
DeepSeek V4 真没炸,但我劝你一定要试试
DeepSeek V4 好用吗?我的真实感受:没那么炸,但很值得用
最近试了一圈 DeepSeek V4,我的感受比较明确:它不是那种一上来就让人觉得“行业又被改写了”的模型,但它确实把 DeepSeek 重新拉回了一线竞争区。
如果你期待的是“拳打所有闭源模型、碾压所有开源模型”,那可能会失望。但如果你关心的是:模型能不能真正用起来、成本能不能压下来、Agent 场景能不能跑得更稳,那 DeepSeek V4 其实很值得认真看一看。
我的结论是:
DeepSeek V4 没有神化的必要,但它是一个非常实用、非常有竞争力的版本。尤其是 V4-Flash,可能会成为很多人日常 AI 工作流里的默认选择。
一、它没有“炸裂”,但确实回到一线了
先说最直观的体感。
DeepSeek V4 不是那种让人第一次用就觉得“完全不是一个时代”的模型。它没有带来特别强烈的震撼感,也没有在所有维度上明显甩开其他模型。
但它的综合表现已经很稳。
在国产和开源模型里,它明显属于第一梯队。和最顶尖的闭源模型相比,它可能还有一些差距,尤其是在极复杂推理、长链路任务稳定性、工具调用判断等方面。但这次更新至少说明一件事:DeepSeek 没有掉队,它重新回到了核心竞争区。
我觉得这点比“炸不炸”更重要。
因为大模型发展到现在,已经不是每次发布都能靠一个单点突破震撼所有人。越往后,竞争越依赖综合工程能力:模型架构、训练效率、推理成本、上下文长度、工具调用、Agent 适配、生态接入,这些东西共同决定了一个模型到底好不好用。
DeepSeek V4 给我的感觉就是:它不浮夸,但很扎实。
二、真正重要的是:百万上下文开始变得日常化
这次我最在意的不是跑分,而是 1M 上下文。

百万上下文听起来像是一个参数,但它对实际使用的影响非常大。
以前很多任务并不是模型“不会做”,而是上下文不够,或者处理成本太高。比如:
| 使用场景 | 过去的问题 | 百万上下文的价值 |
|---|---|---|
| 长文档分析 | 文档切片后容易遗漏关键信息 | 可以一次性塞入更多材料 |
| 多文件代码理解 | 跨文件关系很难完整保留 | 更适合做项目级分析 |
| 研究报告生成 | 资料多了之后容易丢上下文 | 能维持更完整的信息链 |
| Agent 自动办公 | 任务跑久了容易忘记前文 | 更适合长流程执行 |
| 企业知识库问答 | 检索片段容易割裂 | 更容易形成整体判断 |
我一直觉得,Agent 能不能真正普及,一个关键点就是长上下文能不能便宜、稳定、可持续地使用。
因为 Agent 不是简单问答,它需要持续理解任务背景、保留历史状态、调用工具、处理多轮反馈。如果上下文太短,Agent 就会频繁丢信息;如果上下文很贵,普通用户和小团队又用不起。
所以 DeepSeek V4 把百万上下文放进相对低成本的模型里,这件事比单纯跑分更有意义。
它不是在解决一个炫技问题,而是在补 Agent 普及所需要的基础设施。
三、价格看起来不一定最低,但实际成本可能很香
单看 API 价格表,DeepSeek V4 Pro 不一定是最便宜的那个。
但我现在越来越觉得,看模型成本不能只看“每百万 token 单价”。真正重要的是:完成同一个任务到底花多少钱。
这里面有几个因素:
- 模型是否容易跑偏;
- 是否需要多次重试;
- 是否能一次性读完更多上下文;
- 是否能减少人为拆分文档的成本;
- 是否能用更便宜的版本完成大部分普通任务;
- 工具调用和 Agent 流程是否稳定。
有些模型单价看起来低,但任务做得不稳,需要反复补充提示、反复重试,最后总成本并不低。相反,如果一个模型单价略高,但一次就能做完,实际反而更省。
DeepSeek V4 给我的感觉就是这种类型:不能只看标价,要看最终任务完成成本。
尤其是 V4-Flash,很值得单独拿出来说。
更关键的是,现在 DeepSeek 已经开始把价格打下来了。
按照最新价格说明,DeepSeek 还把全系列模型输入缓存命中的价格降到了首发价格的 1/10。这个调整对长上下文和 Agent 场景很关键,因为很多任务会反复使用相同的系统提示词、项目背景、工具说明和文档结构,一旦缓存命中,后续调用的输入成本就会被明显压低。
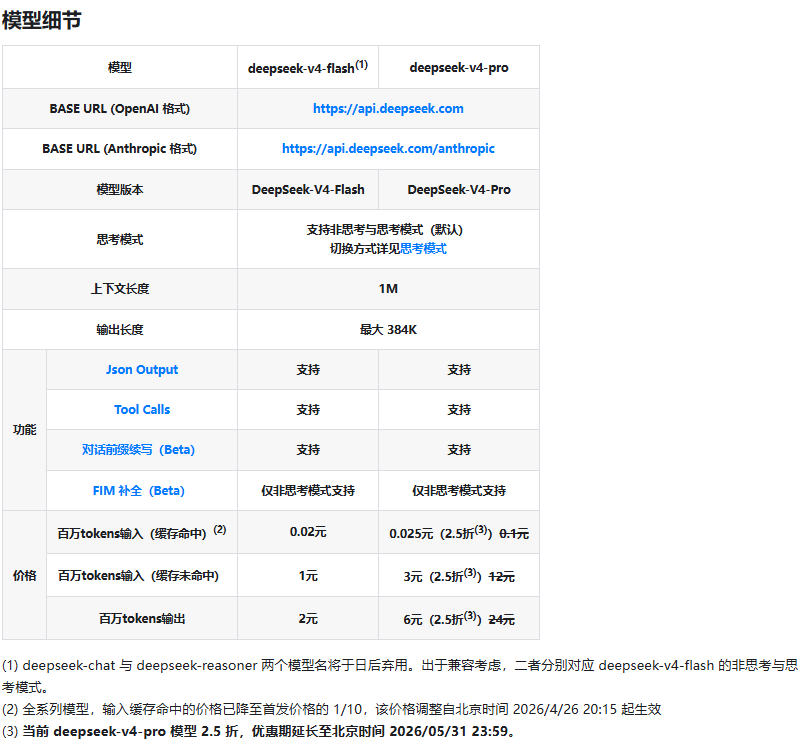
另外,deepseek-v4-pro 当前有 2.5 折限时优惠,活动持续到北京时间 2026 年 5 月 31 日 23:59。折后价格里,V4-Pro 的百万 tokens 输入价格,缓存命中是 0.025 元,缓存未命中是 3 元,百万 tokens 输出是 6 元;而 V4-Flash 的百万 tokens 输入价格,缓存命中是 0.02 元,缓存未命中是 1 元,百万 tokens 输出是 2 元。
所以这次降价不是简单的“便宜一点”,而是更像在鼓励大家把 DeepSeek V4 放进真实工作流里用:长文档、多轮任务、代码仓库分析、自动化办公、Agent 调用,都能更容易跑起来。
我的判断是:
DeepSeek V4 真正想打的不是单次调用价格,而是长上下文和 Agent 工作流的总体使用成本。
这也是为什么我觉得它的性价比不能只看表面价格。对于轻量聊天来说,感知可能没那么强;但一旦进入高频调用、长上下文、多步骤任务场景,V4-Flash 加缓存优惠的组合,就会变得非常有吸引力。
四、V4-Flash 可能是这次最值得用的版本
很多人看到 Flash,会默认理解成“低配版”。
但我这次用下来,觉得 V4-Flash 并不是传统意义上的“凑合能用”。在很多普通任务里,它和 Pro 的差距没有想象中那么明显。
比如:
- 日常问答;
- 文案改写;
- 内容总结;
- 资料整理;
- 简单办公任务;
- 基础 Agent 流程;
- 普通中文写作。
这些任务用 Flash 基本已经很够了。
当然,如果是复杂推理、竞赛编程、数学题、多步骤规划、严肃代码审查,Pro 还是更稳。但大部分日常场景,其实不一定需要一上来就用 Pro。
我现在比较推荐的策略是:
| 任务类型 | 推荐选择 |
|---|---|
| 日常聊天、摘要、改写 | V4-Flash |
| 中文写作、办公材料 | V4-Flash |
| 简单 Agent 任务 | V4-Flash |
| 长文档初筛 | V4-Flash |
| 复杂推理 | V4-Pro |
| 代码审查和工程任务 | V4-Pro |
| 多文档深度研究 | V4-Pro |
| 数学、算法、竞赛类任务 | V4-Pro |
简单说就是:
能用 Flash 的地方先用 Flash,真的不够再切 Pro。
这会是一个很实用的成本控制方式。
五、DeepSeek V4 更应该放进 Agent 里测
如果只是把 DeepSeek V4 当聊天模型用,可能感知不会特别强。
但如果把它接入 Agent 工具、代码助手、自动化办公流程,价值会更明显。
因为 V4 这次比较值得关注的方向,本来就不是单轮对话,而是:
- 长上下文;
- 工具调用;
- 多步骤任务;
- 自动化流程;
- 代码和办公结合;
- 文档理解与报告生成。
我觉得现在测一个模型,不能只问它几个知识题,也不能只看它写一段文案漂不漂亮。真正要测的是:它能不能完成任务。
比如可以这样测:
- 给它一组资料,让它整理成报告;
- 给它一个代码仓库,让它分析结构和潜在问题;
- 给它一个复杂需求,让它拆分任务并执行;
- 让它调用工具生成文件、表格、报告;
- 让它在长上下文中持续追踪目标。
这些场景更能看出 DeepSeek V4 的真实水平。
不过,我也确实感觉到一个问题:它在“什么时候该主动调用工具”这件事上,还不是每次都足够主动。有些任务如果不明确提示,它可能会先用普通回答解决,而不是主动进入工具流程。
这不是 DeepSeek 一家的问题,很多模型都有类似情况。但对于 Agent 场景来说,这是一个很关键的能力。
未来的模型竞争,一定不只是比谁会聊天,而是比谁更会完成任务。
六、不要神化一次发布,也不要低估长期趋势
很多人对 DeepSeek 有一种很高的期待:每次都要惊艳,每次都要改写行业,每次都要让所有人重新排队。
但我觉得这种期待并不太现实。
大模型行业已经进入了一个又重又长的阶段。越往后,突破越难,成本越高,不确定性也越大。没有任何团队能每次发布都“四两拨千斤”。
所以我更愿意把 DeepSeek V4 看成一次长期积累的结果,而不是一次单点奇迹。
它说明的是:
- 国产模型继续在前沿位置追赶;
- 开源路线仍然有很强生命力;
- 长上下文正在成为基础能力;
- Agent 生态会继续被低成本模型推动;
- AI 模型竞争会越来越依赖工程效率和生态适配。
也就是说,DeepSeek V4 不一定改变了行业格局,但它参与了行业格局正在改变的过程。
这次发布里,我最喜欢的一句话反而不是关于参数、跑分或者价格,而是发布会结尾那句:
不诱于誉,不恐于诽,率道而行,端然正己。
这句话放在 DeepSeek 身上其实挺合适的。
今天的 AI 行业太容易被情绪裹挟了。模型一发布,要么被捧上天,要么被踩到底;跑分高一点就是“封神”,体感没那么炸就是“不行了”。但真正做长期技术的人,最重要的恰恰不是被掌声推着走,也不是被质疑吓退,而是知道自己要解决什么问题,然后持续往前走。
所以我觉得,DeepSeek V4 最值得看的地方,不是它有没有满足所有人的幻想,而是它有没有沿着正确方向继续推进。
从这个角度看,V4 是一次很典型的“长期主义式更新”:没有那么戏剧化,但方向很清楚;不一定让所有人惊呼,但确实把长上下文、Agent、成本和开源生态往前推了一步。
七、谁适合现在就用 DeepSeek V4?
我觉得下面几类人可以尽快试试:
1. 经常处理长文档的人
如果你经常要读报告、论文、合同、会议纪要、产品文档,百万上下文的价值会很明显。
2. 做内容和研究的人
写文章、做选题、整理资料、生成分析报告,DeepSeek V4 的中文能力和长上下文都很有帮助。
3. 用 Agent 工具的人
如果你已经在用代码助手、自动化办公工具、AI 工作流平台,那 V4 值得接进去测试。
4. 对成本敏感的开发者
尤其是 V4-Flash,可能会成为很多中低复杂度任务的高性价比选择。
5. 中文办公需求比较多的人
在中文表达、资料整理、报告生成这类任务上,DeepSeek V4 的体感比较自然。
八、谁没必要焦虑?
如果你只是偶尔问问问题、写几句文案、让 AI 帮你改个标题,那其实不用太焦虑。
DeepSeek V4 很值得试,但它不是那种“不用就落后一个时代”的东西。
如果你已经有稳定好用的模型组合,也不想折腾 API 和工具配置,那完全可以先观望。
我的建议是:
有 Agent 需求、长文档需求、成本优化需求的人,值得马上试。
只是轻度聊天和日常问答的人,不用因为它发布就急着切换。
最后总结:DeepSeek V4 的关键词是“实用”
如果要给 DeepSeek V4 一个评价,我不会说它“颠覆”,也不会说它“封神”。
我会说它:实用、稳健、性价比高,而且方向很对。
它最值得关注的地方不是某个单点能力,而是把几个关键能力组合到了一起:
- 1M 长上下文;
- 更强的 Agent 适配;
- 更好的中文办公能力;
- 可用的 Flash 版本;
- 相对友好的调用成本;
- 开源生态里的持续竞争力。
所以,DeepSeek V4 好用吗?
我的答案是:
好用,但不用神化。
它不是所有场景的最强模型,但很可能是当前中文长上下文、Agent 工作流和高性价比 API 场景里,非常值得尝试的选择。
我的使用建议
最后给一个比较直接的模型选择建议:
-
日常任务优先用 V4-Flash
摘要、改写、写作、资料整理,Flash 基本够用。 -
复杂任务再上 V4-Pro
代码、推理、数学、多文档深度分析,更适合 Pro。 -
重点测试 Agent 场景
不要只拿它聊天,最好放进真实工作流里测。 -
不要只看单价
要看任务完成成本、重试次数和稳定性。 -
保持交叉验证
重要任务不要只依赖一个模型,尤其是涉及事实、代码和决策的内容。
DeepSeek V4 不是一个需要被膜拜的模型,但它确实是一个值得认真使用的模型。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)