
Claude Sonnet 5 辅助网络爬虫开发完全指南:从 Requests 到 Scrapy,理论、库函数与提示词工程
文章目录
📌 国内读者访问提示:由于 Anthropic 官网(anthropic.com)在国内网络环境下无法直接访问,国内开发者若希望使用 Claude Sonnet 5 辅助网络爬虫开发,可以通过国内可用的镜像站 AIGCBAR 进行注册使用。该镜像站同步了 Claude 全系列模型的 API 接口,支持 low、medium、high、extra、max 五档思考模式,适合从简单的 Requests 请求脚本到复杂的 Scrapy 分布式爬虫架构等不同开发场景。
第 1 章 引言:当“最强编码大脑”遇上网络爬虫
2026 年 6 月 30 日,Anthropic 正式发布了 Claude Sonnet 5。官方将其定位为“迄今最具智能体特质的 Sonnet 模型”——能够制定计划、使用浏览器和终端等工具,并以数月前还需要更大、更昂贵模型才能达到的水平自主运行。对于网络爬虫开发者而言,这意味着一个能够自主完成从请求构造、数据解析到反爬突破、数据存储全流程的 AI 开发助手,首次以中端价格进入了“日常可用”的区间。
网络爬虫是数据采集领域最基础也最重要的技术之一。Python 生态为爬虫开发提供了世界上最丰富的工具链:Requests 以其简洁的 API 成为静态网页请求的首选;BeautifulSoup 将复杂的 HTML 文档转换为可遍历的解析树;lxml 借助 XPath 实现了比 BS4 快 5-10 倍的高性能解析;Scrapy 作为基于 Twisted 异步架构的工业级框架,支撑着高并发的分布式采集系统;Selenium 和 Playwright 则为动态渲染页面提供了浏览器自动化的解决方案。
然而,这个丰富的工具链也带来了陡峭的学习曲线。开发者需要同时掌握 HTTP 协议、HTML 解析、反爬策略、数据存储、并发控制等多个维度的知识。这正是 Sonnet 5 可以发挥独特价值的地方——实测验证表明,只需输入自然语言需求,Sonnet 5 生成的 Python 爬虫代码工整规范、适配性强、自带容错机制,全程零修改即可直接运行。
Sonnet 5 在 SWE-bench Pro 上达到 63.2%,比上一代 Sonnet 4.6 高出 5 个百分点;在 OSWorld-Verified 计算机使用测试中达到 81.2%,与 Opus 4.8 的 83.4% 差距缩至 2.2 个百分点;在知识工作测试 GDPval-AA v2 上拿到 1618 分,甚至反超了 Opus 4.8 的 1615 分。这些数字背后是一个清晰的信号:在编码、工具使用和知识工作领域,Sonnet 5 已经达到了“足够好用”的阈值。
本章作为全文的绪论,旨在说明 Sonnet 5 在网络爬虫开发中的定位。后续各章将从网络爬虫的理论基础、Requests 请求库、BeautifulSoup 与 lxml 解析库、Scrapy 框架、动态页面处理、提示词工程技巧等维度,系统论述如何利用 Sonnet 5 辅助网络爬虫开发。
第 2 章 网络爬虫的理论基础:从 HTTP 协议到数据流水线
理解 Sonnet 5 如何辅助网络爬虫开发,首先需要理解网络爬虫本身的技术体系。这一章从理论层面梳理网络爬虫的核心概念,为后续的库函数讲解和提示词设计提供认知框架。
2.1 爬虫的本质:模拟浏览器的自动化数据采集
网络爬虫的本质是模拟浏览器向目标网站发送 HTTP 请求,获取网页数据后解析提取有用信息的程序。其核心价值在于批量、自动化地获取公开网络数据,适用于数据分析、舆情监控、信息聚合等场景。
从技术实现的视角看,一个完整的爬虫系统需要依次跨越三个层次:
第一层:网络协议层。 爬虫需要理解 HTTP/HTTPS 协议的基本规范——请求方法(GET/POST)、状态码(200/404/503)、请求头(User-Agent、Cookie、Referer)、响应体结构等。Requests 库正是对这一层的封装,将复杂的 socket 操作简化为 requests.get(url) 这样一行代码。
第二层:内容解析层。 获取到的 HTML 源代码是未经整理的文本,爬虫需要通过解析技术从这段文本中提取出结构化的有用信息。BeautifulSoup 将 HTML 转换为可遍历的 DOM 树;lxml 则通过 XPath 表达式实现精准定位。不同解析方案在性能和学习成本上各有取舍。
第三层:数据流水线层。 数据提取之后还需要清洗、去重、格式化、存储等一系列后处理操作。Scrapy 的 Item Pipeline 机制正是对这一层的标准化封装。
2.2 静态网页与动态网页的分野
网络爬虫技术路线最根本的分野,在于目标网页是“静态”还是“动态”:
静态网页:服务器直接返回完整的 HTML 文档,所有内容在首次请求时就已经就绪。这类网页的爬取最为直接——只需一个 HTTP 请求获取 HTML,再用解析库提取数据即可。Requests + BeautifulSoup/lxml 是处理静态网页的经典组合。
动态网页:网页内容由 JavaScript 在浏览器端渲染生成,直接请求 HTML 只能拿到一个空壳框架。典型场景包括单页应用(SPA)、无限滚动列表、登录后加载的数据等。处理动态网页有两种思路:一是通过抓包分析找到数据接口(AJAX/GraphQL),直接请求接口获取 JSON 数据;二是使用无头浏览器(Selenium/Playwright)模拟真实用户操作,等待 JS 渲染完成后提取数据。
技术选型的核心原则是:能用 Requests 就别用 Selenium,能抓接口就别渲染页面。浏览器自动化的资源开销是纯 HTTP 请求的数十倍甚至上百倍。
2.3 反爬策略与突破的攻防博弈
反爬策略是网站为了保护数据资源而设置的技术屏障,爬虫与反爬的博弈构成了网络爬虫领域最动态、最考验工程能力的技术维度。常见的反爬手段可以分为三个层次:
基础层:身份验证。 包括 User-Agent 检测(识别非浏览器请求)、Referer 校验(检查请求来源)、Cookie/Session 验证(区分登录态)。突破手段是伪造请求头——fake_useragent 库可以随机生成各浏览器的 UA 字符串。
进阶层:频率控制。 包括 IP 频率限制(同一 IP 短时间内请求过多触发封禁)、请求间隔检测(请求之间时间间隔过于规律被识别为机器)。突破手段包括:设置随机延迟(1-3 秒间隔)、维护 IP 代理池、使用分布式架构分散请求。
高阶层:行为分析与数据加密。 包括验证码(图形/滑块/行为验证)、动态 Token、WebSocket 加密通信、鼠标轨迹与点击热区监测。这一层次的突破涉及验证码识别(Tesseract/打码平台)、JS 逆向工程等更复杂的技术。
2.4 爬虫开发的技术栈全景
一个完整的网络爬虫项目通常涉及以下技术栈:
| 层次 | 工具/库 | 核心功能 |
|---|---|---|
| 请求层 | Requests / urllib | 发送 HTTP 请求,获取网页源码 |
| 解析层 | BeautifulSoup / lxml / pyquery | HTML/XML 解析,数据提取 |
| 框架层 | Scrapy | 全功能爬虫框架,请求调度、数据流管理 |
| 动态层 | Selenium / Playwright | 浏览器自动化,JS 渲染页面抓取 |
| 存储层 | Pandas / SQLite / MongoDB | 数据清洗与持久化 |
| 辅助层 | fake_useragent / Redis | UA 伪装、分布式队列 |
Sonnet 5 可以在上述每一个层次提供辅助——从解释 Requests 的参数含义,到生成 BeautifulSoup 的解析代码,再到调试 Scrapy 的中间件配置。
第 3 章 Requests:网络爬虫的“第一块敲门砖”
Requests 是 Python 生态中最流行的 HTTP 请求库,基于 urllib 封装,API 简洁友好,是静态网页爬取的首选工具。其核心优势在于用几行代码就能完成过去需要几十行 urllib 代码才能实现的功能。
3.1 Requests 的核心函数与用法
requests.get():发送 GET 请求,是最常用的方法。基本用法:
import requests
response = requests.get('https://example.com', timeout=10)
print(response.status_code) # 200
print(response.text) # 网页源码
requests.post():发送 POST 请求,常用于提交表单或调用 API。
requests.Session():维持会话状态,自动处理 Cookie,适合需要登录的场景:
session = requests.Session()
session.post('https://example.com/login', data={'user': 'test', 'pass': '123'})
response = session.get('https://example.com/dashboard')
请求头伪装:通过 headers 参数模拟浏览器行为,是绕过基础反爬的关键:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'https://www.google.com/'
}
response = requests.get(url, headers=headers)
3.2 Requests 的高级特性
超时与重试:timeout 参数防止请求永久阻塞;配合 urllib3.util.retry 可实现自动重试机制。
连接池:通过 requests.adapters.HTTPAdapter 配置连接池大小,提升高并发场景下的性能。
异步请求:通过 aiohttp 实现异步并发采集,QPS 可提升 5-8 倍。
3.3 Requests 在爬虫中的典型工作流
一个完整的 Requests 爬虫工作流包含以下步骤:
- 构造请求头(User-Agent、Cookie 等)
- 发送 GET/POST 请求
- 检查响应状态码(
response.raise_for_status()) - 获取响应内容(
response.text或response.content) - 将 HTML 传递给解析库
- 提取目标数据
3.4 Requests 常用函数速查表
| 函数/属性 | 用途 | 示例 |
|---|---|---|
get(url, params, headers) |
发送 GET 请求 | requests.get(url, headers=headers) |
post(url, data, json) |
发送 POST 请求 | requests.post(url, data={'key':'val'}) |
Session() |
维持会话 | session = requests.Session() |
response.status_code |
获取状态码 | 200 |
response.text |
获取响应文本 | 网页源码 |
response.json() |
解析 JSON 响应 | data = response.json() |
response.raise_for_status() |
检查请求是否成功 | 失败时抛出异常 |
第 4 章 BeautifulSoup 与 lxml:HTML 解析的“双雄”
获取到网页源码之后,下一步是从混乱的 HTML 中提取出结构化的数据。BeautifulSoup 和 lxml 是 Python 生态中最主流的两个解析库,各有侧重、各擅胜场。
4.1 BeautifulSoup:Pythonic 的 DOM 解析器
BeautifulSoup 是一个基于 Python 的 HTML/XML 解析库,其核心价值在于将复杂的文档结构转换为可编程操作的解析树。通过封装底层解析器的差异,开发者可以使用统一的 Pythonic 接口完成文档遍历、元素定位和数据提取任务。
核心对象:BeautifulSoup 将 HTML 文档转换为树形结构,暴露 Tag、NavigableString、BeautifulSoup、Comment 四种对象类型。
定位方法:
find()/find_all():按标签名、属性、文本内容查找元素select():使用 CSS 选择器定位元素find_parents()/find_children():树遍历
基本用法:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml') # 使用 lxml 作为解析器
title = soup.find('h1').text
items = soup.select('.news-item') # CSS 选择器
links = soup.find_all('a', href=True)
解析器选择:BeautifulSoup 支持多种底层解析器,其中 lxml 解析器在处理大型文档时比默认解析器快 3-5 倍。
4.2 lxml + XPath:高性能的精准定位
如果说 BeautifulSoup 的优势是“易用”,那么 lxml 的优势就是“性能”和“精准”。lxml 结合 XPath(XML Path Language),能够实现比 CSS 选择器强大数倍的数据定位能力。
XPath 的核心优势:
- 支持复杂的条件筛选(如“选取 class 包含 ‘price’ 且 文本大于 100 的所有元素”)
- 支持轴遍历(如“选取当前节点的所有祖先元素”)
- 支持文本匹配和属性匹配的组合
基本用法:
from lxml import html
tree = html.fromstring(page_content)
# XPath 提取
price = tree.xpath('//span[@class="price"]/text()')[0]
# CSS 选择器(lxml 也支持)
name = tree.cssselect('h1.product-name::text')[0].strip()
性能对比:在 lxml 的加持下,XPath 解析速度比 BeautifulSoup 快 5-10 倍。对于需要处理大规模数据的场景,lxml 是更优的选择。
4.3 解析方案的选型指南
| 技术方案 | 性能 | 学习成本 | 适用场景 |
|---|---|---|---|
| 正则表达式 | ★★★★★ | ★★★☆☆ | 简单结构化文本提取 |
| BeautifulSoup | ★★☆☆☆ | ★★☆☆☆ | 复杂 HTML 文档解析、新手友好 |
| lxml + XPath | ★★★★☆ | ★★★☆☆ | 大规模数据高效处理、精准定位 |
| CSS 选择器 | ★★★☆☆ | ★★☆☆☆ | 现代网页元素定位 |
选型的核心原则是:新手从 BeautifulSoup 入门,生产环境优先 lxml。
第 5 章 Scrapy:工业级爬虫框架的架构解析
如果说 Requests + BeautifulSoup 是爬虫开发的“单兵武器”,那么 Scrapy 就是“集团军作战体系”。Scrapy 是 Python 高性能工业级爬虫框架,基于 Twisted 异步架构,支持高并发、自动去重、重试与反爬。
5.1 Scrapy 的核心架构
Scrapy 的核心组件构成了一条完整的数据流水线:
Engine(引擎):Scrapy 的核心,负责控制数据流在所有组件之间的流动,触发事件。
Scheduler(调度器):管理待抓取 URL 的优先级队列,负责去重和调度。
Downloader(下载器):负责发送 HTTP 请求并获取响应。
Spider(爬虫):开发者定义如何解析响应、如何提取数据、如何生成新的请求。
Item Pipeline(管道):处理 Spider 提取的数据——清洗、验证、去重、存储。
5.2 Scrapy 的开发流程
一个典型的 Scrapy 项目开发流程包括:
- 创建项目:
scrapy startproject project_name - 定义 Item:在
items.py中定义数据模型 - 编写 Spider:在
spiders/目录下创建爬虫,定义start_requests()和parse()方法 - 配置 Pipeline:在
pipelines.py中实现数据存储逻辑 - 运行爬虫:
scrapy crawl spider_name -o output.json
5.3 Scrapy 的分布式扩展
Scrapy 原生是单机架构,通过 Scrapy-Redis 可以扩展为分布式爬虫系统。其核心思路是:
- 用 Redis 的 Set 实现 URL 去重队列
- 用 Redis 的 List 实现待抓取任务队列
- 多台机器共享同一个 Redis 队列,实现协同工作
更复杂的分布式方案还包括 Kafka + Scrapy 的整合,将任务分发和结果收集从 Scrapy 原生单机模型中解耦出来。

第 6 章 Selenium 与 Playwright:动态网页的“破局者”
当目标网站的内容由 JavaScript 动态渲染时,Requests 直接获取的 HTML 往往只是一个空壳。这时需要 Selenium 或 Playwright 这样的浏览器自动化工具来模拟真实用户操作。
6.1 Selenium:经典的浏览器自动化工具
Selenium 是一个可编程的浏览器控制工具,能够模拟点击、滚动、输入等真实用户操作。其工作原理是:Python 代码通过 Selenium 库发出指令,指令被传递给对应浏览器的 WebDriver 驱动,驱动将命令转换为浏览器能执行的底层操作。
Selenium 4 的关键升级:
- 废弃
DesiredCapabilities,采用更简洁的配置方式 - 支持相对路径的 Service 配置
- 原生自动下载浏览器驱动
- 强制显式等待(Explicit Wait)
- 统一
find_element方法 - 强化无头模式的反检测能力
CDP 协议支持:Selenium 4 原生支持 Chrome DevTools Protocol(CDP),可以直接在自动化脚本中拦截和分析网页发出的 API 请求。
6.2 Playwright:新一代浏览器自动化的“王者”
Playwright 是微软推出的新一代浏览器自动化库,支持 Chromium、Firefox 和 WebKit 三大浏览器引擎。相比 Selenium,Playwright 的优势包括:
- 更可靠的等待机制:自动等待元素可见、可交互,无需手写
time.sleep() - 更快的执行速度:内置的智能等待减少了不必要的延迟
- 更好的 API 设计:支持 async/await 异步模式
- 多浏览器支持:一套 API 覆盖三大浏览器引擎
对于需要处理复杂 SPA(单页应用)的爬虫任务,Playwright 的事件驱动 DOM 等待和自动等待机制显著提升了稳定性。
6.3 动态网页处理的技术选型
| 工具 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| 直接抓 API | 能找到数据接口 | 最快、最稳定、资源消耗最低 | 需要分析网络请求 |
| Selenium | 中小型动态页面、反爬较弱 | 上手简单、社区成熟 | 资源消耗大、速度慢 |
| Playwright | 复杂 SPA、需要多浏览器 | 更可靠、更快、API 更现代 | 学习成本略高 |
核心原则是:能抓接口就不渲染页面,能不用浏览器就不用浏览器。
第 7 章 提示词工程:让 Sonnet 5 成为更好的爬虫开发助手
提示词工程是连接“模型能力”和“实际效果”的桥梁。同样的模型,不同的提示词策略可能带来数倍的效率差异。实测表明,Claude 生成的爬虫代码一次运行通过率超 90%,无需修改任何参数即可直接运行。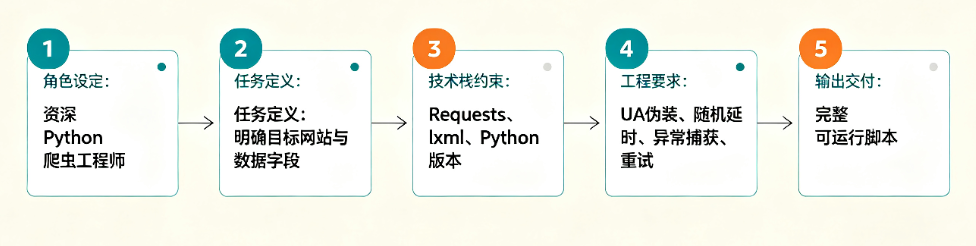
7.1 爬虫开发提示词的黄金结构
基于前文的讨论和爬虫开发的特点,可以总结出爬虫开发提示词的黄金结构:
第一层:角色设定。 “你是一位资深 Python 爬虫工程师。”
第二层:任务定义。 “请帮我写一个爬取 [目标网站] 新闻标题和发布时间的爬虫脚本。”
第三层:技术栈约束。 “使用 requests 和 BeautifulSoup,Python 3.10+。”
第四层:质量要求。 “包含 User-Agent 伪装、随机延迟、异常捕获和超时重试。”
第五层:具体内容。 提供目标 URL、数据字段定义等。
7.2 爬虫代码生成的专用提示词模板
模板一:静态网页爬虫
你是一位资深 Python 爬虫工程师。请帮我写一个爬取公开新闻数据的 Python 脚本。
技术要求:
- 使用 requests 发送 HTTP 请求
- 使用 BeautifulSoup 解析 HTML
- 提取标题、发布时间、阅读量三个字段
- 加入随机 User-Agent
- 每次请求随机延迟 1-3 秒
- 包含完整的异常捕获和超时处理
- 输出为 CSV 格式
目标网站:[提供示例 URL]
模板二:动态网页爬虫
请使用 Selenium 4 编写一个爬取动态渲染页面的脚本。
要求:
- 使用 Chrome WebDriver
- 等待页面完全加载后再提取数据
- 模拟滚动加载更多内容
- 提取 [具体数据字段]
- 包含无头模式配置
- 添加显式等待(Explicit Wait)
模板三:Scrapy 爬虫
请帮我创建一个 Scrapy 项目,用于爬取 [网站] 的 [数据类型]。
要求:
- 定义 Item 数据模型
- 编写 Spider,使用 XPath 提取数据
- 配置 Pipeline 将数据保存到 [存储方式]
- 设置合理的并发数和下载延迟
- 包含 User-Agent 中间件
7.3 迭代优化:从“可用”到“可靠”
初次生成的代码往往只满足基本功能,通过迭代优化可以显著提升代码质量。Sonnet 5 的一个核心优势是:它深度吃透了 Python 爬虫的工程逻辑,生成的代码自带完整的工程体系——请求头模拟、超时重试、异常捕获、编码自适应、数据清洗、格式导出全流程。
迭代优化的提示词示例:
请对上面生成的爬虫代码进行以下优化:
1. 添加随机延时,避免被目标网站封 IP
2. 优化错误处理机制,对不同类型的异常采取不同处理策略
3. 将数据保存为 Excel 格式
4. 如果阅读量包含“万”字,自动乘以 10000 转化为数字
7.4 XML 标签:让提示词结构更清晰
Anthropic 官方建议使用 XML 标签来组织提示词结构,帮助模型清晰地区分提示词的不同部分:
<role>
你是一位资深 Python 爬虫工程师,精通 requests、BeautifulSoup 和 Scrapy。
</role>
<task>
请帮我写一个爬取电商网站商品信息的爬虫脚本。
</task>
<tech_stack>
- Python 3.11
- requests 2.31+
- BeautifulSoup 4
- pandas(数据清洗和导出)
</tech_stack>
<requirements>
- 模拟浏览器请求头
- 处理分页
- 提取商品名称、价格、评价数
- 数据导出为 CSV
- 包含完整的异常处理
</requirements>
<target_url>
https://example.com/products?page=1
</target_url>
第 8 章 Effort 参数调优与成本控制策略
Sonnet 5 提供了五档 effort 参数(low、medium、high、xhigh、max),本质是一个“思考量调节旋钮”——更高的 effort 意味着更深入的推理,但也意味着更多的 token 消耗。在中等 effort 下显著提升成本效率,在更高 effort 下其性能可在某些任务上媲美 Opus 4.8。
8.1 爬虫开发场景的 Effort 选择矩阵
| 任务类型 | 推荐 Effort | 说明 |
|---|---|---|
| 简单 Requests 请求脚本 | medium | 常规代码生成,不需要深度推理 |
| BeautifulSoup 解析代码 | medium-high | 需要理解 HTML 结构 |
| Scrapy 项目搭建 | high | 涉及多文件、多组件 |
| 复杂反爬突破 | xhigh | 需要理解反爬机制 |
| 分布式爬虫架构设计 | max | 最复杂的决策场景 |
8.2 渐进式策略:用最低成本获得最高质量
一个实用的成本控制策略是渐进式 effort 调整:
- 先用 medium 或 high 快速生成初稿
- 评估代码质量
- 如果不满意,用 xhigh 进行深度优化
- 对于架构设计等关键决策,直接使用 xhigh 或 max
8.3 成本估算与注意事项
Sonnet 5 的定价为:促销期(至 2026 年 8 月 31 日)输入 $2/百万 token、输出 $10/百万 token;标准定价为输入 $3/百万 token、输出 $15/百万 token。
需要注意的是,Sonnet 5 启用了新的分词器,同一段英文文本被切分的 token 数量比之前增加了约三成。在估算爬虫脚本生成的成本时,需要预留一定的缓冲空间。
第 9 章 结论:Sonnet 5 正在重新定义爬虫开发的方式
把全文的分析收束起来,可以得出一个清晰的判断:Claude Sonnet 5 正在从根本上改变网络爬虫开发的方式。
这种改变体现在三个层面:
第一,爬虫开发的门槛被显著降低。 传统爬虫开发需要掌握请求协议、解析规则、反爬机制、异常处理等专业知识。而现在,只需输入自然语言需求,Sonnet 5 就能生成工整规范、自带容错机制的爬虫代码。Claude 生成的爬虫代码会自动加上异常捕获和请求限速,避免因请求过快被服务器屏蔽。
第二,爬虫代码的质量远超新手水平。 新手写爬虫常常忽略 UA 伪装、请求间隔、超时设置,导致请求被拦截或 IP 被封禁。而 Claude 生成的代码会自动模拟真实浏览器请求,自带随机请求间隔、超时重试机制、状态码校验。代码分层清晰、注释详细、逻辑严谨。
第三,复杂动态页面的处理变得触手可及。 传统简易爬虫无法解析 JS 动态加载的数据。而 Sonnet 5 可以配合 Selenium 或 Playwright 生成完整的动态页面爬虫脚本,从环境配置到数据提取一气呵成。
当然,Sonnet 5 并非万能。对于需要最高精度的复杂反爬突破,人工分析和调试仍然是必要的。对于超大规模的分布式爬虫架构设计,Opus 4.8 仍然是更稳妥的选择。
但对于绝大多数爬虫开发场景——从简单的静态页面抓取到中等复杂度的动态页面采集——Sonnet 5 已经达到了“足够好用”的阈值。正如 Anthropic 在发布公告中所说:“Sonnet 5 完成了以前的 Sonnet 模型会中途止步的复杂任务”。对于爬虫开发者而言,这意味着一个能够陪伴你从“第一行请求代码”到“第一个完整数据采集系统”的 AI 开发助手——已经触手可及。
参考文献
[1] Anthropic. Introducing Claude Sonnet 5. 2026 年 6 月 30 日. 链接
[2] Help Net Security. Claude Sonnet 5 includes safeguards against dangerous cyber use. 2026-07-01. 链接
[3] NDTV. Anthropic Launches Claude Sonnet 5 To Handle Complex Jobs On Its Own. 2026-07-01. 链接
[4] 量子位. A社你解释下,啥叫Sonnet 5比Fable 5还贵?. 2026-07-02. 链接
[5] 开源中国. Claude写Python爬虫,一行代码不用改. 2026-06-08. 链接
[6] SegmentFault. 自动化脚本编写指南:用 Claude 10分钟搞定 Python 爬虫与数据清洗. 2026-06-12. 链接
[7] 百度开发者中心. Python网络爬虫开发实战:从入门到进阶指南. 2026-02-11. 链接
[8] 百度开发者中心. Python网络爬虫开发全栈指南:从基础到分布式实践. 2026-06-30. 链接
[9] 百度开发者中心. BeautifulSoup:高效解析HTML/XML的Python利器. 2026-01-26. 链接
[10] 腾讯云. 为什么你的爬虫跑着跑着内存就爆了?BeautifulSoup、Lxml与XPath的性能生死局. 2026-06-02. 链接
[11] CSDN. Python爬虫利器PyQuery:用jQuery语法高效解析HTML与数据提取. 2026-05-13. 链接
[12] Scrapy 官方文档. Scrapy Tutorial. 2026. 链接
[13] 阿里云开发者社区. Scrapy框架入门指南. 2026-02-07. 链接
[14] PHP中文网. 如何解决Python爬虫无法抓取JavaScript动态渲染数据的问题. 2026-05-10. 链接
[15] Playwright 官方文档. Playwright for Python. 2026. 链接
[16] CSDN. 告别抓包工具!用Selenium 4 + CDP协议直接拦截网页API请求. 2026-04-30. 链接
[17] CSDN AI编程社区. Claude Sonnet 5 科研神器:如何用提示词工程驾驭英文PDF文献阅读与项目复现. 2026-07-04. 链接
声明:本文所有数据均来自上述公开来源,已尽力核实并标注出处。受限于行业评测方法论本身的局限,具体数值在不同测试环境下可能存在合理误差,建议读者在做开发决策前以 Anthropic 官方最新发布与自身实测为准。文中推荐的 AIGCBAR 为第三方镜像服务,使用前请自行评估其合规性与稳定性。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 1
1 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)