
02:Tool System:Claude Code 如何把想法变成行动
02:Tool System:Claude Code 如何把想法变成行动
上一篇把 Agent Loop 当成 Claude Code 的运行时主线来看。主循环负责维护任务状态,判断下一步该观察、行动、验证,还是询问用户。
但主循环本身负责组织过程。真正让 Claude Code 能读仓库、改文件、跑测试、拿反馈的,是工具系统。
这一篇接着看工具系统:
模型说“我要读文件”“我要改代码”“我要跑测试”时,这些动作如何变成真实项目里的受控行动?
工具系统就是 Claude Code 接触真实工程环境的执行层。它让 agent 有眼睛看项目,有手修改文件,有办法运行验证,也有一套规则把结果带回下一轮判断。
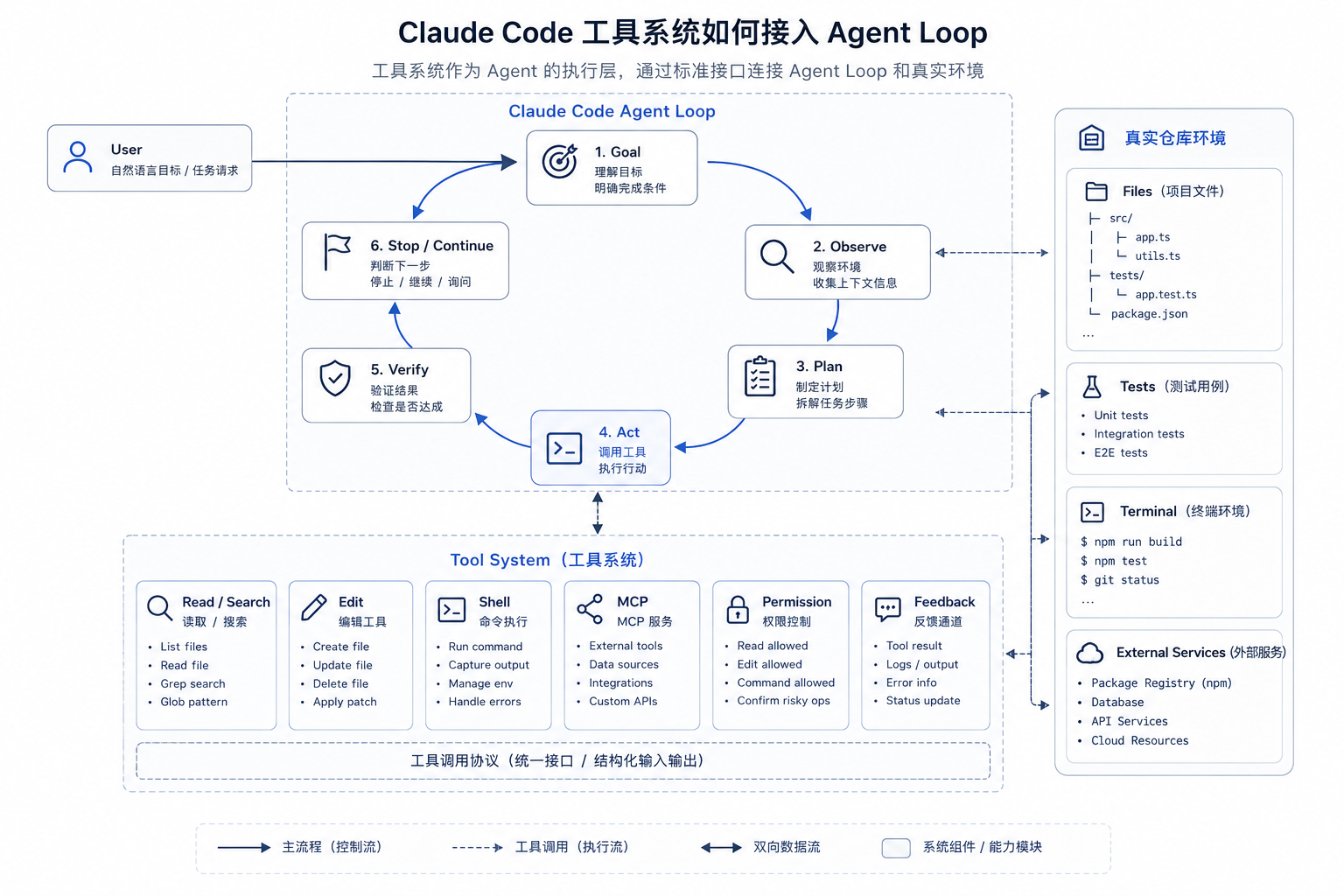
这篇文章要拆的主线
这一篇回答的问题是:
Claude Code 如何把模型想做的事,变成系统可检查、可执行、可回收结果的工具动作?
工具系统容易被理解成能力清单:读文件、搜代码、改文件、跑命令。
这个清单有用,但还只是入口。真正的工具系统要解决的是一条完整链路:
模型提出动作
-> 工具系统检查输入
-> 判断风险和权限
-> 执行真实动作
-> 整理工具结果
-> 回到 Agent Loop
这条链路决定了 agent 工作时的稳定性。
一个工具设计得好,模型更容易选对它,系统更容易判断风险,主循环也更容易理解结果。工具设计得粗,agent 就会多绕路:读太多文件、跑错命令、把长日志塞满上下文,或者在失败后不知道下一步该怎么走。
这篇只讲工具系统本身。权限判断的位置会点到,第 07 篇展开;工具结果进入上下文以后怎么筛选和压缩,第 05 篇展开;MCP、插件、技能这些扩展机制,第 10 篇展开。
工具系统解决的工程问题:让 agent 接触真实项目
Claude Code 面对的是真实仓库。仓库里有代码、配置、测试、依赖、日志、历史改动,也可能有用户已经改过但还没提交的文件。
用户经常只给一句目标:“这个构建失败了,帮我修一下。”模型一开始只有目标,缺少现场信息。工具系统要帮它把现场补出来。
工具系统至少解决五件事。
-
看见项目。
列目录、读文件、看配置,让 agent 建立项目地图。 -
定位证据。
搜索关键词、追踪报错、查引用关系,把问题范围缩小到具体文件和位置。 -
改变环境。
编辑文件、应用补丁、调整配置,把判断落到真实仓库里。 -
运行验证。
跑测试、构建、类型检查或其他命令,拿到可判断的结果。 -
回收反馈。
把文件内容、搜索结果、diff、退出码、错误输出整理回主循环。
所以工具系统的价值,可以这样概括:
工具系统让 Claude Code 用一组受控动作接触真实项目,并把项目反馈整理回 Agent Loop。
这里的关键词是“受控动作”。工具越强,越需要边界。读文件和搜索通常风险较低;写文件会改变仓库;运行命令可能产生副作用;访问外部系统还会带来更多安全和权限问题。
这一层风险控制先放在工具系统里标出位置,后面第 07 篇权限控制再专门拆。
最小工具底座:看、找、读、改、跑
Claude Code 的工具能力很多,但从本地 coding agent 的底座看,最小工具集可以先压成五类。
| 工具能力 | 它在主循环里的作用 | 典型反馈 |
|---|---|---|
| 看目录 | 建立项目地图,找到可能入口 | 文件树、模块结构 |
| 搜索 | 从关键词、报错、函数名定位候选位置 | 路径、行号、命中片段 |
| 读文件 | 精读关键文件,理解真实实现 | 文件片段、行号、上下文 |
| 改文件 | 把判断落到代码、文档或配置 | diff、改动范围 |
| 跑命令 | 验证构建、测试、类型检查或脚本结果 | 退出码、输出摘要、错误信息 |
这五类工具对应的是“看、找、读、改、跑”。
看和找让 agent 先把范围稳住。读文件让它拿到真实代码。改文件让判断落地。跑命令给任务收敛提供证据。
工具系统里还会有很多扩展能力,比如 Web、MCP、LSP、浏览器、数据库、设计稿、issue 系统。它们能把 Claude Code 接到更大的工作流里,但本地 coding 任务先要把底座打稳。
用大白话说:
Claude Code 至少要能看项目、找线索、读关键文件、做小范围修改、运行验证,并把每一步结果交回主循环。
执行流水线:从工具请求到结果回流
资料里对 Claude Code 工具系统的拆解,有一个共同点:工具调用是一条执行流水线,模型的意图要经过运行时检查以后才会接触文件系统。[1],[2]
可以把它理解成这几步:
模型提出工具请求
-> 参数检查
-> 权限和风险判断
-> hook 或运行时拦截
-> 工具执行
-> 结果封装
-> 回流主循环
每一步都有自己的意义。
参数检查负责确认路径、命令、输入格式是否合理。
权限和风险判断负责区分只读、写入、高风险命令这些动作。
hook 或运行时拦截给团队规则和自动化流程留入口。
工具执行真正去读文件、搜索、编辑或运行命令。
结果封装负责把工具输出整理成主循环能继续使用的材料。
这样设计以后,模型的“我想做什么”会变成系统的“这次动作是否可执行、怎么执行、做完返回什么”。
这里有一个很重要的边界:工具层负责把动作执行清楚,把结果返回清楚;下一步继续读、改、跑,还是停止总结,交给 Agent Loop 判断。
工具协议:描述、输入、风险和输出
工具系统稳定的关键,不在于工具数量多,而在于每个工具的协议清楚。
一个工具至少要说清四类信息。
| 协议部分 | 要解决的问题 | 对 agent 的影响 |
|---|---|---|
| 工具说明 | 这个工具适合什么时候用 | 帮模型选对工具 |
| 输入格式 | 参数要怎么写,路径和命令如何表达 | 减少无效调用 |
| 风险属性 | 只读、写入、破坏性、是否可并发 | 帮系统做权限和调度 |
| 输出格式 | 返回什么结果,错误如何表达 | 帮主循环理解下一步 |
这张表比具体接口名更重要。
模型看到工具说明和输入格式,才能知道什么时候用、怎么用。运行时看到风险属性,才能判断是否需要确认、是否适合并行。主循环看到结构化输出,才能继续定位问题或判断任务完成。
比如一个搜索工具,如果只返回一大段文本,模型还要自己猜路径、行号和上下文。更适合 agent 的返回方式,是把路径、行号、命中片段、命中数量分开。这样下一轮可以直接决定读哪个文件。
再比如命令工具,返回“失败了”帮助很小。更有用的是工作目录、命令、退出码、stdout/stderr 摘要、是否超时、是否产生副作用。这些信息会直接影响下一轮判断。
所以工具协议的目标很朴素:
让工具结果既能给人读,也能被下一轮主循环继续使用。
风险分层:只读、写入和命令工具的边界
工具能力越强,越需要分层。
Claude Code 这类 coding agent 里,工具大致可以按风险分成三层。
-
只读观察工具。
搜索、读文件、列目录这类工具主要负责观察。它们通常风险较低,适合频繁使用,也更适合并行。它们的问题主要是返回太多、噪声太大,需要上下文管理来接住。 -
写入工具。
编辑文件、写文件、应用补丁会改变仓库。它们需要关注改动范围、目标文件、已有用户改动和 diff。一个好的写入工具要让主循环看清“改了哪里”和“改动是否集中”。 -
命令工具。
Bash 或 shell 命令能力最强,也最复杂。它能跑测试和构建,也可能改文件、删文件、访问网络或卡住。命令工具需要工作目录、超时、环境信息、退出码和副作用记录。
这三层风险后面会和权限系统合在一起看。第 07 篇会专门讲哪些动作可以直接执行,哪些动作要询问用户,哪些动作要被拦住。
在 02 里先记住一点:
工具系统既要判断动作是否可执行,也要判断它属于哪类风险、结果如何回收。
并行工具调用:哪些动作可以同时做
工具系统还有一个容易被低估的设计:并行工具调用。
并行的目标是减少等待时间,尤其是在观察阶段。很多只读动作互相独立,可以同时进行。比如排查构建失败时,agent 可能同时搜索错误关键词、读取配置文件、查看相关目录结构。这些动作都在收集证据,彼此之间没有写入冲突。
适合并行的动作通常有几个特点:
- 只读。
- 互不依赖。
- 目标都是收集证据。
- 结果之间可以合并。
典型例子包括多个关键词搜索、读取几个互不相关的候选文件、同时查看配置和测试入口。
适合串行的动作也很明确:
- 写文件。
- 运行可能改变环境的命令。
- 依赖前一步输出的操作。
- 同一文件上的连续编辑。
- 同一个服务的启动、停止和验证。
并行工具调用真正麻烦的地方在结果合并。多个搜索结果回来以后,系统要能去重、归类、标出冲突,再交给主循环判断。比如两个搜索都指向同一个文件,就应该合并成一个候选;两个结果给出不同入口,就要把分歧保留下来。
有资料提到 Claude Code 相关分析里出现过流式工具执行和并行工具调用的设计讨论[3],[5]。这里先看工程原则:
并行适合用来更快收集证据,串行适合用来控制副作用。
并行还会影响可观测性和失败恢复。哪个工具先返回、哪个工具失败、部分成功时怎么继续,这些问题后面第 08、09 篇再展开。
工具结果:下一轮判断的证据
工具调用的终点,是结果回流。
这部分是工具系统和 Agent Loop 接上的地方。工具执行完以后,主循环需要知道发生了什么,以及这些结果对下一步有什么意义。
工具结果最好包含几类信息:
| 工具结果 | 为什么有用 |
|---|---|
| 文件片段 | 支撑模型理解真实代码 |
| 搜索命中 | 指向候选文件和行号 |
| diff | 说明环境发生了哪些变化 |
| 退出码 | 判断命令成功、失败或异常 |
| 输出摘要 | 从长日志里提取高信号内容 |
| 错误类型 | 区分路径错误、权限不足、命令失败、超时 |
| 副作用记录 | 判断是否需要验证、回滚或说明风险 |
这里的重点是“高信号”。
测试日志可能几百行,构建输出可能更长。工具层要尽量把结果整理成主循环能读懂的证据:失败测试名、报错文件、错误行、关键堆栈、退出码、是否超时。
如果工具只是把一大段输出原样塞回去,上下文很快会被噪声占满。工具结果如何裁剪、保留、压缩,就是第 05 篇要继续拆的问题。
工具变多以后:常驻、搜索和延迟加载
工具数量变多以后,工具本身也会带来成本。
每个工具都要有说明、输入格式和行为边界。模型要看懂这些说明,系统也要把它们放进合适的位置。工具太多时,选择变难,上下文也会被工具描述占掉一部分。
所以工具系统需要分层管理。
-
高频底座常驻。
读文件、搜索、编辑、运行命令这些高频工具要随时可用。 -
低频工具延迟加载。
某些工具只在特定任务里出现,比如特殊格式处理、外部服务、平台相关工具。它们可以需要时再加载。 -
工具搜索帮助发现能力。
当工具很多时,agent 可以先搜索工具,再决定把哪些工具放进当前上下文。Kubesimplify 对 deferred tool loading 和工具 schema 稳定性有专门分析[4]。 -
扩展工具接入外部系统。
MCP、Web、LSP、插件、技能都可以把外部能力接进来。这里先点到为止,第 10 篇会专门讲扩展机制。
这说明一个问题:工具系统越强,越需要管理工具本身。
工具系统追求的方向是:高频底座稳定、低频能力可发现、外部工具可接入、结果能回流。
案例分析:构建失败时工具如何接力
继续沿用 01 的例子:用户说“博客页面构建失败了,帮我修一下”。
工具系统会把这个模糊目标拆成一串可执行动作。
读 package.json
-> 确认构建命令和脚本入口
运行构建命令
-> 拿到退出码、错误摘要和报错文件
搜索报错关键词
-> 找到相关文件和候选调用点
读取目标文件
-> 确认 frontmatter、导入路径或组件用法
编辑文件
-> 做最小范围修改,返回 diff
再次运行构建
-> 返回验证结果
整理结果
-> 把改动、验证命令、剩余风险交回主循环
这个例子里,每个工具只做一小步。读文件不负责判断任务是否完成;构建命令不负责决定怎么修;编辑工具不负责总结。它们各自返回高信号结果,主循环再把这些结果串起来。
这样看,工具系统像一组受控的工程动作。它们把“我想修构建失败”变成“我读了哪个文件、跑了哪个命令、改了哪一行、验证结果是什么”。
对我写 Agent 的启发:先设计工具协议
如果自己写一个最小 coding agent,我会先把工具协议设计清楚,再增加工具数量。
第一版工具可以很少:
list_files:列目录,并过滤依赖目录和构建产物。search:返回路径、行号、命中片段。read_file:支持行号范围,避免整文件塞入上下文。edit:做小范围修改,返回 diff。run_command:记录工作目录、超时、退出码和输出摘要。git_status:查看已有改动,减少覆盖用户工作的风险。
比工具数量更重要的是统一返回格式。
每次工具调用最好都带上这些信息:
- 这次调用的意图。
- 工具输入。
- 风险等级。
- 是否改变环境。
- 成功结果或错误类型。
- 给下一轮看的高信号摘要。
这样工具调用更像一次小实验:带着一个假设行动,拿到结果以后更新任务状态。
我还会给工具加并发策略。只读工具可以并行收集证据;写入工具和有副作用的命令默认串行;并行结果要先合并,再交给主循环判断。
这套协议比工具数量本身更重要。工具少一点也能跑,协议乱了以后,主循环很快会看不懂发生了什么。
下一篇:提示词系统如何让 Agent 按协议行动
这一篇先把工具系统理解成 Claude Code 的执行层。
它的作用可以收束成一句话:
工具系统把模型意图变成受控动作,再把真实项目反馈整理回主循环。
但工具有了以后,新的问题马上出现:agent 为什么知道什么时候该用哪个工具,应该遵守哪些项目规则,又该用什么方式和用户协作?
所以下一篇要继续追的问题就是:
Claude Code 如何把系统提示、项目规则、工具描述和用户指令,组织成 agent 每轮行动前看到的行为协议?
参考资料
Claude Code 源码分析
[1] 《驾驭工程:从 Claude Code 源码到 AI 编码最佳实践》
本文主要参考它关于工具接口、工具注册、执行编排和流式工具执行的分析。
[2] Tool Call Implementation - liuup/claude-code-analysis
本文主要参考它关于从工具请求到工具结果回流这一执行链路的分析。
[3] Diving into Claude Code’s Source Code Leak - Engineer’s Codex
本文主要参考它关于 Grep、Glob、LSP 等结构化观察工具,以及工具系统和其他模块挂接关系的分析。
[4] What Claude Code’s Leaked Source Actually Teaches Us About Building AI Agents - Kubesimplify
本文主要参考它关于 deferred tool loading、工具 schema 稳定性和工具数量管理的分析。
[5] Claude Code Architecture Analysis - Bits, Bytes and Neural Networks
本文主要参考它关于 StreamingToolExecutor、并行工具执行和工具调用延迟优化的分析。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)