
“你的AI-Coding为什么还在制造Bug?” 别再傻傻地换模型了,问题出在你的项目规范!
我们都知道,模型越智能,生成效果越好,决定了AI编程的上限。但在工业界,比起追求更高的上限,稳定的下限往往更为关键。毕竟,大部分代码都是在既定的业务与技术框架中完成的,能持续输出稳定、规范的代码才是真正的竞争力。那么,如何保障这一“稳定的下限”呢?下面是我的一些心得。
序
我们都知道,模型越智能,生成效果越好,决定了AI编程的上限。但在工业界,比起追求更高的上限,稳定的下限往往更为关键。毕竟,大部分代码都是在既定的业务与技术框架中完成的,能持续输出稳定、规范的代码才是真正的竞争力。那么,如何保障这一“稳定的下限”呢?下面是我的一些心得。
一、项目结构清晰简单
你是否遇到过AI生成的代码不符合规范、路径错误等问题?项目结构的核心不是 “完美设计”,而是 “低理解成本 + 易重构”。过度嵌套、模糊命名会导致人需花大量时间定位文件,AI 也易因层级混乱生成错误路径的代码。
核心原则:simple is best
在 AI Coding 中这个原则更显重要,能保证AI生成的代码质量
- 项目层级不要过深,减少程序员和AI阅读理解负担。
- 目录职责单一,每个目录只做一类事。如果目录的功能模棱两可,项目文件会存放越来越混乱。
为了便于AI理解,可以提供一个项目结构介绍文档,比如写在项目的
Readme.md中,通过tree -d命令获取当前项目结构,复制到Readme.md中进行一一描述
- 代码可维护性高:
随着项目的修改,业务的变化、人员的变更,项目逐渐混乱是必然的规律。我们要考虑如何长时间的保证AI-Coding的质量,这里我们不去长篇大论各种设计模式和原理,只提出一个核心的点:
写易删除或易拓展的代码
我们可以区分两个场景,人和AI都可以遵循如下规范:
- 写易删除的代码
若不确定业务未来变化,不提前做 “过度封装”(比如为未明确的复用场景建多层抽象类)。我们保证代码高内聚、层级单一、简单清晰,这样遇到较大的变动,直接重写会更方便。只有当出现重复逻辑或则业务清晰后我们在进行抽象封装。
- 写易拓展的代码
对于确定的核心业务,大概率有成熟方案或者发展路径清晰,在代码复杂的情况下我们可以提前考虑如何抽象、封装,保证后续的可拓展性。 为了保证核心代码稳定性,记得编写单元测试,并让AI修改代码后自动运行测试用例。
通过AI生成测试时建议在Prompt中加上测试覆盖率的要求,比如:“核心代码单测覆盖率 >= 80%”, 这样测试用例会更加全面
二、项目工具、配置齐全
每个公司或团队应该都有项目layout或脚手架工具,辅助快速创建一个结构统一,工具、配置齐全的项目。
通过类似如下命令初始化项目:
contrib project init ...
创建的项目里需要包含了AI-Coding 必要的依赖,如下:
1.MCP
其中配置了必要的Tools和Prompts,比如 需求文件获取、合并请求创建等Tools, develop-flow、code-review、unit-test等Prompts. 可以在聊天窗口通过/快速触发。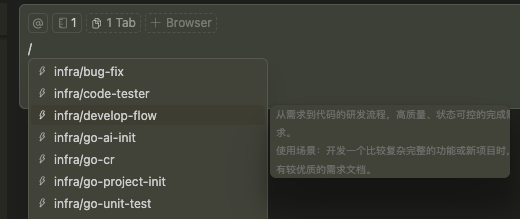
MCP 的管理维护可以使用 higress、MCP Context Forge 等网关,具体可以看看我的上一期文章:[AI 编程的下半场:从找工具到管工具
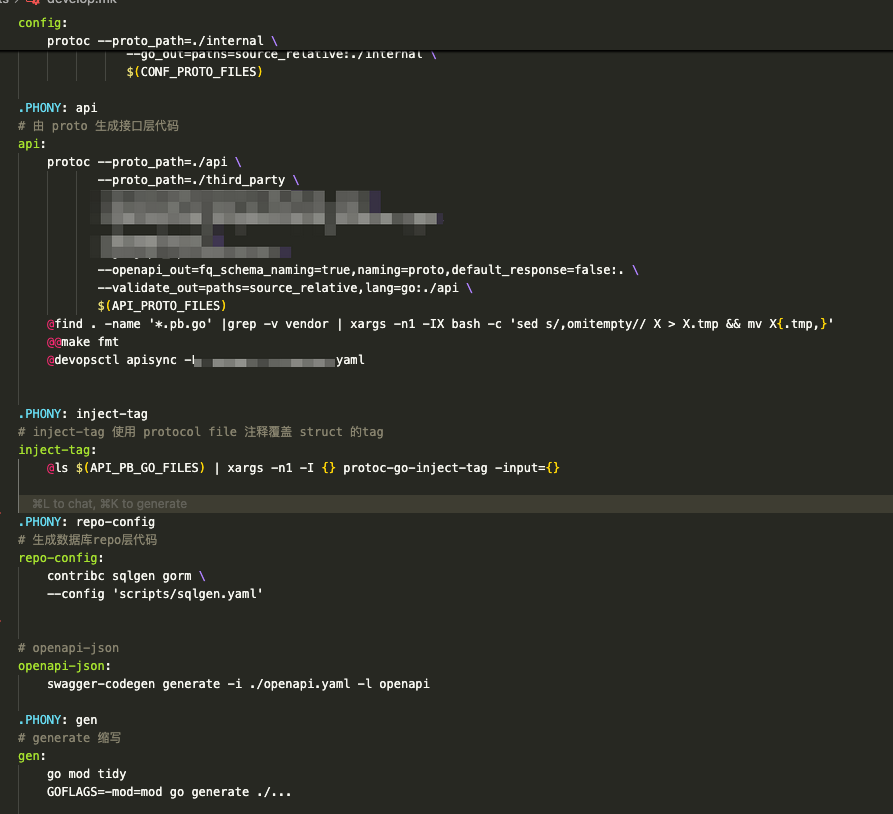
2.代码生成工具
模版代码不建议让AI生成,效率低且效果不稳定、耗token。类似的规则固定的大文本处理场景,建议用AI构建解决问题的工具,而不是把问题直接丢给AI处理。
我们将代码生成工具,通过 Makeflie 的形式提供,比如 api生成、repo层代码生成、错误码生成…:
3.AI开发指南文档
这个文档建议一直添加在上下文中,其中包含了项目结构介绍、并指导如何实现各种类型的功能,比如:api、定时任务…, 以及如何在过程中结合使用代码生成工具等等。
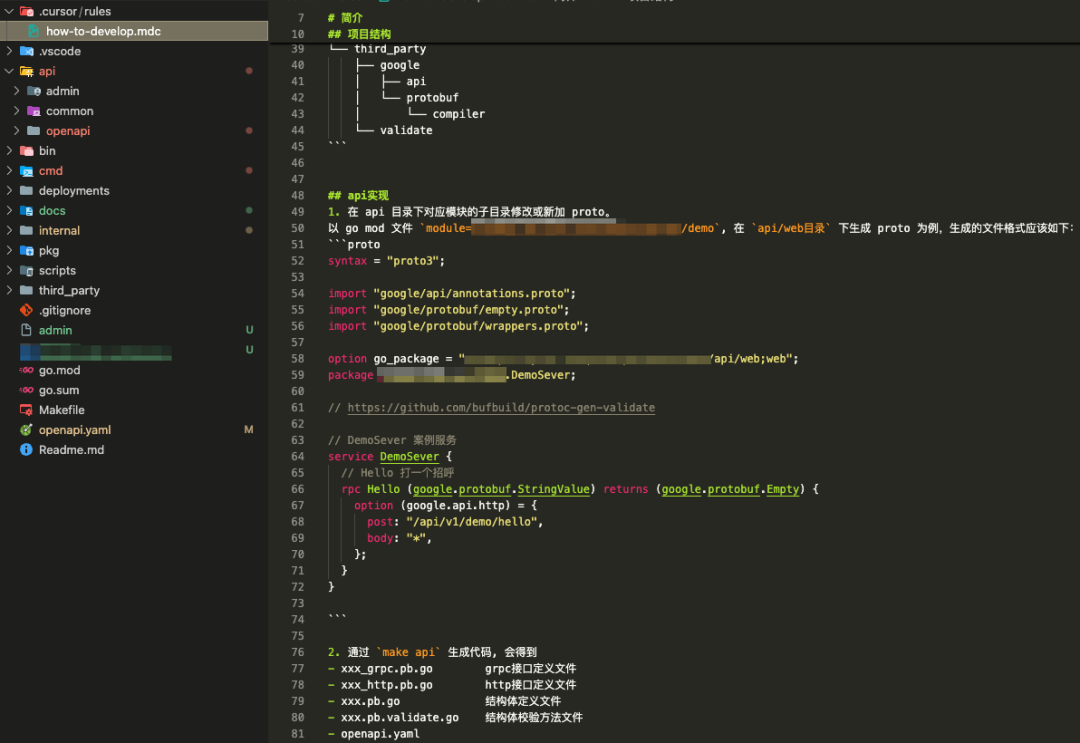
⚠️ 在项目中的文档、提示词如无必要,请勿增加,否则会面临难以维护的问题。建议只存储需要一直添加在聊天上下文中的(IDEA功能限制)、或者是项目独有规范的才放在项目中,其余都通过专业的工具进行远端管理。
三、最后
如果把 AI 当作一个“人”,我们就能推理出它偏好的项目特征:结构清晰、目标明确、工具链完善。 与人不同,AI 目前不便于主动与现实世界交互、也不能即时求证和筛选信息,因此它比人更依赖“干净的输入”和“确定的环境”。
💡 AI-Coding 相关Prompts 我提炼了一些通用的放到了:
https://github.com/xyzbit/AI-Coding, 希望对你有帮助 😊
最后,让我们一起讨论一个问题,你认为“AI 编程的最终形态”是:A. 人主导,AI 辅助?
B. AI 主导,人做决策?
C. 通过工具和流程,让 AI 像“程序员机器人”一样自主完成开发?
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 18
18 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)