【资讯】当前不同用途的各类大模型进行总结(截至 2025 年 7 月)
📚前言
对当前不同用途的各类大模型进行总结,并给出不同领域推荐的模型。
📚deepseek对比分析(侧重国内大模型对比)
以下是针对当前主流大模型按应用领域进行的分类总结与推荐清单,涵盖通用基座、多模态、垂直行业、智能体与端侧部署等方向,基于模型性能、场景适配度及落地成本综合评估:
一、通用文本大模型:强语言理解与生成
适用于文本创作、编程辅助、逻辑推理等通用任务,推荐模型如下:
| 模型名称 | 核心优势 | 适用场景 | 部署要求 |
|---|---|---|---|
| DeepSeek-R1 | 128K长上下文,编程任务超越GPT-4.1 | 企业知识库问答、合同生成、代码助手 | 云端/端侧(轻量化版)310 |
| GLM-4.5-Air | 高性价比API(输入2元/M tokens) | 多轮对话、低成本客服系统 | 云端API |
| 腾讯混元系列 | 支持256K上下文,Excel操作/旅行规划能力强 | 办公自动化、长文档处理 | 端侧(手机/笔记本)7 |
💡 选型建议:企业级应用选DeepSeek-R1(兼顾性能与安全),轻量级任务选腾讯混元(端侧部署)。
二、多模态大模型:图文音视频融合理解
支持图像、视频、GUI界面等跨模态分析与生成:
| 模型名称 | 突破性能力 | 典型场景 | 开源/商用 |
|---|---|---|---|
| GLM-4.5V | 全场景视觉覆盖(图像/视频/GUI),空间感知误差<2% | 工业图纸解析、游戏策略反推、长视频分析 | 开源(106B参数)25 |
| GPT-5 | HealthBench医疗评测全球最高分(>32分) | 跨模态医疗诊断、生物图像分析 | 商用API |
| 通义Wan2.2 | 图生视频速度提升12倍 | 短视频自动生成、电影特效制作 | 商用API6 |
🔍 场景适配:GLM-4.5V性价比突出(开源且API成本低),医疗场景首选GPT-5或百川M2。
三、垂直行业大模型:领域知识深度优化
针对专业场景定制,解决行业痛点:
-
医疗健康 - Baichuan-M2
-
特点:强化中国诊疗指南,支持单卡RTX4090部署,HealthBench得分60.1(超越GPT-oss120b)
-
场景:门诊决策支持、电子病历分析、患者模拟训练9
-
-
隧道工程 - 先锋·隧道大模型
-
特点:基于1200亿条工程数据训练,断层预报精度>90%
-
场景:地质隐患实时探测、盾构参数自动调优16
-
-
办公自动化 - WPS AI 2.0 & 企业微信智能机器人
-
特点:Word/Excel/PPT全组件智能操作,集成DeepSeek-R1实现企业知识库问答
-
场景:合同审查、报表生成、跨系统流程调度10
-
四、轻量化端侧模型:低功耗设备部署
适用于手机、IoT设备等资源受限场景:
| 模型 | 参数量 | 关键特性 | 硬件要求 |
|---|---|---|---|
| 腾讯混元0.5B-7B | 0.5~7B | 256K上下文,支持快/慢思考模式 | 手机/平板/智能座舱7 |
| 百川-M2轻量化版 | 32B | 医疗问答token速度提升74.9% | RTX 4090单卡9 |
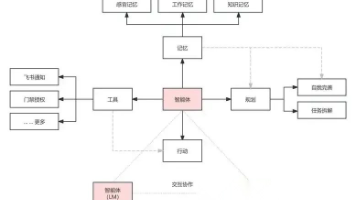
五、智能体(Agent)模型:自主任务规划
实现多工具调度与复杂决策:
-
腾讯“百宝箱”:支持工作流定制(如数据爬取→清洗→可视化)8
-
钉钉多智能体协作:同时调度10个专业AI完成跨系统任务(如差旅管理+合规审计)10
未来趋势与挑战
-
技术方向:多模态→3D空间建模(如灾难现场重建)、脑机接口融合3
-
风险警示:数据安全需硬件级防护(如华为可信AI芯片),避免生物特征伪造诈骗34
建议结合场景复杂度与预算灵活选型:高精度专业任务用垂直模型,多模态创意选GLM-4.5V,普惠级应用优先端侧部署。
📚copilot对比分析
大模型用途综述与领域推荐
你想要的,可能不是“最强模型”,而是“最合适的组合”:成本、效果、合规、中文能力、落地难度,哪个对你更重要?
快速对照表
| 用途/领域 | 推荐模型 | 亮点 | 何时优先选择 |
|---|---|---|---|
| 通用对话与综合推理 | GPT‑4o, Claude 3 Opus, Gemini 1.5 Pro | 准确性高、复杂推理强、上下文长 | 需要稳健可靠与高复杂度任务 |
| 高性价比通用 | Claude 3 Sonnet, Gemini 1.5 Flash, GPT‑3.5/Turbo 系列 | 低延迟、低成本、吞吐量高 | 大规模调用、交互频繁 |
| 代码与软件工程 | GPT‑4 Turbo/4o, Claude 3 Opus/Sonnet, Mistral Large, Code Llama | 代码理解与重构强、单测补全好 | 复杂代码库、跨语言项目 |
| 中文场景 | 通义千问 Qwen 1.5(≥32B/72B), 智谱 GLM‑4/GLM‑3, 百川 Baichuan 2(13B), Yi‑34B | 中文对齐好、术语稳定 | 中文写作、政企中文问答 |
| 开源自部署 | Llama 3(8B/70B)Instruct, Mixtral 8x22B, Qwen 1.5 72B, Yi‑34B | 私有化、可控、可微调 | 合规与数据本地化刚需 |
| 多模态图像理解 | GPT‑4o, Gemini 1.5 Pro, Claude 3 Sonnet(Vision) | OCR/图表/页面理解强 | 票据/表格/幻灯片解析 |
| 图像生成 | DALL·E 3, Midjourney v6, Stable Diffusion XL | 文生图质量高、风格多 | 创意与品牌视觉生成 |
| 视频生成 | Runway Gen‑3, Pika 1.0(文本/图生视频), (Sora 仍受限) | 易用、营销短视频 | 市场物料、分镜测试 |
| 语音(ASR/TTS) | Whisper, Azure Speech, Google STT, ElevenLabs(TTS) | ASR稳、多语种、TTS自然 | 呼叫中心、配音上屏 |
| RAG 检索增强 | 通用模型 + 向量检索 + 重排序器(Cohere Rerank 等) | 可控、降幻觉 | 知识库问答、企业搜索 |
| 生物医药 | Med‑PaLM(研究/医疗QA), BioGPT(文献)、NVIDIA BioNeMo 生态 | 专业领域知识 | 医学摘要、药物发现(合规前提) |
| 法律/金融 | GPT‑4o/Claude 3 Opus + RAG + 严格提示约束 | 审慎、可追溯 | 合规审阅、长文摘要 |
Sources: 行业常识与 2024 年前公开发布的模型格局
通用对话与推理
-
旗舰之选: GPT‑4o、Claude 3 Opus、Gemini 1.5 Pro 理由: 准确率高、复杂推理稳、长上下文能力强,适合策略分析、长文档理解与多步骤任务。
-
性价比之选: Claude 3 Sonnet、Gemini 1.5 Flash、GPT‑3.5/Turbo 系列 理由: 低成本低延迟,适合大量消息、客服与轻量创作。
-
中文友好补充: 通义千问 Qwen 1.5(≥32B/72B)、GLM‑4、Baichuan 2、Yi‑34B 理由: 中文对齐与术语稳定性更好,适合中文问答、政企场景。
代码与软件工程
-
复杂工程与跨语言: GPT‑4 Turbo/4o、Claude 3 Opus/Sonnet、Mistral Large 优势: 代码理解、重构、性能分析、设计评审与单测补全更强。
-
开源与离线: Code Llama、StarCoder2、Llama 3 70B Instruct、Mixtral 8x22B 优势: 私有化可控,配合函数调用、AST 分析与项目索引实现“代码 RAG”。
-
实践建议:
-
上下文工程: 用仓库摘要、模块图与接口契约喂给模型,减少幻觉。
-
单测优先: 先让模型补全/修复测试,再改实现,回归更稳。
-
安全栈: 引入权限最小化与机密分层,避免秘钥泄露。
-
多模态(图像/视频/语音)
-
图像理解: GPT‑4o、Gemini 1.5 Pro、Claude 3 Sonnet(Vision) 适用: 票据/报表 OCR、图表解读、UI 截图分析、幻灯片摘要。
-
图像生成: DALL·E 3(构图与指令跟随强)、Midjourney v6(美学与风格)、Stable Diffusion XL(可控与私有化微调)。 提示: 品牌一致性可用 LoRA/风格库;合成图片需水印与合规声明。
-
视频生成: Runway Gen‑3、Pika 1.0(文本/图生视频);Sora 公测受限。 场景: 营销物料、分镜预演、动效草图;对时长与细节的期望要管理。
-
语音:
-
ASR: Whisper(开源、稳)、Azure/Google STT(企业级与多语种)。
-
TTS: ElevenLabs(自然度高)、Azure Neural TTS(角色风格多)。
-
通话场景: 选择低延迟流式接口,降噪、声纹与敏感词过滤并行上。
-
RAG 检索增强与企业私有化
-
为什么要 RAG: 让模型“只回答有依据的内容”,用向量检索、BM25、重排序器组合,显著降低幻觉与过拟合。
-
模型搭配:
-
生成: GPT‑4o / Claude 3 / Gemini 1.5 Pro(重要回答),Sonnet/Flash(高并发)。
-
重排序: Cohere Rerank/开源 Cross‑Encoder;长文多阶段检索更稳。
-
嵌入: OpenAI/Text‑Embeddings、BGE‑m3(中文强)、E5/M3 系列(多语)。
-
-
私有化选型:
-
轻载边缘: Llama 3 8B Instruct、Qwen 1.5 7B、Baichuan 2 7B。
-
中高载: Llama 3 70B、Qwen 1.5 32B/72B、Mixtral 8x22B、Yi‑34B。
-
策略: 先用开源+RAG 验证闭环,再决定是否引入商用 API。
-
-
治理与合规:
-
可追溯: 引用片段回链与“我不知道”策略。
-
安全: PII/敏感词脱敏、访问审计、提示注入检测。
-
评测: 建立领域集(准确、覆盖、拒答率、来源一致性)。
-
行业场景要点
-
金融:
-
推荐: GPT‑4o/Claude 3 + RAG(招股书、研报、条款解析);表格/图表配多模态。
-
注意: 合规审阅、版本留痕、不可替代人类决策。
-
-
法律:
-
推荐: Claude 3 Opus(长文与严谨措辞)+ 分段 RAG;引用必须回链原文。
-
注意: 明确“非法律意见”声明,强拒答策略。
-
-
医疗与生命科学:
-
推荐: Med‑PaLM(研究)、BioGPT/NVIDIA BioNeMo 生态(语料专业);临床需 IRB/合规。
-
注意: 必须由持证专家复核,数据最小化与脱敏。
-
-
教育与企业培训:
-
推荐: Sonnet/Flash 作为对话引擎 + RAG 知识库 + 过程可视化。
-
注意: 防止“编造参考”,题库与答案分离管理。
-
落地选型三步法
-
明确优先级:
-
目标: 准确/成本/延迟/合规/中文能力,选两个最重要。
-
场景: 问答/创作/代码/多模态/流程自动化,确定主任务。
-
-
双轨验证:
-
旗舰 vs 性价比: 同一评测集跑 GPT‑4o/Claude 3 与 Sonnet/Flash。
-
API vs 自托管: 同时验证开源(Llama 3/Qwen 等)+ RAG 的稳定性与 TCO。
-
-
小步快跑:
-
从一个高价值用例出发: 如客服知识库、报表问答或代码评审。
-
治理闭环: 指标看板(准确、拒答、引用质量、时延、成本)、A/B 更新与回滚。
-

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)