
以 Harness 工程的视角,拆解 Claude Code 的特性
以 Harness 工程的视角,拆解 Claude Code 的特性
如果只把 Claude Code 理解成“一个很强的写代码模型”,其实会错过它最有意思的部分。
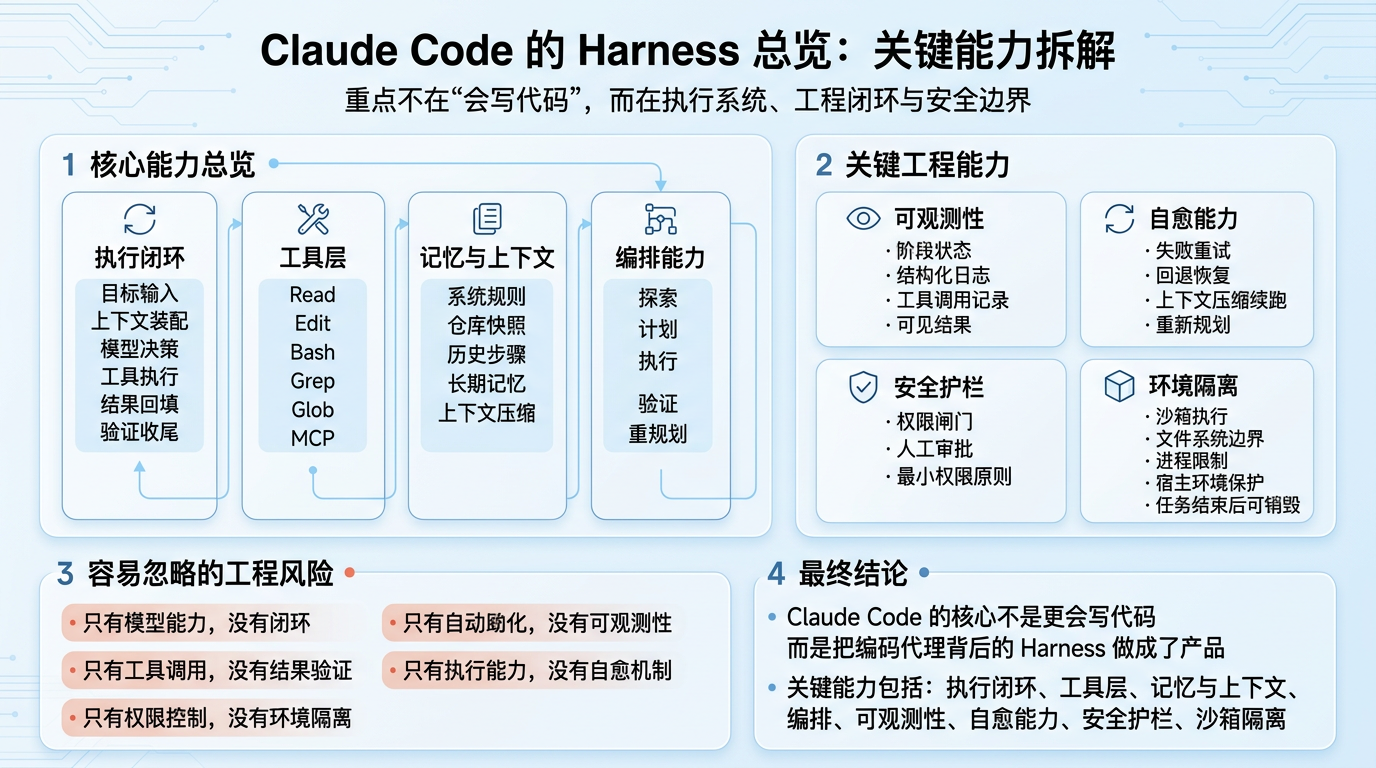
它真正特别的地方,不是会不会补全代码,也不是能不能读文件、改文件、跑命令,而是它把一套面向编码任务的执行系统做成了产品能力。它会理解目标、装配上下文、选择动作、调用工具、处理失败、暴露进度、校验结果,还会在高风险动作前停下来,把边界重新交还给人。
从这个角度看,Claude Code 更像一套已经成型的 Harness,而不是一个更聪明的编辑器插件。
一、执行闭环:Claude Code 是怎么把任务一步步跑完的
一个真正可用的编码代理,核心不是“回答像不像人”,而是能不能把任务推进到闭环。
对 Claude Code 来说,这个闭环通常包含六个动作:
- 接收用户目标
- 组装当前上下文
- 让模型判断下一步
- 调用工具接触真实环境
- 把执行结果回填进上下文
- 判断是继续推进,还是结束交付
这和传统聊天模型最大的区别在于,它不是一问一答,而是一轮一轮地向完成状态逼近。
把这个过程压缩成伪代码,大致会像这样:
class AgentLoop:
def __init__(self, model, tools, context_builder):
self.model = model
self.tools = tools
self.context_builder = context_builder
async def run(self, task: str):
state = {"task": task, "steps": [], "done": False}
while not state["done"]:
messages = self.context_builder.build(state)
decision = await self.model.next_action(messages)
if decision["type"] == "final":
state["done"] = True
return decision["content"]
if decision["type"] == "tool_call":
result = await self.tools.execute(
decision["tool"],
decision["input"],
)
state["steps"].append({
"action": decision,
"observation": result,
})
看起来最简单的这段循环,恰恰是整个系统的骨架。后面所有高级能力,都是围绕它长出来的。
二、工具层:Claude Code 为什么不是“调几个命令”那么简单
很多人第一次看 Claude Code,会把它的工具能力概括成一句话:能读文件、能改文件、能跑 Bash。
但从 Harness 工程的角度看,重点根本不在工具列表,而在工具协议。
一个真正可用的工具层,至少要回答四个问题:
- 工具怎么注册
- 参数怎么约束
- 权限怎么检查
- 结果怎么标准化
也就是说,模型只是提出“想做什么”,真正把这件事变成可执行、可控制、可回填动作的,是底层 Harness。
一个简化版工具注册表可以写成这样:
from dataclasses import dataclass
@dataclass
class ToolSpec:
name: str
schema: dict
permission: str
handler: callable
class ToolRegistry:
def __init__(self):
self._tools = {}
def register(self, tool: ToolSpec):
self._tools[tool.name] = tool
async def execute(self, name: str, params: dict, permission_manager=None):
tool = self._tools[name]
validate_json_schema(tool.schema, params)
if permission_manager:
await permission_manager.check(tool.permission, params)
output = await tool.handler(params)
return {
"tool": name,
"ok": True,
"output": output,
}
从这个角度再看 Read、Edit、Bash、Glob、Grep、MCP,它们就不只是一些功能点,而是不同风险等级、不同调用语义、不同结果回填方式的执行接口。
三、记忆与上下文:Claude Code 为什么能在长任务里保持稳定
编码任务天然是长链路任务。
在一次真实开发里,代理不仅要知道“用户想做什么”,还要持续记住:
- 已经读过哪些文件
- 刚刚做了哪些改动
- 哪些命令已经执行过
- 哪些校验通过了,哪些还没过
- 项目里有哪些隐性约束
- 当前任务还剩哪些收尾动作
如果没有稳定的记忆与上下文系统,再强的模型也会在长任务里逐渐漂移。
所以,Claude Code 的稳定性很大程度上不来自“模型记性好”,而来自持续装配上下文。最终送进模型的,不是一段孤立对话,而是一组被组织过的任务信息:
- 系统规则
- 用户目标
- 仓库快照
- 历史步骤
- 工具输出
- 项目约束
- 长期记忆
一个最小可用的上下文构建器,大致如下:
class ContextBuilder:
def __init__(self, memory_store, repo_index):
self.memory_store = memory_store
self.repo_index = repo_index
def build(self, state):
return [
{"role": "system", "content": load_system_rules()},
{"role": "user", "content": state["task"]},
{"role": "system", "content": self.repo_index.snapshot()},
{"role": "system", "content": self.memory_store.recall(state["task"])} ,
{"role": "system", "content": summarize_steps(state["steps"])} ,
{"role": "system", "content": current_permission_mode()},
]
真正的记忆系统至少要分层:
- 短期记忆:最近几步执行状态
- 工作记忆:当前任务中间结论
- 长期记忆:项目约定、常见修复模式、结构性知识
当任务过长、上下文逼近上限时,系统还需要进一步做两件事:
- 压缩旧上下文,只保留关键决策和结果
- 把高价值信息沉淀成长期记忆,而不是让它跟着会话一起丢失
这也是为什么好的编码代理不会简单“失忆”。它不是死记硬背,而是在不断重建最有效的任务上下文。
四、编排:Claude Code 为什么能先探索、再计划、再执行
一旦任务不再是单步回答,编排就变成必须存在的层。
Claude Code 之所以看起来像“会做事”,一个重要原因是它不会直接把第一反应当成最终动作,而是更接近下面这种过程:
- 先探索环境
- 再形成计划
- 然后进入执行
- 执行后做验证
- 验证不过就重规划
这本质上已经是一个轻量工作流引擎,而不是简单的聊天回合。
编排层的价值在于,它让任务执行不再是“想到哪做到哪”,而是具备阶段感、节奏感和回退能力。对于复杂改动来说,这比单次生成质量更重要。
五、可观测性:Claude Code 为什么不像一个黑箱
很多 AI 工具的问题,不是结果差,而是过程不可见。
你不知道它读了什么,不知道它改了什么,不知道它为什么这么改,也不知道它失败在了哪里。只要结果一偏,排查就会变得非常痛苦。
Claude Code 更接近工程系统的地方,是它会主动把过程暴露出来。
可观测性至少体现在四个层面:
- 状态可见性:现在在做什么,下一步准备做什么
- 动作可见性:读了哪些文件,跑了哪些命令,调了哪些工具
- 结果可见性:哪些验证通过了,哪些还没验证
- 协作可见性:为什么要这样改,哪里需要人工决策
这意味着用户面对的不是一个只会吐结果的黑箱,而是一个持续报告状态的执行系统。
一个简化版的事件模型如下:
from dataclasses import dataclass
from datetime import datetime
@dataclass
class ExecutionEvent:
timestamp: datetime
source: str
level: str
message: str
context: dict
def emit(event_handler, source, level, message, **context):
event_handler(
ExecutionEvent(
timestamp=datetime.now(),
source=source,
level=level,
message=message,
context=context,
)
)
当系统具备结构化事件流之后,很多“产品体验”其实是顺势长出来的:步骤汇报、阶段总结、失败定位、审计回放、验证门禁,都依赖这层能力。
所以,可观测性不是附属体验,而是让代理真正可协作、可维护、可排障的基础设施。
六、自愈能力:Claude Code 为什么不会一出错就卡死
AI 代理真正难的,不是做对一次,而是做错之后还能继续跑。
在工程环境里,错误几乎是常态:
- 命令可能失败
- 工具可能超时
- 输出可能格式不合法
- 上下文可能过长
- 原计划可能在执行中失效
- 编辑后的代码可能根本跑不通
如果系统一出错就停摆,那它最多只是 demo。真正能进入真实工作流的系统,必须具备自愈能力。
Claude Code 式的自愈,通常体现在这些位置:
- 工具失败后的重试
- 流式响应异常后的回退
- 上下文过长时的压缩与续跑
- 原计划走不通时的重新规划
- 编辑后通过测试、Hook、review 做纠偏
一个极简的恢复逻辑可以写成这样:
async def execute_with_recovery(step, tool_runner, planner, max_retries=2):
for attempt in range(max_retries + 1):
result = await tool_runner(step)
if result["ok"]:
return result
new_step = await planner.replan(
failed_step=step,
failure_reason=result["error"],
)
return {"ok": False, "replanned_step": new_step}
自愈能力最关键的地方,不是“永远不失败”,而是“失败以后不失控”。它让代理从一次性工具,变成一个能在真实环境里持续工作的系统。
七、安全护栏:Claude Code 为什么能执行,但不是无限制执行
只要代理从“回答问题”进入“执行动作”,安全就会立刻成为主干问题。
因为文件修改、命令执行、外部访问,都是天然的高风险动作。真正的问题不是“模型会不会犯错”,而是系统是不是从一开始就默认它可能犯错。
所以,一个成熟的 Harness 一定会有安全护栏。
它通常包含这些层次:
- 最小权限原则
- 高风险动作审批
- 文件与命令分级控制
- 沙箱与隔离执行
- 外部能力访问边界
光有权限控制还不够,真正进入工程现场之后,还必须解决另一个问题:即便某个动作被允许执行,它也不应该天然拥有整个宿主环境的全部能力。
这就是环境隔离的重要性。对于 Claude Code 这类会修改文件、执行命令、调用外部能力的代理来说,沙箱不是附加优化,而是执行体系的一部分。它的作用不是让代理什么都做不了,而是把它能做的事情限制在一个可预期、可回收、可审计的边界内。
一个合格的沙箱环境,至少要做到几件事:
- 限制文件系统访问范围,只开放任务必需目录
- 限制进程能力,避免任意启动高风险命令
- 限制网络或外部资源访问,减少越界调用
- 把代理执行和宿主系统隔离开,避免一次错误扩散成全局问题
- 在任务结束后可以清理、回放或直接销毁执行环境
从 Harness 视角看,权限闸门解决的是“该不该做”,沙箱解决的是“即便做了,最多能影响到哪里”。这两层能力叠加起来,代理才有可能既高效推进任务,又不把宿主环境暴露在无边界风险里。
一个简化版权限检查可以写成这样:
class PermissionManager:
def __init__(self, policy):
self.policy = policy
async def check(self, action: str, resource: dict):
level = self.policy.resolve(action, resource)
if level == "forbidden":
raise PermissionError(f"{action} is forbidden")
if level == "ask":
approved = await request_human_approval(action, resource)
if not approved:
raise PermissionError(f"{action} was rejected")
return True
安全护栏的意义,不是限制代理什么都不能做,而是让它在推进任务的同时,始终待在明确边界里。
八、结尾:从 Harness 工程出发,Claude Code 最值得学什么
把 Claude Code 拆到最后,会发现它最值得学习的不是某个单点功能,而是一种工程顺序。
真正重要的,不是先追求“更像人”,而是先把系统骨架搭起来:
- 先做执行闭环
- 再做工具协议、记忆与上下文
- 然后补上编排、可观测性和自愈能力
- 最后用安全护栏把系统带到可上线状态
这也是 Claude Code 和很多“会写代码的 AI”之间的本质差异。
前者在做的是一个持续执行、可恢复、可追踪、可控边界的工程系统;后者很多时候只是把更强的模型塞进了一个编辑器面板里。
所以,如果一定要用一句话概括 Claude Code 的特性,更准确的说法也许是:
Claude Code 的核心,不是“更会写代码”,而是“把编码代理背后的 Harness 做成了完整产品”。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)