机器学习基础——主成分分析
主成分分析主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法。对于正交属性空间中的样本点,如果用一个超平面对所有的样本进行恰当的表达最近重构性:样本点到这个超平面的距离都足够近最大可分性:样本点在这个超平面上的投影能尽可能分开。假定数据样本进行中心化,即∑ixi=0\sum_i x_i=0∑ixi=0,在假定投影百年换后得到的新的...
主成分分析
主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法。
对于正交属性空间中的样本点,如果用一个超平面对所有的样本进行恰当的表达
- 最近重构性:样本点到这个超平面的距离都足够近
- 最大可分性:样本点在这个超平面上的投影能尽可能分开。
假定数据样本进行中心化,即∑ixi=0\sum_i x_i=0∑ixi=0,在假定投影百年换后得到的新的坐标为{ω1,ω2,⋯ ,ωd}\{\omega_1,\omega_2,\cdots, \omega_d\}{ω1,ω2,⋯,ωd},其中wiw_iwi是标准正交基,∣∣wi∣∣2=1,ωiTωj=0(i≠j)||w_i||_2=1,\omega_i^T\omega_j=0(i\ne j)∣∣wi∣∣2=1,ωiTωj=0(i=j),若丢弃新坐标系中的部分坐标,即将维度降到d′<dd^{'} < dd′<d,则样本点xix_ixi在低维坐标系中的投影是zi=(zi1,zi2,⋯ ,zid′)z_i=(z_{i1},z_{i2},\cdots,z_{id^{'}})zi=(zi1,zi2,⋯,zid′),其中zij=ωjTxiz_{ij}=\omega^T_jx_izij=ωjTxi是xix_ixi在低维坐标系下第j维的坐标,若基于ziz_izi来重构xix_ixi,就会得到x^i=∑j=1d′zijwj\hat{x}_i = \sum_{j=1}^{d^{'}} z_{ij}w_jx^i=∑j=1d′zijwj
考虑整个训练集,原样本点xix_ixi是基于投影重构的样本点x^i\hat{x}_ix^i之间的距离为
∑i=1m∣∣∑j=1d′zijω−xi∣∣22=∑i=1mziTzi−2∑i=1mziTWTxi+const∝−tr(WT(∑i=1mxixiT)W) \sum_{i=1}^m ||\sum_{j=1}^{d^{'}} z_{ij}\omega -x_i||_2^2 = \sum_{i=1}^m z_i^Tz_i-2\sum_{i=1}^m z_i^TW^Tx_i+const \\ \varpropto -tr(W^T(\sum_{i=1}^m x_ix_i^T)W) i=1∑m∣∣j=1∑d′zijω−xi∣∣22=i=1∑mziTzi−2i=1∑mziTWTxi+const∝−tr(WT(i=1∑mxixiT)W)
已知WTW=I,zi=WTxiW^TW=I,z_i = W^Tx_iWTW=I,zi=WTxi
∑i=1m∣∣∑j=1d′zijwj−xi∣∣22=∑i=1m∣∣Wzi−xi∣∣22=∑i=1m(Wzi−xi)T(Wzi−xi)=∑i=1m(ziTWTWzi−ziTWTxi−xiTWzi+xiTxi)=∑i=1m(ziTzi−2ziTWTxi+xiTxi)=∑i=1mziTzi−2∑i=1mziTWTxi+∑i=1mxiTxi=∑i=1mziTzi−2∑i=1mziTzi+const=−∑i=1mziTzi+const=−∑i=1mtr(ziziT)+const=−tr(∑i=1mWTxixiTW)+const=−tr(WT(∑i=1mxixiT)W)+const \begin{aligned} \sum_{i=1}^m ||\sum_{j=1}^{d^{'}}z_{ij}w_j-x_i||_2^2 & = \sum_{i=1}^m ||Wz_i-x_i||^2_2 \\ & = \sum_{i=1}^m(Wz_i-x_i)^T(Wz_i-x_i) \\ &= \sum_{i=1}^m (z_i^TW^TWz_i-z_i^TW^Tx_i-x_i^TWz_i+x_i^Tx_i)\\ &= \sum_{i=1}^m (z_i^Tz_i-2z_i^TW^Tx_i+x_i^Tx_i)\\ &=\sum_{i=1}^m z_i^Tz_i - 2\sum_{i=1}^m z_i^TW^Tx_i + \sum_{i=1}^m x_i^Tx_i\\ &= \sum_{i=1}^m z_i^Tz_i -2\sum_{i=1}^m z_i^Tz_i + const \\ &= -\sum_{i=1}^m z_i^Tz_i + const \\ &= -\sum_{i=1}^m tr(z_iz_i^T) +const\\ &= -tr(\sum_{i=1}^m W^Tx_ix_i^TW) + const \\ &= -tr(W^T(\sum_{i=1}^m x_ix_i^T)W) + const \end{aligned} i=1∑m∣∣j=1∑d′zijwj−xi∣∣22=i=1∑m∣∣Wzi−xi∣∣22=i=1∑m(Wzi−xi)T(Wzi−xi)=i=1∑m(ziTWTWzi−ziTWTxi−xiTWzi+xiTxi)=i=1∑m(ziTzi−2ziTWTxi+xiTxi)=i=1∑mziTzi−2i=1∑mziTWTxi+i=1∑mxiTxi=i=1∑mziTzi−2i=1∑mziTzi+const=−i=1∑mziTzi+const=−i=1∑mtr(ziziT)+const=−tr(i=1∑mWTxixiTW)+const=−tr(WT(i=1∑mxixiT)W)+const
根据最近重构性,上式应该被最小化,考虑到wjw_jwj是标准正交基∑ixixiT\sum_{i}x_ix_i^T∑ixixiT是协方差矩阵
minW−tr(WTXXTW)s.t. WTW=1 \underset{W}{\min} -tr(W^TXX^TW) \\ s.t. \ W^TW =1 Wmin−tr(WTXXTW)s.t. WTW=1
这就是主成分分析的优化目标
从最大可分性出发,得到主成分分析的另外一种解释,样本点xix_ixi在新空间中超平面上的投影是WTxiW^Tx_iWTxi,若所有样本点的投影能尽可能分开,应该使投影后样本点的方差最大化。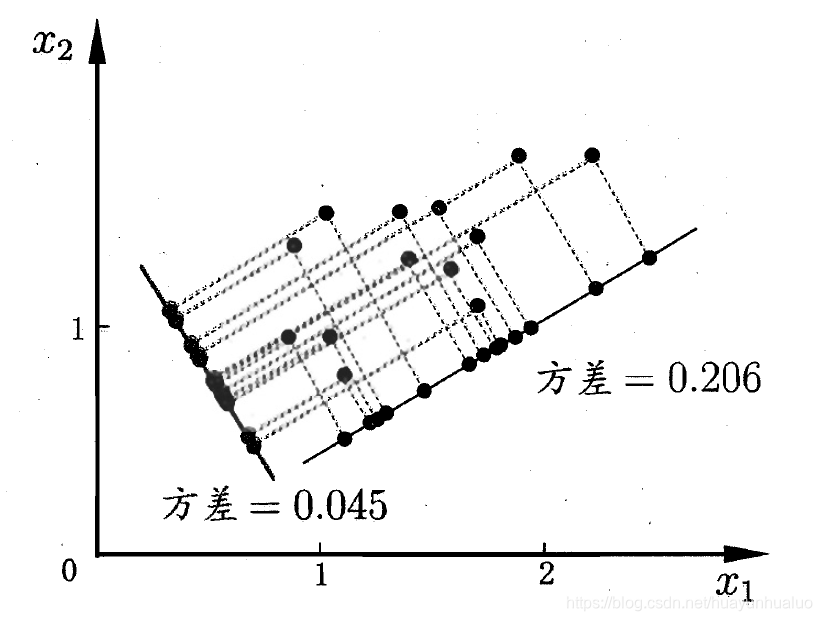
于是优化目标可写为:
maxW tr(WTXXTW)s.t. WTW=I \underset{W}{\max} \ tr (W^TXX^TW) \\ s.t. \ W^TW=I Wmax tr(WTXXTW)s.t. WTW=I
使用拉格朗日乘子法可得
XXTW=λW XX^TW = \lambda W XXTW=λW
推导
X=(x1,x2,⋯ ,xm)∈Rd×m,W=(w1,w2,⋯ ,wd′)∈Rd×d′,I∈Rd′×d′X=(x_1,x_2,\cdots,x_m)\in \mathbb{R}^{d\times m},W=(w_1,w_2,\cdots,w_{d^{'}})\in \mathbb{R}^{d\times d^{'}},I\in \mathbb{R}^{d^{'}\times d^{'}}X=(x1,x2,⋯,xm)∈Rd×m,W=(w1,w2,⋯,wd′)∈Rd×d′,I∈Rd′×d′为单位矩阵,对于带矩阵约束的优化问题,优化目标的拉格朗日函数为
L(W,Θ)=−tr(WTXXTW)+⟨Θ,WTW−I⟩=−tr(WTXXTW)+tr(ΘT(WTW−I)) \begin{aligned} L(W,\Theta) &= -tr(W^TXX^TW) + \langle \Theta,W^TW-I \rangle \\ &= -tr(W^TXX^TW) + tr(\Theta^T(W^TW-I)) \end{aligned} L(W,Θ)=−tr(WTXXTW)+⟨Θ,WTW−I⟩=−tr(WTXXTW)+tr(ΘT(WTW−I))
其中,Θ∈Rd′×d′\Theta\in \mathbb{R}^{d^{'}\times d^{'}}Θ∈Rd′×d′为拉格朗日乘子矩阵,其维度恒等于约束条件的维度,且其中的每个元素均为未知的拉格朗日乘子。若此时只考虑约束∣∣wi∣∣2=1(i=1,2,⋯ ,d′)||w_i||_2 = 1(i=1,2,\cdots,d^{'})∣∣wi∣∣2=1(i=1,2,⋯,d′),则拉格朗日乘子矩阵Θ\ThetaΘ此时为对角矩阵,令新的拉格朗日乘子矩阵为Λ=diag(λ1,λ2,⋯ ,λd′)∈Rd′×d′\Lambda=diag(\lambda_1,\lambda_2,\cdots,\lambda_{d^{'}})\in \mathbb{R}^{d^{'}\times d^{'}}Λ=diag(λ1,λ2,⋯,λd′)∈Rd′×d′,新的拉格朗日函数为
L(W,Λ)=−tr(WTXXTW)+tr(ΛT(WTW−I)) L(W,\Lambda) = -tr(W^TXX^TW) + tr(\Lambda^T(W^TW-I)) L(W,Λ)=−tr(WTXXTW)+tr(ΛT(WTW−I))
对拉格朗日函数关于WWW求导可得
∂L(W,Λ)∂W=∂∂W[−tr(WTXXTW)+tr(ΛT(WTW−I))]=−∂∂Wtr(WTXXTW)+∂∂Wtr(ΛT(WTW−I)) \begin{aligned} \frac{\partial L(W,\Lambda)}{\partial W} & = \frac{\partial}{\partial W}[-tr(W^TXX^TW) + tr(\Lambda^T(W^TW-I))] \\ &= -\frac{\partial}{\partial W}tr(W^TXX^TW) + \frac{\partial}{\partial W}tr(\Lambda^T(W^TW-I)) \end{aligned} ∂W∂L(W,Λ)=∂W∂[−tr(WTXXTW)+tr(ΛT(WTW−I))]=−∂W∂tr(WTXXTW)+∂W∂tr(ΛT(WTW−I))
由矩阵微分公式∂∂Xtr(XTBX)=BX+BTX,∂∂Xtr(BXTX)=XBT+XB\frac{\partial}{\partial X}tr(X^TBX) = BX+B^TX,\frac{\partial}{\partial X} tr(BX^TX) = XB^T+XB∂X∂tr(XTBX)=BX+BTX,∂X∂tr(BXTX)=XBT+XB
∂L(W,Λ)∂W=−2XXTW+WΛ+WΛT=−2XXTW+W(Λ+ΛT)=−2XXTW+2WΛ \begin{aligned} \frac{\partial L(W,\Lambda)}{\partial W} &= -2XX^TW +W\Lambda + W\Lambda^T \\ &=-2XX^TW+W(\Lambda + \Lambda^T) \\ &= -2XX^TW + 2W\Lambda \end{aligned} ∂W∂L(W,Λ)=−2XXTW+WΛ+WΛT=−2XXTW+W(Λ+ΛT)=−2XXTW+2WΛ
令∂L(W,Λ)∂W=0\frac{\partial L(W,\Lambda)}{\partial W}=0∂W∂L(W,Λ)=0
−2XXTW+2WΛ=0XXTW=WΛ -2XX^TW +2W\Lambda = 0\\ XX^TW = W\Lambda −2XXTW+2WΛ=0XXTW=WΛ
只需要对协方差矩阵XXTXX^TXXT进行特征值分解,将求得的特征值排序λ1≥λ2⋯≥λd\lambda_1 \ge \lambda_2 \cdots \ge \lambda_dλ1≥λ2⋯≥λd,再取前d′d^{'}d′个特征值对应的特征值对应的特征向量构成W=(ω1,ω2⋯ ,ωd′)W=(\omega_1,\omega_2\cdots, \omega_{d^{'}})W=(ω1,ω2⋯,ωd′)
算法步骤:
- 输入:样本集D={x1,x2,⋯ ,xm}D=\{x_1,x_2,\cdots,x_m\}D={x1,x2,⋯,xm},低维空间维数d′d^{'}d′
- 过程:
- 对所有样本进行中心化xi←xi−1m∑i=1mxix_i \leftarrow x_i-\frac{1}{m}\sum_{i=1}^m x_ixi←xi−m1∑i=1mxi
- 计算样本的协方差矩阵XXTXX^TXXT
- 对协方差矩阵XXTXX^TXXT做特征值分解
- 取最大的d′d^{'}d′个特征值所对应的特征向量w1,w2,⋯ ,wd′w_1,w_2,\cdots,w_{d^{'}}w1,w2,⋯,wd′
- 输出:投影矩阵
降维后的低维空间的维数d′d^{'}d′通常是由用户先指定,或通过在d′d^{'}d′值不同的低维空间中对kkk近邻分类器进行交叉验证来选择较好的d′d^{'}d′值。
∑i=1d′λi∑i=1dλi≥t \frac{\sum_{i=1}^{d^{'}}\lambda_i}{\sum_{i=1}^d \lambda_i} \ge t ∑i=1dλi∑i=1d′λi≥t
PCA仅需保留W与样本的均值向量即可通过简单的向量减法和矩阵-向量乘法将新的样本投影到低维空间中,因为对应于最小的d−d′d-d^{'}d−d′个特征值的特征向量被舍弃了,这就是降维导致的结果。但是舍弃这部分往往是必要的:
- 舍弃这部分信息之后能使样本的采样密度增大
- 当数据收到噪声的影响时,最小的特征值所对应的特征向量往往与噪声有关,将它们舍弃能在一定程度上起到去噪的效果。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)