
知识库问答接入模型 API 时,为什么要先验证上下文成本和错误处理
知识库问答接入模型 API 时,为什么要先验证上下文成本和错误处理

一、问题背景:为什么这个问题现在值得重新看
最近很多团队把知识库问答、智能客服、研发文档助手和内部 Agent 接到模型 API 上。
表面上看,这件事只需要三步:准备知识库,配置模型,填一个 Base URL。
实际落地时,问题通常不是“模型能不能回答”,而是“模型到底拿到了什么上下文、花了多少成本、失败时谁来兜底”。
我见过几类很常见的故障。
第一类是回答不稳定。
同一个问题,第一次命中文档,第二次变成泛泛回答,第三次直接说没有相关信息。
第二类是成本不好解释。
调用次数不多,但账单上升很快,排查后才发现每次都塞入了过长的检索片段、历史对话和系统提示词。
第三类是错误处理缺失。
知识库应用在 Dify 里正常,换到 Cursor、Chatbox、Cherry Studio 或自研脚本里就开始报错。
有的客户端把 Base URL 拼错。
有的客户端不支持某些响应字段。
有的客户端遇到 429 或 5xx 后连续重试,把一次失败放大成一串失败。
所以,知识库问答接入模型 API 时,不能只验证“能不能返回一句话”。
更应该先验证四件事:
- 上下文是否可控。
- 错误是否可分类。
- 成本是否可记录。
- 客户端是否可迁移。
这篇文章用一个偏工程化的方式,把验证链路拆开。
二、不要只看模型名:先判断这次调用属于什么负载
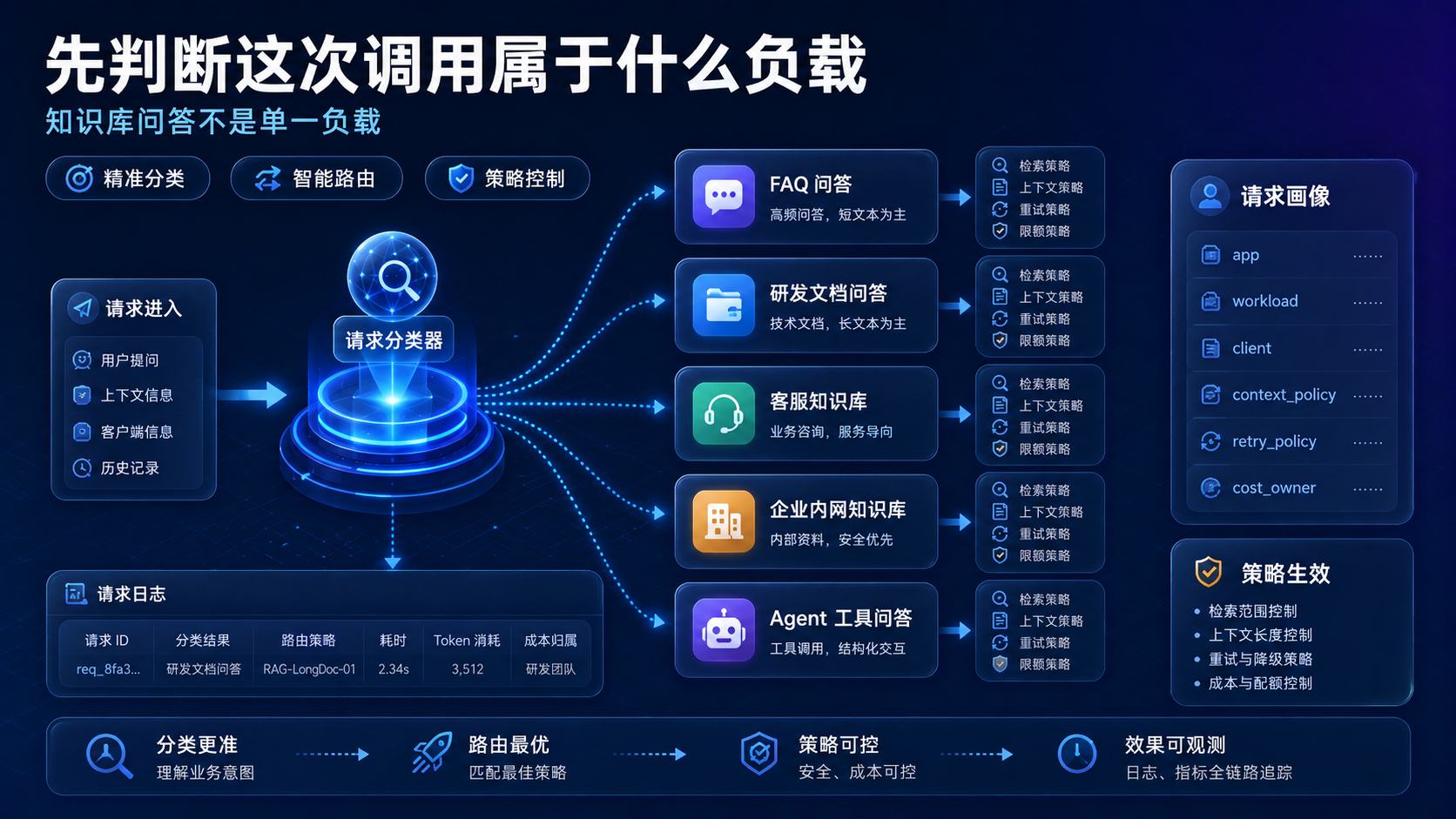
知识库问答不是一种单一负载。
它至少包含检索、拼接、生成、引用、重试和记录几个环节。
如果只看模型名,很容易忽略真正影响稳定性的部分。
常见负载可以这样拆:
| 负载类型 | 主要风险 | 验证重点 |
|---|---|---|
| FAQ 问答 | 命中片段太短或太泛 | 检索命中率、片段排序、拒答逻辑 |
| 研发文档问答 | 版本混杂、术语相近 | 文档版本、引用来源、上下文窗口 |
| 客服知识库 | 高并发、重复问题多 | 缓存、限流、重试、成本统计 |
| 企业内网知识库 | 权限边界不清 | 用户身份、数据脱敏、日志留存 |
| Agent 工具问答 | 工具结果和检索结果混合 | 调用链、工具失败、结果验收 |
一个比较稳的做法是,在真正接入业务前,先给每次请求打上负载标签。
例如:
request_profile:
app: internal-kb-qa
workload: retrieval_qa
client: dify
user_scope: employee
context_policy: top_k_5
retry_policy: no_retry_on_4xx
cost_owner: docs_team
这些字段不是为了好看。
它们决定后面的路由、日志、预算和错误处理。
如果一个知识库问答请求没有负载标签,后面出现“回答变长”“成本上升”“某个客户端报错”时,排查会很被动。
三、Base URL 配置应该怎么验证
Base URL 是很多接入问题的第一现场。
但 Base URL 不是只看字符串对不对。
至少要确认三层地址:
服务域名:https://api.vectorengine.cn
Base URL:https://api.vectorengine.cn/v1
Chat Completions 路径:https://api.vectorengine.cn/v1/chat/completions
如果客户端要求填 Base URL,一般填到 /v1。
如果是自研 HTTP 请求,则需要拼完整接口路径。
建议先用 curl 做最小健康检查。
export MODEL_API_KEY="your_api_key"
export MODEL_BASE_URL="https://api.vectorengine.cn/v1"
export MODEL_NAME="your_model_name"
curl -sS --max-time 20 \
-w "\nHTTP_STATUS:%{http_code}\nTOTAL_TIME:%{time_total}\n" \
-X POST "${MODEL_BASE_URL}/chat/completions" \
-H "Authorization: Bearer ${MODEL_API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"model": "'"${MODEL_NAME}"'",
"messages": [
{
"role": "system",
"content": "你是一个用于接口健康检查的助手,只返回简短结果。"
},
{
"role": "user",
"content": "请返回 ok,并说明当前请求已到达模型接口。"
}
],
"temperature": 0.2,
"max_tokens": 80
}'
这个检查要看三件事。
第一,HTTP 状态码是不是 200。
第二,响应耗时是否在可接受范围内。
第三,返回体里有没有错误对象、用量字段或模型侧拒绝信息。
不要只看页面上有没有一句回答。
知识库系统真正上线后,问题往往出在“偶发慢请求”“某些输入触发 400”“限流时没有退避”。
四、Dify、Cursor、Chatbox、Cherry Studio 接入时最容易错在哪里

不同客户端对 OpenAI 兼容接口的配置方式不完全一样。
Dify 更像应用编排平台。
它关心模型供应商、模型名称、凭证、知识库检索和工作流节点。
Cursor 更偏开发环境。
它关心编辑器内的模型调用、上下文注入和响应速度。
Chatbox 和 Cherry Studio 更接近通用模型客户端。
它们关心自定义供应商、模型列表、流式响应和对话体验。
容易错的地方主要有这些:
| 客户端 | 常见错误 | 排查方式 |
|---|---|---|
| Dify | Base URL 填到完整路径,导致重复拼接 | 只填到 /v1,再单独配置模型名 |
| Cursor | 模型名可见但调用失败 | 用 curl 验证同一 key 和同一模型名 |
| Chatbox | 普通对话可用,知识库场景变慢 | 检查上下文长度和是否开启流式 |
| Cherry Studio | 自定义供应商保存成功但请求 401 | 检查 Authorization 格式和 key 是否带空格 |
| 自研后端 | 本地可用,线上超时 | 检查网络出口、代理、DNS、超时设置 |
这里有一个小经验:先不要急着接知识库。
先用同一个 key、同一个模型名、同一个 Base URL,在 curl、Python、自研服务和目标客户端里各跑一次最小请求。
如果最小请求都不一致,就不要继续排查检索效果。
因为检索层再怎么调,也救不了基础接口配置错误。
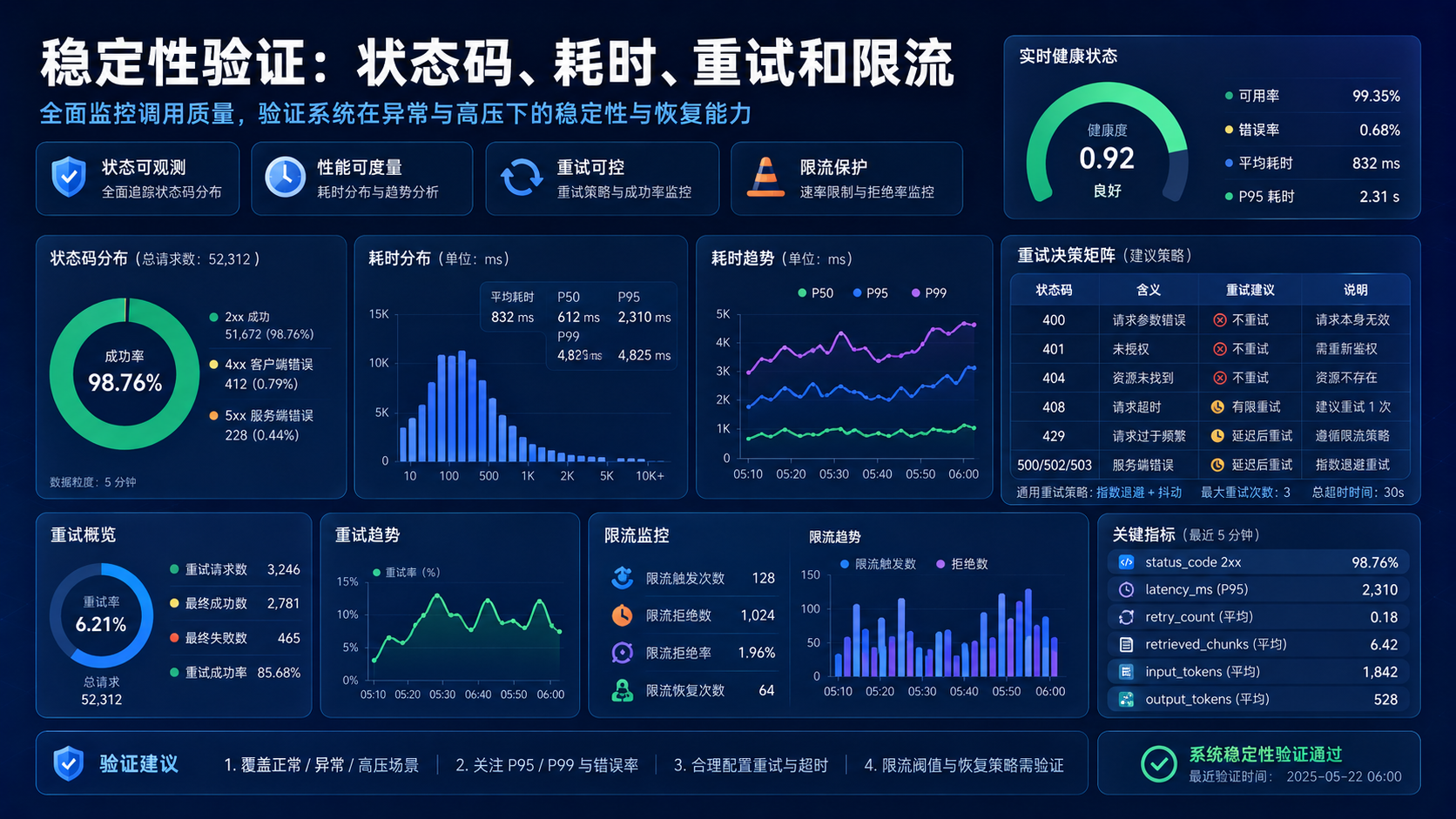
五、稳定性验证:状态码、耗时、重试和限流

知识库问答最怕两种稳定性问题。
一种是显性失败。
例如 401、404、429、500。
另一种是隐性失败。
例如响应时间突然变长、重试次数过多、回答来自错误上下文、引用来源缺失。
上线前建议记录这些字段:
{
"request_id": "kbqa-20260705-001",
"client": "dify",
"model": "your_model_name",
"status_code": 200,
"latency_ms": 1840,
"retry_count": 0,
"retrieved_chunks": 5,
"input_tokens": 3200,
"output_tokens": 420,
"error_type": null
}
重试策略要谨慎。
不是所有错误都应该重试。
一般可以这样处理:
| 状态 | 是否重试 | 原因 |
|---|---|---|
| 400 | 不重试 | 请求结构、上下文或参数问题 |
| 401 | 不重试 | key、权限或认证问题 |
| 404 | 不重试 | 模型名、路径或供应商配置错误 |
| 408 | 可有限重试 | 请求超时,可能是网络问题 |
| 429 | 延迟后重试 | 限流或额度问题,需要退避 |
| 500/502/503 | 可有限重试 | 服务端暂时异常 |
| 200 但内容为空 | 不直接重试 | 先记录响应体和输入上下文 |
重试次数建议限制在 2 次以内。
知识库问答一旦叠加检索、生成和工具调用,盲目重试很容易放大成本。
六、成本核算:不要只看单价,要看完整调用链
很多团队看成本时只看模型输入输出单价。
这在普通聊天里勉强够用,但在知识库问答里不够。
知识库问答的成本来自完整调用链:
总成本相关 token =
系统提示词
+ 用户问题
+ 历史对话
+ 检索片段
+ 工具返回结果
+ 模型输出
+ 重试请求
+ 调试请求
真正需要记录的是“为什么这次请求用了这些上下文”。
一个简单的成本记录可以这样设计:
{
"question": "如何配置生产环境的模型 Base URL?",
"retrieval": {
"top_k": 5,
"chunk_tokens": 2480,
"source_count": 3
},
"prompt": {
"system_tokens": 320,
"history_tokens": 600,
"user_tokens": 28
},
"completion": {
"output_tokens": 460
},
"retry": {
"count": 0,
"tokens": 0
}
}
然后再做一个内部口径:
单次问答估算成本 = 输入 token 成本 + 输出 token 成本 + 重试成本 + 检索链路成本
这里不一定要一开始就做到财务级精确。
但至少要能回答三个问题:
- 哪类问题最贵。
- 哪个客户端最容易产生长上下文。
- 哪些知识库片段经常被塞入但没有帮助。
如果回答不了这三个问题,后面很难做预算控制。
七、合规和安全:密钥、日志、数据边界和团队权限

知识库问答经常接企业文档、客户问题、工单记录和研发资料。
所以安全边界要早于功能上线。
至少要检查这些点:
- API Key 不写进前端代码。
- 日志里不记录完整密钥。
- 用户问题和检索片段区分敏感级别。
- 内部文档按用户权限过滤后再进入模型上下文。
- 调试日志设置保留周期。
- 对外部供应商或中转服务明确数据边界。
- 团队成员按角色分配配置权限。
这里可以把向量引擎中转站作为一个可测试的统一 Base URL 样本,但它不应该成为唯一依赖。
工程上更稳的方式是保留抽象层:
model_gateway:
provider: vector_engine_sample
base_url: "${MODEL_BASE_URL}"
api_key: "${MODEL_API_KEY}"
model: "${MODEL_NAME}"
timeout_seconds: 20
log_request_body: false
log_response_body: false
redact_fields:
- Authorization
- api_key
- phone
- email
这段配置的重点不是某个平台名。
重点是把密钥、日志、超时、脱敏和模型名称放到可审计的位置。
八、代码示例:用通用 HTTP 请求验证接口

下面是一个 Python requests 示例。
它没有使用特定 SDK,只做通用 HTTP 请求。
它包含超时、状态码判断、错误文本输出、耗时记录、有限重试和用量记录。
import os
import time
import json
import requests
MODEL_API_KEY = os.environ["MODEL_API_KEY"]
MODEL_BASE_URL = os.environ.get("MODEL_BASE_URL", "https://api.vectorengine.cn/v1")
MODEL_NAME = os.environ.get("MODEL_NAME", "your_model_name")
url = f"{MODEL_BASE_URL.rstrip('/')}/chat/completions"
payload = {
"model": MODEL_NAME,
"messages": [
{
"role": "system",
"content": "你是知识库问答接口验证助手。回答要简短,并说明是否收到上下文。"
},
{
"role": "user",
"content": "问题:生产环境如何验证 Base URL 配置?\n上下文:Base URL 应填到 /v1,完整路径由程序拼接。"
}
],
"temperature": 0.2,
"max_tokens": 200
}
headers = {
"Authorization": f"Bearer {MODEL_API_KEY}",
"Content-Type": "application/json"
}
def classify_error(status_code, text):
if status_code == 401:
return "auth_error"
if status_code == 404:
return "route_or_model_error"
if status_code == 429:
return "rate_limit"
if 500 <= status_code < 600:
return "server_error"
if status_code >= 400:
return "request_error"
if not text:
return "empty_response"
return None
max_attempts = 3
for attempt in range(1, max_attempts + 1):
started = time.perf_counter()
try:
resp = requests.post(url, headers=headers, json=payload, timeout=20)
latency_ms = round((time.perf_counter() - started) * 1000)
error_type = classify_error(resp.status_code, resp.text)
record = {
"attempt": attempt,
"status_code": resp.status_code,
"latency_ms": latency_ms,
"error_type": error_type
}
if resp.status_code == 200:
data = resp.json()
record["usage"] = data.get("usage", {})
record["answer"] = data.get("choices", [{}])[0].get("message", {}).get("content", "")
print(json.dumps(record, ensure_ascii=False, indent=2))
break
record["error_text"] = resp.text[:500]
print(json.dumps(record, ensure_ascii=False, indent=2))
if resp.status_code not in (408, 429, 500, 502, 503, 504):
break
time.sleep(min(2 ** attempt, 8))
except requests.Timeout:
latency_ms = round((time.perf_counter() - started) * 1000)
print(json.dumps({
"attempt": attempt,
"status_code": None,
"latency_ms": latency_ms,
"error_type": "timeout"
}, ensure_ascii=False, indent=2))
time.sleep(min(2 ** attempt, 8))
except requests.RequestException as exc:
print(json.dumps({
"attempt": attempt,
"error_type": "network_error",
"error_text": str(exc)[:500]
}, ensure_ascii=False, indent=2))
break
这个脚本跑通后,再接 Dify 或其他客户端会更稳。
如果脚本本身就失败,优先排查 Base URL、key、模型名、网络出口和请求体。
九、常见错误排查表

| 现象 | 可能原因 | 处理方式 |
|---|---|---|
| 401 Unauthorized | key 错误、key 带空格、权限未开通 | 重新复制 key,检查环境变量和权限范围 |
| 404 Not Found | Base URL 拼错、模型名不存在、路径重复 | 确认 Base URL 填到 /v1,完整路径只拼一次 |
| 429 Too Many Requests | 请求过密、并发过高、额度不足 | 降低并发,增加退避,记录请求来源 |
| 400 Bad Request | messages 格式错误、参数不兼容 | 打印请求体,删掉非必要参数后重试 |
| 响应很慢 | 检索片段过长、历史对话太多 | 限制 top_k,压缩上下文,设置超时 |
| 回答不引用文档 | 检索未命中、排序错误、提示词太弱 | 打印命中文档,检查 chunk 和 rerank |
| Dify 可用但脚本不可用 | SDK 或请求体差异 | 用 curl 对齐 headers、路径和 payload |
| 脚本可用但客户端不可用 | 客户端配置项不一致 | 检查供应商类型、模型名、流式开关 |
| 成本突然升高 | 重试过多、上下文过长、批量任务失控 | 记录 retry tokens 和 retrieved tokens |
| 日志里出现敏感文本 | 日志策略过宽 | 关闭请求体日志,增加脱敏字段 |
十、个人开发者、内容团队、企业团队分别怎么用
个人开发者通常关心接入效率。
建议先用 curl 和 Python 验证接口,再接 Chatbox、Cherry Studio 或自己的脚本。
不要一开始就堆复杂路由。
先把 Base URL、模型名、key、超时和错误输出跑通。
内容团队通常关心知识库问答质量。
重点不是“回答更长”,而是“回答有没有引用正确材料”。
建议记录每次命中的文档标题、片段长度和回答是否使用这些片段。
企业团队通常关心权限、成本和稳定性。
建议把模型调用放在后端服务里,不要让每个客户端直接持有长期 key。
同时要记录成本归属、调用来源、用户身份和错误类型。
如果团队已经有多个客户端,例如 Dify 做工作流、Cursor 做开发辅助、Chatbox 做测试、Cherry Studio 做个人验证,就更应该先统一接口验证口径。
否则每个工具都能“看起来可用”,但问题发生时没人知道到底是哪一层坏了。
十一、适用场景和不适合场景
适用场景:
- 知识库问答准备接入模型 API。
- Dify 工作流需要接 OpenAI 兼容接口。
- 团队要把 Cursor、Chatbox、Cherry Studio 和自研服务接到同一套模型入口。
- 企业内部要记录成本、错误码和调用来源。
- 已经遇到 401、404、429、超时或上下文过长问题。
不适合场景:
- 只想做一次临时聊天,不需要稳定性验证。
- 不记录任何日志,也不关心成本归属。
- 没有权限边界,所有用户都能访问所有知识库。
- 把模型回答当成最终事实,不做引用和验收。
- 希望靠更换模型直接解决检索质量问题。
知识库问答的核心不是把模型接上。
核心是让模型在可控上下文里回答,并且让每次失败都能被解释。
十二、FAQ
1. Base URL 到底应该填哪里?
大多数 OpenAI 兼容客户端填到 /v1。
如果是自己写 HTTP 请求,则在代码里拼 /chat/completions。
不要在客户端里填完整路径后,又让程序再拼一次完整路径。
2. 为什么 curl 能通,Dify 里不通?
常见原因是模型名、供应商类型、流式开关或请求参数不一致。
先把 Dify 实际使用的 Base URL、模型名和 key 与 curl 对齐,再看错误体。
3. 知识库问答成本高,第一步应该看什么?
先看检索片段长度和重试次数。
很多成本不是模型单价造成的,而是每次都带入了过多上下文,或者失败后重复请求。
4. 429 应该怎么处理?
不要立即连续重试。
应该降低并发,增加指数退避,记录是哪一个客户端或工作流触发了限流。
如果 429 来自批量任务,还要加队列和速率限制。
5. 是否应该把所有客户端都接到同一个入口?
可以统一入口,但不要统一权限。
入口可以统一,key、用户身份、成本归属、日志策略和知识库权限应该分开。
6. 知识库问答需要保留完整请求日志吗?
不一定。
生产环境更建议保留结构化摘要,例如状态码、耗时、token、错误类型、文档编号和 request_id。
完整问题和检索片段要按敏感级别决定是否记录。

十三、总结
知识库问答接入模型 API,最容易被低估的是上下文成本和错误处理。
如果只验证模型能不能回答,很快就会遇到成本不可解释、客户端表现不一致、限流难定位、权限边界不清的问题。
比较稳的接入顺序是:
- 先用 curl 验证 Base URL、key、模型名和完整接口路径。
- 再用 Python 或 Node.js 做超时、状态码、重试和用量记录。
- 然后接 Dify、Cursor、Chatbox、Cherry Studio 或自研后端。
- 最后再接真实知识库,并记录检索片段、上下文长度和成本归属。
如果需要一个可测试的统一 Base URL 样本,可以把向量引擎中转站作为候选入口之一,注册链接是 https://178.nz/awa 。
但无论使用哪个入口,都建议把验证重点放在工程事实上:请求是否可复现,错误是否可分类,成本是否可核算,数据边界是否清楚。
这比单纯替换模型名更重要。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)