
Codex 和 Claude Code,到底哪个更好?
一、先看一个真实场景
有些小伙伴在工作中可能遇到过这样的情况:你有个任务——“帮我把这个项目里的日志框架从Log4j迁移到Logback”。你在Claude Code里敲了这句话,它开始读文件、分析依赖、写代码、跑测试……每一步都在终端里实时输出,还会时不时停下来问你“这个文件我可以改吗?”你看着它一步步推进,心里踏实。
同样一句话,你在Codex里敲下去,它会说“收到,我去处理了”,然后你就只能等着。几分钟后它回来告诉你“搞定了”,中间发生了什么你完全不知道。但在这几分钟里,它可能同时在云端开了8个并行的子Agent帮你干活。
这不是段子,这是两种截然不同的工作哲学。
下面这张图帮你直观感受两者的差异:


二、它们到底是什么?
Codex
它是OpenAI的“云端委派式”编程Agent。
Codex是OpenAI推出的终端编程代理。
它不是一个代码补全插件,而是一个能自主拆解需求、跨多文件修改、执行终端命令、运行测试并交付完整功能的“软件工程Agent”。
Codex CLI用Rust重写,轻量且高效。截至2026年6月,Codex CLI在GitHub上已积累82.9K Star,采用Apache-2.0开源协议。
它支持o3、o4-mini、GPT-4.1等模型,甚至有针对CLI优化的codex-mini小模型。
Codex最核心的特点是:任务在云端隔离沙箱中执行。你的代码会被克隆到一个独立容器里,AI在里面干活,你的本地环境不会被触碰。
这对那些担心AI“乱改东西”的开发者来说,是个巨大的安全感来源。
Claude Code
他是Anthropic的“终端协作式”编程Agent。
Claude Code是Anthropic推出的代理型编码工具。
它的设计哲学是:你的终端就是界面,你的代码库就是上下文,Agent端到端处理整个工作流。
Claude Code的核心循环是:收集上下文 → 采取行动 → 验证结果。它会在终端里逐行输出思考过程,每一步都让你看得清清楚楚。
遇到敏感操作(比如删除文件、git push --force),它会停下来问你“可以吗?”
Claude Code最核心的特点是:直接在你的本地机器上运行。它直接访问你的文件系统,在你的终端里执行命令。
这种“不隔一层”的操作方式,让它在处理复杂项目时更灵活、更深入。
三、底层原理
两者的本质差异,不在于模型(Claude用Claude 4系列,Codex用GPT-5.5系列),而在于Harness架构——也就是“驱动AI执行任务的引擎”。
3.1 Codex的Harness
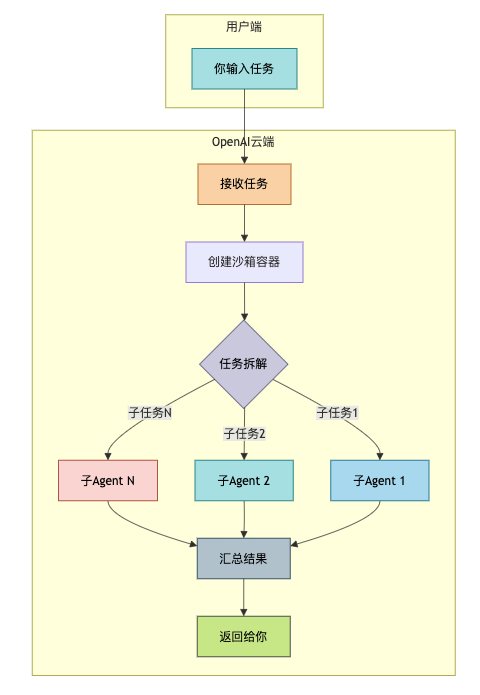
是云端沙箱 + 并行Agent。
Codex的Harness架构围绕“隔离”和“并行”两个关键词设计。
当你给Codex一个任务时:
-
Codex在云端创建一个隔离的沙箱容器
-
把你的代码库克隆进去
-
根据任务复杂度,决定启动多少个并行子Agent(最多8个)
-
每个子Agent负责一部分任务,互不干扰
-
所有子Agent完成后,汇总结果返回给你
这种架构让Codex在可并行化的任务上效率极高。
比如你有5个独立的feature要开发,Codex可以同时开5个容器并行处理。
Codex的Harness执行流程:
3.2 Claude Code的Harness
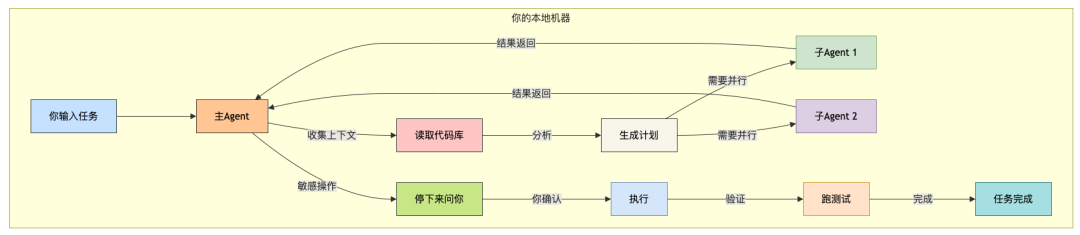
是本地执行 + 协作Agent。
Claude Code的Harness架构围绕“透明”和“协作”两个关键词设计。
当你给Claude Code一个任务时:
-
Claude Code直接在你的本地机器上开始工作
-
每走一步都在终端里输出,你看得见每一步
-
遇到敏感操作会停下来征求你的同意
-
需要并行处理时,通过子Agent来实现
-
所有Agent之间可以相互通信和协调
这种架构让Claude Code在需要深度理解和协作的复杂任务上更有优势。因为它就在你的机器上运行,可以直接访问完整的项目上下文,不用通过“沙箱”这层隔离。
Claude Code的Harness执行流程:
四、谁更强?
数据不会说谎。
我们看2026年最新的基准测试结果。
4.1 SWE-bench
真实GitHub问题修复能力。
SWE-bench是衡量AI编程工具“真实世界编码能力”最重要的基准。
|
基准 |
Codex (GPT-5.5) |
Claude Code (Opus 4.7) |
|---|---|---|
| SWE-bench Pro |
58.6% |
64.3% |
| SWE-bench Verified | 88.7% |
87.6% |
| Terminal-Bench 2.0 | 82.7% |
69.4% |
数据来源:
解读:
-
SWE-bench Pro(更复杂的真实任务):Claude Code领先5.7个百分点
-
SWE-bench Verified(500个人工验证任务):Codex微弱领先
-
Terminal-Bench 2.0(终端命令行任务):Codex大幅领先13.3个百分点
简单说:复杂代码库任务Claude Code更强,终端自动化任务Codex更强。
4.2 综合评测:Codex总分第一
根据2026年6月25日“至顶AI实验室”的硬核评测,在PPT生成、前后端代码开发、论文解读三类真实长流程任务中:
-
Codex:91.6分(第一)
-
Manus:86.4分
-
Claude Code:82.5分
-
OpenClaw:79.9分
数据来源:
这说明在端到端的长流程任务上,Codex的综合表现目前更胜一筹。
4.3 Token效率:Codex的“省油”优势
这是两者最显著的差异之一。Codex在同等任务下使用的Token数量约为Claude Code的三分之一。
有一个真实的对比数据:构建一个Figma插件,Codex用了150万Token,而Claude Code用了620万Token——相差4倍多。
对于按Token付费的用户来说,这个差异直接关系到钱包。
五、功能对比
2026年6月,一位开发者Elie Bakouch做了一件很有意思的事——他把Claude Code和Codex的所有共有功能整理成了一条时间线。
结果发现:两家共有24项相似功能,其中18项是Claude Code先发布的,Codex只先发布了4项。
5.1 Claude Code先发的功能(18项)
包括:无界面脚本化(headless)、模型上下文协议(MCP)、自定义斜杠命令、上下文压缩、子智能体(subagents)、生命周期钩子(hooks)、技能(skills)等。
5.2 Codex先发的功能(4项)
包括:内置沙箱、云端异步智能体、多智能体并行团队、目标模式(Goal mode)。
5.3 关键差异点
|
功能维度 |
Codex |
Claude Code |
|---|---|---|
| 开源协议 |
✅ Apache-2.0 |
❌ 专有软件 |
| 上下文窗口 |
200K tokens |
1M tokens |
| 并行Agent |
最多8个 |
Agent Teams(可通信) |
| 执行环境 |
云端沙箱 |
本地机器 |
| Token效率 | 约3倍 |
基准 |
| IDE扩展 |
✅ VS Code/Cursor/Windsurf |
✅ VS Code扩展 |
特别注意:Codex的云端沙箱执行意味着你的本地环境不会被触碰。
而Claude Code直接在你的机器上运行,虽然更灵活,但也带来了潜在风险——有用户反映Claude Code“非常喜欢用git push --force,甚至在依赖冲突时直接去降级你Spring Boot的版本号”。
六、安装与使用
6.1 Codex CLI安装
Codex CLI的安装非常简单:
# Mac/Linux一键安装
curl -fsSL https://chatgpt.com/codex/install.sh | sh
# 或通过npm安装
npm install -g @openai/codex
# 或通过Homebrew (macOS)
brew install openai-codex
前置条件:Node.js ≥ 18,以及一个ChatGPT Plus/Pro订阅($20/月起)。
使用示例:
# 进入项目目录
cd my-project
# 启动Codex
codex
# 在Codex中输入任务
> 帮我把这个项目的所有console.log替换成logger.info
6.2 Claude Code安装
Claude Code同样通过npm安装:
# 全局安装
npm install -g @anthropic-ai/claude-code
# 启动
claude
前置条件:Node.js 18+,以及Claude订阅($20/月起)。
使用示例:
# 进入项目目录
cd my-project
# 启动Claude Code
claude
# 初始化项目记忆
> /init
# 然后输入任务
> 帮我重构这个Service层的代码,拆分成更小的类
七、优缺点
🌟 Codex的优点
1. Token效率极高:同等任务下Token消耗约为Claude Code的1/3,长期使用成本优势明显。
2. 云端沙箱安全隔离:任务在隔离容器中执行,不会影响你的本地环境。适合担心AI“乱改东西”的开发者。
3. 原生并行执行:最多8个子Agent并行处理任务,适合可并行化的批量任务。
4. 开源可审计:Apache-2.0协议,企业可以Fork并定制。
5. 多端覆盖:CLI、IDE扩展、Web端、桌面App、iOS全覆盖。
6. ChatGPT订阅即用:如果你已经有ChatGPT Plus($20/月),Codex直接就能用。
⚠️ Codex的缺点
1. 复杂代码库任务稍弱:SWE-bench Pro上落后Claude Code约5.7个百分点。
2. 协作感较弱:任务执行过程不透明,适合“派任务等结果”的模式。
3. 上下文窗口较小:200K tokens,处理超大代码库时可能不够用。
4. 云端依赖:需要联网,离线无法使用。
🌟 Claude Code的优点
1. 复杂任务能力更强:SWE-bench Pro领先,适合大型代码库的深度重构。
2. 超长上下文:1M tokens,可以一次性hold住整个微服务代码库。
3. 协作式体验:每一步都输出,敏感操作要确认,适合“边做边看”的工作方式。
4. 功能先行者:24项共有功能中18项先发,产品迭代节奏快。
5. Agent Teams可通信:多个Agent之间可以共享文件和交换消息,适合需要协调的复杂任务。
6. 开发者社区庞大:开发者认知度是Codex的两倍,工作场所采用率是Codex的六倍。
⚠️ Claude Code的缺点
1. Token消耗大:同等任务Token消耗约为Codex的3-4倍。
2. 额度消耗快:有用户反映3分钟就用掉5小时会话配额的60%。
3. 偶发“降智”问题:2026年4月曾因配置Bug导致思考深度骤降67%。
4. 不是开源:CLI不是开源软件,企业无法自由定制。
5. 本地执行风险:直接在你的机器上运行,可能误操作。
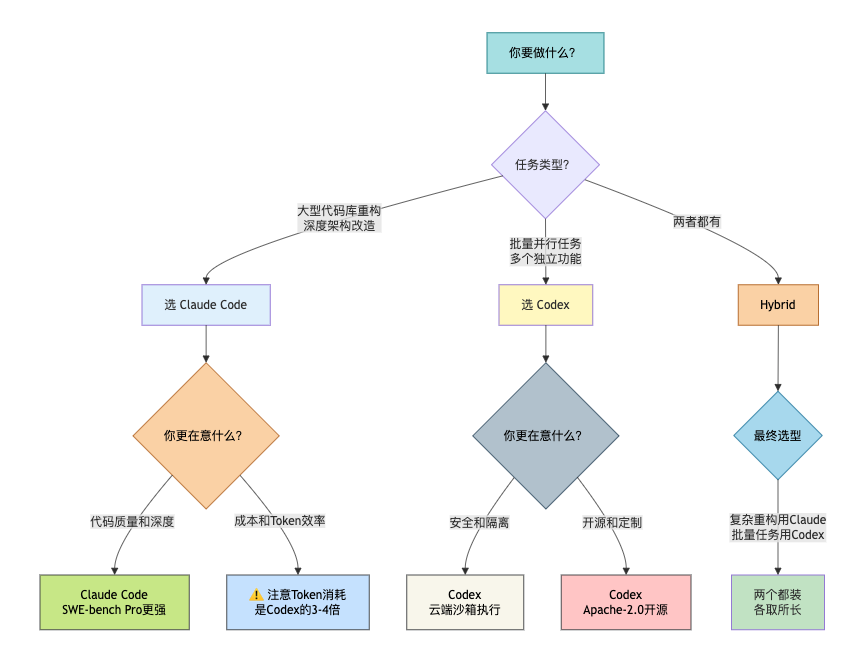
八、一张图看懂怎么选
九、适用场景
选Codex的场景
|
场景 |
理由 |
|---|---|
| 批量并行任务 |
原生支持8个并行子Agent |
| Token预算有限 |
Token效率是Claude Code的3倍 |
| 追求安全隔离 |
云端沙箱执行,不碰本地环境 |
| 需要开源可审计 |
Apache-2.0协议,可Fork定制 |
| 已有ChatGPT订阅 |
无需额外付费 |
| 终端自动化任务 |
Terminal-Bench 2.0领先13.3个百分点 |
选Claude Code的场景
|
场景 |
理由 |
|---|---|
| 大型代码库深度重构 |
SWE-bench Pro领先 |
| 需要超长上下文 |
1M tokens vs Codex的200K |
| 喜欢协作式体验 |
每一步都输出,敏感操作要确认 |
| 追求最新功能 |
24项共有功能中18项先发 |
| 需要Agent间通信 |
Agent Teams支持消息传递 |
| 团队已有Anthropic生态 |
与Claude模型深度集成 |
最佳实践
很多资深开发者发现,两个工具可以互补使用:
-
Claude Code:负责复杂重构、深度理解代码库的任务
-
Codex:负责批量并行、可独立拆分的任务
这种“组合拳”的打法,能让你同时享受两者的优势。
十、写在最后
回到最初的问题:Codex和Claude Code,到底哪个更好用?
答案不是“谁比谁强”,而是“谁更适合你的工作方式”。
如果你喜欢“派任务等结果”的模式——把任务交给AI,然后去喝杯咖啡,回来看结果——Codex更适合你。它的云端沙箱和并行执行能力,让“委派式”工作变得高效又安全。
如果你喜欢“并肩作战”的模式——看着AI一步步推进,随时可以介入、纠正、确认——Claude Code更适合你。它的透明输出和协作式体验,让“结对编程”的感觉更真实。
一个形象的类比:Codex像“项目经理”——你派活,它干完汇报;Claude Code像“结对编程的资深工程师”——你俩坐在一起,边聊边干。
从功能演进来看,两者正在变得越来越像。
Codex在追赶Claude Code的功能丰富度,Claude Code在优化Token效率和稳定性。
这场竞争对开发者来说是好事——我们有更多选择,而且选择还在变得更好。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)