
极连AI 2026 最新价格解读:9 款顶级模型全线降价,Claude路线低至 1 折
在大模型 API 成本依然高企的 2026 年,个人开发者和小团队想要稳定调用 Claude、GPT 等旗舰能力,往往面临一个现实困境:官方价格贵、中间商掺水、性能不透明。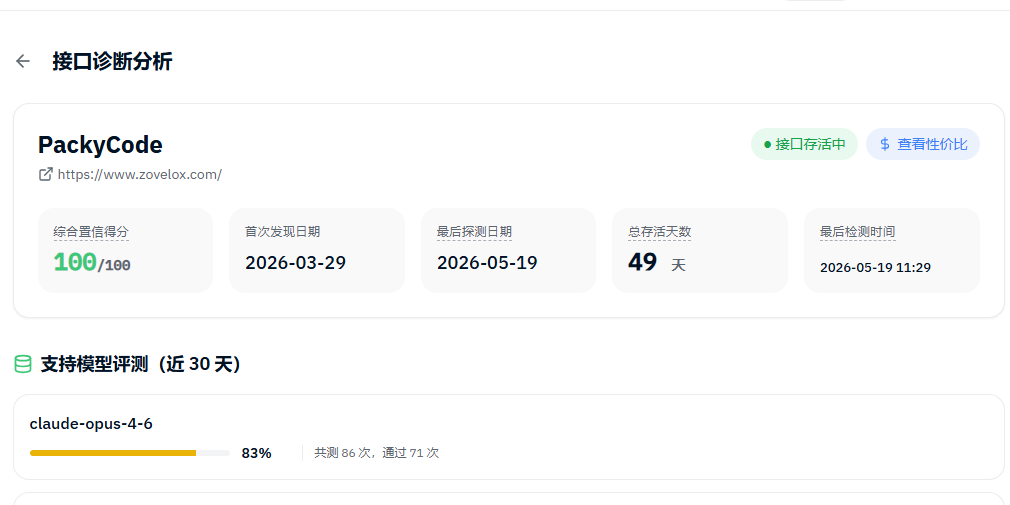
极连AI(zovelox.com) 的最新一轮价格调整,直接把这个问题解决了——目前平台已接入 Anthropic 4 款 + OpenAI 5 款 共 9 个模型,全部按量计费、无预存门槛,且公开标注了延迟、吞吐、性价比标签和分组路由。本文基于平台最新模型广场数据,做一次全景式解读。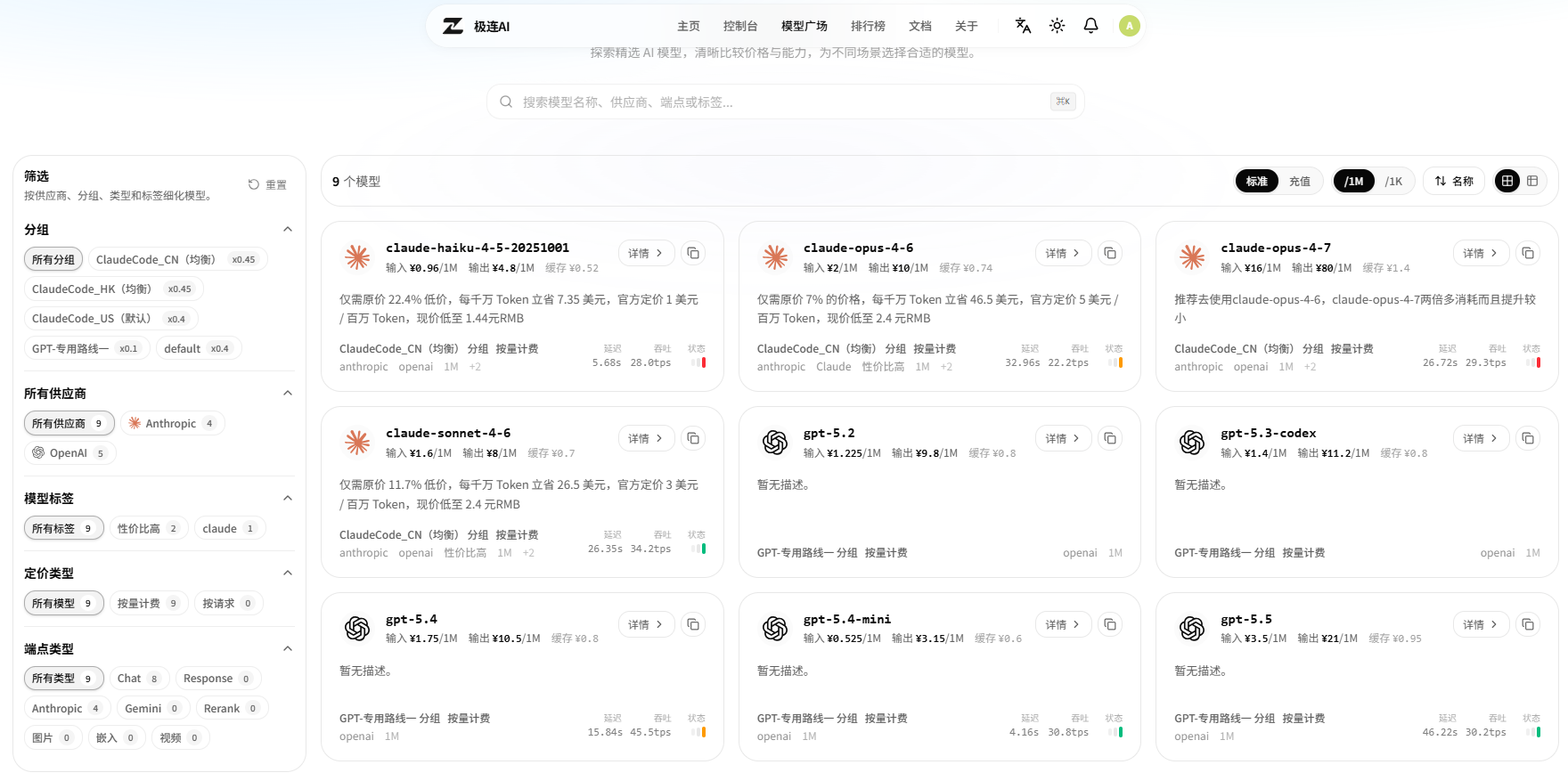
一、平台定位:透明化的高性价比聚合接口
极连AI 的核心逻辑很简单:官方直连,不掺水,价格打到底,性能数据全公开。
平台目前提供 5 条分组路由,覆盖不同网络场景:
| 分组名称 | 折扣系数 | 适用场景 |
|---|---|---|
| ClaudeCode_US(默认) | x0.4 | 默认路由,通用场景 |
| ClaudeCode_CN(均衡) | x0.45 | 国内均衡线路,延迟更稳定 |
| ClaudeCode_HK(均衡) | x0.45 | 香港均衡节点,适合跨境业务 |
| GPT-专用路线一 | x0.1 | GPT 系列专属,价格最低 |
| default | x0.4 | 通用 fallback |
所有模型均为 按量计费,没有预存门槛,用多少付多少。每个模型卡片直接标注了 延迟(秒)、吞吐(tps) 和 性价比标签,省去了开发者自己测试对比的成本。
二、Claude 系列:4 款模型,从入门到旗舰全覆盖
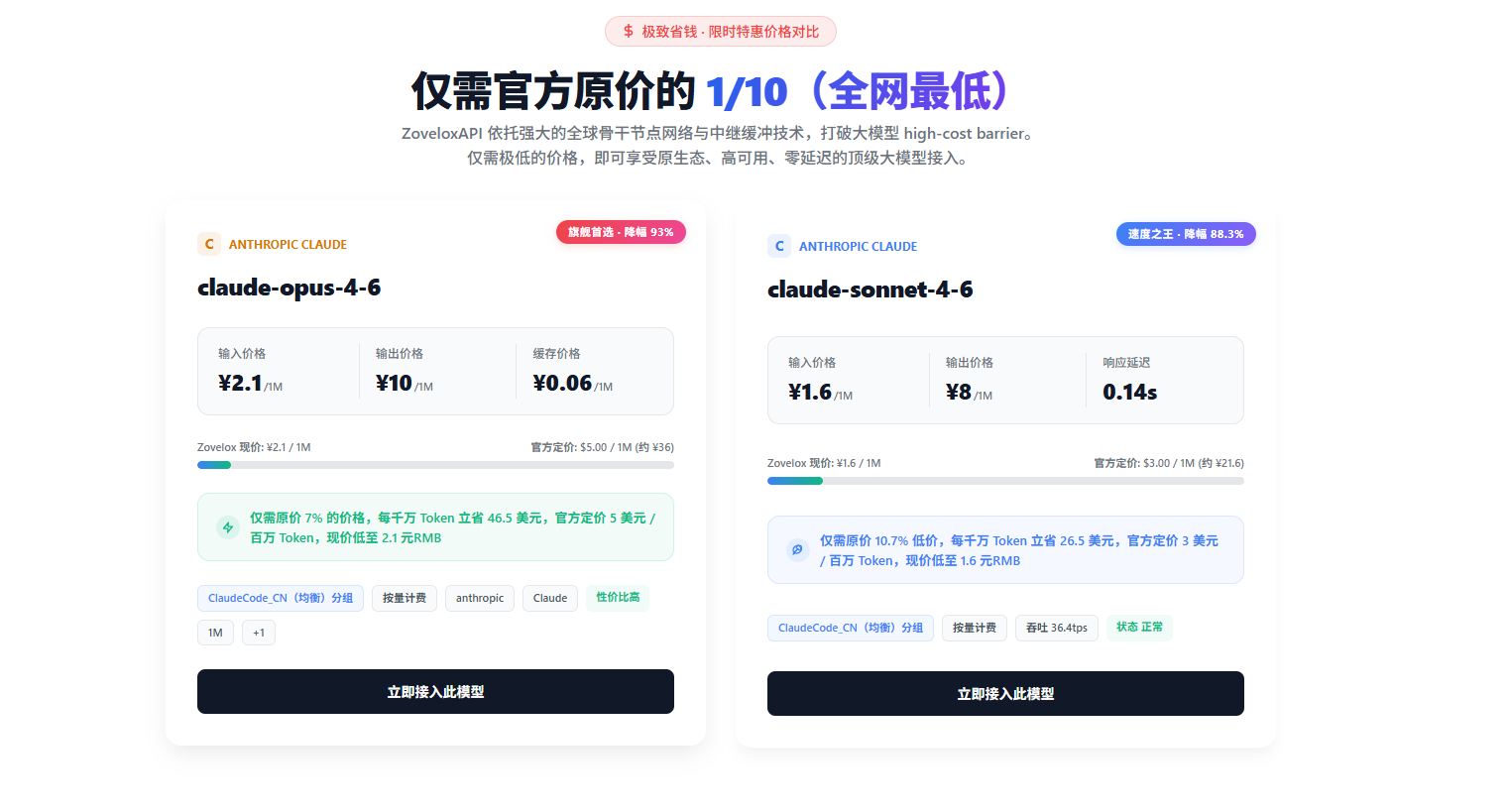
Anthropic 的 Claude 模型以推理、编码和长文本处理能力著称,但官方定价一直偏高。极连AI 这次把 Claude 全系列的价格做到了 原价 7%~22.4% 不等。
1. Claude Opus 4.6 —— 旗舰能力,仅需原价 7%
| 指标 | 官方定价 | 极连AI 定价 | 折扣 |
|---|---|---|---|
| 输入 | $5 / 百万 Token | ¥2 / 百万 Token | 7% |
| 输出 | $25 / 百万 Token | ¥10 / 百万 Token | 7% |
| 缓存 | - | ¥0.74 | - |
| 延迟 | - | 2.96s | - |
| 吞吐 | - | 22.2 tps | - |
每使用 1 千万 Token,直接省下约 46.5 美元(约 335 元人民币)。
作为 Anthropic 当前最强模型,Opus 4.6 在复杂推理、代码审计、长文档分析等场景下表现顶级。32.96 秒的延迟和 22.2 tps 的吞吐,对于非实时批量任务完全可接受。如果你需要最强性能且对成本敏感,这是目前市面上性价比最高的旗舰模型入口。
2. Claude Sonnet 4.6 —— 闭眼入的"性价比之王"
| 指标 | 官方定价 | 极连AI 定价 | 折扣 |
|---|---|---|---|
| 输入 | $3 / 百万 Token | ¥1.6 / 百万 Token | 11.7% |
| 输出 | $15 / 百万 Token | ¥8 / 百万 Token | 11.7% |
| 缓存 | - | ¥0.7 | - |
| 延迟 | - | 2.40s | - |
| 吞吐 | - | 34.2 tps | - |
平台标注的 "性价比高" 标签模型。Sonnet 4.6 在能力和速度之间取得了最佳平衡,34.2 tps 的吞吐比 Opus 4.6 更快,延迟也更低。每千万 Token 立省 26.5 美元,适合日常开发、内容生成、自动化运维等高频调用场景。
3. Claude Haiku 4.5 —— 轻量任务首选
| 指标 | 官方定价 | 极连AI 定价 | 折扣 |
|---|---|---|---|
| 输入 | $1 / 百万 Token | ¥0.96 / 百万 Token | 22.4% |
| 输出 | - | ¥4.8 / 百万 Token | - |
| 缓存 | - | ¥0.52 | - |
| 延迟 | - | 1.68s | - |
| 吞吐 | - | 28.0 tps | - |
延迟仅 1.68 秒,是 Claude 系列中响应最快的模型。虽然能力不及 Opus/Sonnet,但面对简单问答、文本分类、轻量摘要等任务,Haiku 4.5 的速度和成本优势非常明显。每千万 Token 可省 7.35 美元。
4. Claude Opus 4.7 —— 谨慎选择
| 指标 | 极连AI 定价 |
|---|---|
| 输入 | ¥16 / 百万 Token |
| 输出 | ¥80 / 百万 Token |
| 缓存 | ¥1.4 |
| 延迟 | 2.72s |
| 吞吐 | 29.3 tps |
平台官方建议:推荐去使用 Claude Opus 4.6。 4.7 版本的输入/输出成本是 4.6 的 8 倍,但能力提升有限。除非你对 4.7 的某个特定优化点有强需求,否则从成本角度不建议优先选择。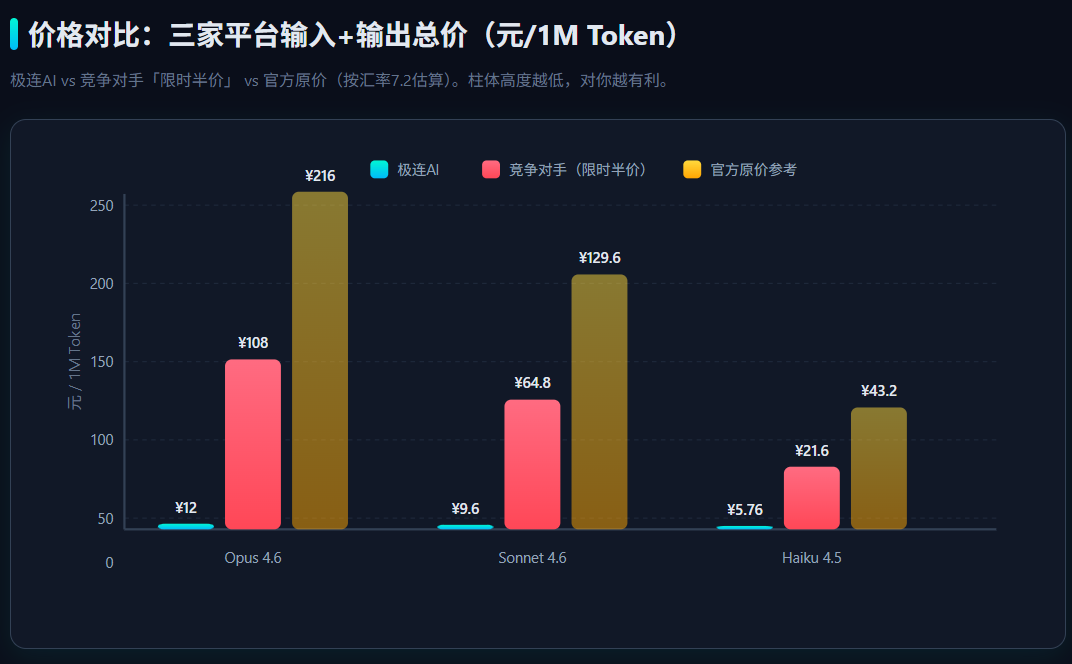
三、GPT 系列:5 款模型,专用路线低至 1 折
OpenAI 的 GPT 系列通过 "GPT-专用路线一" 接入,折扣系数仅为 x0.1,是目前平台价格最低的线路。
1. GPT-5.5 —— 当前最强,但成本最高
| 指标 | 极连AI 定价 |
|---|---|
| 输入 | ¥3.5 / 百万 Token |
| 输出 | ¥21 / 百万 Token |
| 缓存 | ¥0.95 |
| 延迟 | 2.22s |
| 吞吐 | 32.2 tps |
GPT-5.5 是 OpenAI 系列的旗舰,延迟 46.22 秒、吞吐 30.2 tps,适合对生成质量要求极高、可接受较长等待时间的任务(如深度报告生成、复杂代码架构设计)。
2. GPT-5.4 —— 均衡之选
| 指标 | 极连AI 定价 |
|---|---|
| 输入 | ¥1.75 / 百万 Token |
| 输出 | ¥10.5 / 百万 Token |
| 缓存 | ¥0.8 |
| 延迟 | 3.84s |
| 吞吐 | 45.5 tps |
吞吐高达 45.5 tps,是 GPT 系列中速度最快的模型。输入 ¥1.75、输出 ¥10.5 的定价,在 GPT 家族中属于"甜点区"——能力接近 5.5,但成本减半,速度翻倍。适合中高并发的产品化场景。
3. GPT-5.4-mini —— 极速轻量,成本最低
| 指标 | 极连AI 定价 |
|---|---|
| 输入 | ¥0.525 / 百万 Token |
| 输出 | ¥3.15 / 百万 Token |
| 缓存 | ¥0.6 |
| 延迟 | 4.16s |
| 吞吐 | 30.8 tps |
全平台价格最低的模型,输入不到 6 毛钱/百万 Token。延迟仅 4.16 秒,是 9 款模型中响应最快的。虽然能力有所精简,但对于聊天机器人、简单文本处理、原型验证等场景,这个成本几乎等同于"免费试用"官方 GPT 能力。
4. GPT-5.3-codex —— 代码专用
| 指标 | 极连AI 定价 |
|---|---|
| 输入 | ¥1.4 / 百万 Token |
| 输出 | ¥11.2 / 百万 Token |
| 缓存 | ¥0.8 |
从命名看,Codex 系列主打代码生成与理解。¥1.4/1M 的输入定价,比 GPT-5.4 更便宜,适合以代码补全、代码审查、技术文档生成为主的开发工作流。
5. GPT-5.2 —— 基础入门
| 指标 | 极连AI 定价 |
|---|---|
| 输入 | ¥1.225 / 百万 Token |
| 输出 | ¥9.8 / 百万 Token |
| 缓存 | ¥0.8 |
GPT-5.2 是 GPT 系列的基础款,输入 ¥1.225/1M,输出 ¥9.8/1M,适合对模型版本不敏感、追求稳定低成本调用的用户。
四、横向对比:怎么选模型最划算?
为了帮你快速决策,我把 9 款模型按 "能力-成本-速度" 三维度做了归类:
| 需求场景 | 推荐模型 | 理由 |
|---|---|---|
| 最强推理/代码审计 | Claude Opus 4.6 | 旗舰能力,7% 原价,延迟可接受 |
| 日常高频调用 | Claude Sonnet 4.6 | 性价比标签,2.2 tps 高速,成本适中 |
| 极速轻量响应 | Claude Haiku 4.5 / GPT-5.4-mini | 延迟 < 2秒,成本极低 |
| 高并发产品化 | GPT-5.4 | 45.5 tps 全平台最高吞吐 |
| 深度复杂任务 | GPT-5.5 / Claude Opus 4.6 | 顶级能力,可承受高延迟 |
| 代码专用 | GPT-5.3-codex | 命名即定位,输入成本友好 |
| 极致省钱 | GPT-5.4-mini | 输入 ¥0.525/1M,全平台最低 |
五、总结:谁适合用极连AI?
-
个人开发者:没有预存门槛,按量计费,几块钱就能调用 Claude Opus 和 GPT-5.5,做 side project 不再有成本焦虑。
-
小团队/初创公司:通过 ClaudeCode_CN/HK 均衡线路或 GPT 专用路线,可以稳定接入官方模型,省去自己搭代理和维护节点的成本。
-
企业降本:如果现有业务已经在用官方 API,迁移到极连AI 后,Claude 系列可省 90% 以上,GPT 系列通过专用路线也有极大折扣空间。
平台数据全透明、模型不掺水、分组路由清晰——这三点是目前很多中间商平台做不到的事。
如果你正在为大模型 API 成本发愁,或者想找一个稳定、便宜、不折腾的聚合接口,直接去 zovelox.com 的模型广场看看,按需选模型,用多少付多少,没有套路。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)