
别再吹 AI 写代码了!AI 程序员是个伪命题!
写在前面
今天给程序员同行们缓解一下焦虑啊。本月四号,也就是三月四号,中山大学和阿里联合发布了一份实验报告,报告表明AI闭卷考试一把好手,一到真实工程迭代就露怯。
论文地址:https://arxiv.org/pdf/2603.03823

这篇论文没整花活,直接拉着 18 个主流模型熬了 233 天、烧掉 100 亿 token,用一套贴近现实的 CI 流程狠狠测了一波长期维护能力。结果很扎心:大部分 AI 根本不是靠谱程序员,只是高级 “救火临时工”,越迭代越崩,技术债堆得比代码还快。
一、老评测太假,只考单次修复不算本事
现在 HumanEval、SWE-bench 这类基准全是 “一锤子买卖”,修好一个 bug 就算通关,完全不管后续迭代。可真实开发是持续演进的,需求会变、依赖会变、代码要兼容历史版本。论文直接戳破泡沫:能单次修 bug≠会写代码,静态评测根本反映不了真实水平。
![]()
为此作者搞出 SWE-CI 基准,用 100 个真实项目、平均 233 天演进史、71 次提交,把 AI 编程从 “快照式测评” 拉到 “长期演化赛道”,还用上双 agent 架构模拟真实 CI/CD 流程。
二、核心指标:零回归率与 EvoScore 见真章
SWE-CI 直接把评估门槛从 “能跑通” 拉高到 “可维护”,两个指标尤为关键:零回归率和EvoScore。零回归率代表不搞崩原有功能的能力,结果惨不忍睹 —— 绝大多数模型不到 25%,改 4 次崩 3 次是常态。
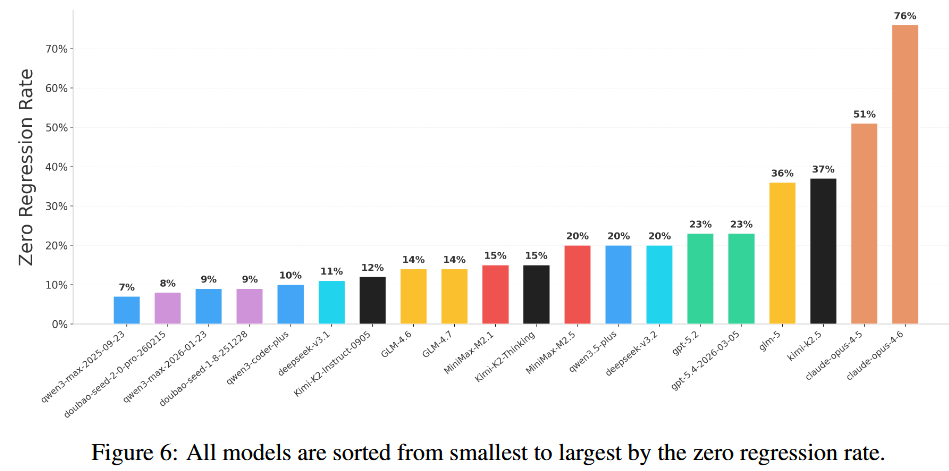
EvoScore 则侧重长期演化质量,专门惩罚只顾眼前、堆技术债的短视行为。实验显示,随着迭代推进,70% 的 AI 都在疯狂制造技术债,后期直接雪崩式崩盘,完全扛不住长周期项目。
三、模型梯队:Claude 独一档,国产 GLM 很能打
18 个模型测下来,差距直接拉开:Claude 4.5/4.6 是唯一零回归率超 50% 的选手,架构思维和稳定性一骑绝尘。国产 GLM-5 表现亮眼,稳稳跻身第一梯队。
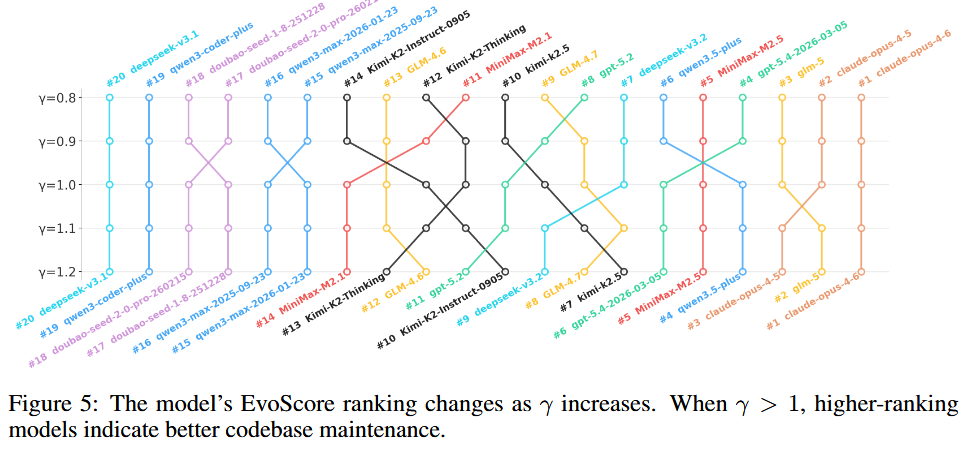
不同模型风格也泾渭分明:Kimi、GLM 偏激进救火,见效快但透支未来;GPT、DeepSeek 更谨慎,有架构意识;Claude、Qwen 等则全能稳健,长短兼顾。整体看,2026 年主流模型在长期代码维护上依旧短板明显,离可用还差得远。
四、AI 崩掉的真相:只顾眼前,记不住全局
AI 在长周期维护拉胯,原因很现实:一是只追求短期通过测试,不做全局架构设计;二是多轮迭代后上下文遗忘,对早期变更影响失控;三是真实项目依赖复杂、配置多变,远超训练数据覆盖范围。
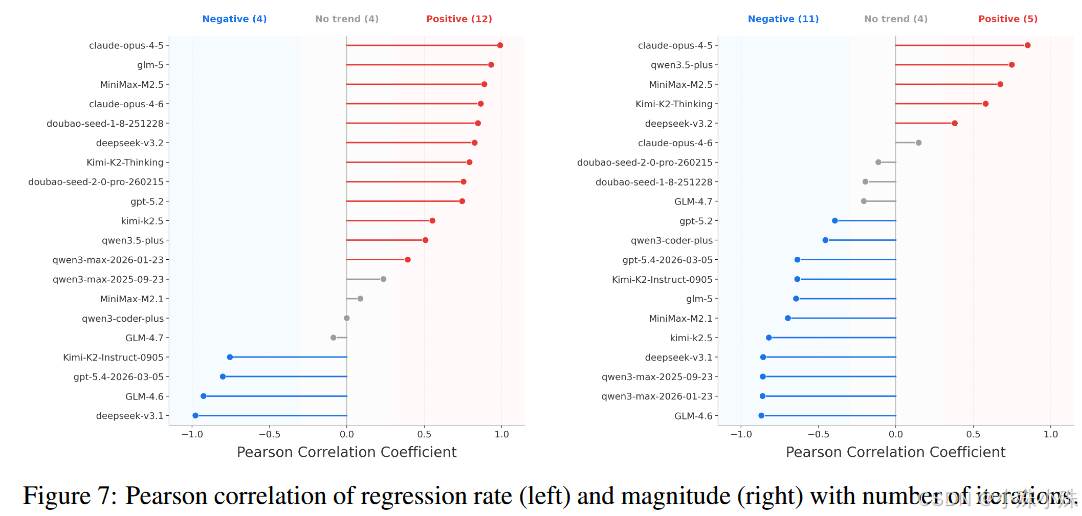
这篇论文说白了就是一盆冷水:AI 想真正进工程流水线,先过了长期可维护这关,别再拿单次跑分忽悠人了。
当下AI程序员仍是伪命题,但它绝非无用。作为编程工具,AI能高效完成基础编码、辅助查错,实实在在提升编程效率,当好程序员的“得力助手”就够出彩。
关注不迷路(*^▽^*),暴富入口==》 https://bbs.csdn.net/topics/619691583

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)