在有多少篇论文?
500?1000?还是像我一样,已经堆到几千篇,每次打开都不知道从哪看起。
我之前的状态很典型:文献拼命往里塞,分类全靠手动拖;想找某篇论文的关键结论,要在文件夹、标签和 PDF 之间来回翻。写综述时更痛苦,对着几十篇相关文献,一篇篇点开摘要,看完很快又忘。
后来我把 Codex 和 Zotero 接到同一套工作流里。
现在处理文献时,我会先把目标说清楚:要检索什么主题、整理哪些字段、输出什么表格、哪些结论必须回到原文核对。Codex 负责跑检索、生成分类草案、整理摘要和引用线索;我负责检查来源、判断质量和决定是否采用。
这套方法真正改变的,不是让 AI 替我读论文,而是让文献库从“堆文件”变成可提问、可整理、可复查的系统。
先看这张总图:它概括了 Codex + Zotero 的基本协作位置。
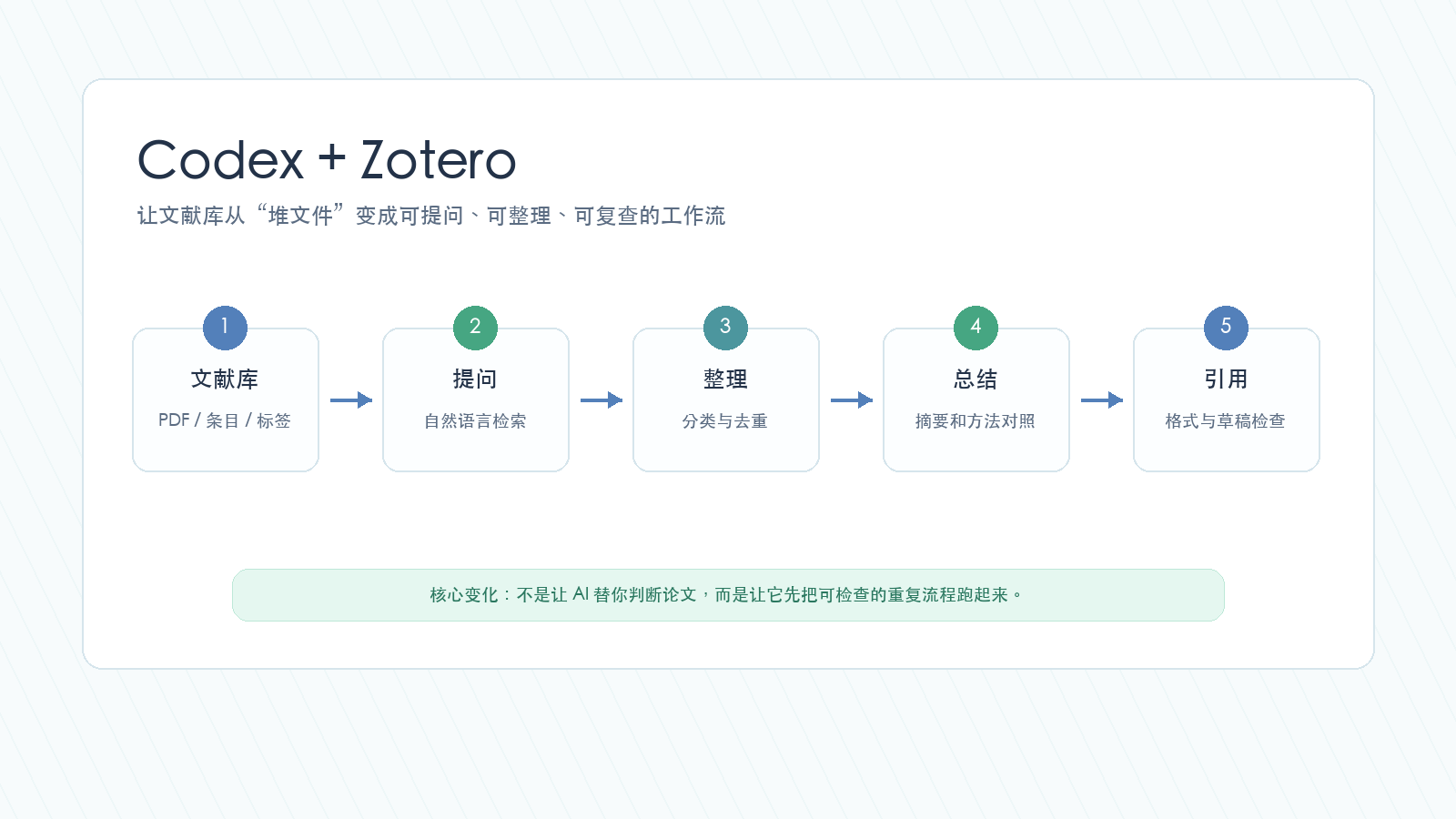
你仍然是最终判断者。AI 只是先把重复检索、分类和格式整理这些工作跑起来。
下面我按真实使用路径,把配置准备、四个核心玩法、进阶知识库和使用边界完整拆开。
先说结论:它适合解决什么问题
Codex + Zotero 最适合处理“结果可以复查”的文献管理任务。
比如:根据主题检索本地文献库、给文献打标签、整理分类草案、批量提取摘要信息、生成阅读清单、检查论文草稿里的引用线索。这些任务的共同点是:输入明确,输出可保存,结果可以回到 Zotero 条目或原始 PDF 核对。
它不适合替你做最终学术判断。
一篇论文是否可靠、方法是否适合你的课题、某个结论能否写进综述,这些仍然需要你自己判断。AI 可以把线索摆出来,但不能替你承担学术责任。
判断是否适合交给 AI 协助,只看一句话:这个任务最后能不能留下可检查的清单、表格、摘要或引用记录。
下面这张卡片可以帮你快速判断哪些事适合先交给 Codex。
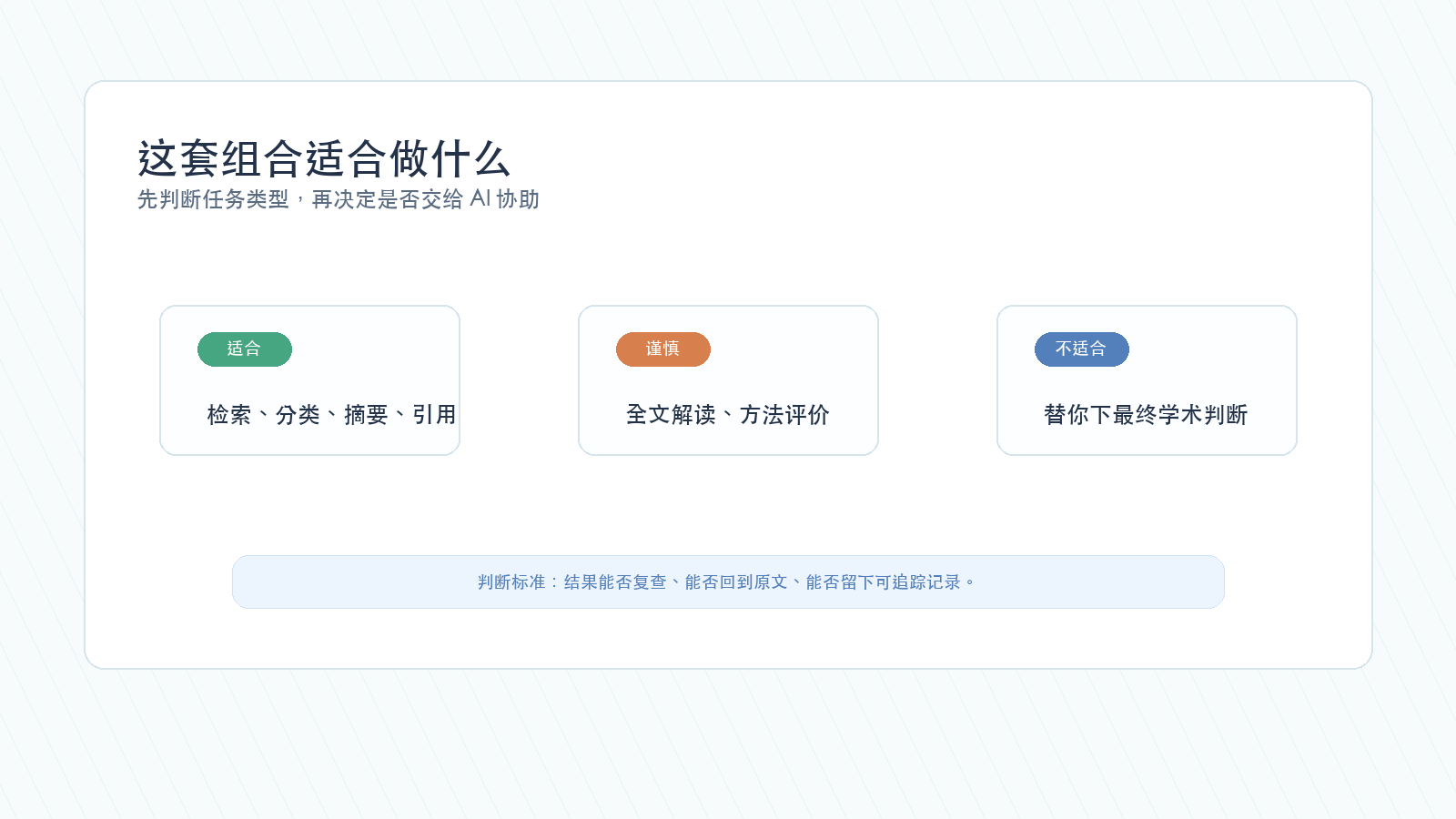
如果任务没有可复查输出,只是让 AI “帮我理解一下这个领域”,那更适合先小范围讨论,再逐步收敛成具体任务。
为什么是 Codex + Zotero
Zotero 负责管理文献本体,Codex 负责把操作流程自动化。
Zotero 的优势很明确:条目、PDF、标签、笔记、引用格式都在一个地方。它适合长期保存和管理文献,但当文献数量变多后,纯手动分类和检索会越来越累。
Codex 的价值在于,它可以根据你的目标调用工具、读取文件、整理结构化结果,并把过程保留下来。你不需要每一步都手动点鼠标,但要把任务边界写清楚。
这两个工具合在一起,最好的用法不是“让 AI 直接总结整个文献库”,而是把任务拆成小块:
- 先找出某个主题下的候选文献;
- 再生成分类或阅读顺序;
- 然后提取摘要、方法、数据类型和局限性;
- 最后把结果整理成表格、笔记或引用清单。
成本也要说清楚。
Zotero 和 Better BibTeX 本身是常见的免费工具;Codex、账号、模型能力、额度和安装方式则应以官方页面和你当前账号显示为准。不要把“当前能用”写成永久承诺,也不要从第三方镜像或不明安装包获取工具。
前置准备:先把边界和权限设好
开始之前,建议先准备四件事。
第一,安装 Zotero 桌面版,并把已有文献导入进去。导入后先整理一下基础字段,比如标题、作者、年份、期刊、DOI 和 PDF 附件。
第二,安装 Better BibTeX。它可以帮助 Zotero 生成稳定引用键,也方便和外部工具做引用导出。具体安装方式以插件官方页面为准。
第三,准备 Codex 环境。安装入口和命令可能会变化,建议按 OpenAI 官方文档或你当前 Codex 客户端的提示来做。不要在文章、截图或仓库里暴露真实 token、cookie 或 API Key。
第四,先设定操作权限。我的习惯是:读条目、生成报告、输出 CSV 可以自动做;批量移动文献、修改标签、删除条目、覆盖笔记之前必须先给预览,让我确认。
下面这张清单,适合在第一次配置时对照检查。

配置不是为了把流程搞复杂,而是为了让 AI 在正确边界里工作。
玩法一:用自然语言检索文献库
自然语言检索是最容易上手的场景。
以前我在 Zotero 里找文献,要么按文件夹翻,要么在搜索框里试关键词。关键词写得太窄会漏结果,写得太宽又会返回一堆不相关条目。
现在我会这样提需求:
帮我在 Zotero 文献库里找近三年关于“深度学习用于医学图像分割”的论文。请输出标题、年份、期刊、DOI、关键词和为什么相关。不要修改 Zotero 条目,只生成一份 Markdown 清单。
这个 Prompt 的重点有三个。
第一,限定范围。比如近三年、某个文件夹、某个标签、某个关键词组合。
第二,说明字段。不要只说“找论文”,而是说清楚要标题、作者、年份、DOI、摘要还是标签。
第三,要求解释相关性。这样你不是拿到一堆标题,而是能快速判断每篇为什么被选中。
下面这张流程图,把一次好的文献检索拆成了五步。

检索结果出来后,我通常会再让它按优先级分组:必读、可选、暂时跳过。这样下一步阅读就不会从一堆无序列表开始。
玩法二:让 AI 辅助分类整理
分类整理是最容易省时间,也最需要谨慎的环节。
我的 Zotero 里曾经有十几个文件夹,每个文件夹下面又套了几层子文件夹。最麻烦的是,一篇论文常常同时属于几个方向,放哪里都不完全对。
我现在不会直接让 Codex “帮我重新整理所有文献”。更稳妥的写法是:
请先分析 Zotero 文献库中“单细胞分析”文件夹下的条目,基于标题、摘要、关键词生成一个分类建议。只输出分类结构、每类代表论文和分类理由,不要移动任何文献。等我确认后,再生成具体操作计划。
这一步先输出草案,而不是直接修改文献库。
确认分类合理后,再让它执行小范围操作,比如给一个文件夹里的文献加标签,或者把一批条目移动到新的集合里。每次动作都要留下清单,方便回退。
下面这张图,是我更推荐的自动分类链路。
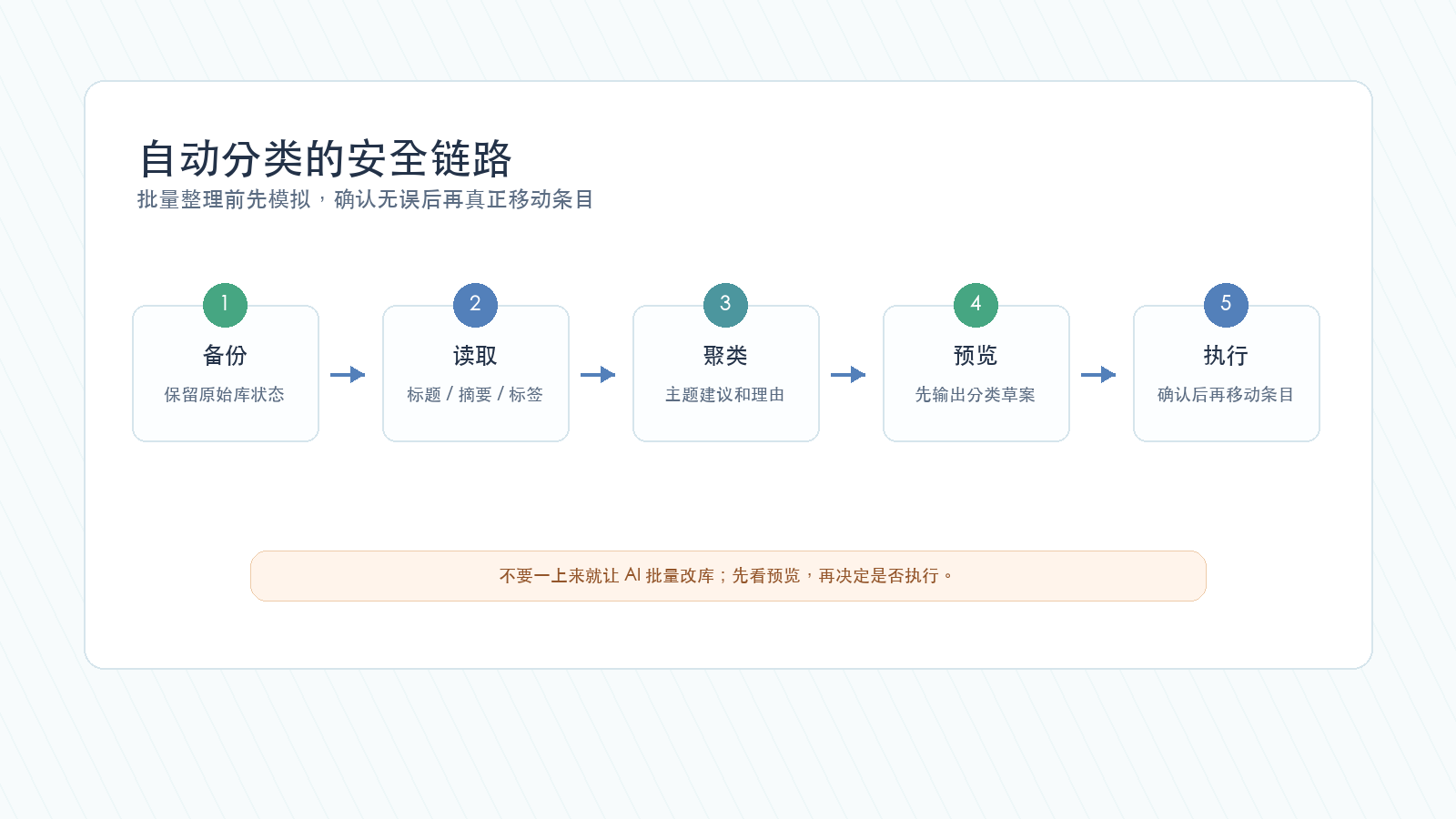
批量整理前,最好先备份 Zotero 数据库,或至少导出当前分类结构。AI 操作再顺,也不值得拿多年积累的文献库冒险。
玩法三:批量总结,但只把它当初稿
批量阅读总结是最有吸引力的功能,但也最容易被误用。
写综述或准备开题时,你需要快速了解某个方向的研究现状。以前我会打开十几篇论文,逐篇看摘要、做笔记、整理方法差异。现在我会先让 Codex 做第一轮结构化整理。
一个比较稳的 Prompt 是:
请总结 Zotero 中“空间转录组分析”文件夹里的文献。每篇论文输出核心方法、数据类型、主要发现、局限性和可复核来源。只使用 Zotero 条目中的公开元数据、摘要和我本地已保存且有权阅读的 PDF。结论不确定时请标注“需人工核对”。
这里有两个边界很重要。
第一,只处理你有权访问的本地 PDF 和公开元数据,不去获取非公开全文,并遵守数据库规则。
第二,要求可复核来源。AI 生成的总结如果不能回到原文定位,就只能当线索,不能直接写进论文。
下面这张表格卡,是我希望批量总结最终长成的样子。

我最常用的做法,是让它先生成一张 CSV 或 Markdown 表格,再从表格里挑出真正值得精读的论文。这样可以把“粗筛”和“精读”分开。
玩法四:生成引用和检查草稿
引用整理是另一个很适合交给工具预处理的任务。
写论文时,最烦的往往不是某一条参考文献,而是几十条引用的格式、顺序和匹配关系。尤其是改投期刊时,格式一换,前面整理好的参考文献又要重来。
Codex + Zotero 可以先帮你做三件事。
第一,从 Zotero 条目生成指定格式的参考文献列表。
第二,读取论文草稿中的引用线索,尝试匹配 Zotero 中的对应条目。
第三,列出不确定匹配、缺失 DOI、年份冲突、作者不一致等需要人工核对的问题。
我会这样写:
请读取我的 Markdown 论文草稿,检查文中的引用线索,并从 Zotero 中匹配对应条目。输出三部分:确定匹配的引用、不确定匹配的引用、缺失或需要补充的信息。不要直接覆盖原文,先生成检查报告。
这个流程的目标不是“一键交稿”,而是先把引用问题暴露出来。
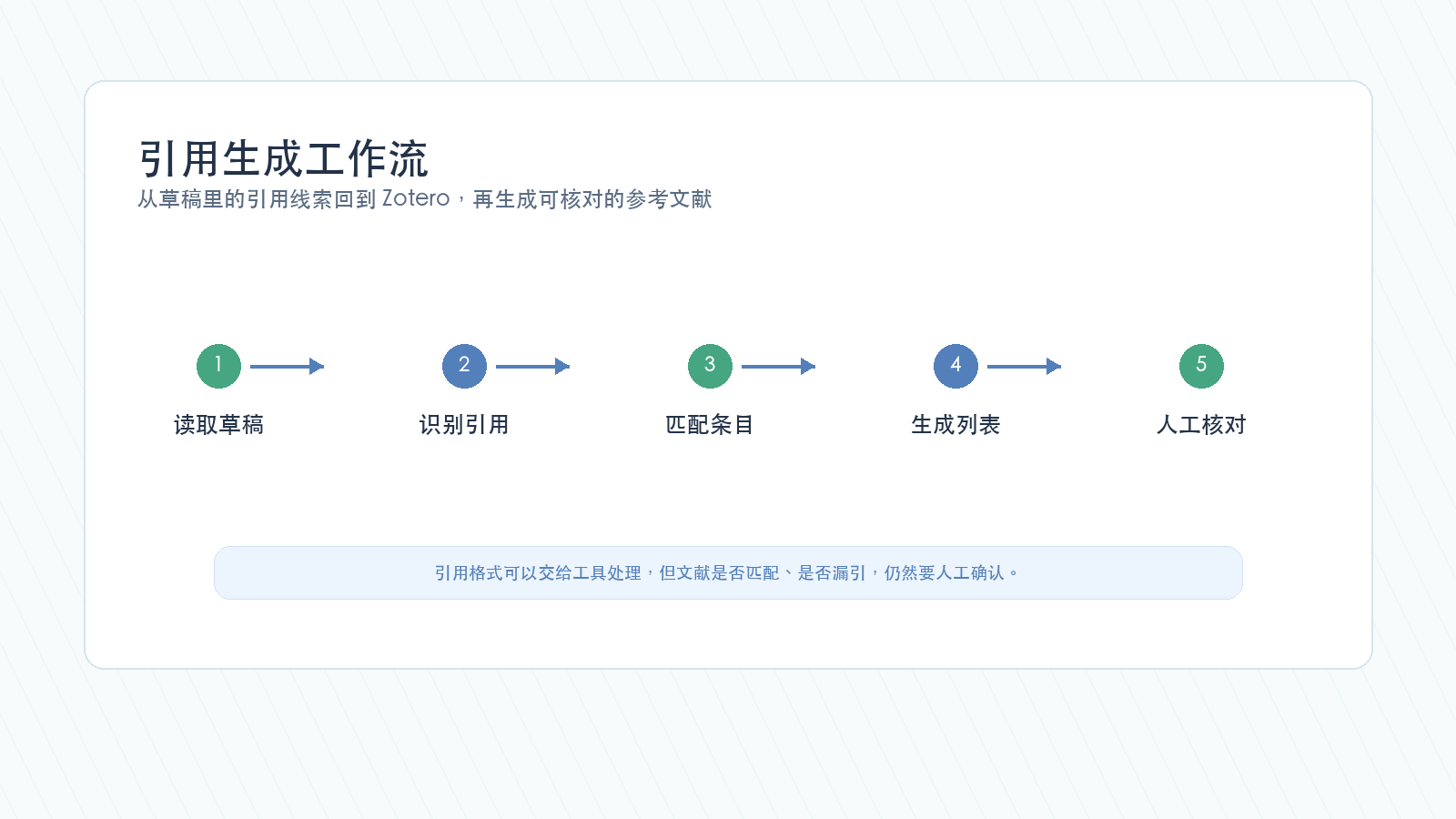
引用格式可以交给工具处理,但文献是否匹配、是否漏引、是否引用了真正支持结论的论文,仍然要人工确认。
进阶:把 Zotero 变成个人知识库
用熟以后,可以把 Zotero 当成你的个人科研知识库入口。
关键不是把所有 PDF 一股脑丢给 AI,而是给 Codex 一份稳定的背景说明。比如你的研究方向、常用术语、常见数据类型、当前项目目标、希望优先关注的方法。
这样它在帮你检索或总结时,就不只是按关键词匹配,而是会更接近你的研究语境。
例如:
我是一名生物信息学研究者,主要关注单细胞组学、空间转录组学和深度学习在基因组学中的应用。总结文献时,请优先关注数据类型、模型方法、评估指标、可复现性和对我当前项目的启发。
之后你可以定期让它整理新增文献。
比如每周手动触发一次:检查 Zotero 中新增条目,按研究方向分组,列出最值得精读的 5 篇,并说明推荐理由。这里仍然建议只生成报告,不自动改库。
下面这张闭环图,展示了我更推荐的知识库用法。
真正长期有价值的,不是一次性总结多少篇论文,而是让新文献、旧笔记和当前项目持续连接起来。
使用边界:哪些事不要交给它拍板
Codex + Zotero 能明显减少重复操作,但不要把它当成学术判断机器。
第一,不要直接相信批量总结里的结论。尤其是方法比较、实验效果、争议观点,必须回到原文核对。
第二,不要让 AI 在没有预览的情况下批量修改文献库。移动集合、删除标签、覆盖笔记、改引用键,都应该先生成操作清单。
第三,不要在公开文章、截图或仓库里暴露 API Key、token、cookie 或个人账号信息。
第四,不要让工具获取你无权访问的全文资源。文献整理可以使用公开元数据和你本地已有、授权可读的文件,同时遵守数据库规则。
第五,不要把“当前可用”写成永久承诺。工具安装方式、账号要求、模型能力和价格策略都会变化,涉及这些内容时都应以官方页面为准。
这些边界看起来保守,但它们能让这套工作流长期可用。
总结:先从一个低风险文件夹开始
Codex + Zotero 的价值,不是让你彻底不管文献,而是先把重复流程跑起来。
你给目标,它检索、整理、生成草案;你做判断、核对来源、决定是否采用。这样一来,文献管理不再只是“把 PDF 放进文件夹”,而是变成一个可以持续复用的工作流。
如果你刚开始尝试,不建议一上来处理整个文献库。
更稳的做法是:挑一个低风险文件夹,里面放 20 到 50 篇论文。先让 Codex 做一次检索清单、分类建议和摘要表格。你检查它的结果、修正 Prompt,再逐步扩大范围。
等你熟悉这套节奏之后,再把引用检查、综述粗筛、项目文献追踪这些任务接进来。
有使用 Codex 和 Zotero 管理文献的经验,欢迎在评论区交流。尤其是分类、批量总结、引用检查这几类场景,很值得互相借鉴。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)