人工智能课程设计—新闻文本分类
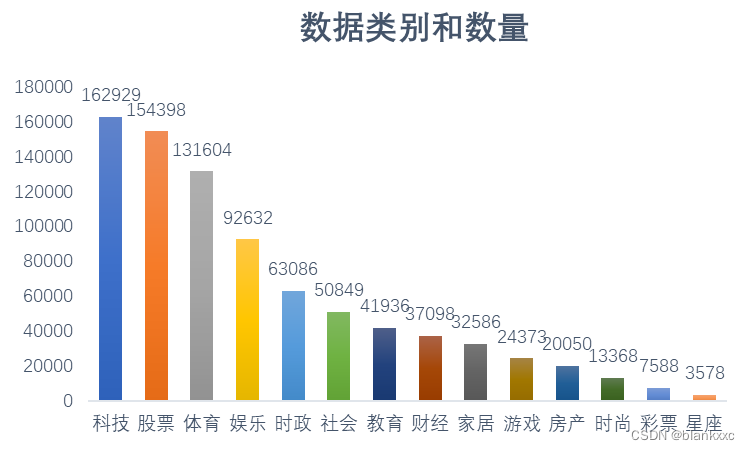
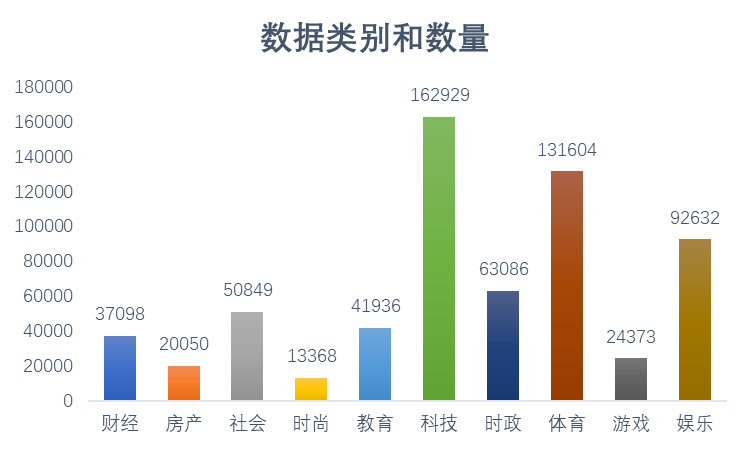
本文的数据是来自THUCTC(THU Chinese Text Classification),它是由清华大学自然语言处理实验室推出的中文文本分类工具包,能够自动高效地实现用户自定义的文本分类语料的训练、评测、分类功能。它的大小为1.56GB,为14个分类,一共有836075个数据(一个数据为一个txt文件),其中类别对应的数据量可见下图。通过上述的对比,我们可以发现在10中分类模型中,基于卷积神
需要完整代码和论文私信我
文件夹内容
以下是报告完整内容:
1、数据准备
1.1数据介绍
本文的数据是来自THUCTC(THU Chinese Text Classification),它是由清华大学自然语言处理实验室推出的中文文本分类工具包,能够自动高效地实现用户自定义的文本分类语料的训练、评测、分类功能。它的大小为1.56GB,为14个分类,一共有836075个数据(一个数据为一个txt文件),其中类别对应的数据量可见下图。
1.2数据详情
数据集的目录结构可见如下图。

一个数据为一个txt文件,里边拥有大量的中文文本数据,具体可见下图。猜测应该为新闻相关的语料数据。

从数据详情上大体看,数据不需要做任何数据清洗工作,数据比较干净和数据结构也比较完整。
2数据预处理
2.1数据选择
我们可以看到该数据集的数据量非常庞大,并且一个数据对象为一个txt文件的格式,有80多万个数据对象,一般的笔记本电脑会吃不消,所以我们需要从中提取部分数据出来进行处理和模型训练。类别数目取整,我们选择14个类别中的10个类别数据进行使用,做一个10分类的文本分类任务,对应的10个类别和原始数据量可见下图。

对于上述类别的数据,每个类别我们选择前10000条数据出来,5000条作为训练数据5000条作为测试数据。
2.2去除停用词
判断和去除停用词,主要是对原数据和停用词表中的停用词一一对比进行判断,代码快可见如下。
2、分词
2.1jieba分词
我们首先使用已经封装好了的jieba库对其中的一个数据集进行分词,主要去除了专有名词、人名等无用名词,留下仅有名词的干净文本,查看效果,例如我们对以下文本数据进行分词,文本数据初始详情可见如下。

使用jieba分词对文本数据进行切分(包括了上述提到的去除停用词的步骤),代码可见如下。

分词结果可见下图。我们逐个词去分析,发现分词还是挺合理的,对于每个单词都可以根据他们在句中的意思划分。

2.2正向最大匹配法
我们首先使用正向最大匹配法对上述的文本数据进行切分,代码可见如下。

具体结果可见如下。我们可以看到该方法的分词结果并不好,许多的数字数据都被拆分成一个一个的单位,效果并不好。

2.3逆向最大匹配法
我们此处使用逆向最大匹配法进行分词,代码可见如下图。

得到的分词效果可见如下图。我们可以发现分词的效果并不好,有些词都分错了,例如英文单词“WIND”,被拆开了。该方法的分词结果与上述的正向最大匹配法类似,效果与jieba分词相比,都并不好。
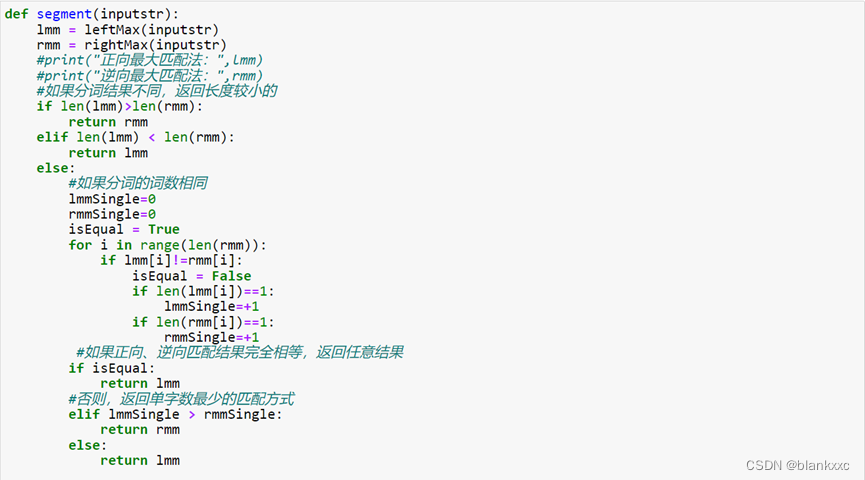
2.4双向最大匹配法
最后一个是双向最大匹配法,该方法的代码可见如下图。
该方法得到的分词结果可见下图。似乎和上述的两种匹配方法的结果大差不差,效果都并不好,相对而言,都比jieba分词差一些。

与jieba分词对比,个人觉得上述的三种匹配方法得到的分词效果都要逊色一些,所以我们后续使用到的数据,都是使用jieba分词进行处理。
使用jieba分词对全部文本数据进行分词完毕后,我们对全部数据进行保存在一个txt文件中。

主要分为两个txt文件,一个是训练集txt文件,一个是测试集txt文件。保存的结果可见下图。其中,该txt文件中一行的数据代表着之前的一个文本数据对象,即此处得到的训练集数据和测试集数据均有50000行,原因是一个类别的训练/测试集数据均有5000个数据对象,一共有10个类别,即可10*5000=50000行数据。

3、特征提取
3.1TF-IDF
我们首先对每个类别的全部数据进行特征提取,提取前1000个关键词,提取的方法主要是对关键词出现的次数进行统计,然后排序即可得到关键词出现频率最多的前1000个关键词了,词频统计可见下图。
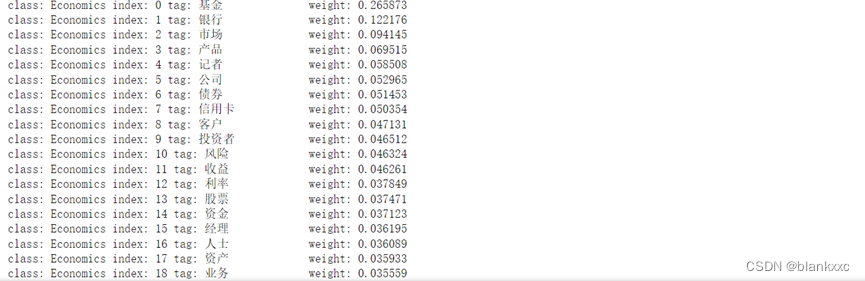
我们使用jieba内置的TF/IDF方法(jieba.analyse)进行加权,提取初步的特征。这里我们只对前1000个词频数最高的分词做处理

初步得到的权重值可见下图的输出列表。
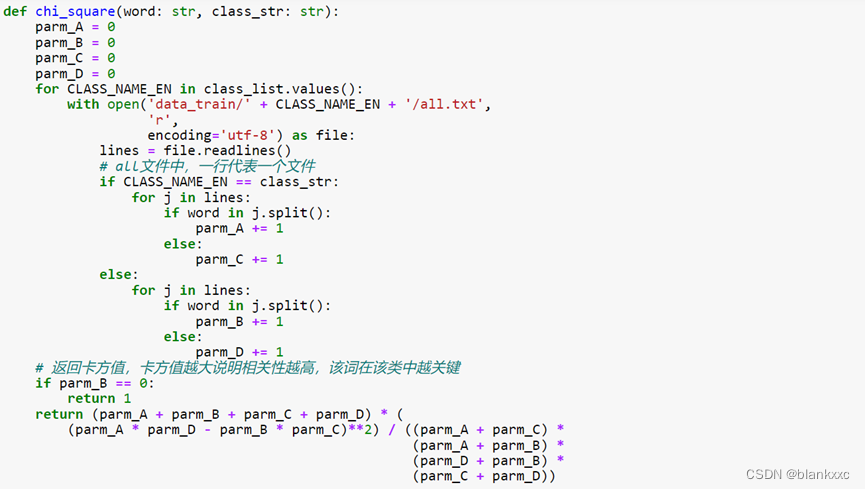
3.2TF-IDF+卡方
我们将词频统计完后的词频数作为当前权重,与卡方检验值相乘得到综合权值,对于得到综合权重的关键词,只选择前500个关键词。
我们使用卡方检验的方法计算卡方值,与上述的初步权重进行乘积,得到综合权重,可见下图。
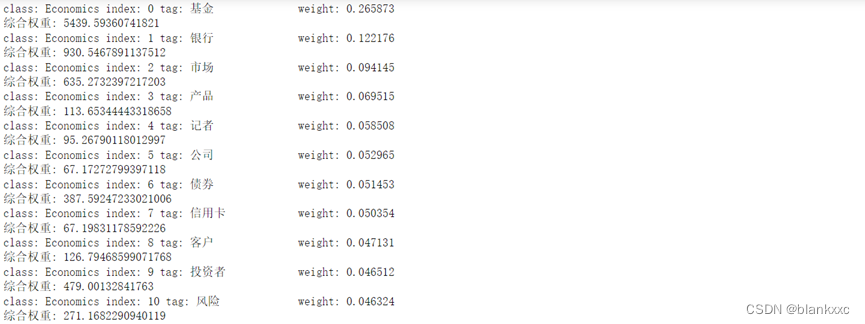
得到的综合权重值可见下图,即每个关键词的下一行,weight是初始计算权重,与上述计算的权重是一致的,综合权重=卡方值*初始权重。
得到的词向量的特征可见下图

特征维度可见下图。训练集的特征维度为50000*3685,其中3685指的是从上述提取得到的每个类别前500个单词中不重复的分词作为特征关键词,一共有3685个,部分的关键词可见下图。


加入了卡方计算的权重,会比单独的TF-IDF计算的权重考虑的更加全面,所以后续的模型训练都使用计算了综合权重的特征向量数据。
4、文本分类
对于模型分类效果的评估指标有许多种,例如准确率、精确率、召回率、f1score和AUC等。本文使用的是准确率、召回率和F1-score三个指标。我们可以查看下图的混淆矩阵。T:真,F:假,P:阳性,N:阴性;TP:真阳性 TN:真阴性 FP:假阳性 FN:假阴性。
精确率Precision=TPTP+FP
召回率Recall=TPTP+FN
F1-score F1=21Precision+1Recall
4.1感知机(Per)
模型代码可见下图

模型训练预测结果可见下图



4.2贝叶斯(Byes)
模型代码可见下图。

模型训练测试结果可见下图。



4.3支持向量机(SVM)
模型代码可见下图

模型训练测试结果可见下图。



4.4逻辑回归(LGR)
模型代码可见下图。

模型训练测试结果可见下图。



4.5 K近邻(KNN)
模型代码可见下图

模型训练测试结果可见下图。



4.6决策树(Tree)
模型代码可见下图

模型训练测试结果可见下图。



4.7自适应提升树(Adaboost)
模型代码可见下图

模型训练测试结果可见下图。



4.8随机森林(RF)
模型的代码可见下图

模型的训练测试结果可见下图。



4.9梯度提升树(GBDT)
模型代码可见下图

模型的训练测试结果可见下图。



4.10卷积神经网络(CNN)
上述9种方法都是常用的机器学习分类模型,在此处我们使用深度学习中的卷积神经网络,构建一个简单的卷积神经网络模型进行训练测试。此处我们使用三层的卷积神经网络,网络结构使用tensorflow框架中的conv1d层实现。代码可见下图


我们设置模型训练迭代次数位1000次,学习率为0.00004,模型训练代码可见下图。当我们训练到1000次的时候,模型的训练集准确率达到了0.9609,非常高了。

我们直接查看模型的测试结果,与上一致,使用50%的数据对模型进行测试,即5000条数据。测试结果可见下图。


我们可以看到卷积神经网络训练1000次得到的测试结果要比上述全部的模型结果都要好,模型精确率、召回率和f1-score都达到0.95以上,上述9个模型3个指标有一个达到0.9的都没有。

5、总结
通过上述的对比,我们可以发现在10中分类模型中,基于卷积神经网络的三个模型评估指标都是最高的,对比可见下图所示。本文使用的数据量还是非常多的,在大量数据面前,卷积神经网络模型的优势会比普通的机器学习模型要好,并且本文中普通的机器学习模型未进行调参处理,都是属于接口默认的参数,所以效果不太好还是可以理解的。
所以我们使用该模型对某一段文本数据进行测试,测试内容和结果可见下图。我们对该文本内容进行预测。而我们随意输入一段文字,例如“考研还是实习呢”,其实这个类别真的不好分,可是模型将它归类为教育的类别,可能是出现了“考研”这个关键字吧。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)