Cursor+Playwright MCP实现UI全自动化,告别繁琐元素定位!
摘要:本文探讨了利用Cursor和PlaywrightMCP实现UI自动化测试的创新方法。通过将AI编程助手与浏览器自动化技术结合,解决了传统UI自动化测试中元素定位繁琐、维护成本高等痛点。文章详细介绍了项目架构设计、AI使用技巧(包括精准提问和编写.mdc规则文档),以及如何实现自然语言测试用例到自动化脚本的转换。最终实现了测试人员只需输入手工测试步骤,AI即可自动生成完整测试代码的智能化流程,
UI自动化一直以来深受测试人员诟病:
1.页面元素太多太杂,元素定位耗时耗心力
2.很多元素无惟一识别属性,元素定位依赖页面结构,页面结构调整,自动化脚本维护成本高
3.UI自动化不稳定
......
近期各类LLM、MCP现世后,确实极大解放了研发人员双手,而Cursor+Playwright MCP也彻底让传统UI自动化告别了繁琐的元素定位。然而想要有效的利用AI,在项目中实现手工测试用例一键转自动化,还是需要一些小技巧的。
下面展开说说我最近结合Cursor和Playwright MCP实现UI全自动化的一些技巧思路
一、定义与核心概念
Cursor是一个类VSCode的智能编程IDE,集成了GPT-5、Claude 4.0等先进大语言模型(LLM),本质上是一个内置AI助手的VSCode。它不仅支持自然语言编程,还提供从代码编写、调试、重构到部署的智能辅助;
Playwright MCP 是一个基于 Model Context Protocol (MCP) 的浏览器自动化服务器,它将 Playwright 的浏览器自动化能力与 MCP 协议相结合,使大型语言模型(LLM)能够通过结构化命令控制网页浏览器。这一技术由微软推出,主要依赖于浏览器的可访问性树进行工作,无需依赖视觉模型;
二、项目想要达成的效果
UI自动化测试项目基于python+playwright+pytest,结构如下:
auto_demo/
config/
__init__.py
global_conf.yaml
settings.py
locators/ # 元素定位,按页面划分
__init__.py
customer_manage_locators.py
login_locators.py
pages/ # 页面操作层,封装具体页面操作方法
__init__.py
customer_manage_page.py
login_page.py
testcases/ # 测试用例层
__init__.py
test_cst_assign.py
test_cst_recycle.py
test_login.py
utils/ # 底层方法层
__init__.py
assert_util.py
driver_manager.py
global_conf_util.py
log_util.py
read_yaml_util.py
screenshot_util.py
logs/
screenshots/
reports/
conftest.py
run.py因此,当我需要新增测试用例时,只需要做:
(1)testcases/下写具体测试用例
(2)pages/下写相关页面操作,如登录页面的登录
(3)locator/下写相关页面元素定位,如登录页面的登录按钮
(4)将日志输出到logs/下,截图输出到screenshots/下
我希望在Cursor chat框输入具体的测试用例操作步骤(用自然语言),让AI帮我把代码更新到相应文件中,最后我直接执行testcases/下的测试用例就可以了,全程无需手工编写代码
三、有效利用AI实战小技巧
这里需要提前配置好Playwright MCP,配置步骤看------------>
cursor+playwright mcp实战落地-CSDN博客
如何让AI精准按照我们的需求去写代码,而不是瞎写乱改,2点小技巧分享给大家:
1、精准提问,避免”乱写“
- 需求对齐:先确认后执行
1. 强制复述:
“请先复述我的需求,并说明关键步骤和输出格式。”
2. 暴露盲区:
“这个需求中哪些地方容易歧义?请列出你的疑问。”
3. 补充背景:
“[背景] 这是Python 3.8的微服务模块,要求兼容旧版API。
[任务] 重写以下函数的错误处理逻辑:”
- 任务拆解:一次只做一件事
# 实例:需要AI帮我完成【分配】自动化任务
1.访问目标网址,如遇登录问题,用已知账户密码登录
2.切换到指定项目(global_conf.yaml)
3.切换到跟进中客户-正常跟进客户tab页面
4.找到列表中第一个客户,点击【分配】
5.在打开的客户分配会话框,将客户分配给第一个顾问
- 范围锁定
1.精准定位
“修改 `config_loader.py` 中第88行的 `_parse_url()` 方法(注意是私有方法)”
2.声明禁区
“`main()` 函数的参数结构不允许变动”
3.影响预判
“如果重命名 `Database.connect()` 方法,请列出所有调用它的文件路径”
2、利用Cursor-rules
写好.mdc才能让AI按照预期的方式去生成代码,例如代码风格、输出方式、特定的一些要求等等......我的项目写了下面3个mdc文件:
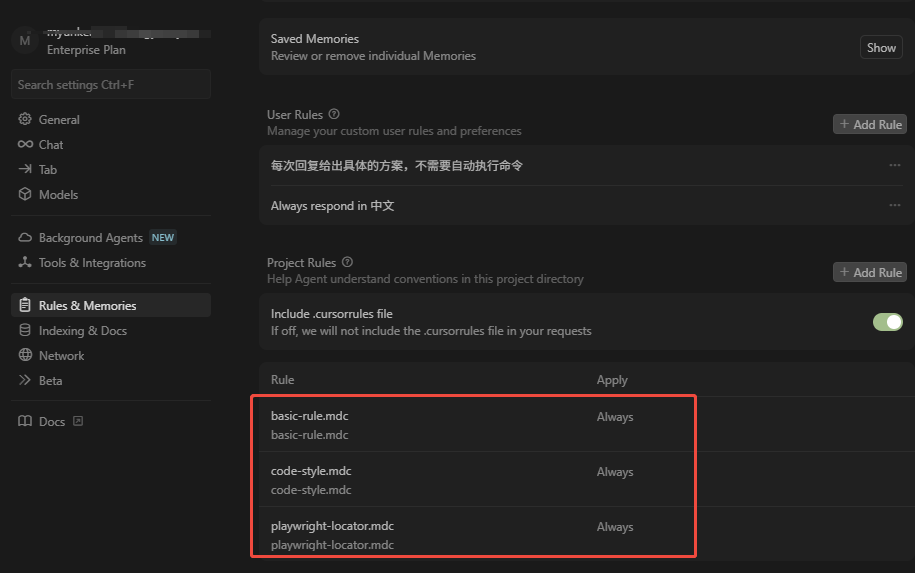
发现LLM经常写很多的try,基本上一行代码就加一个try,太繁琐了......
---
alwaysApply: true
---
# 代码规范指南
## 核心原则
### 1. 遵循《代码整洁之道》
- **有意义的命名**:使用能够表达意图的变量名、函数名和类名
- **函数应该短小**:一个函数只做一件事,保持函数简洁
- **注释应该解释为什么,而不是做什么**:代码本身应该是自解释的
- **保持一致性**:在整个项目中使用一致的编码风格
### 2. 简洁性原则
- 优先编写清晰、简洁的代码
- 避免过度设计和不必要的复杂性
- 删除无用的代码和注释
- 使用 Python 的内置功能和标准库
### 3. 错误处理策略
- **仅在必要时使用 try...except**:
- 处理预期可能发生的异常
- 网络请求、文件操作、外部 API 调用
- 用户输入验证
- **避免过度的错误处理**:
- 不要为每步操作都添加 try...except
- 让程序在遇到真正的错误时快速失败
- 相信 Python 的异常机制
发现LLM经常天马行空,瞎改我的代码,改完之后,核心模块都不通了
---
alwaysApply: true
---
# 基础开发规则
## 任务实现方案说明
在执行本任务前,需详细说明实现方案,包括以下内容:
1. **实现方案描述**
- 说明本次修改或开发的目标、核心思路和主要技术路线。
- 明确涉及的MCP(如有),并说明其调用方式和作用。
2. **流程图(如适用)**
- 推荐使用简单的文本流程图或工具绘制流程图,帮助理解整体流程。
- 流程图应覆盖主要步骤和关键分支。
3. **实现步骤拆解**
- 将整体任务拆解为若干具体的实现步骤,每一步应简明扼要,便于跟踪和执行。
4. **to_do_list**
- 以 checklist 形式列出所有待办事项,便于开发和自查。
---
### 示例模板
#### 1. 实现方案描述
- 目标:简要描述本次任务的目标。
- 技术路线:说明采用的主要技术、库、接口等。
- 相关MCP调用:列出涉及的MCP及其作用。
#### 2. 流程图(可选)
## 代码修改原则
1. **最小改动原则**
- 在解决问题时,优先考虑最小化修改
- 避免改动核心文件和核心逻辑
- 如必须修改核心部分,需先进行充分讨论
2. **任务处理流程**
- 接收任务后先全面理解需求
- 分析任务并拆解为具体步骤
- 明确需要修改的文件和范围
- 确认修改方案后再实施
3. **代码影响评估**
- 修改前评估对现有功能的影响
- 确保修改不会引入新的问题
- 保持代码的向后兼容性
UI自动化特有rules:期望按照预期元素定位方式去定位:
---
alwaysApply: true
---
# UI自动化元素定位
## 实现方案描述
- 目标:通过Playwright MCP(页面访问树)自动分析网页结构,智能定位页面元素,并将定位信息自动更新到`locators`模块,提升元素定位的准确性和维护效率。
- 技术路线:利用Playwright的MCP(Main Control Process)能力,读取页面访问树(Accessibility Tree/DOM Tree),结合Playwright的多种定位API(如get_by_role、get_by_label等),自动生成最优定位表达式,并写入到对应的`locators` Python 类中。
- 相关MCP调用:通过Playwright的MCP接口获取页面结构信息,分析节点属性(role、label、placeholder、text、alt、title等),优先级依次尝试,自动选择最优定位方式。
## Playwright 元素定位方法优先级规则
在使用 Playwright 进行元素定位时,请按照以下优先级顺序选择定位方法:
## 优先级顺序(从高到低)
1. **get_by_role()** - 最优先
- 基于元素的语义角色定位,最符合用户交互方式
- 示例:`page.get_by_role('button', name='登录')`
- 示例:`page.get_by_role('textbox', name='用户名')`
2. **get_by_label()** - 第二优先
- 通过关联的 label 文本定位表单元素
- 示例:`page.get_by_label('密码')`
3. **get_by_placeholder()** - 第三优先
- 通过 placeholder 属性定位输入框
- 示例:`page.get_by_placeholder('请输入用户名')`
4. **get_by_text()** - 第四优先
- 通过可见文本内容定位元素
- 示例:`page.get_by_text('提交')`
5. **get_by_alt_text()** - 第五优先
- 通过图片的 alt 属性定位
- 示例:`page.get_by_alt_text('用户头像')`
6. **get_by_title()** - 第六优先
- 通过 title 属性定位元素
- 示例:`page.get_by_title('关闭窗口')`
7. **XPath** - 第七优先
- 当语义化定位方法无法使用时的备选方案
- 示例:`page.locator('//button[@class="login-btn"]')`
8. **CSS 选择器** - 最后选择
- 仅在其他方法都不适用时使用
- 示例:`page.locator('.login-button')`
### 使用原则
- 优先使用语义化的定位方法(1-6),这些方法更贴近用户的实际操作方式
- 避免过度依赖 XPath 和 CSS 选择器,因为它们容易因页面结构变化而失效
- 所有需要写入文件的元素定位,都应经过MCP Server测试验证,确保能够定位到
- 在编写测试代码时,始终从优先级最高的方法开始尝试
- 如果高优先级方法无法准确定位,再考虑使用低优先级方法
总结起来其实两种方式都是为了给大模型设置一些规则,让它明确我们的想法,才能按照预期去写代码,项目中比较推荐写.mdc;
四、项目成果
最终实现chat框输入手工测试用例步骤,LLM帮忙补充相应代码:
完成以下测试用例:
1.访问@【目标网址】 ,如遇登录问题,用已知账户密码登录
2.切换到指定项目(global_conf.yaml)
3.切换到跟进中客户-正常跟进客户tab页面
4.找到列表中第一个客户,点击【回收】
5.在打开的客户回收会话框,输入回收原因:回收-自动化测试
6.点【确定】完成客户回收
需要注意大部分方法已实现,目前只需要实现回收方法封装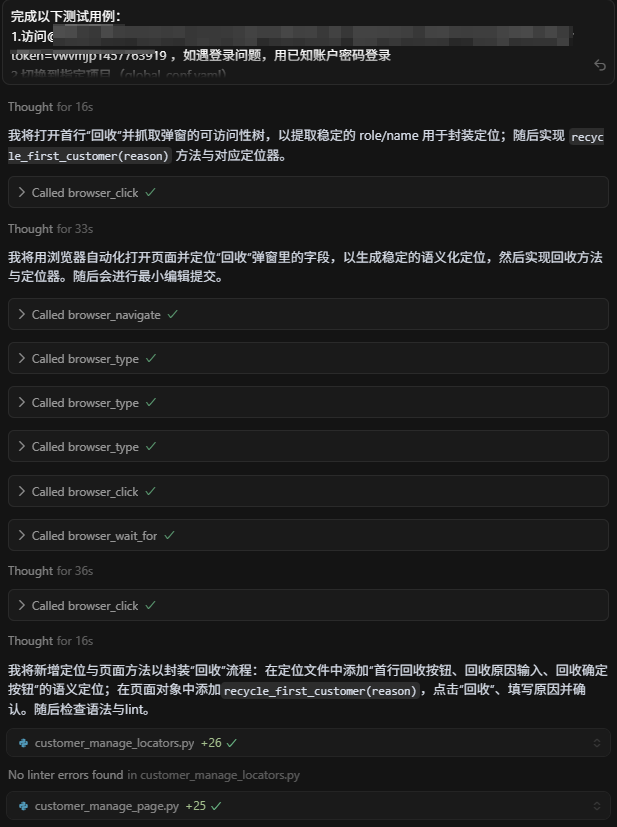


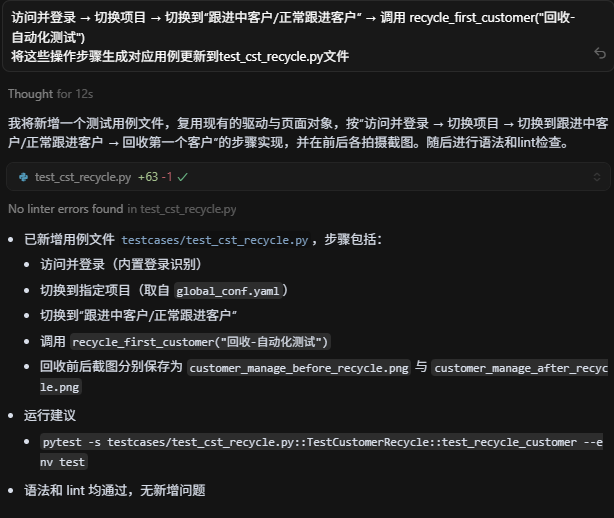
圆满收官!!!
进一步设想的话,可以在项目中新增一个目录写手工测试用例(如xlsx格式形式),直接读取表格一键生成UI自动化测试用例,实现0代码写UI自动化!!!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)