
用 Codex 创建论文全文下载 Skill

本文记录一个可复用的科研自动化实践:把“打开论文页面、选择机构、完成统一身份认证、点击 PDF、保存并校验”封装成 Codex Skill。最终实现了 IEEE Xplore 和 Springer Nature Link 两个可用 Skill,同时也记录了 ScienceDirect 因机器人检测无法可靠自动化的失败案例。
一、为什么要把论文下载做成 Skill
下载一篇有机构订阅权限的论文,人工操作通常并不复杂:
- 打开论文详情页;
- 点击机构登录;
- 搜索并选择所在学校;
- 在学校统一身份认证页面输入账号,必要时完成 MFA;
- 返回出版商网站;
- 点击 PDF 并选择保存位置。
问题在于,这套流程会被反复执行,而且不同出版商的 URL、登录入口、PDF 路由和会话机制都不相同。普通脚本很容易退化成一堆一次性选择器,而 Skill 可以同时封装:
- 触发条件:什么请求应该调用它;
- 固定流程:URL 解析、机构访问、下载与校验;
- 安全边界:不保存密码、不绕过 CAPTCHA、不批量爬取;
- 可执行脚本:把容易出错的步骤固化为确定性代码;
- 故障策略:会话过期、无订阅权限、机器人检测时如何停止。
最终使用体验可以压缩成一句话:
使用 $ieee-download-paper 下载 https://ieeexplore.ieee.org/document/11158579
或者:
使用 $springer-download-paper 下载 https://link.springer.com/article/10.1007/s10515-026-00637-6
二、整体架构
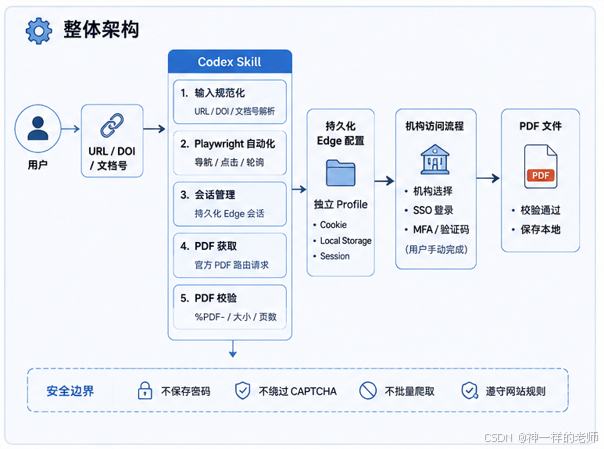
两个 Skill 都采用“Skill 指令 + Playwright 脚本 + 独立浏览器配置”的结构:
$CODEX_HOME/skills/
├── ieee-download-paper/
│ ├── SKILL.md
│ ├── package.json
│ ├── package-lock.json
│ ├── agents/
│ │ └── openai.yaml
│ └── scripts/
│ └── ieee-download.mjs
└── springer-download-paper/
├── SKILL.md
├── package.json
├── package-lock.json
├── agents/
│ └── openai.yaml
└── scripts/
└── springer-download.mjs
运行链路如下:
用户输入 URL / DOI / 文档号
↓
规范化输入
↓
打开独立的持久化 Edge 会话
↓
尝试带 Cookie 获取官方 PDF
↓
已有权限?──是──→ 保存 PDF
│
否
↓
打开机构登录入口并选择学校
↓
用户手动完成账号、MFA、验证码
↓
轮询官方 PDF 路由
↓
校验 %PDF 文件头、大小和页数
这里最重要的设计是:自动化负责导航和重复劳动,敏感认证始终由用户在真实浏览器页面中完成。
三、初始化 Skill
Codex 自带 skill-creator,新建 Skill 时先运行初始化脚本:
python "$CODEX_HOME\skills\.system\skill-creator\scripts\init_skill.py" `
ieee-download-paper `
--path "$CODEX_HOME\skills" `
--resources scripts `
--interface "display_name=IEEE Paper Downloader" `
--interface "short_description=Download IEEE papers through institutional access" `
--interface 'default_prompt=Use $ieee-download-paper to download an IEEE paper.'
Springer Skill 同理,只需要替换名称与界面元数据。
依赖保持最小化,只安装 playwright-core,直接控制本机 Microsoft Edge,不额外下载 Chromium:
{
"name": "paper-download-skill",
"private": true,
"type": "module",
"dependencies": {
"playwright-core": "1.61.1"
}
}
安装依赖:
npm install --omit=dev --prefix "$SKILL_DIR"
四、SKILL.md 如何设计
Skill 能否被正确触发,首先取决于 YAML frontmatter 中的 description。以 IEEE 版本为例:
---
name: ieee-download-paper
description: Download IEEE Xplore article PDFs by using the user's legitimate institutional subscription in a persistent Microsoft Edge session. Use when the user provides an IEEE document URL, document number, or DOI and asks to save the full-text PDF.
---
正文不需要解释通用的编程知识,而应该明确另一个 Agent 执行任务时必须遵循的操作约束:
- 允许哪些输入格式;
- 应执行哪个脚本;
- PDF 保存到哪里;
- 登录时如何与用户协作;
- 什么条件表示下载成功;
- 什么情况下必须停止。
安全规则必须写进 Skill,而不是仅靠使用者记忆:
- 只使用用户本来就拥有的机构访问权限。
- 不保存、记录或通过命令行传递账号密码。
- 用户必须在可见浏览器页面中完成 MFA 和 CAPTCHA。
- 不绕过付费墙、机器人检测和访问频率限制。
- 持久化浏览器目录包含会话 Cookie,不得上传或提交到 Git。
五、持久化浏览器会话
如果每次启动都是全新浏览器,用户就必须反复选择机构并登录。Playwright 的 launchPersistentContext 可以把 Cookie 和本地存储保存在独立目录中:
const context = await chromium.launchPersistentContext(profileDir, {
channel: 'msedge',
headless: false,
acceptDownloads: true,
viewport: null,
locale: 'en-US',
});
这里有两个关键点:
headless: false:机构登录、MFA 和验证码必须在可见浏览器中完成;- 使用专用
profileDir:绝不能让自动化脚本操作用户日常使用的 Edge 主配置。
例如:
const profileDir = path.join(
process.env.LOCALAPPDATA,
'Codex',
'ieee-download-paper',
'edge-profile'
);
这个目录等价于登录凭证容器,应当视为敏感数据。
六、输入规范化
为了让 Skill 易用,IEEE 版本同时接受文档号、URL 和 DOI:
function normalizeInput(input) {
const value = input.trim();
if (/^\d{6,12}$/.test(value)) {
return `https://ieeexplore.ieee.org/document/${value}`;
}
if (/^10\.\d{4,9}\//i.test(value)) {
return `https://doi.org/${value}`;
}
return new URL(value).toString();
}
Springer 版本则把 DOI 规范化为文章页:
if (/^10\.1007\//i.test(value)) {
return `https://link.springer.com/article/${value}`;
}
同时要限制允许访问的域名,避免自动化浏览器被输入引导到任意网站。
七、IEEE Xplore 的实现要点
IEEE 论文通常可以由 arnumber 唯一标识。脚本先从文章 URL、查询参数、canonical 链接或页面正文中提取文档号,然后通过浏览器上下文请求官方 PDF 路由。
核心校验不是 HTTP 200,而是返回内容必须真的是 PDF:
const body = await response.body();
if (
body.length >= 1024 &&
body.subarray(0, 5).toString('ascii') === '%PDF-'
) {
return body;
}
原因很简单:很多网站在未登录时仍返回 200,但正文实际上是登录页、错误页或机器人验证页。如果只看状态码,就会把 HTML 错误页面保存成 .pdf。
当没有访问权限时,脚本尝试点击机构登录入口,搜索学校,然后等待用户在 SSO 页面完成认证。脚本每隔数秒重新请求 PDF;Cookie 一旦生效,下载自动继续。
实测论文:
IEEE 文档号:11158579
输出大小:514,818 字节
文件头:%PDF-
八、复杂应用案例:从 IEEE 检索到 HTML 论文目录
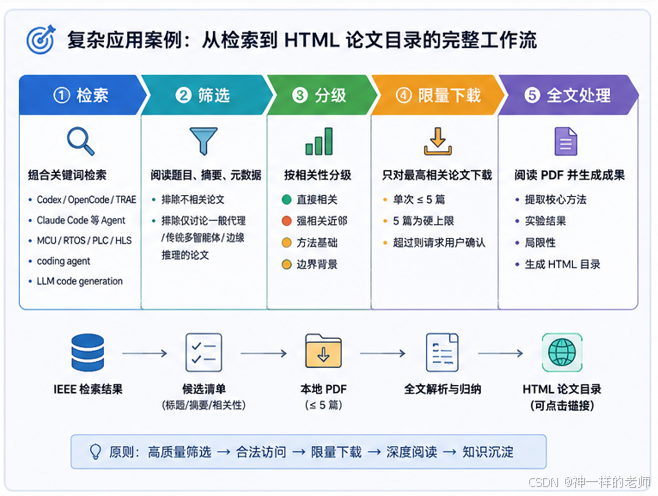
单篇下载只能证明脚本可用,更能体现 Skill 价值的场景,是把它放进一条完整的科研资料工作流中。
实际使用过的复杂任务是:
在 IEEE 网站上查找在嵌入式系统中使用 Codex、OpenCode、TRAE、
Claude Code 或同类编码 Agent 的论文;如果存在相关论文,
使用 $ieee-download-paper 下载全文;阅读全文后生成 HTML 论文目录,
附上每篇论文的核心内容、IEEE 链接和本地 PDF 链接。
这个任务不再是简单的“给定链接 → 下载文件”,而是包含五个阶段:
- 检索:组合产品名、
coding agent、LLM code generation、firmware、microcontroller、PLC、RTL、HLS等关键词检索 IEEE; - 筛选:先读取题目、摘要和元数据,排除只讨论传统多智能体、边缘推理或一般代码生成的论文;
- 分级:区分直接相关、强相关近邻、方法基础和边界背景;
- 限量下载:只对最高相关的少量论文调用
$ieee-download-paper; - 全文处理:验证 PDF,提取全文,归纳核心方法、实验结果与局限,最终生成可点击的 HTML 目录。
实际结果中,严格匹配 Codex CLI、OpenCode、TRAE 或 Claude Code 在 MCU/RTOS 固件项目中应用的论文为 0 篇,但找到了 PLC 控制代码生成、RTL、HLS 和 Codex 多语言评测等相关工作。最终下载并核验 5 篇 PDF,生成了包含相关性分级、中文摘要、IEEE/DOI 链接和本地全文链接的 HTML 目录。
为什么必须限制全文下载数量
检索结果可能有几十甚至上百篇,但不能把“找到多少”直接变成“下载多少”。出版商通常会监控短时间内的下载频率和数量,连续获取大量全文可能触发限流、会话失效或账号/机构访问风控。
本工作流采用明确的保守上限:
单次全文下载最好不超过 5 篇,并将 5 篇作为硬上限。 如果候选超过 5 篇,先输出题目、摘要、相关性和链接,让用户再次筛选;不要自动继续下载下一批,也不要通过并发、切换会话或缩短间隔规避网站限制。
相应的执行规则可以直接写进检索提示词:
先检索并按相关性排序。最多选择 5 篇下载全文;如果高相关候选超过 5 篇,
仅生成候选清单并请求用户确认,不要继续批量下载。
这条限制有三个作用:
- 降低触发 IEEE 下载限制的概率;
- 迫使检索阶段先做高质量筛选,避免无目的囤积 PDF;
- 让用户对全文获取范围保持明确控制。
因此,在复杂应用中,Skill 的价值不是“下载越多越好”,而是把检索、判断、授权访问、全文理解和成果整理连接成一个可审计的闭环。
九、Springer Nature Link 的实现要点
Springer 的文章 URL 本身包含 DOI。官方 PDF 路由可以由 DOI 构造:
function pdfUrlFor(doi) {
const encoded = doi.split('/').map(encodeURIComponent).join('/');
return `https://link.springer.com/content/pdf/${encoded}.pdf`;
}
未获得订阅权限时,目标示例返回 204,而文章页会显示 Log in via an institution。脚本点击该入口后进入 Springer WAYF 页面:
https://wayf.springernature.com/?redirect_uri=...
机构搜索输入框名称为 search,可填写学校名称并回车:
const input = wayf.locator('input[name="search"]').first();
await input.fill(institution);
await input.press('Enter');
用户完成统一身份认证后,脚本通过同一持久化浏览器上下文重新请求 PDF。
实测论文:
DOI:10.1007/s10515-026-00637-6
标题:SENTRY: an adversarial robust anomaly detection approach...
输出大小:3,855,558 字节
页数:40
文件头:%PDF-
十、文件名与重复下载处理
标题优先从标准元数据读取:
const title = await page
.locator('meta[name="citation_title"]')
.first()
.getAttribute('content');
Windows 文件名中的非法字符必须替换:
function safeFilename(value) {
return value
.replace(/[<>:"/\\|?*\u0000-\u001f]/g, '_')
.replace(/\s+/g, ' ')
.trim()
.slice(0, 180);
}
写文件时使用 wx,避免静默覆盖已有论文。如果文件已存在,就追加时间戳生成新文件。
十一、失败案例:为什么 Elsevier Skill 被删除
ScienceDirect 版本最初也采用相同架构,但页面持续进入机器人检查循环:用户勾选“不是机器人”后,网站再次发起检查,无法进入机构登录流程。诊断页面返回了类似以下信息:
There was a problem providing the content you requested
CPE00001
这不是换一个 CSS 选择器就能解决的问题,而是网站综合自动化特征、网络出口、浏览器环境和行为风险进行判断。继续自动点击检查框属于规避机器人检测,也无法保证稳定性。
最终处理方式是:
- 明确停止自动化;
- 不尝试绕过 CAPTCHA;
- 删除不可靠的 Elsevier Skill;
- 建议使用普通浏览器、校园网或学校 VPN 手动下载。
这个失败很重要。一个可靠的 Agent 工具不仅要知道如何完成任务,也必须知道何时应该停止。
十二、验证流程
Skill 创建完成后至少执行四层验证。
1. Skill 结构校验
python "$CODEX_HOME\skills\.system\skill-creator\scripts\quick_validate.py" `
"$CODEX_HOME\skills\springer-download-paper"
2. JavaScript 语法校验
node --check "$SKILL_DIR\scripts\springer-download.mjs"
3. 依赖审计
npm audit --omit=dev --prefix "$SKILL_DIR"
4. 真实文章测试
只有脚本实际经历“打开文章—机构登录—获取 PDF—校验文件”的完整链路,才能认为 Skill 可用。测试时还要记录:
- 输出文件是否存在;
- 大小是否合理;
- 前 5 字节是否为
%PDF-; - PDF 解析器能否读取页数;
- 浏览器是否正确关闭并释放持久化配置。
十三、可进一步改进的方向
当前版本已经可以完成单篇和小批量下载,但还可以继续增强:
- 将出版商差异抽象为统一适配器接口;
- 在下载前自动识别开放获取状态;
- 把 DOI、题目、作者和本地路径写入统一文献清单;
- 与 Zotero 或本地知识库联动;
- 下载后自动提取摘要、关键词并生成 HTML 目录;
- 为机构登录状态增加更清晰的过期检测;
- 加入保守的速率限制和可审计日志。
十四、总结
论文下载 Skill 的核心并不是“模拟点击 PDF”,而是把授权访问流程变成一个有边界、可复用、可验证的工程组件:
- 用 Skill 描述触发条件和安全规则;
- 用 Playwright 处理浏览器会话与机构跳转;
- 让用户亲自处理账号、MFA 和 CAPTCHA;
- 用官方 PDF 路由获取文件;
- 用
%PDF文件头、大小和页数验证结果; - 遇到机器人检测时停止,而不是绕过。
IEEE 的“检索—筛选—限量下载—全文理解—HTML 目录”案例,以及 Springer 的单篇机构访问案例,证明这种模式可以显著减少重复操作;Elsevier 的失败案例则说明,科研自动化必须服从网站规则和技术边界。真正可靠的 Agent,不是“任何网站都能下载”,也不是“一次下载越多越好”,而是每一步都可解释、可验证,并且知道什么时候应该把控制权交还给用户。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)