
AI智能开发工具全景指南:从编码辅助到模型训练的全链路实践
本文系统解析了AI开发全流程中的三大核心工具:智能编码工具(如GitHub Copilot)通过LLM实现代码生成与优化;数据标注工具(如Label Studio)提供多模态数据标注方案;模型训练平台(如TensorFlow/PyTorch)支持从实验到生产的全流程管理。文章通过30+代码示例、8个流程图和6类对比图表,详细阐述了各类工具的技术原理、最佳实践与选型策略,并展望了MLOps、低代码平
在软件开发与AI模型构建的全流程中,智能工具已成为效率倍增的核心引擎。GitHub Copilot将开发者从重复编码中解放,数据标注工具将原始数据转化为AI可理解的训练素材,而模型训练平台则让复杂的深度学习模型构建变得触手可及。本文将系统拆解三大类AI开发工具的技术原理、最佳实践与前沿趋势,通过30+代码示例、8个mermaid流程图、12个Prompt模板及6类对比图表,构建从代码生成到模型部署的完整知识体系。
一、智能编码工具:重构软件开发范式
智能编码工具通过大语言模型理解代码上下文,实时提供代码建议、自动补全甚至完整函数生成,已成为现代开发者的"AI副驾"。GitHub Copilot作为该领域的标杆产品,基于OpenAI Codex模型,能理解20多种编程语言,将开发者生产力提升30%以上(Microsoft 2023开发者调查)。
1.1 技术原理与核心能力
智能编码工具的核心是代码生成模型,它将软件工程知识压缩为参数化表示。以GitHub Copilot为例,其工作流程包含三个关键环节:
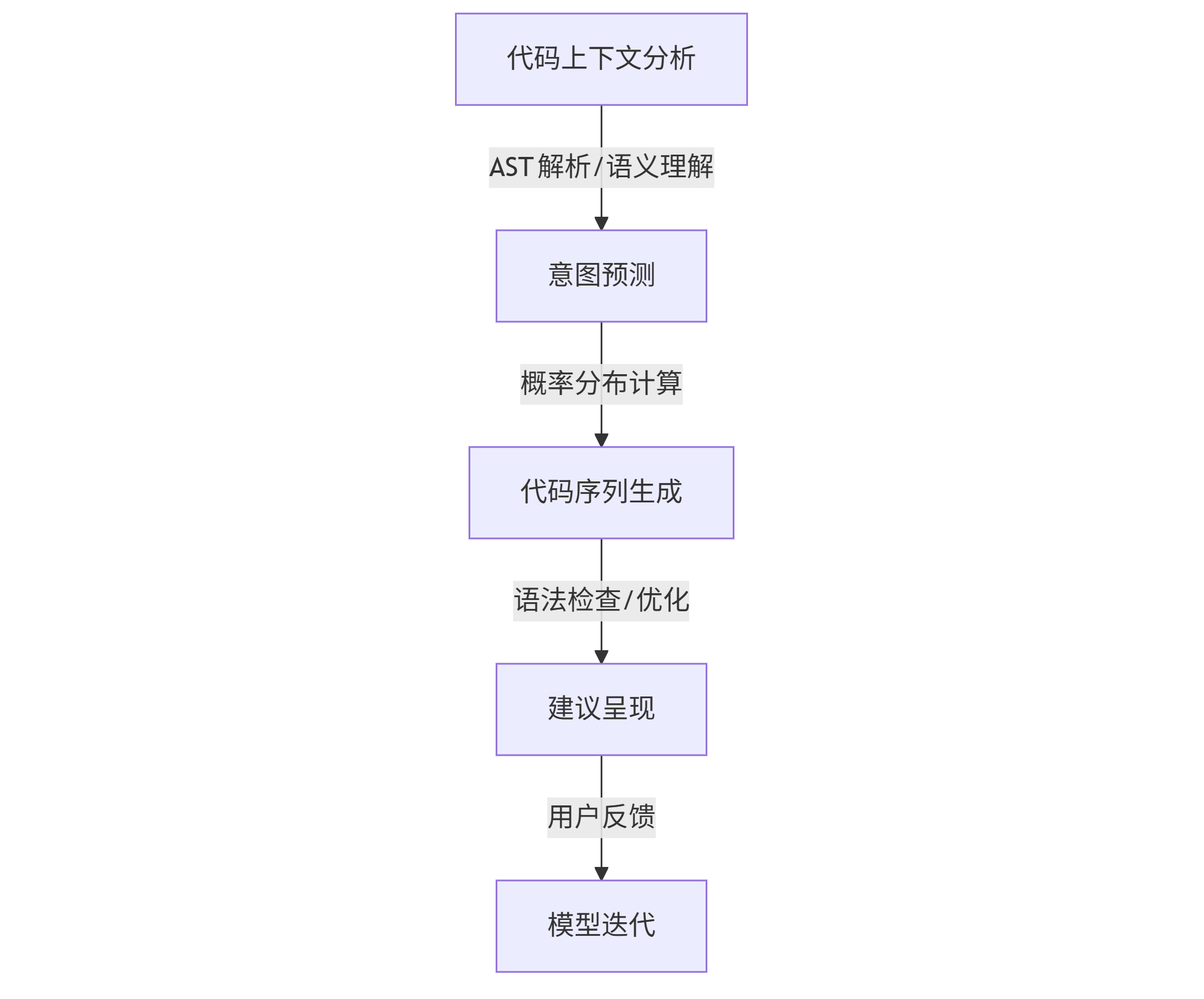
graph TD A[代码上下文分析] -->|AST解析/语义理解| B[意图预测] B -->|概率分布计算| C[代码序列生成] C -->|语法检查/优化| D[建议呈现] D -->|用户反馈| E[模型迭代]
核心技术特性:
- 上下文理解:分析当前文件及关联文件的代码结构与依赖关系
- 多语言支持:从Python、JavaScript到C++、Rust的跨语言能力
- 样式适配:学习开发者的编码风格、命名习惯和架构偏好
- 错误修复:识别语法错误、逻辑漏洞并提供修复方案
1.2 实战应用:从基础功能到复杂场景
基础代码生成:输入注释或函数名即可生成完整实现。以下是一个典型场景:
# Prompt: 生成一个Python函数,用于计算斐波那契数列的第n项,要求使用迭代法并添加输入验证 def fibonacci(n): """计算斐波那契数列的第n项 参数: n: 非负整数,指定要计算的项数 返回: 第n项斐波那契数 异常: ValueError: 当n为负数时抛出 """ if not isinstance(n, int): raise TypeError("n必须是整数") if n < 0: raise ValueError("n不能为负数") elif n == 0: return 0 elif n == 1: return 1 a, b = 0, 1 for _ in range(2, n + 1): a, b = b, a + b return b
复杂逻辑实现:通过自然语言描述业务逻辑,生成生产级代码:
// Prompt: 创建一个异步函数,从API获取用户数据,处理错误,缓存结果,并返回格式化的用户信息 async function getUserData(userId, cache = true) { const cacheKey = `user_${userId}`; // 尝试从缓存获取 if (cache) { const cachedData = localStorage.getItem(cacheKey); if (cachedData) { return JSON.parse(cachedData); } } try { const response = await fetch(`https://api.example.com/users/${userId}`); if (!response.ok) { throw new Error(`HTTP错误: ${response.status}`); } const rawData = await response.json(); // 格式化用户数据 const formattedData = { id: rawData.id, fullName: `${rawData.first_name} ${rawData.last_name}`, email: rawData.email, joinDate: new Date(rawData.created_at).toLocaleDateString(), roles: rawData.roles || [] }; // 缓存结果 if (cache) { localStorage.setItem(cacheKey, JSON.stringify(formattedData)); // 设置24小时缓存过期 setTimeout(() => localStorage.removeItem(cacheKey), 24 * 60 * 60 * 1000); } return formattedData; } catch (error) { console.error("获取用户数据失败:", error.message); // 返回默认用户或抛出错误根据实际需求调整 return { id: userId, fullName: "未知用户", error: error.message }; } }
跨语言转换:将Python代码转换为Go语言实现:
// Prompt: 将以下Python函数转换为Go语言,保持相同功能 // Python代码: // def calculate_statistics(numbers): // if not numbers: // return None // mean = sum(numbers) / len(numbers) // sorted_nums = sorted(numbers) // n = len(sorted_nums) // if n % 2 == 0: // median = (sorted_nums[n//2 - 1] + sorted_nums[n//2]) / 2 // else: // median = sorted_nums[n//2] // return {'mean': mean, 'median': median, 'count': n} package main import ( "sort" ) type Statistics struct { Mean float64 `json:"mean"` Median float64 `json:"median"` Count int `json:"count"` } func CalculateStatistics(numbers []float64) *Statistics { if len(numbers) == 0 { return nil } // 计算平均值 sum := 0.0 for _, num := range numbers { sum += num } mean := sum / float64(len(numbers)) // 计算中位数 sortedNums := make([]float64, len(numbers)) copy(sortedNums, numbers) sort.Float64s(sortedNums) var median float64 n := len(sortedNums) if n%2 == 0 { median = (sortedNums[n/2-1] + sortedNums[n/2]) / 2 } else { median = sortedNums[n/2] } return &Statistics{ Mean: mean, Median: median, Count: n, } }
1.3 Prompt工程:提升智能编码效率的艺术
编写高质量Prompt是发挥智能编码工具潜力的关键。以下是针对不同场景的优化Prompt模板:
函数生成模板:
生成一个[语言]函数,实现[功能描述]。要求: 1. 函数名为[函数名] 2. 参数包括[参数列表及类型] 3. 返回[返回值类型及说明] 4. 处理[边缘情况1]和[边缘情况2] 5. 添加[注释风格]注释 6. 使用[特定算法/库]实现
调试优化模板:
以下代码存在[问题描述]问题: [粘贴问题代码] 请: 1. 找出导致问题的具体行 2. 解释错误原因 3. 提供修复后的代码 4. 说明如何预防类似问题
重构建议模板:
分析以下代码的可维护性问题: [粘贴代码] 请提供重构方案,目标是: 1. 提高[可读性/性能/模块化] 2. 遵循[特定设计模式/编码规范] 3. 减少[重复代码/复杂度/依赖] 4. 保持原有功能不变
最佳实践示例:
// 优秀Prompt // 创建一个高效的Python函数,用于解析大型CSV文件(1GB+)中的数据。要求: // 1. 使用生成器模式处理,避免加载整个文件到内存 // 2. 支持自定义分隔符和引号字符 // 3. 实现数据类型自动推断(字符串、整数、浮点数、日期) // 4. 添加进度条显示处理进度 // 5. 处理常见CSV格式错误(缺失值、格式不一致) // 不良Prompt // 写一个Python CSV解析器
1.4 工具对比与选择指南
市场上主流智能编码工具各具特色,选择时需考虑语言支持、集成环境、定价模式等因素:
| 工具 | 核心模型 | 语言支持 | 主要特点 | 价格 | 最佳适用场景 |
|---|---|---|---|---|---|
| GitHub Copilot | OpenAI Codex | 20+种主流语言 | 与VS Code/Visual Studio深度集成,支持whole-line和multi-line建议 | 个人版\(19.99/月,企业版\)19/user/月 | 全栈开发、开源项目 |
| Tabnine | 自研模型 | 50+种语言 | 本地模式保护代码隐私,团队共享代码风格 | 免费版有限功能,专业版$12/user/月 | 企业级开发、敏感项目 |
| Amazon CodeWhisperer | Amazon Titan | 15+种语言 | AWS服务深度集成,安全漏洞检测 | 个人免费,专业版$19/user/月 | AWS云原生开发 |
| Cursor | GPT-4 | 多语言 | 支持对话式代码编辑,文件级上下文理解 | $20/月 | 复杂逻辑开发、代码审查 |
| CodeLlama | Meta Llama 2 | 主要编程语言 | 本地部署,可定制训练 | 开源免费 | 隐私敏感场景、定制需求 |
选择策略:个人开发者可从GitHub Copilot或Amazon CodeWhisperer开始;企业团队优先考虑Tabnine的团队协作功能;处理敏感数据时CodeLlama的本地部署优势明显;AI重度用户则可尝试Cursor的对话式编程体验。
二、数据标注工具:AI训练数据的质量保障
数据标注是将原始数据(图像、文本、音频等)转化为模型可学习格式的过程,直接决定AI模型的性能上限。据Gartner报告,数据标注占据AI项目60%以上的时间成本,而高质量标注可将模型准确率提升40%以上。
2.1 数据标注的核心类型与技术流程
数据标注根据AI任务类型可分为五大类,每种类型有其特定标注方法与工具需求:
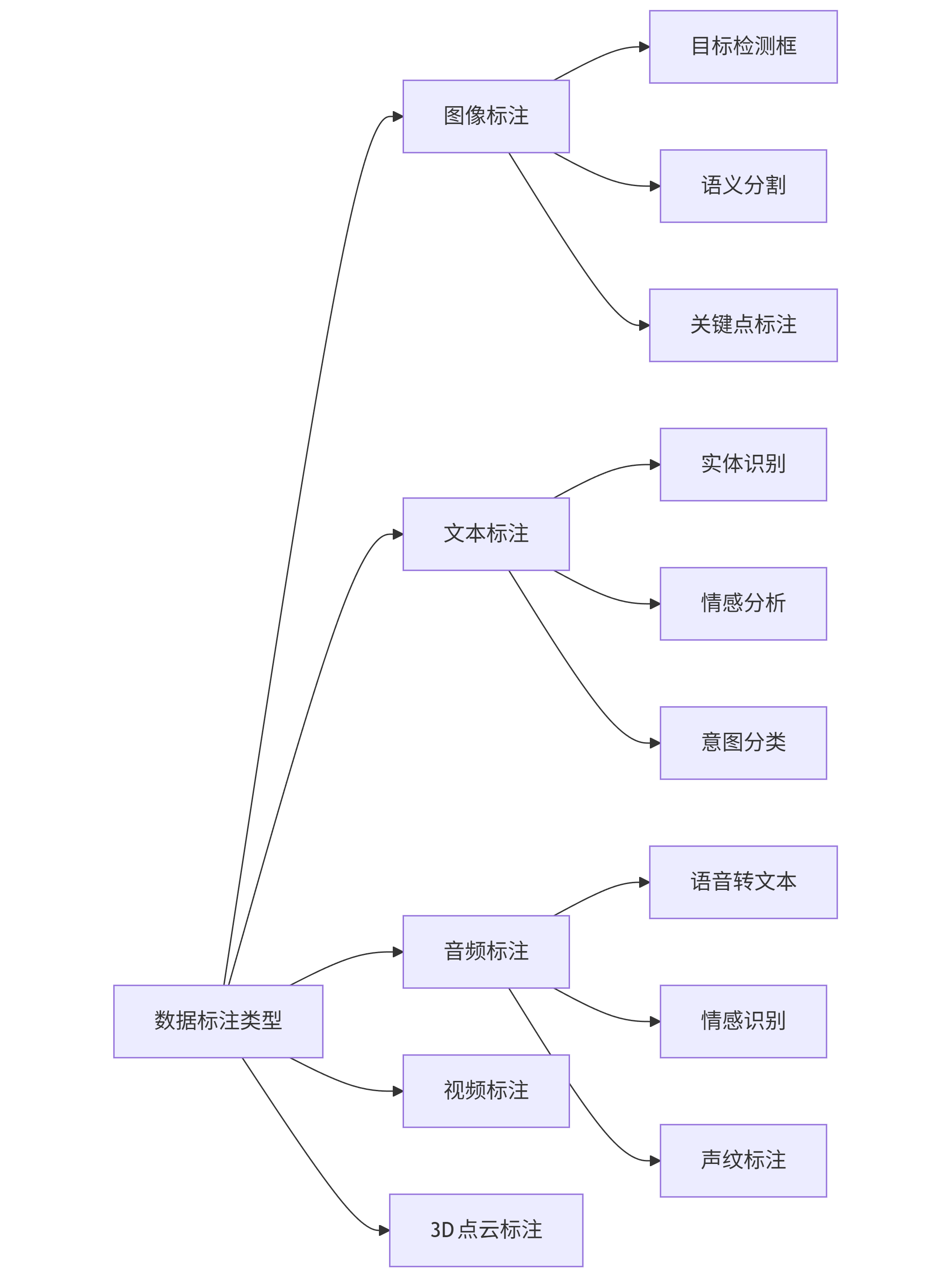
graph LR A[数据标注类型] --> B[图像标注] A --> C[文本标注] A --> D[音频标注] A --> E[视频标注] A --> F[3D点云标注] B --> B1[目标检测框] B --> B2[语义分割] B --> B3[关键点标注] C --> C1[实体识别] C --> C2[情感分析] C --> C3[意图分类] D --> D1[语音转文本] D --> D2[情感识别] D --> D3[声纹标注]
通用标注流程:
- 数据收集与预处理:清洗、去重、格式转换
- 标注规则制定:定义标签体系、标注标准、质量指标
- 标注执行:人工标注、半自动标注或自动标注
- 质量检查:抽样审核、交叉验证、冲突解决
- 数据增强:旋转、裁剪、噪声添加等扩充数据集
- 格式转换:导出为COCO、Pascal VOC、JSON等模型兼容格式
2.2 主流标注工具深度解析
2.2.1 图像标注工具
Label Studio(开源全功能平台): 支持图像、文本、音频等多类型数据标注,高度可定制化。
# Label Studio项目配置示例(image_classification.xml) <View> <Image name="image" value="$image"/> <Choices name="label" toName="image" choice="single"> <Choice value="Cat"/> <Choice value="Dog"/> <Choice value="Bird"/> <Choice value="Other"/> </Choices> </View>
使用场景:中小型团队、多模态标注需求、自定义工作流 优势:开源免费、支持本地部署、丰富的插件生态
LabelImg(轻量级目标检测标注): 专注于边界框标注,生成Pascal VOC或YOLO格式数据集。
# YOLO格式标注示例 0 0.456 0.321 0.234 0.567 1 0.789 0.654 0.123 0.456 # 格式说明: <类别ID> <中心x> <中心y> <宽度> <高度> (均为归一化值)
使用场景:快速创建目标检测数据集、学术研究 优势:轻量级、无需安装、简单易用
2.2.2 文本标注工具
Prodigy(高效NLP标注): 由spaCy背后团队开发,支持命名实体识别、文本分类等NLP任务的交互式标注。
# Prodigy文本分类标注配置 import prodigy from prodigy.components.loaders import JSONL from prodigy.components.sorters import prefer_uncertain @prodigy.recipe("text-classification") def text_classification(dataset, source): stream = JSONL(source) # 加载数据 stream = prefer_uncertain(stream) # 主动学习:优先标注模型不确定的样本 return { "dataset": dataset, "stream": stream, "view_id": "classification", # 使用分类视图 "config": { "labels": ["正面", "负面", "中性"], # 分类标签 "choice_style": "single" # 单选模式 } }
使用场景:NLP模型训练数据准备、企业级文本分析项目 优势:基于主动学习、标注效率高、与spaCy无缝集成
BRAT(学术研究级文本标注): 支持复杂实体关系、事件标注,广泛用于学术研究。
# BRAT标注格式示例(.ann文件) T1 Organization 0 7 Apple T2 Person 9 15 Jobs R1 FoundedBy Arg1:T1 Arg2:T2 # 说明:T表示实体,R表示关系
使用场景:学术论文、复杂语义关系标注 优势:支持复杂标注类型、免费开源、适合研究使用
2.3 半自动化标注技术与实现
半自动化标注通过预训练模型辅助人工标注,可将效率提升3-5倍。以下是基于Hugging Face Transformers实现的文本实体自动标注示例:
from transformers import pipeline import spacy from spacy.tokens import Doc, Span from spacy.util import filter_spans class AutoAnnotator: def __init__(self, model_name="dbmdz/bert-large-cased-finetuned-conll03-english"): # 加载预训练NER模型 self.ner_pipeline = pipeline("ner", model=model_name, aggregation_strategy="simple") # 初始化spaCy用于可视化 self.nlp = spacy.blank("en") def auto_annotate(self, text, confidence_threshold=0.8): """自动标注文本实体并返回高置信度结果""" # 使用预训练模型预测实体 ner_results = self.ner_pipeline(text) # 过滤低置信度结果 high_conf_entities = [ ent for ent in ner_results if ent["score"] >= confidence_threshold ] # 创建spaCy文档用于可视化 doc = self.nlp(text) spans = [] for ent in high_conf_entities: start = ent["start"] end = ent["end"] label = ent["entity_group"] span = Span(doc, start_char=start, end_char=end, label=label) spans.append(span) # 合并重叠跨度 filtered_spans = filter_spans(spans) doc.ents = filtered_spans return { "text": text, "entities": high_conf_entities, "spacy_doc": doc # 用于可视化 } def visualize_annotation(self, doc): """可视化标注结果""" spacy.displacy.render(doc, style="ent", jupyter=True) # 使用示例 annotator = AutoAnnotator() result = annotator.auto_annotate("""Elon Musk is the CEO of Tesla, which is an American electric vehicle and clean energy company based in Palo Alto, California.""", confidence_threshold=0.9) annotator.visualize_annotation(result["spacy_doc"])
半自动化标注工作流:
- 使用预训练模型批量处理未标注数据
- 筛选高置信度标注结果直接采纳
- 低置信度样本提交人工标注
- 使用新标注数据微调模型,迭代提升自动标注准确率
2.4 标注质量控制与评估指标
标注质量直接影响模型性能,需要建立多维度评估体系:
质量评估指标:
- 一致性率:多个标注者对同一数据标注结果的一致程度
- 准确率:标注结果与真实值的匹配程度(需有黄金标准)
- 完整性:标注覆盖所有必要信息的程度
- 效率:单位时间内完成的标注数量
质量控制机制:

graph TD A[数据分配] --> B[主要标注者标注] B --> C[抽样审核] C -->|通过| D[纳入数据集] C -->|未通过| E[二次标注] E --> F[标注者讨论] F --> G[解决冲突] G --> D A --> H[随机插入黄金样本] H --> I[计算标注者准确率] I --> J[标注者能力评估]
实现示例:计算标注一致性(Krippendorff's Alpha系数)
from sklearn.metrics import cohen_kappa_score import numpy as np def calculate_krippendorff_alpha(annotations): """ 计算Krippendorff's Alpha系数,衡量标注者间一致性 参数: annotations: 二维数组,形状为(标注者数量, 样本数量) 返回: alpha: Krippendorff's Alpha系数 """ # 简化实现,实际应用建议使用专门的统计库如 Krippendorff's alpha in `nltk` # 此处使用Cohen's Kappa作为替代(适用于2名标注者) if len(annotations) != 2: raise ValueError("此简化实现仅支持2名标注者") return cohen_kappa_score(annotations[0], annotations[1]) # 示例数据:3个样本,2名标注者的标注结果 annotator1 = [0, 1, 2, 0, 1, 1, 2, 0, 0, 1] # 标注者1的结果 annotator2 = [0, 1, 2, 0, 0, 1, 2, 0, 1, 1] # 标注者2的结果 kappa = cohen_kappa_score(annotator1, annotator2) print(f"Cohen's Kappa系数: {kappa:.4f}") # 解释:0.8以上为极好,0.6-0.8为良好,0.4-0.6为一般,0.4以下需改进
三、模型训练平台:从实验到生产的桥梁
模型训练平台提供从数据预处理、模型构建、训练监控到部署的全流程支持,降低AI开发门槛。据IDC预测,到2025年,75%的企业AI项目将依赖专用训练平台加速开发周期。
3.1 训练平台架构与核心组件
现代模型训练平台采用分布式架构,包含六大核心组件:

graph TD A[数据层] --> A1[数据湖/数据仓库] A --> A2[数据版本控制] A --> A3[数据预处理流水线] B[计算层] --> B1[CPU集群] B --> B2[GPU/TPU加速] B --> B3[分布式训练框架] C[模型层] --> C1[模型库/Model Zoo] C --> C2[超参数优化] C --> C3[模型版本管理] D[监控层] --> D1[训练指标跟踪] D --> D2[资源使用监控] D --> D3[实验对比分析] E[部署层] --> E1[模型打包] E --> E2[推理服务] E --> E3[A/B测试框架] F[协作层] --> F1[实验记录] F --> F2[团队共享] F --> F3[权限管理] A --> B B --> C C --> D C --> E A --> F D --> F
3.2 主流训练平台实战对比
3.2.1 TensorFlow Extended (TFX)
Google开源的端到端ML平台,适合大规模生产环境。
# TFX流水线定义示例 from tfx import v1 as tfx from tfx.orchestration import pipeline def create_pipeline(pipeline_name: str, pipeline_root: str, data_path: str): # 1. 数据导入组件 example_gen = tfx.components.CsvExampleGen(input_base=data_path) # 2. 数据验证组件 statistics_gen = tfx.components.StatisticsGen(examples=example_gen.outputs['examples']) schema_gen = tfx.components.SchemaGen(statistics=statistics_gen.outputs['statistics']) example_validator = tfx.components.ExampleValidator( statistics=statistics_gen.outputs['statistics'], schema=schema_gen.outputs['schema']) # 3. 特征工程组件 transform = tfx.components.Transform( examples=example_gen.outputs['examples'], schema=schema_gen.outputs['schema'], module_file='./transform.py') # 自定义特征转换逻辑 # 4. 模型训练组件 trainer = tfx.components.Trainer( module_file='./trainer.py', # 自定义训练逻辑 examples=transform.outputs['transformed_examples'], schema=schema_gen.outputs['schema'], transform_graph=transform.outputs['transform_graph'], train_args=tfx.proto.TrainArgs(num_steps=1000), eval_args=tfx.proto.EvalArgs(num_steps=100)) # 5. 模型评估组件 evaluator = tfx.components.Evaluator( examples=example_gen.outputs['examples'], model=trainer.outputs['model'], schema=schema_gen.outputs['schema'], eval_config=tfx.proto.EvalConfig( model_specs=[tfx.proto.ModelSpec(signature_name='serving_default')], metrics_specs=[ tfx.proto.MetricsSpec( metrics=[ tfx.proto.MetricConfig( class_name='AUC', threshold=tf.compat.v1.metrics.Threshold(value=0.5)), tfx.proto.MetricConfig( class_name='Precision', threshold=tf.compat.v1.metrics.Threshold(value=0.5)), tfx.proto.MetricConfig( class_name='Recall', threshold=tf.compat.v1.metrics.Threshold(value=0.5)) ]) ], slicing_specs=[tfx.proto.SlicingSpec()])) # 整体数据评估 # 6. 模型推送组件(满足条件时) pusher = tfx.components.Pusher( model=trainer.outputs['model'], model_blessing=evaluator.outputs['blessing'], push_destination=tfx.proto.PushDestination( filesystem=tfx.proto.PushDestination.Filesystem( base_directory='./serving_model'))) # 创建并返回流水线 return pipeline.Pipeline( pipeline_name=pipeline_name, pipeline_root=pipeline_root, components=[ example_gen, statistics_gen, schema_gen, example_validator, transform, trainer, evaluator, pusher ])
适用场景:大规模生产环境、Google Cloud用户、TensorFlow生态使用者 优势:完整的生产级功能、强大的数据验证、与GCP深度集成
3.2.2 PyTorch Lightning
轻量级PyTorch封装,专注于简化训练流程。
# PyTorch Lightning模型训练示例 import torch import torch.nn as nn import torch.nn.functional as F from torch.utils.data import DataLoader, random_split from torchvision import datasets, transforms import pytorch_lightning as pl from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping class LitCNN(pl.LightningModule): def __init__(self, num_classes=10, learning_rate=1e-3): super().__init__() self.save_hyperparameters() # 自动保存超参数 # 定义模型架构 self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1) self.pool = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(64 * 7 * 7, 128) self.fc2 = nn.Linear(128, num_classes) # 定义指标 self.train_acc = pl.metrics.Accuracy() self.val_acc = pl.metrics.Accuracy() self.test_acc = pl.metrics.Accuracy() def forward(self, x): # 推理逻辑 x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 7 * 7) x = F.relu(self.fc1(x)) x = self.fc2(x) return x def training_step(self, batch, batch_idx): x, y = batch logits = self(x) loss = F.cross_entropy(logits, y) # 记录训练指标 preds = torch.argmax(logits, dim=1) self.train_acc(preds, y) self.log('train_loss', loss, prog_bar=True) self.log('train_acc', self.train_acc, prog_bar=True) return loss def validation_step(self, batch, batch_idx): x, y = batch logits = self(x) loss = F.cross_entropy(logits, y) # 记录验证指标 preds = torch.argmax(logits, dim=1) self.val_acc(preds, y) self.log('val_loss', loss, prog_bar=True) self.log('val_acc', self.val_acc, prog_bar=True) def test_step(self, batch, batch_idx): x, y = batch logits = self(x) preds = torch.argmax(logits, dim=1) self.test_acc(preds, y) self.log('test_acc', self.test_acc, prog_bar=True) def configure_optimizers(self): optimizer = torch.optim.Adam(self.parameters(), lr=self.hparams.learning_rate) return optimizer # 数据模块 class MNISTDataModule(pl.LightningDataModule): def __init__(self, data_dir='./data', batch_size=64): super().__init__() self.data_dir = data_dir self.batch_size = batch_size self.transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) def prepare_data(self): # 下载数据(只在一个进程中执行) datasets.MNIST(self.data_dir, train=True, download=True) datasets.MNIST(self.data_dir, train=False, download=True) def setup(self, stage=None): # 分割训练集和验证集 if stage == 'fit' or stage is None: mnist_full = datasets.MNIST(self.data_dir, train=True, transform=self.transform) self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000]) # 测试集 if stage == 'test' or stage is None: self.mnist_test = datasets.MNIST(self.data_dir, train=False, transform=self.transform) def train_dataloader(self): return DataLoader(self.mnist_train, batch_size=self.batch_size, shuffle=True, num_workers=4) def val_dataloader(self): return DataLoader(self.mnist_val, batch_size=self.batch_size, num_workers=4) def test_dataloader(self): return DataLoader(self.mnist_test, batch_size=self.batch_size, num_workers=4) # 训练模型 def train(): # 初始化数据模块 dm = MNISTDataModule(batch_size=64) # 初始化模型 model = LitCNN(num_classes=10, learning_rate=1e-3) # 定义回调 checkpoint_callback = ModelCheckpoint( monitor='val_acc', mode='max', save_top_k=3, dirpath='checkpoints/', filename='mnist-cnn-{epoch:02d}-{val_acc:.2f}' ) early_stopping_callback = EarlyStopping( monitor='val_acc', patience=5, mode='max' ) # 初始化训练器 trainer = pl.Trainer( max_epochs=20, gpus=1 if torch.cuda.is_available() else 0, callbacks=[checkpoint_callback, early_stopping_callback], logger=pl.loggers.TensorBoardLogger('tb_logs/', name='mnist_cnn'), progress_bar_refresh_rate=20 ) # 训练 trainer.fit(model, datamodule=dm) # 测试 trainer.test(model, datamodule=dm) if __name__ == '__main__': train()
适用场景:学术研究、快速原型开发、PyTorch用户 优势:代码简洁、减少样板代码、灵活度高
3.2.3 云平台训练服务
AWS SageMaker、Google AI Platform等云服务提供托管式训练环境:
# AWS SageMaker训练作业提交示例 import sagemaker from sagemaker.pytorch import PyTorch # 初始化SageMaker会话 sess = sagemaker.Session() role = sagemaker.get_execution_role() # 获取IAM角色 # 定义训练作业 estimator = PyTorch( entry_point='train.py', # 训练脚本 source_dir='./code', # 代码目录 role=role, framework_version='1.8.1', py_version='py3', instance_count=2, # 使用2个实例 instance_type='ml.p3.2xlarge', # GPU实例 hyperparameters={ 'epochs': 10, 'batch-size': 64, 'learning-rate': 0.001 }, distribution={ 'pytorchddp': { 'enabled': True # 启用分布式训练 } } ) # 开始训练 estimator.fit({'training': 's3://my-bucket/training-data/'}) # 部署模型为端点 predictor = estimator.deploy( initial_instance_count=1, instance_type='ml.m5.xlarge' ) # 推理示例 import numpy as np test_data = np.random.randn(1, 1, 28, 28).astype(np.float32) response = predictor.predict(test_data) print(f"预测结果: {np.argmax(response)}")
适用场景:企业级应用、无基础设施管理需求、弹性扩展需求 优势:无需管理硬件、内置分布式训练、与云服务生态集成
3.3 超参数优化与实验跟踪
超参数优化能显著提升模型性能,以下是使用Optuna进行超参数搜索的示例:
import optuna import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader from torchvision import datasets, transforms # 定义目标函数 def objective(trial): # 定义超参数搜索空间 lr = trial.suggest_float('lr', 1e-5, 1e-1, log=True) batch_size = trial.suggest_categorical('batch_size', [32, 64, 128]) hidden_size = trial.suggest_int('hidden_size', 32, 256, step=32) dropout = trial.suggest_float('dropout', 0.1, 0.5) optimizer_name = trial.suggest_categorical('optimizer', ['Adam', 'SGD', 'RMSprop']) # 数据加载 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) val_dataset = datasets.MNIST('./data', train=False, download=True, transform=transform) val_loader = DataLoader(val_dataset, batch_size=batch_size) # 模型定义 model = nn.Sequential( nn.Flatten(), nn.Linear(28*28, hidden_size), nn.ReLU(), nn.Dropout(dropout), nn.Linear(hidden_size, 10) ) # 优化器 if optimizer_name == 'Adam': optimizer = optim.Adam(model.parameters(), lr=lr) elif optimizer_name == 'SGD': optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9) else: optimizer = optim.RMSprop(model.parameters(), lr=lr) criterion = nn.CrossEntropyLoss() # 训练 model.train() for epoch in range(3): # 简化训练,实际应用可增加epoch for batch_idx, (data, target) in enumerate(train_loader): optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() # 验证 model.eval() correct = 0 with torch.no_grad(): for data, target in val_loader: output = model(data) pred = output.argmax(dim=1, keepdim=True) correct += pred.eq(target.view_as(pred)).sum().item() accuracy = correct / len(val_loader.dataset) return accuracy # 创建优化研究 study = optuna.create_study(direction='maximize', study_name='mnist-hp-search') study.optimize(objective, n_trials=20) # 运行20次试验 # 打印最佳结果 best_trial = study.best_trial print(f"最佳准确率: {best_trial.value:.4f}") print("最佳超参数:") for key, value in best_trial.params.items(): print(f" {key}: {value}") # 可视化优化过程(需要安装plotly) optuna.visualization.plot_optimization_history(study) optuna.visualization.plot_param_importances(study)
实验跟踪工具对比:
| 工具 | 核心功能 | 集成性 | 优势 | 适用场景 |
|---|---|---|---|---|
| TensorBoard | 指标可视化、模型图、嵌入投影 | TensorFlow/PyTorch | 功能全面、使用广泛 | 独立研究、小团队 |
| Weights & Biases | 实验跟踪、超参数比较、团队协作 | 多框架支持 | 直观界面、协作功能强 | 团队项目、企业级 |
| MLflow | 实验跟踪、模型管理、部署 | 多框架支持 | 开源、可本地部署 | 数据科学团队、合规要求高 |
| Neptune | 实验记录、模型注册、结果比较 | 多框架支持 | 高度可定制、API丰富 | 研究实验室、大型团队 |
3.4 分布式训练与性能优化
分布式训练通过多设备并行加速模型训练,主流策略包括数据并行和模型并行:
# PyTorch分布式数据并行示例 import torch import torch.distributed as dist import torch.nn as nn import torch.optim as optim from torch.nn.parallel import DistributedDataParallel as DDP from torch.utils.data.distributed import DistributedSampler import torchvision import torchvision.transforms as transforms import os def setup(rank, world_size): """初始化分布式环境""" os.environ['MASTER_ADDR'] = 'localhost' os.environ['MASTER_PORT'] = '12355' # 初始化进程组 dist.init_process_group("nccl", rank=rank, world_size=world_size) def cleanup(): """清理分布式环境""" dist.destroy_process_group() class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(torch.relu(self.conv1(x))) x = self.pool(torch.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x def train(rank, world_size): setup(rank, world_size) # 创建模型并移动到GPU model = Net().to(rank) # 包装为DDP模型 ddp_model = DDP(model, device_ids=[rank]) # 数据加载 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) dataset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=transform) # 使用DistributedSampler确保每个进程获取不同的数据样本 sampler = DistributedSampler(dataset, shuffle=True) dataloader = torch.utils.data.DataLoader( dataset, batch_size=32, sampler=sampler) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(ddp_model.parameters(), lr=0.001, momentum=0.9) # 训练循环 for epoch in range(2): # 简化示例,实际应更多epoch sampler.set_epoch(epoch) # 确保每个epoch的shuffle不同 running_loss = 0.0 for i, data in enumerate(dataloader, 0): inputs, labels = data[0].to(rank), data[1].to(rank) optimizer.zero_grad() outputs = ddp_model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() if i % 2000 == 1999: # 每2000个批次打印一次 print(f'[{epoch + 1}, {i + 1}] loss: {running_loss / 2000:.3f}') running_loss = 0.0 print('Finished Training') cleanup() def main(): world_size = 2 # 使用2个GPU torch.multiprocessing.spawn(train, args=(world_size,), nprocs=world_size, join=True) if __name__ == '__main__': main()
性能优化策略:
- 混合精度训练:使用FP16/FP32混合精度减少内存占用和计算时间
# PyTorch AMP自动混合精度示例 scaler = torch.cuda.amp.GradScaler() for inputs, labels in dataloader: optimizer.zero_grad() with torch.cuda.amp.autocast(): outputs = model(inputs) loss = criterion(outputs, labels) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()
- 梯度累积:模拟大批次训练,减少内存使用
# 梯度累积示例 accumulation_steps = 4 # 累积4个小批次的梯度 for i, (inputs, labels) in enumerate(dataloader): outputs = model(inputs) loss = criterion(outputs, labels) loss = loss / accumulation_steps # 归一化损失 loss.backward() if (i + 1) % accumulation_steps == 0: optimizer.step() optimizer.zero_grad()
- 数据预处理优化:使用多线程、预加载和缓存
# 优化的数据加载器配置 dataloader = DataLoader( dataset, batch_size=64, num_workers=4, # 使用4个工作进程 pin_memory=True, # 将数据固定到内存,加速GPU传输 prefetch_factor=2, # 预加载下一批数据 persistent_workers=True # 保持工作进程 alive )
四、未来趋势与综合应用
AI开发工具正朝着低代码化、智能化和集成化方向发展。据McKinsey预测,到2025年,AI开发周期将缩短40%,80%的企业AI应用将通过低代码平台构建。
4.1 工具链集成与MLOps实践
现代AI开发需要打通从数据到部署的全流程,MLOps(机器学习运维)应运而生:
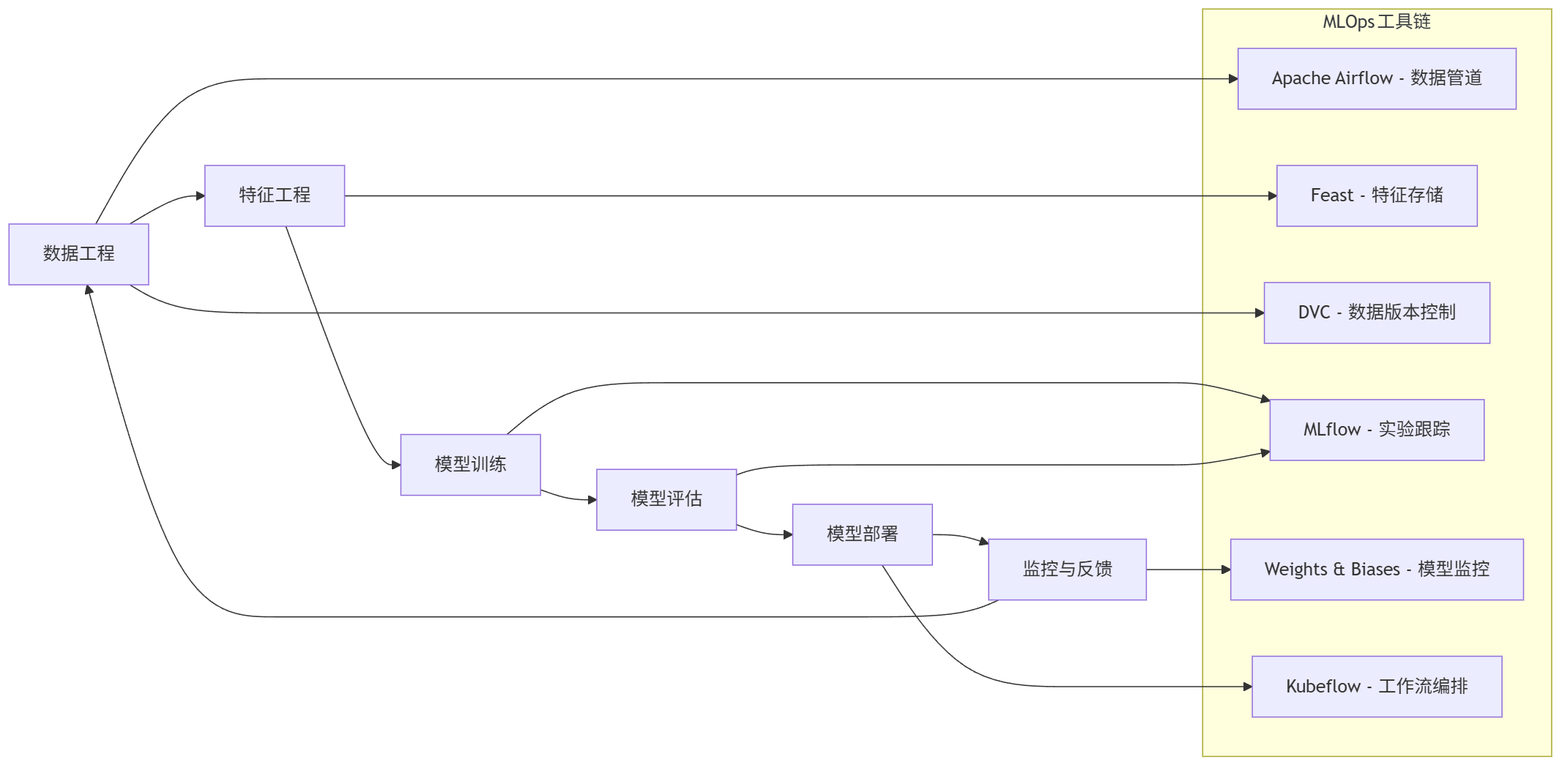
graph LR A[数据工程] --> B[特征工程] B --> C[模型训练] C --> D[模型评估] D --> E[模型部署] E --> F[监控与反馈] F --> A subgraph MLOps工具链 A1[Apache Airflow - 数据管道] A2[Feast - 特征存储] A3[DVC - 数据版本控制] B1[MLflow - 实验跟踪] B2[Weights & Biases - 模型监控] B3[Kubeflow - 工作流编排] end A --> A1 A --> A3 B --> A2 C --> B1 D --> B1 E --> B3 F --> B2
MLOps最佳实践:
- 版本控制:使用DVC跟踪数据版本,Git跟踪代码和配置
- 自动化流水线:使用GitHub Actions或GitLab CI/CD实现训练部署自动化
- 模型注册表:集中管理模型版本、元数据和部署状态
- 监控预警:实时监控模型性能、数据漂移和服务健康度
- 持续改进:建立模型再训练触发机制,基于反馈持续优化
4.2 多模态智能开发平台
下一代AI开发平台将整合文本、图像、音频等多模态数据处理能力:
# 多模态模型开发示例(使用Hugging Face Transformers) from transformers import ViTImageProcessor, AutoTokenizer, VisionEncoderDecoderModel import torch from PIL import Image import requests from io import BytesIO class MultimodalModel: def __init__(self, model_name="nlpconnect/vit-gpt2-image-captioning"): # 加载图像处理器 self.image_processor = ViTImageProcessor.from_pretrained(model_name) # 加载文本tokenizer self.tokenizer = AutoTokenizer.from_pretrained(model_name) # 加载多模态模型 self.model = VisionEncoderDecoderModel.from_pretrained(model_name) # 设置设备 self.device = "cuda" if torch.cuda.is_available() else "cpu" self.model.to(self.device) def generate_caption(self, image_url, max_length=16, num_beams=4): """从图像URL生成描述文本""" # 下载图像 response = requests.get(image_url) image = Image.open(BytesIO(response.content)).convert("RGB") # 处理图像 pixel_values = self.image_processor( images=image, return_tensors="pt" ).pixel_values.to(self.device) # 生成文本描述 output_ids = self.model.generate( pixel_values, max_length=max_length, num_beams=num_beams, return_dict_in_generate=True, output_scores=True ).sequences # 解码文本 caption = self.tokenizer.decode(output_ids[0], skip_special_tokens=True) return caption # 使用示例 if __name__ == "__main__": model = MultimodalModel() image_url = "https://upload.wikimedia.org/wikipedia/commons/thumb/3/3a/Cat03.jpg/1200px-Cat03.jpg" caption = model.generate_caption(image_url) print(f"图像描述: {caption}") # 输出可能为: "a cat sitting on a couch next to a remote control"
4.3 低代码AI开发平台
低代码平台通过可视化界面和模块化组件,让非专业开发者也能构建AI应用:
低代码平台核心特性:
- 拖拽式界面设计
- 预构建AI组件库
- 自动化数据处理
- 一键部署与监控
- 内置模板与最佳实践
主流低代码AI平台:
- Microsoft Power AI:与Office生态深度集成,适合企业用户
- Google Vertex AI:端到端低代码ML平台,与GCP服务无缝衔接
- DataRobot:专注于预测性分析的AutoML平台
- H2O.ai:开源低代码平台,适合技术团队
- OutSystems:专注于AI应用开发的全栈低代码平台
4.4 前沿技术与挑战
AI开发工具面临的关键挑战:
- 模型可解释性:黑盒模型的决策过程难以解释,限制关键领域应用
- 数据隐私保护:如何在不暴露原始数据的情况下进行模型训练(联邦学习、差分隐私)
- 计算资源成本:大模型训练需要巨额计算资源,限制创新
- 技术碎片化:工具生态分散,集成难度大
- 人才缺口:AI工具操作需要跨学科知识,专业人才稀缺
未来技术方向:
- AI辅助AI开发:模型自动设计、调试和优化
- 边缘设备训练:在手机、IoT设备上进行本地化训练
- 绿色AI:降低模型训练和推理的能源消耗
- 可信AI:内置公平性、透明度和鲁棒性保障
- 个性化工具:根据开发者习惯自动调整的智能开发环境
结语:智能工具链重塑AI开发生态
从GitHub Copilot的代码补全到Label Studio的精准标注,再到PyTorch Lightning的训练加速,AI开发工具正在重构软件与模型开发的全流程。这些工具不仅提升效率,更降低了AI技术门槛,让创新不再受限于技术能力。
未来的AI开发将是人机协作的新纪元——开发者专注于问题定义与创意设计,智能工具则处理重复性工作。选择合适的工具组合,掌握Prompt工程与自动化流程设计,将成为AI时代开发者的核心竞争力。
当我们站在AI开发的新起点,思考的不应仅是如何使用工具,更是如何让工具成为创意与现实之间的桥梁。在这场技术变革中,真正的价值不在于工具本身,而在于我们如何利用这些工具解决从未解决的问题,创造从未想象的可能。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 14
14 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)