
一篇焦虑文案,ChatGPT 说还行,271 个 AI 用户却想点踩
一、先说我遇到的真问题
上周团队审一篇 AI 职场课的投放文案。文案走的是焦虑路线:"不会用 AI 明年就被优化""你的同事已经在抢你晋升名额了",最后落到 199 元的课程上。
一个同事把文案贴进 ChatGPT,得到的回复是:"结构完整,转化逻辑清晰,但恐吓感略重,建议调整。" 另一个同事皱了皱眉说:"但我感觉这话术有点过了。"
两个人的直觉打架,我们没有一个能拍板的数据。
我忽然意识到:如果我们只问了一个"人"(哪怕是大模型),凭什么相信自己做了"评测"?真实的消费市场里,看到这篇文案的不是一个人,而是一群人——有人被打动,有人被激怒,有人沉默围观,有人转给朋友看热闹。单点意见捕捉不到这种分布。
于是我做了一件事:把同一篇文案同时丢给两个对象——ChatGPT-5.4,以及 RaaS100 万智市场测评的 271 位数字受访者。然后我看到了一个 ChatGPT 永远不会给出的答案。
二、单点评测的盲区:为什么"还行"不等于"能投"
先说说传统的内容评测方式有什么问题。
最常见的是"内部投票":把文案发到群里,大家凭直觉打分。问题是,群里的人背景相近,样本量小,而且没人会认真说"这篇文案让我不舒服"。
另一种方式是"专家评估":请一位资深文案人或营销顾问来看。专家能指出结构问题、语言问题,但他代表的是"专业视角",不是"用户视角"。一篇在专家眼里"手法粗糙"的文案,可能在目标人群里转化率极高;反之亦然。
大模型评测是第三种方式,但它本质上和专家评估类似——一个训练出来的"平均视角"给出一个综合判断。它无法告诉你:这篇文案在 20 岁大学生和 40 岁职场中层眼里的差异有多大?有多少人看了想点踩?有多少人会转给别人但自己不买?
真实的市场不是一个"平均人"在投票,而是一群"不平均的人"在各自做决策。要预测市场反应,你需要的是统计分布,而不是单点意见。
这就是数字孪生测评的思路:用大量各具特色的 AI 模拟不同背景的真实用户,并行阅读素材、表达反馈,最后聚合出人群级别的统计结论。
三、万智测评的实测:271 个人,271 种偏见
我用的测试文案是这篇 AI 职场课的广告:
"你的同事都在偷偷用 AI 了,再不会用明年就被优化。" "现在用 AI 写周报的人,已经在抢你的晋升名额了。" "你愿意花 199 买一堂课,还是等着被 AI 淘汰?"
典型的焦虑驱动 + 社会比较 + 低价成交三件套。手法偏硬,有争议性,最适合检验评测工具的"视野完整性"。
在万智测评里,我配置了 271 名数字受访者,覆盖 20-28 岁和 36-42 岁两个年龄段,学历从大专到硕士,特别勾选了"理性客观"和"挑剔严苛"两种表达倾向。整个测评跑了约 10 分钟。
万智测评是 RaaS100 社区平台上的一个产品模块。底层跑的是魔芋 AI 大模型聚合层——简单说就是替开发者统一接入了通义千问、DeepSeek、GPT 等国内外主流模型,不用自己一个个去谈 API 和管密钥。更关键的是,所有模型调用都经过魔芋企业 AI 网关做流量调度和成本控制,跑完 271 人的并行评测,实际 Token 消耗和费用都在后台精细到调用级可查,不会出现"测评一时爽,账单火葬场"的情况。
第一步,综合评分:5.34 / 10。
等级判定"良好·可投放"——但这个"可投放"前面的修饰语很重。往下看才知道为什么。
第二步,十一维拆解:一个危险的剪刀差。
报告把文案拆成 11 个维度打分。转化引导最高(6.29),卖点提炼第二(6.28),但可信度与依据最低(3.38),品牌传递倒数第二(3.72)。
这意味着什么?这篇文案"会卖",但"割完就跑"——它能在短期内撬动转化,却在长期里透支信任。
截图建议:展示十一维评分图表,突出"转化引导"和"可信度"的两极分化
ChatGPT 也提到了"数据略显冒进",但它是定性描述。万智直接告诉你:3.38 分,在所有维度中垫底,而且和最高分差了将近 3 分。这个量化差距,才是决策时真正需要的数据。
四、几个让我坐不住的发现
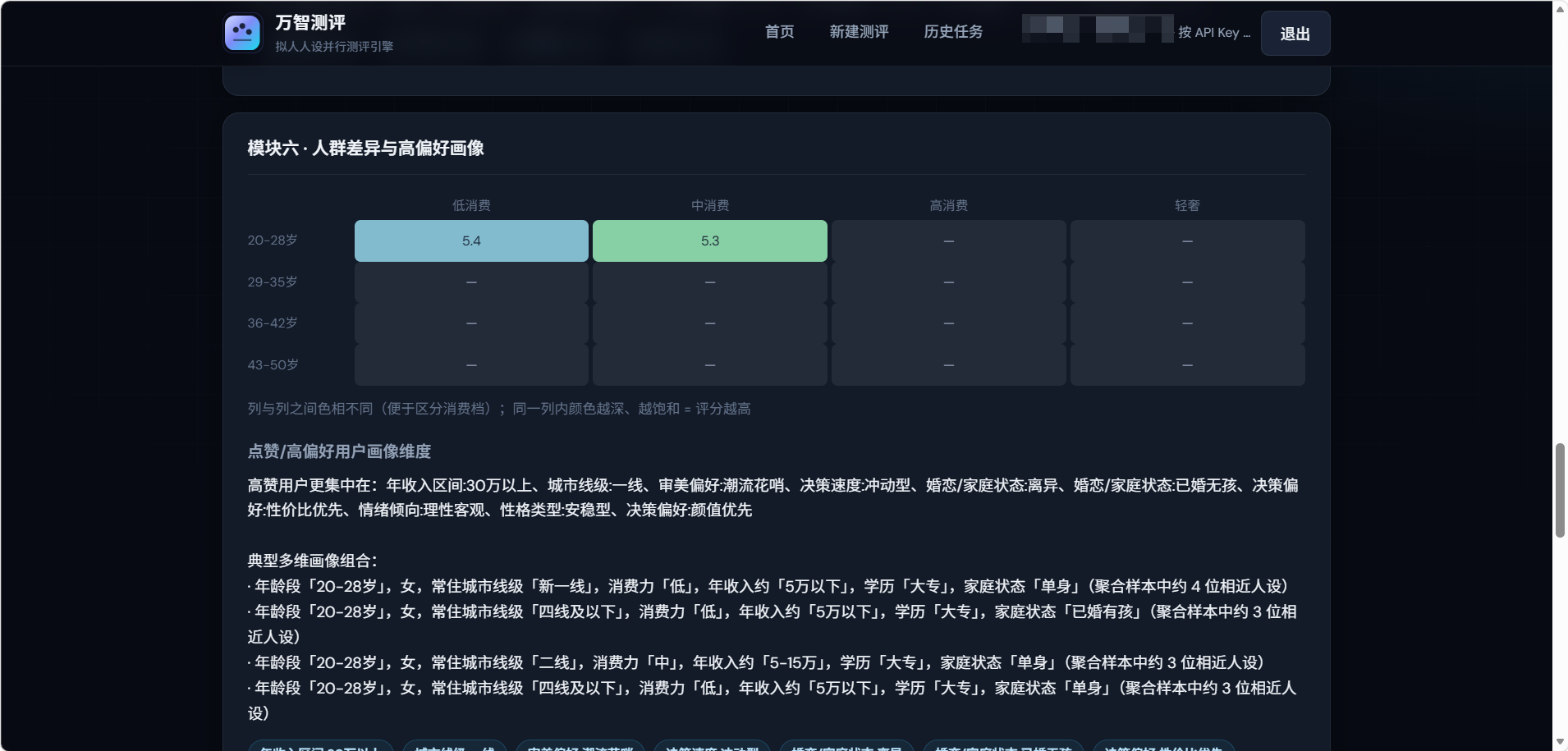
真正让我印象深刻的不是总分,而是报告里的人群交叉分析。
第一个发现:超过一半的人想点踩。
情绪分布显示:正向 1.1%,中性 52.1%,负向 46.8%。点踩率 51.1%。
ChatGPT 不会告诉你这个数字——不是它不想,是它没有。它只能给一个全局判断:"争议性较大。"但"较大"是多大?10%?30%?对投放决策来说,"较大"毫无价值。万智直接给了精确占比。
转化漏斗更残酷:立即咨询 5.3%,先继续了解 38.3%,无感不行动 56.4%。超过一半的人对你精心打磨的文案毫无反应。这不是"文案不好",而是"文案只对 5% 的人说了他们想听的话"。
第二个发现:离婚人群分享率 25%,是其他人群的 10 倍。
这个洞察完全反直觉。经历过重大人生变动的人,对"再不改变就要被淘汰"的叙事有一种特殊的共鸣。他们会转发——不是给文案点赞,是说"你看看这个"。这种"负面传播"在传统评测里几乎无法捕捉,只有在多智能体碰撞中才会浮出水面。
第三个发现:年收入 30 万以上的人评分最高(6.25),正向率 33.3%。
我们的直觉是:高收入人群对焦虑营销应该免疫。数据打脸了。恰恰是收入最高的一群人,对"被淘汰"的恐惧最深——因为他们拥有的东西最多,失去的成本最大。
这三个发现有一个共同点:它们都不是"一个聪明人坐在办公室里"能想出来的。它们来自大量异质个体的并行反馈,来自统计分布里的异常值。
五、你也可以试试
如果你最近也在准备投放素材,可以拿万智测评跑一遍,再对照你自己或团队的直觉判断。欢迎进群,我们一起来探讨一下这些产品。
建议尝试的测评任务:
- 上传你准备投放的文案或海报,看"转化引导"和"可信度"之间有没有出现剪刀差
- 重点关注"点踩率"和"无感率"——这两个数字比"好评率"更能预判投放风险
- 看人群交叉分析里有没有异常值,比如某个年龄段或某类人群的反馈明显偏离整体
测评不是替代真人测试,而是在"大规模、低成本、前置化"维度上填补空白。它能帮你在正式投放前,快速筛掉有明显人群偏差的素材,把有限的预算集中在经过验证的方向上。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)