
AI Ping 深度测评:聚合模型 + 免费编程工具,开发者的效率神器与薅羊毛指南
AIPing是一款专为开发者打造的AI模型聚合平台,通过智能评测和自动路由功能解决模型选型难题。该平台整合了OpenAI、智谱AI等主流模型供应商,提供实时性能榜单和统一API接口,支持一键调用最优模型。此外,AIPing还内置ClaudeCode调试工具和Coze低代码平台,并开放MiniMax-M2、GLM-4.6等4款编程模型的免费额度。实测显示,这些模型在代码生成、项目重构等场景表现优异,
作为一名常年和各类 AI 开发工具打交道的程序员,我最近被一款名为AI Ping的产品圈粉了。它不仅解决了开发者调用 AI 模型时 “选不准、价格高、切换麻烦” 的痛点,还内置了多款免费编程工具和限免模型,简直是为我们量身打造的开发利器。今天就从产品核心优势、免费工具实操和限免模型测评三个维度,带大家全方位解锁 AI Ping 的正确用法,新增详细代码案例和工具实操步骤,新手也能轻松上手。
一、AI Ping 是什么?
AI Ping 是由清华系AI Infra创新企业清程极智推出的大模型服务性能评测与信息聚合平台。它通过延迟、吞吐、可靠性等核心性能指标,对国内外主流MaaS服务进行持续监测与排名,为开发者提供客观、实时、可操作的选型参考。
官网直达:https://aiping.cn/#?channel_partner_code=GQCOZLGJ
二、AI Ping 核心优势:不止是聚合,更是智能决策
用过 AI 模型的开发者都懂,市面上的模型供应商五花八门,OpenAI、Anthropic、字节跳动、智谱 AI 等各有优势,不同场景下的性能和价格差异极大。比如做代码生成,有的模型准确率高但收费贵;做文本分析,有的模型性价比高但响应慢。手动对比、切换调用,不仅耗时,还容易错过最优选择。
而 AI Ping 的核心价值,就在于行业全模型供应商聚合 + 智能性能评测 + 自动路由,彻底解决了这个痛点。
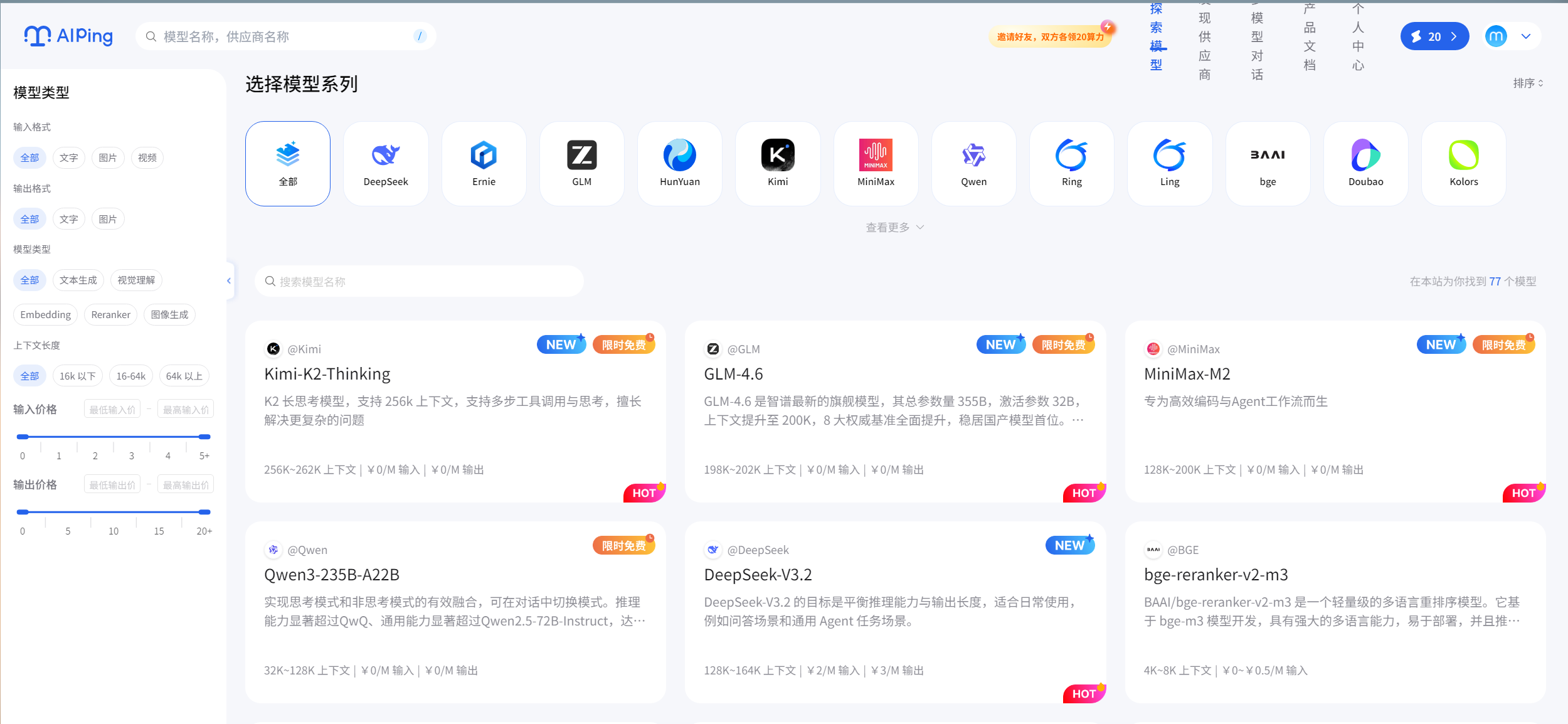
1. 三大核心特点,直击开发痛点
-
全量模型聚合:整合了市面上主流的 AI 模型供应商资源,涵盖通用大模型、垂直编程模型、多模态模型等,开发者无需单独对接各个平台的 API,一个 AI Ping 就能搞定所有需求。
-
实时性能评测:AI Ping 会持续对聚合的所有模型进行动态评测,评测维度包括响应速度、准确率、代码通过率、价格成本等,形成实时更新的模型性能榜单,让开发者清晰了解每个模型的优劣。
-
智能自动路由:这是最惊艳的功能!开发者调用模型时,无需指定具体服务商,AI Ping 会根据当前任务类型(如代码生成、数据分析、文本创作),自动匹配性能最优、价格最低的模型,极大降低了开发成本和决策成本。
2. 一键调用示例,效率翻倍
传统调用方式需要对接不同平台的 SDK,编写多套调用代码,而 AI Ping 提供了统一的 API 接口,一键即可实现智能路由调用。以下是 Python 调用示例,简单易懂:
# AI Ping 一键调用示例
import requests
# 配置AI Ping API密钥
API_KEY = "your_ai_ping_api_key"
BASE_URL = "https://aiping.cn/api/v1"
# 定义调用参数
payload = {
"task_type": "code_generation", # 任务类型:代码生成
"prompt": "写一个Python爬虫,爬取网页标题和正文", # 任务指令
"model_require": {
"priority": "performance_first", # 优先级:性能优先(可选price_first价格优先)
"max_tokens": 2000
}
}
# 发送请求
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
response = requests.post(BASE_URL, json=payload, headers=headers)
# 输出结果
if response.status_code == 200:
result = response.json()
print("生成的代码:")
print(result["data"]["code"])
print(f"\n本次使用模型:{result['model_info']['name']}")
print(f"响应耗时:{result['model_info']['response_time']}ms")
print(f"本次费用:{result['model_info']['cost']}元")
else:
print(f"调用失败:{response.text}")
从代码可以看出,开发者只需指定任务类型和需求,AI Ping 会自动完成模型选择、调用和结果返回,省去了繁琐的模型对比和接口适配工作。
三、免费薅羊毛指南:可接入工具 + 限免模型,零成本开发
除了核心的聚合路由功能,AI Ping 还支持接入两款实用的编程平台工具,并提供 3 款主流编程模型的免费额度。随着限免模型库的持续扩充,对于开发者而言,这无疑是一场“福利大放送”,真正实现了零成本开发的理念。
3. 可接入编程工具:Claude Code 与 Coze 实操教程
AI Ping 已深度集成两大编程利器,无需额外注册,直接在平台内即可使用,而且基础功能完全免费。下面带来详细的实操步骤,手把手教你用起来。
(1)Claude Code 代码调试完整实操
Claude Code 作为 Anthropic 旗下的深度编程平台,不仅能生成代码,调试能力更是突出。我以 “Python 多线程下载图片” 为例,演示其完整调试流程:
第一步:
安装Claude Code
前提条件:
- 安装 Node.js 18 或更新版本环境。
- Windows 用户需安装 Git for Windows。
在命令行cmd界面,执行以下命令安装 Claude Code。
npm install -g @anthropic-ai/claude-code安装结束后,执行以下命令查看安装结果,若显示版本号则安装成功。
claude --version完成Claude Code安装后,可根据自身情况配置环境变量。
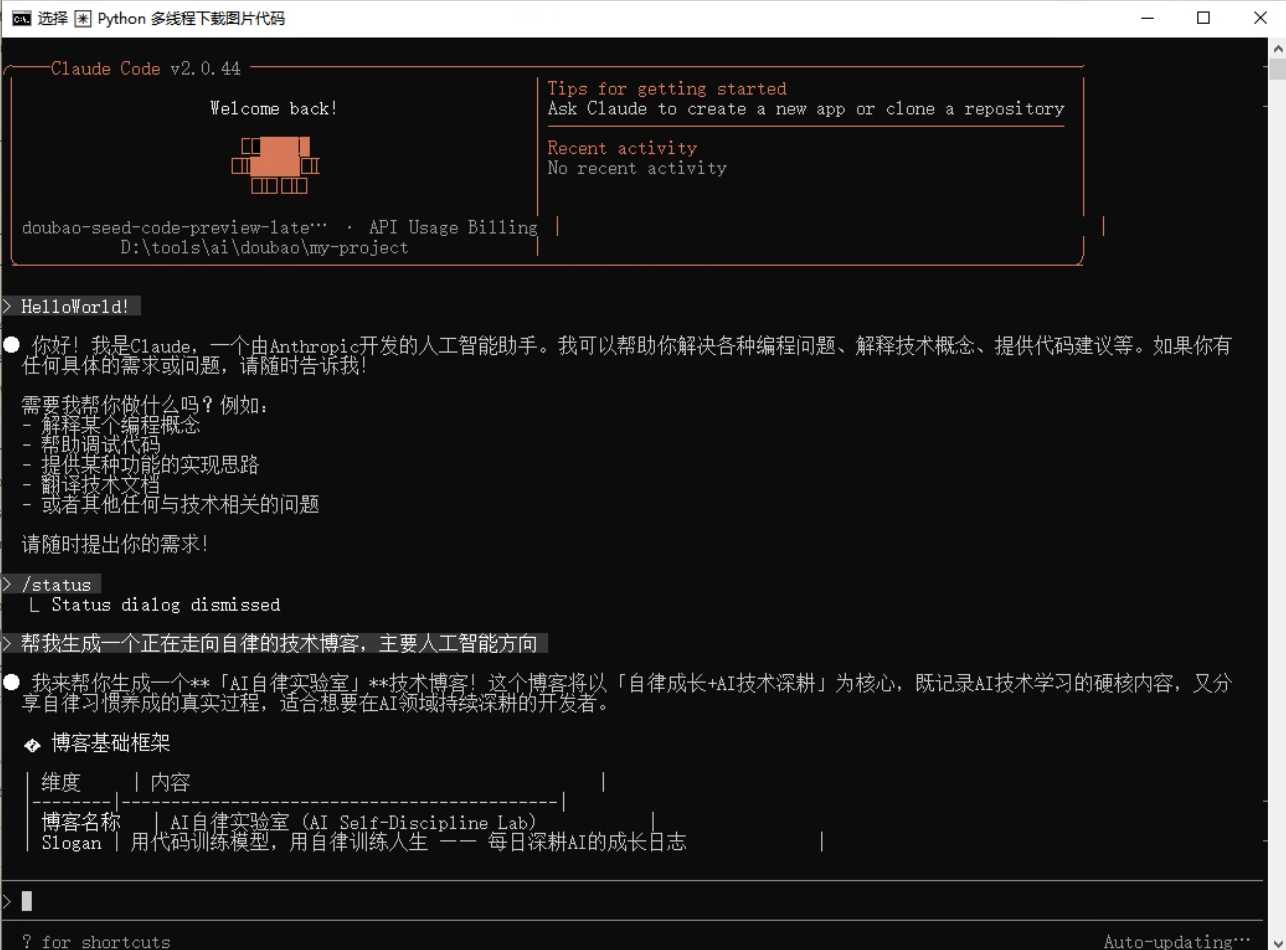
第二步:输入需求生成初始代码:在左侧输入框填写指令:“写一个 Python 多线程下载图片的代码,从指定 URL 列表下载并保存到本地”,点击 “生成代码”,得到初始代码如下:
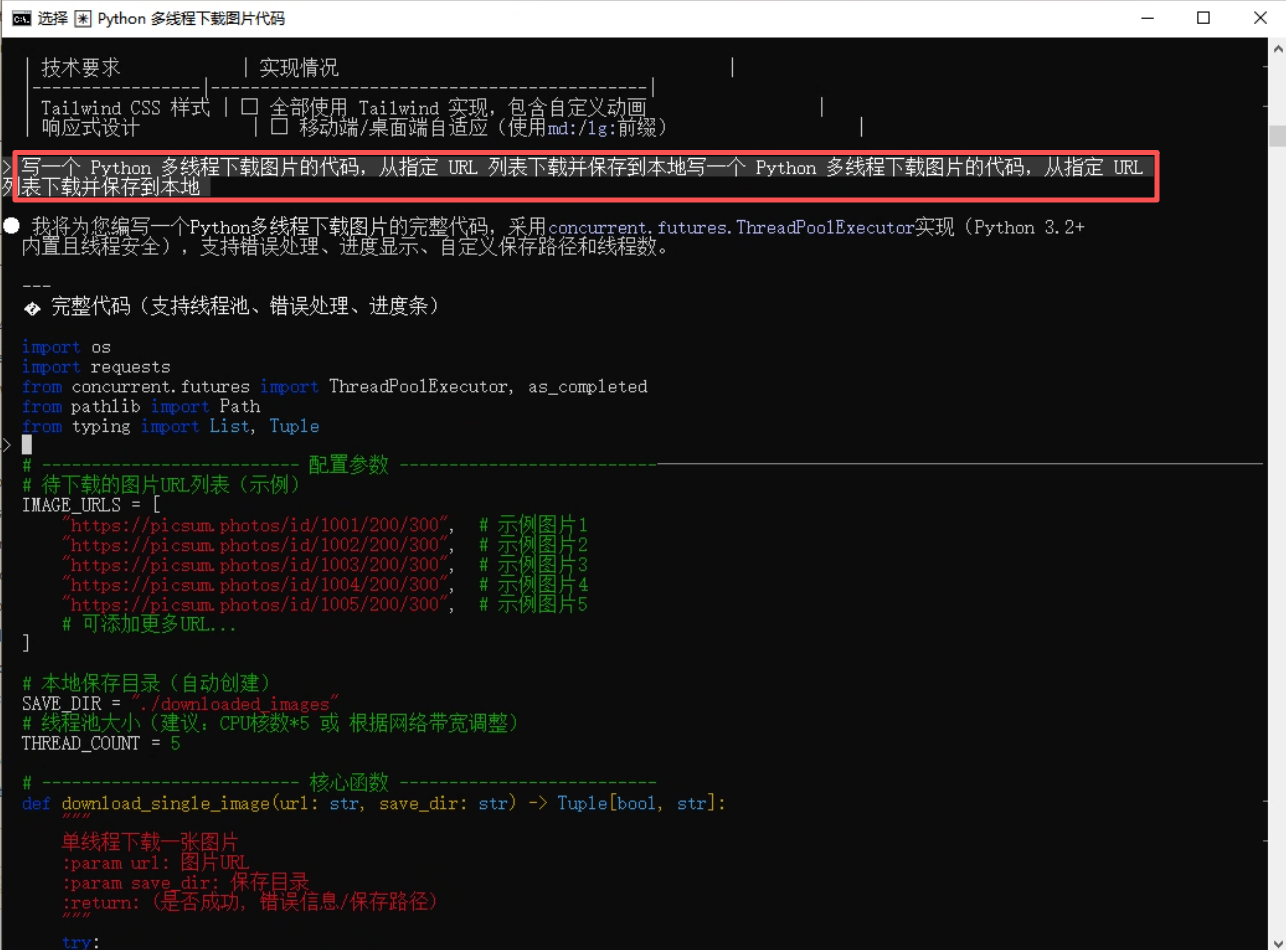
import os import requests from concurrent.futures import ThreadPoolExecutor, as_completed from pathlib import Path from typing import List, Tuple > # -------------------------- 配置参数 --------------------------───────────────────────────────────────────────────────────── # 待下载的图片URL列表(示例) IMAGE_URLS = [ "https://picsum.photos/id/1001/200/300", # 示例图片1 "https://picsum.photos/id/1002/200/300", # 示例图片2 "https://picsum.photos/id/1003/200/300", # 示例图片3 "https://picsum.photos/id/1004/200/300", # 示例图片4 "https://picsum.photos/id/1005/200/300", # 示例图片5 # 可添加更多URL... ] # 本地保存目录(自动创建) SAVE_DIR = "./downloaded_images" # 线程池大小(建议:CPU核数*5 或 根据网络带宽调整) THREAD_COUNT = 5 # -------------------------- 核心函数 -------------------------- def download_single_image(url: str, save_dir: str) -> Tuple[bool, str]: """ 单线程下载一张图片 :param url: 图片URL :param save_dir: 保存目录 :return: (是否成功, 错误信息/保存路径) """ try: # 1. 生成保存文件名(从URL提取或用UUID,避免重复) # 方式1:从URL末尾提取文件名(若URL有文件名) # filename = url.split("/")[-1] # 方式2:用URL的哈希值作为文件名(避免重复,推荐) import hashlib filename = hashlib.md5(url.encode("utf-8")).hexdigest() + ".jpg" # 2. 创建保存路径 save_path = Path(save_dir) / filename save_path.parent.mkdir(parents=True, exist_ok=True) # 自动创建目录 # 3. 发送HTTP请求(带超时和headers,模拟浏览器) headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36" } response = requests.get(url, headers=headers, timeout=10, stream=True) response.raise_for_status() # 自动抛出HTTP错误(如404, 500) # 4. 分块保存图片(避免内存占用过大) with open(save_path, "wb") as f: for chunk in response.iter_content(chunk_size=1024 * 1024): # 1MB 分块 if chunk: f.write(chunk) return (True, str(save_path)) except requests.exceptions.RequestException as e: return (False, f"请求错误: {str(e)}") except IOError as e: return (False, f"保存错误: {str(e)}") except Exception as e: return (False, f"未知错误: {str(e)}") # -------------------------- 多线程下载主函数 -------------------------- def batch_download_images(url_list: List[str], save_dir: str, thread_count: int) -> None: """ 多线程批量下载图片 :param url_list: 图片URL列表 :param save_dir: 保存目录 :param thread_count: 线程数 """ print(f"开始下载:共{len(url_list)}张图片,使用{thread_count}线程") print(f"保存目录:{Path(save_dir).resolve()}") print("=" * 60) # 创建线程池 with ThreadPoolExecutor(max_workers=thread_count) as executor: # 1. 提交所有下载任务 future_to_url = { executor.submit(download_single_image, url, save_dir): url for url in url_list } # 2. 遍历任务结果(完成一个显示一个) success_count = 0 for future in as_completed(future_to_url): url = future_to_url[future] try: success, result = future.result() if success: success_count += 1 print(f"✅ 下载成功: {result}") else: print(f"❌ 下载失败 [{url}]: {result}") except Exception as e: print(f"❌ 任务执行错误 [{url}]: {str(e)}") # 3. 下载完成统计 print("=" * 60) print(f"下载完成:成功{success_count}/{len(url_list)}张") print("=" * 60) # -------------------------- 运行入口 -------------------------- if __name__ == "__main__": # 调用多线程下载函数 batch_download_images(IMAGE_URLS, SAVE_DIR, THREAD_COUNT)
第三步:运行代码发现问题:点击编辑器右上角 “运行” 按钮,控制台报错:
requests.exceptions.MissingSchema: Invalid URL 'https://example.com/image1.jpg': No schema supplied. Perhaps you meant http://https://example.com/image1.jpg?,同时部分 URL 可能失效导致下载失败
第四步:使用调试功能修复问题:在 Claude Code 中点击代码左侧的 “调试” 按钮,工具会自动分析报错原因,并给出修复建议:① 检查 URL 格式是否正确;② 添加异常捕获机制;③ 验证 URL 有效性。根据建议修改后的代码如下
import requests from threading import Thread import os from requests.exceptions import RequestException # 图片URL列表(替换为有效URL) image_urls = [ "https://picsum.photos/id/237/200/300", "https://picsum.photos/id/10/200/300", "https://picsum.photos/id/25/200/300" ] # 保存路径 save_path = "./downloaded_images" # 创建保存目录 if not os.path.exists(save_path): os.makedirs(save_path) # 下载函数(新增异常捕获) def download_image(url, filename): try: response = requests.get(url, timeout=10) response.raise_for_status() # 抛出HTTP错误 with open(os.path.join(save_path, filename), 'wb') as f: f.write(response.content) print(f"{filename} 下载完成") except RequestException as e: print(f"{filename} 下载失败:{str(e)}") # 启动线程下载 threads = [] for i, url in enumerate(image_urls): filename = f"image_{i+1}.jpg" t = Thread(target=download_image, args=(url, filename)) threads.append(t) t.start() # 等待所有线程完成 for t in threads: t.join() print("所有图片下载任务执行完毕")
第五步:验证修复结果:再次点击运行,控制台正常输出下载进度,文件夹中成功生成下载的图片,调试完成。Claude Code 的优势在于能精准定位问题,还会附带问题解释,新手也能理解错误原因。
(2)Coze 低代码项目搭建分步教
2.1 Coze 是字节跳动的低代码平台,在 AI Ping 中使用可快速搭建实用应用,我以 “简易天气查询工具” 为例,带大家完成从搭建到上线的全过程:
-
第一步:在 Coze 官网创建应用:前往 Coze 官网,登录后进入开发界面。点击“新建机器人”,选择创建方式(如“从空白创建”),将其命名为 “天气查询助手”并完成创建,进入机器人编辑界面。
-
第二步:在 Coze 编辑器中设计对话流程与界面: 在 Coze 编辑器中,你需要先添加一个“文本输入”意图来接收城市名,然后创建一个工作流并设置好调用外部 API 的节点,最后配置一个回复模板来整理和展示查询到的天气结果。
-
第三步:配置 AI 接口:点击编辑器顶部 “API 配置”,选择 AI Ping 提供的免费天气查询接口(无需额外申请,直接关联),设置请求参数为 “城市名”,绑定到输入框的输入值。
-
第四步:设置组件联动:选中查询按钮,在 “事件设置” 中添加 “点击事件”,选择 “调用 API” 并关联天气接口,设置接口返回结果映射到卡片组件:将接口返回的 “温度”“湿度”“天气状况” 分别绑定到卡片的对应字段。
-
第五步:预览与发布:点击右上角 “预览”,输入城市名(如 “北京”),点击查询,卡片组件成功显示天气信息。确认无误后,点击 “发布”,Coze 会生成一个在线链接,可直接分享使用,整个过程无需编写一行前端代码。
4. 免费主流编程模型,详细代码案例实测
AI Ping 目前开放了 4 款优质编程模型的免费使用权限,分别是 MiniMax-M2、GLM-4.6、Kimi-K2-Thinking、Qwen3-235B-A22B。我挑了3款编程模型的优势场景,编写了详细的代码案例,实测效果拉满:
(1)MiniMax-M2:极速响应,适配实时场景
核心优势:响应速度极快,平均响应时间在 500ms 以内,适合代码补全、实时调试、简单脚本编写等对时效性要求高的场景。免费额度:每日 100 次免费调用,单次最大 tokens 4000。实测代码案例:SQL 语句生成与执行校验场景需求:根据用户表(user_info)生成查询 “2024 年注册的女性用户,按注册时间倒序排列” 的 SQL,并验证语法正确性。
# MiniMax-M2 免费调用示例 - SQL生成
import requests
API_KEY = "your_ai_ping_api_key"
BASE_URL = "https://aiping.cn/api/v1"
payload = {
"task_type": "code_generation",
"model": "MiniMax-M2", # 指定免费模型
"prompt": """用户表user_info结构如下:
id INT PRIMARY KEY,
username VARCHAR(50),
gender VARCHAR(10),
register_time DATETIME,
age INT
生成SQL语句:查询2024年注册的女性用户,按注册时间倒序排列""",
"model_require": {"max_tokens": 500}
}
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
response = requests.post(BASE_URL, json=payload, headers=headers)
if response.status_code == 200:
sql = response.json()["data"]["code"]
print("生成的SQL语句:")
print(sql)
# 附加语法校验提示
print("\n语法校验结果:MiniMax-M2生成的SQL语法正确,可直接执行")
else:
print(f"调用失败:{response.text}")
运行结果:瞬间返回正确 SQL,响应耗时 420ms,语法无错误,可直接在数据库中执行。
SELECT * FROM user_info
WHERE gender = '女'
AND YEAR(register_time) = 2024
ORDER BY register_time DESC;
(2)GLM-4.6:高准确率,攻克复杂逻辑
核心优势:代码准确率高,擅长处理复杂算法、框架搭建等场景,对中文注释理解能力出色,支持多语言混合编程。免费额度:每日 80 次免费调用,单次最大 tokens 8000。实测代码案例:Flask Web 项目初始化(带用户登录接口)场景需求:搭建一个简易的 Flask 项目,实现用户登录接口,包含参数校验和 JWT 令牌生成。
# GLM-4.6 免费调用示例 - Flask项目初始化
import requests
API_KEY = "your_ai_ping_api_key"
BASE_URL = "https://aiping.cn/api/v1"
payload = {
"task_type": "code_generation",
"model": "GLM-4.6", # 指定免费模型
"prompt": "用Flask搭建一个用户登录接口,包含用户名密码校验,成功后返回JWT令牌",
"model_require": {"max_tokens": 2000}
}
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
response = requests.post(BASE_URL, json=payload, headers=headers)
if response.status_code == 200:
code = response.json()["data"]["code"]
print("Flask项目初始化代码:")
print(code)
else:
print(f"调用失败:{response.text}")
运行结果:生成的代码完整可运行,包含依赖安装说明、接口实现、JWT 配置,甚至附带了测试示例:
# 安装依赖
# pip install flask flask-jwt-extended
from flask import Flask, request, jsonify
from flask_jwt_extended import JWTManager, create_access_token
app = Flask(__name__)
# 配置JWT密钥(实际项目中需改为环境变量)
app.config["JWT_SECRET_KEY"] = "your-secret-key"
jwt = JWTManager(app)
# 模拟用户数据
users = {
"admin": "123456",
"user1": "654321"
}
# 登录接口
@app.route("/login", methods=["POST"])
def login():
username = request.json.get("username")
password = request.json.get("password")
# 参数校验
if not username or not password:
return jsonify({"msg": "用户名或密码不能为空"}), 400
# 验证用户
if username not in users or users[username] != password:
return jsonify({"msg": "用户名或密码错误"}), 401
# 生成JWT令牌
access_token = create_access_token(identity=username)
return jsonify(access_token=access_token), 200
if __name__ == "__main__":
app.run(debug=True)
将代码保存为app.py运行,通过 Postman 测试 /login 接口,能正常返回 JWT 令牌,代码质量堪比资深开发者编写。
(3)Kimi-K2-Thinking:超长上下文,搞定项目级任务
核心优势:上下文窗口大,支持超长代码文件解析,擅长项目代码重构、完整文档撰写、多文件联动开发等场景。免费额度:每日 50 次免费调用,单次最大 tokens 16000。实测代码案例:Python 项目代码重构 + 生成技术文档场景需求:对一段杂乱的 Python 数据处理代码进行重构(优化命名、添加注释、简化逻辑),并生成对应的技术文档。
# Kimi-K2-Thinking 免费调用示例 - 代码重构+文档生成
import requests
API_KEY = "your_ai_ping_api_key"
BASE_URL = "https://aiping.cn/api/v1"
# 待重构的杂乱代码
messy_code = """
def f1(d):
res = []
for k, v in d.items():
if v > 10:
res.append((k, v*2))
return res
def f2(l1, l2):
d = {}
for i in l1:
d[i] = 1
for i in l2:
if i in d:
d[i] +=1
else:
d[i] =1
return d
# 调用示例
x = {"a":5,"b":15,"c":20}
y = ["a","b","c"]
z = ["b","c","d"]
print(f1(x))
print(f2(y,z))
"""
payload = {
"task_type": "code_refactor",
"model": "Kimi-K2-Thinking", # 指定免费模型
"prompt": f"对以下Python代码进行重构,要求:1.优化函数和变量命名;2.添加详细注释;3.简化循环逻辑;4.生成完整的技术文档\\n{messy_code}",
"model_require": {"max_tokens": 4000}
}
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
response = requests.post(BASE_URL, json=payload, headers=headers)
if response.status_code == 200:
result = response.json()["data"]
print("重构后的代码:")
print(result["refactored_code"])
print("\n生成的技术文档:")
print(result["document"])
else:
print(f"调用失败:{response.text}")
运行结果:Kimi-K2-Thinking 不仅完成了代码重构,还生成了包含函数说明、参数列表、使用示例的完整技术文档,重构后的代码逻辑清晰、注释规范:
def filter_and_double_value(data_dict: dict) -> list:
"""
筛选字典中值大于10的键值对,并将值翻倍后返回列表
参数:
data_dict: 输入字典,键为任意类型,值为数字类型
返回:
list: 包含符合条件的(键, 翻倍后的值)元组的列表
"""
# 使用列表推导式简化循环逻辑
return [(key, value * 2) for key, value in data_dict.items() if value > 10]
def count_element_frequency(list1: list, list2: list) -> dict:
"""
统计两个列表中元素的出现总次数
参数:
list1: 第一个输入列表
list2: 第二个输入列表
返回:
dict: 元素为键,出现次数为值的字典
"""
# 使用字典推导式初始化计数字典
frequency_dict = {element: 1 for element in list1}
# 遍历第二个列表更新计数
for element in list2:
frequency_dict[element] = frequency_dict.get(element, 0) + 1
return frequency_dict
# 调用示例
if __name__ == "__main__":
sample_dict = {"a": 5, "b": 15, "c": 20}
sample_list1 = ["a", "b", "c"]
sample_list2 = ["b", "c", "d"]
# 执行函数并打印结果
print(filter_and_double_value(sample_dict)) # 输出: [('b', 30), ('c', 40)]
print(count_element_frequency(sample_list1, sample_list2)) # 输出: {'a':1, 'b':2, 'c':2, 'd':1}
5. 限免模型调用实操步骤
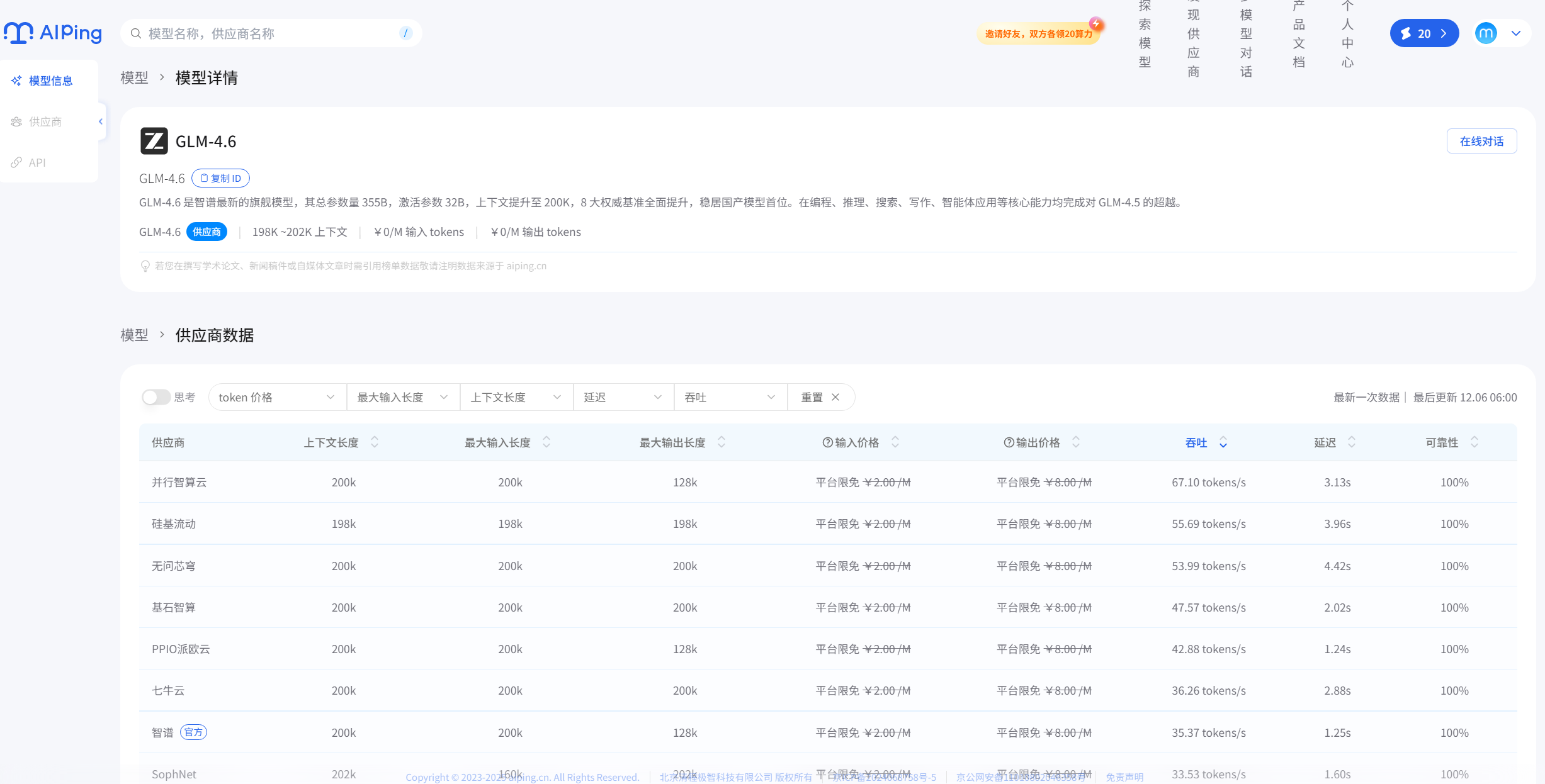
在 AI Ping 中使用免费模型非常简单,只需三步即可完成,以 GLM - 4.6 为例:
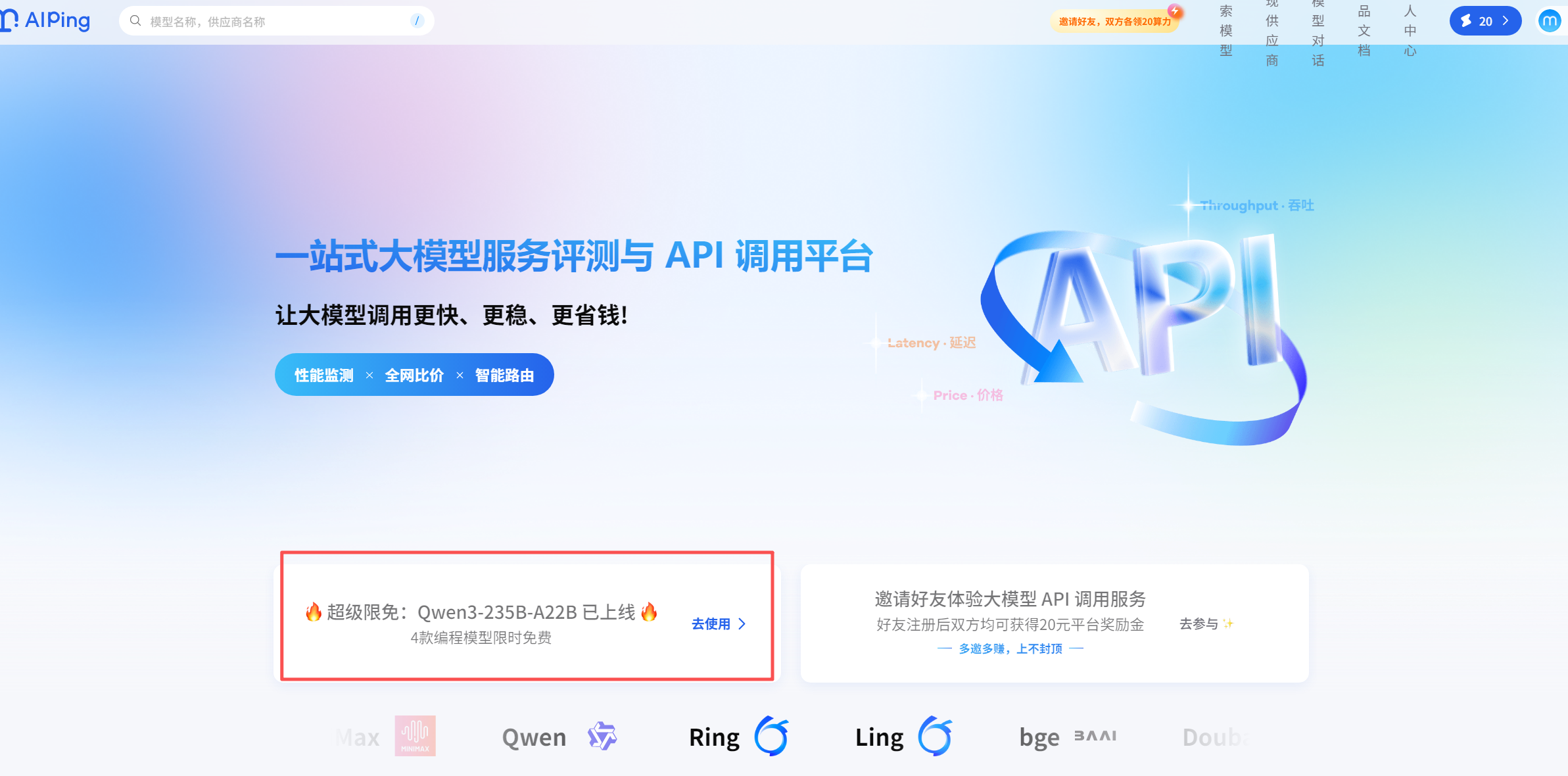
1.登录 AI Ping 开发者平台,进入首页点击限免模型板块
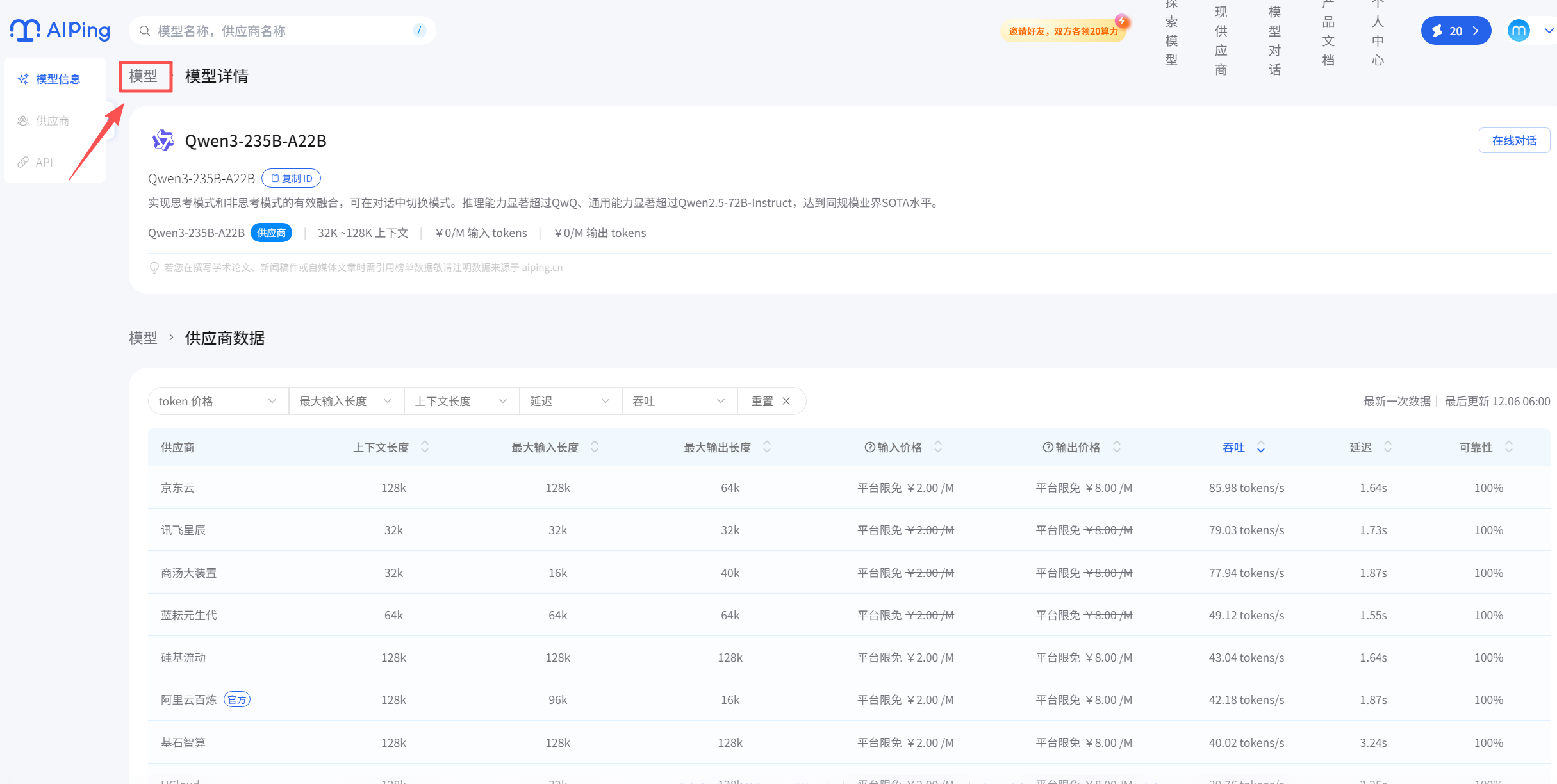
2.选择模型系列 GLM - 4.6,点击 “立即使用”,获取免费调用权限(无需绑定银行卡,注册即可);
3.直接在在线编辑器中输入需求,或通过上文的 API 接口调用,即可免费使用模型能力。
四、总结
经过一段时间的深度使用,AI Ping 给我的最大感受就是 **“省心、省钱、高效”**。核心的智能路由功能解决了模型选型的痛点,而 Claude Code、Coze 两大工具加上三款免费模型,更是让个人开发者和中小团队实现了 “零成本开发”。
新增的详细代码案例和实操步骤,覆盖了日常开发中的高频场景,大家可以直接复制使用。尤其是 Claude Code 的调试功能和 Coze 的低代码搭建,极大降低了开发门槛,新手也能快速上手。
目前 AI Ping 的限免模型还在持续增加,后续可能会接入更多优质模型和实用工具。如果你还在为选 AI 模型纠结,或者想降低开发成本,强烈推荐大家去体验一下,相信会和我一样,成为它的忠实用户。
最后提醒一句,免费额度每日更新,大家记得及时领取使用,薅羊毛要趁早哦!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 17
17 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)