
Java AI - 基于Ollama、Spring AI、Redis、ElasticSearch实现本地RAG知识库【含源码】
RAG
什么是RAG
简单说,RAG(检索增强生成)是让 AI “先查资料再作答” 的技术,核心是解决大模型 “记不住新信息、容易说胡话” 的问题。
核心逻辑
- 先检索:AI 接到问题后,不直接凭 “记忆” 回答,而是先去指定的知识库(比如公司文档、最新新闻、专业资料)里找相关信息。
- 再生成:把找到的精准资料和自身知识结合,整理成自然语言回答,既保证准确性,又不脱离模型本身的语言能力。

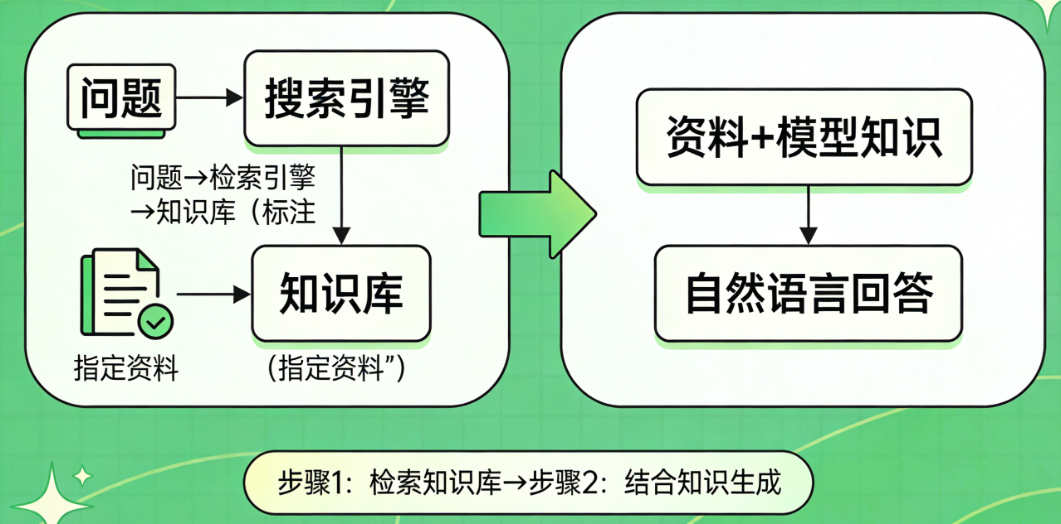
关键价值
- 解决 “知识过期”:大模型的训练数据有截止时间,RAG 能实时调取新信息(比如 2025 年的行业数据、刚发布的政策)。
- 降低 “幻觉率”:基于真实资料作答,减少 AI 编造不存在的事实、数据或逻辑。
- 支持 “专属知识”:可以接入企业内部文档、个人笔记等私域数据,让 AI 只围绕指定内容回答(比如公司产品手册、行业专属规范)。

举个实际例子
你问 AI “2025 年某行业的最新政策要求”,但 AI 的训练数据只到 2023 年:
- 没有 RAG:AI 可能会说 “没有相关信息”,或编造过时的政策。
- 有 RAG:AI 会先去检索 2025 年该行业的官方政策文件、权威解读,再基于这些真实资料,整理出清晰的政策要点和合规建议。
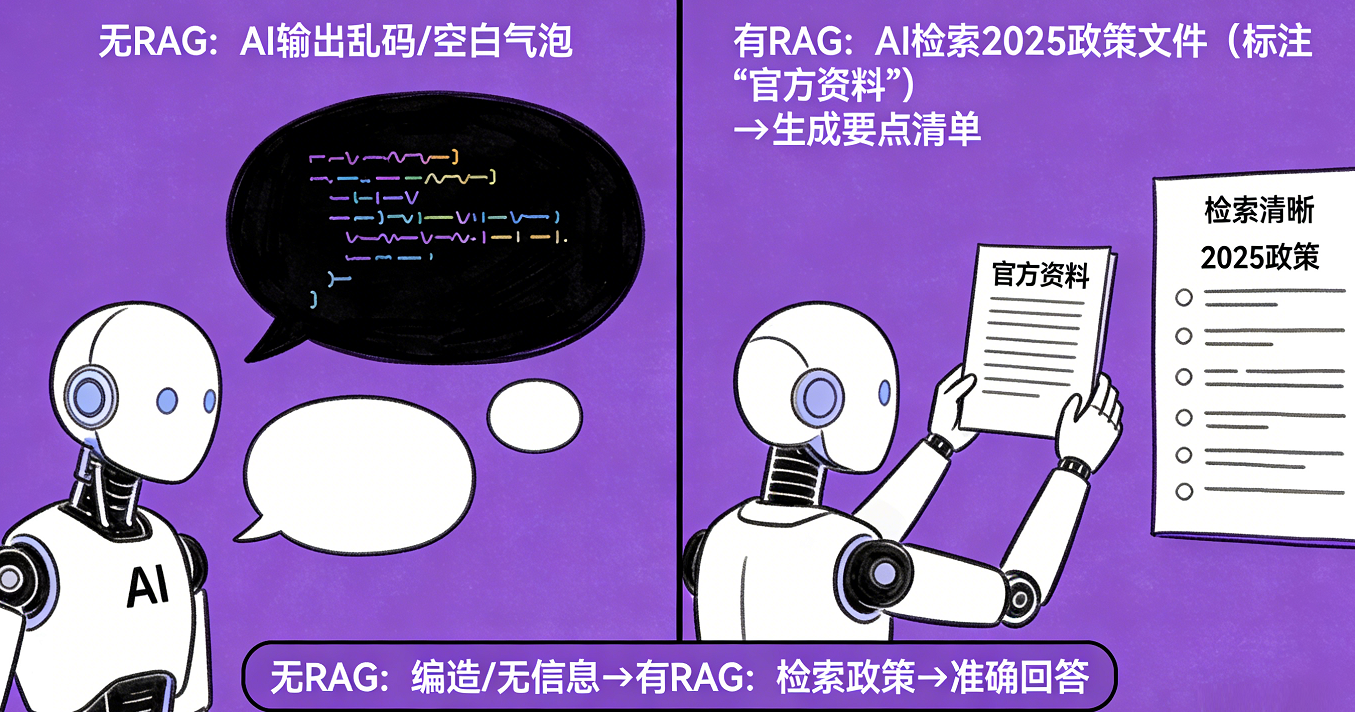
应用场景

以下是 RAG(检索增强生成)的 8 个典型应用场景,覆盖企业、生活、学习等核心领域:
- 企业内部知识库问答
- 核心用法:接入公司内部文档(员工手册、产品手册、流程规范、历史项目资料),员工提问时,AI 实时检索相关文档给出精准答案。
- 例子:新员工问 “报销流程和限额”,AI 直接调取最新报销规范,分步骤说明材料要求、审批节点;销售问 “某产品的技术参数”,快速检索产品手册给出对应信息。
- 智能客服(ToB/ToC)
- 核心用法:关联产品 FAQ、售后手册、用户反馈记录,客户咨询时,AI 检索匹配问题的解决方案,避免重复回复或答非所问。
- 例子:用户问 “家电保修范围”,AI 检索对应产品的保修政策,明确质保期限、免责条款;企业客户问 “API 接口调用限制”,调取技术文档给出具体参数和解决办法。
- 行业动态与政策解读
- 核心用法:接入行业权威网站、政府政策平台、最新研究报告,实时检索最新信息,帮助用户快速掌握动态。
- 例子:创业者问 “2025 年小微企业税收优惠政策”,AI 检索税务总局最新文件,整理优惠条件、申报流程;从业者问 “AI 行业最新监管要求”,汇总近期政策要点和合规建议。
- 学术科研与论文辅助
- 核心用法:对接学术数据库(知网、万方、SCI 论文库)、行业研究成果,科研人员提问时,检索相关文献、数据和研究结论。
- 例子:研究生问 “某算法的最新改进方向”,AI 检索近 3 年相关论文,总结主流改进思路和实验效果;医生问 “某疾病的最新治疗方案”,调取权威医学期刊的研究成果和临床指南。
- 个人私域知识管理
- 核心用法:接入个人笔记(Notion、备忘录)、阅读过的文章、收藏的资料,打造专属 “私人知识库”,快速检索记忆模糊的信息。
- 例子:你问 “之前收藏的 Excel 数据透视表教程”,AI 检索个人收藏文档,提取关键操作步骤;想回忆 “某本书的核心观点”,调取读书笔记给出提炼总结。
- 金融 /法律等专业领域咨询
- 核心用法:接入行业法规、案例库、市场数据,为专业咨询提供精准依据,避免主观判断。
- 例子:律师问 “某类合同纠纷的胜诉案例”,AI 检索相似司法案例,整理判决要点和法律依据;投资者问 “某股票的最新财务数据和行业对比”,调取财经平台数据给出客观分析。
- 产品说明书与使用指导
- 核心用法:关联产品电子版说明书、常见故障排查手册,用户遇到使用问题时,实时检索解决方案。
- 例子:用户问 “智能音箱怎么连接 WiFi”,AI 检索对应型号说明书,分步骤给出操作指引;程序员问 “某软件的函数用法”,调取开发文档给出语法示例和注意事项。
- 新闻资讯与热点汇总
- 核心用法:接入主流新闻平台、权威媒体账号,实时检索特定主题的最新资讯,自动汇总关键信息。
- 例子:你问 “近期某赛事的赛况和结果”,AI 检索最新报道,整理赛程、比分、核心亮点;关注 “某地区的天气预警”,调取气象部门实时信息,给出预警等级和应对建议。
步骤解析
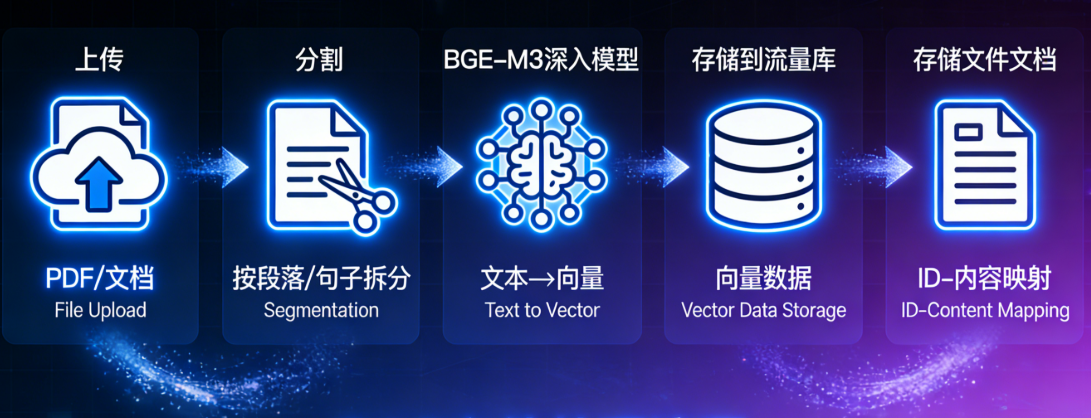
- 文件上传
这是 RAG 文件处理的起始步骤,核心是接收、校验用户上传的文件,同时完成基础的预处理
- 文件接收:基于 Spring Boot 的MultipartFile组件实现文件上传接口,支持的文件类型一般包括 TXT、PDF、DOCX、MD 等常见的文本类文档,也可以扩展支持 PPTX、XLSX(需要提取其中的文本内容)
- 文件校验:
- 校验文件大小,避免过大文件占用资源
- 校验文件格式,拒绝非允许的文件类型
- 校验文件的完整性,避免损坏的文件
- 预处理:将文件的元信息(文件名、文件大小、上传时间、文件唯一标识)存储到关系型数据库(比如 MySQL)中,方便后续和向量数据做关联
- 文档分割
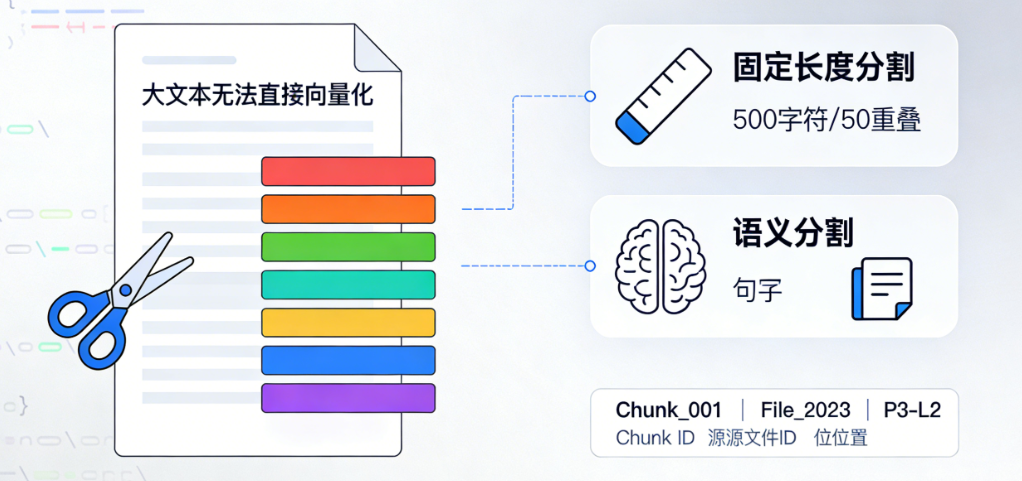
这一步是为了解决大文本无法直接进行向量化的问题(大模型的上下文窗口有限),同时提升后续检索的精准度
- 核心逻辑:将完整的文档,按照一定的规则切割为多个小的文本片段(Chunk)
- 常用分割策略:
- 按固定长度分割:比如每 500 个字符为一个 Chunk,同时设置一定的重叠长度(比如 50 个字符),避免切割到完整的语义单元
- 按语义分割:借助 Ollama 的本地大模型,或者 Spring AI 的语义分割工具,按照句子、段落的语义完成分割,这种方式可以避免切断完整的语义
- 处理细节:为每个分割后的 Chunk 生成唯一 ID,同时记录这个 Chunk 所属的源文件 ID、Chunk 在源文件中的位置信息,方便后续溯源
- 向量化
将分割后的文本片段,转换为计算机可以理解的向量数据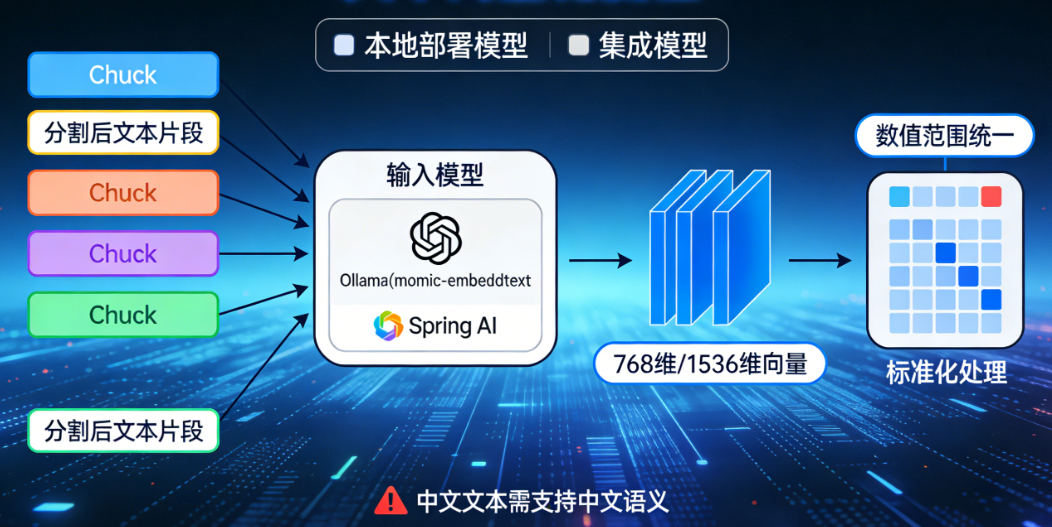
- 工具选择:可以选择 Ollama 部署的本地嵌入模型(比如nomic-embed-text),或者 Spring AI 集成的嵌入模型
- 处理流程:
- 读取分割后的文本 Chunk
- 将文本传入嵌入模型,模型会将文本转换为固定维度的向量(比如 768 维、1536 维)
- 对生成的向量做标准化处理,保证向量的数值范围统一
- 注意事项:如果是中文文本,需要确保嵌入模型支持中文语义的理解,避免向量无法准确表达文本语义
- 向量库存储
将生成的向量数据存储到向量数据库中,用于后续的相似性检索
- 工具选择:你用到的 Elasticsearch 8.0 + 版本已经支持向量存储和向量检索,可以直接使用
- 存储流程:
- 在 Elasticsearch 中创建专门的索引,设置向量字段的类型为dense_vector,指定向量的维度(和嵌入模型生成的向量维度保持一致)
- 将每个 Chunk 的向量、Chunk 的唯一 ID、源文件 ID 等信息,写入到 Elasticsearch 的索引中
- 优化操作:可以为 Elasticsearch 的向量索引设置合适的分片和副本数,提升检索的性能
- 文档对应关系存储
建立源文件、文本 Chunk、向量数据之间的关联关系,保证检索结果可以溯源到源文件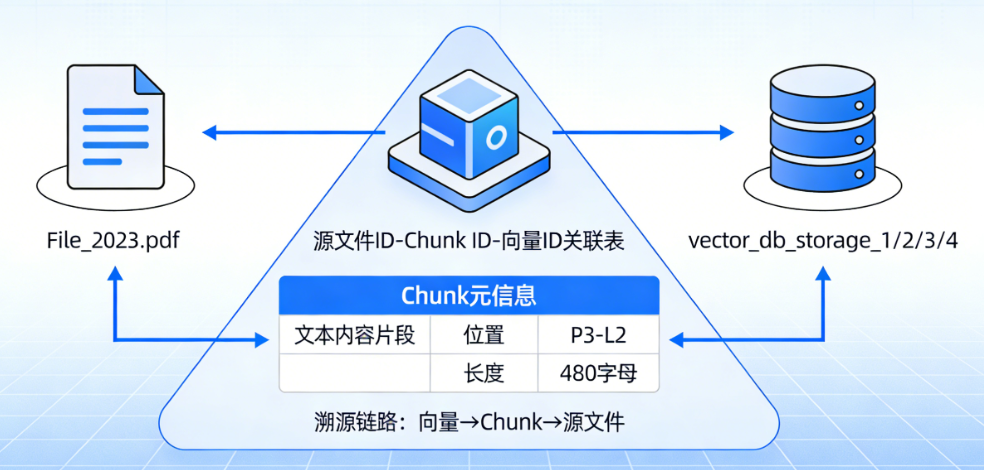
- 存储内容:
- 在关系型数据库中,维护源文件 ID、Chunk ID、向量 ID 的对应关系
- 同时存储 Chunk 的元信息:比如 Chunk 的文本内容、Chunk 在源文件中的位置、Chunk 的长度等
- 作用:当后续检索到相关的向量时,可以通过这个对应关系,找到对应的 Chunk 文本,以及这个 Chunk 所属的源文件,最终可以将源文件的完整内容返回给用户
向量化
在 RAG 技术(以及整个大模型应用领域)中,向量化(Vectorization) 本质是将非结构化的文本信息转换为计算机可理解、可计算的数值向量的过程,可以把它理解为给每一段文本生成一串 “数字身份证”,这串数字能精准表达文本的语义、情感、逻辑等核心特征。
一、为什么需要向量化?
计算机天生不理解 “文字”,只懂 “数字”。比如:
- 你看到 “猫” 和 “小猫”,能立刻判断它们语义高度相似;
- 但计算机直接处理文字时,只能看到两个不同的字符串,无法感知这种相似性。
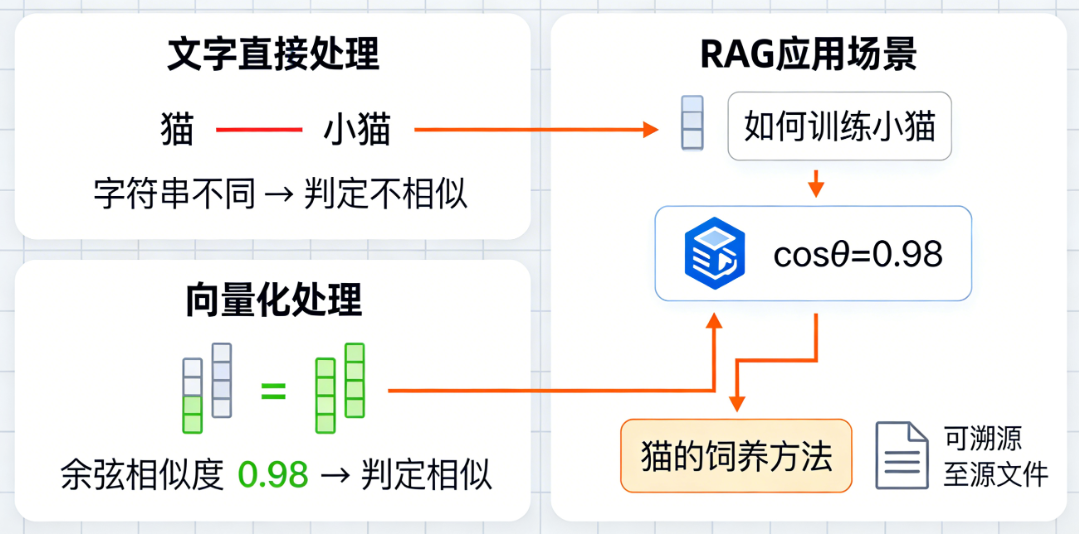
而向量化就是解决这个问题:把 “猫” 转换成 [0.12, 0.35, -0.21, …](一串固定长度的数字),把 “小猫” 转换成 [0.11, 0.34, -0.22, …]—— 这两个向量的数值高度接近,计算机就能通过计算向量间的距离(比如余弦相似度),判断出 “猫” 和 “小猫” 语义相似。
在 RAG 中,向量化的核心价值是:让后续的 “相似性检索” 成为可能(比如用户提问 “如何训练小猫”,能快速从向量库中找到 “猫的饲养方法” 相关的文本片段)。
二、向量化的核心逻辑
以你用到的 Ollama(嵌入模型)+ Spring AI 为例,向量化的过程可以拆解为 3 步: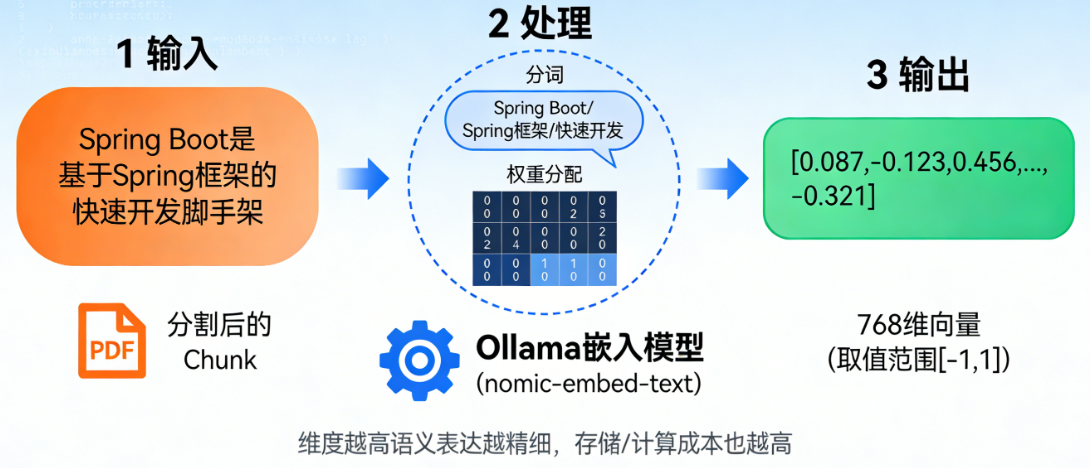
- 输入:分割后的文本片段(Chunk)
比如从 PDF 中分割出的一句话:“Spring Boot 是基于 Spring 框架的快速开发脚手架”。
- 处理:嵌入模型(Embedding Model)的计算
Ollama 可以部署专门的嵌入模型(比如 nomic-embed-text、bge-large),这类模型的核心作用就是 “语义转数字”:
- 模型会先对文本做分词(比如把上面的句子拆成 “Spring Boot”“Spring 框架”“快速开发” 等语义单元);
- 再通过预训练的语义规则,给每个语义单元分配数值权重,最终拼接成固定维度的向量(比如 768 维、1024 维 —— 维度越高,语义表达越精细,但存储 / 计算成本也越高)。
- 输出:固定长度的数值向量
比如最终生成的向量可能是:
[0.087, -0.123, 0.456, 0.098, …, -0.321](共 768 个数字,每个数字的取值范围通常在 [-1, 1] 之间)。
三、向量化的关键特征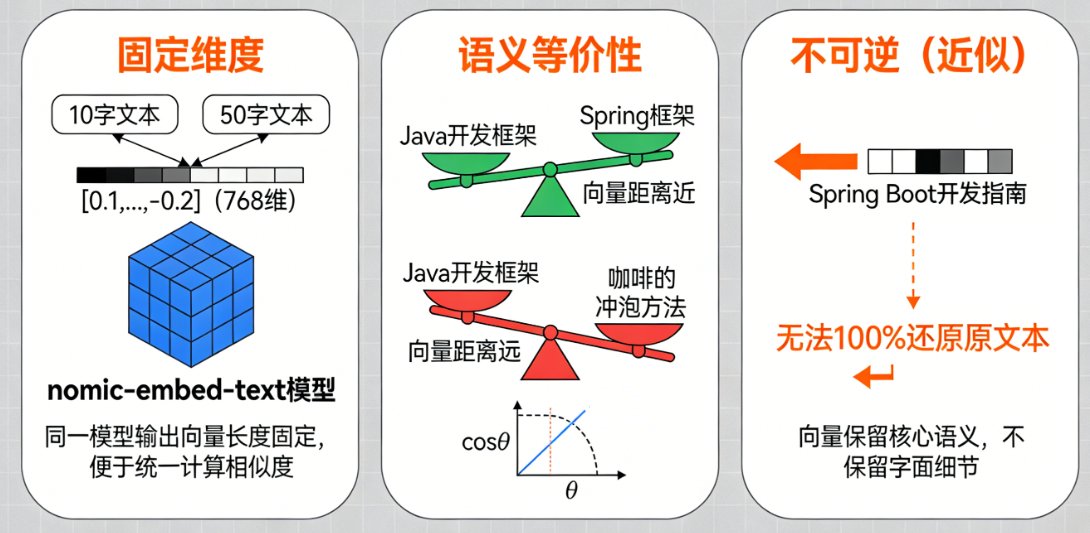
- 固定维度:同一模型生成的向量长度是固定的(比如 nomic-embed-text 生成 768 维向量),不管输入文本是 10 个字还是 50 个字,输出向量的长度都一样 —— 这是为了后续能统一计算相似度。
- 语义等价性:语义相似的文本,向量数值高度相似;语义无关的文本,向量数值差异很大。比如:
- “Java 开发框架” 和 “Spring 框架” → 向量距离近;
- “Java 开发框架” 和 “咖啡的冲泡方法” → 向量距离远。
- 不可逆(近似):从文本能生成向量,但从向量无法 100% 还原出原文本(向量只保留核心语义,不保留字面细节)。
向量库
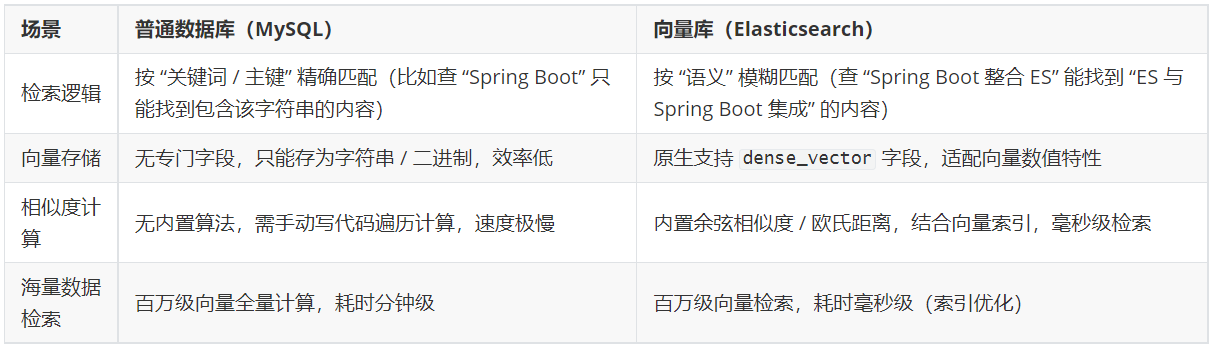
在 RAG(检索增强生成)和大模型应用体系中,向量库(Vector Database) 是专门用于存储、管理、检索「文本 / 数据的向量表示」的核心组件 ,可以把它理解为 “语义级别的数据库”,普通数据库(如 MySQL)按 “关键词 / 主键” 检索,而向量库按 “语义相似性” 检索,是实现 RAG 精准检索的核心基础设施。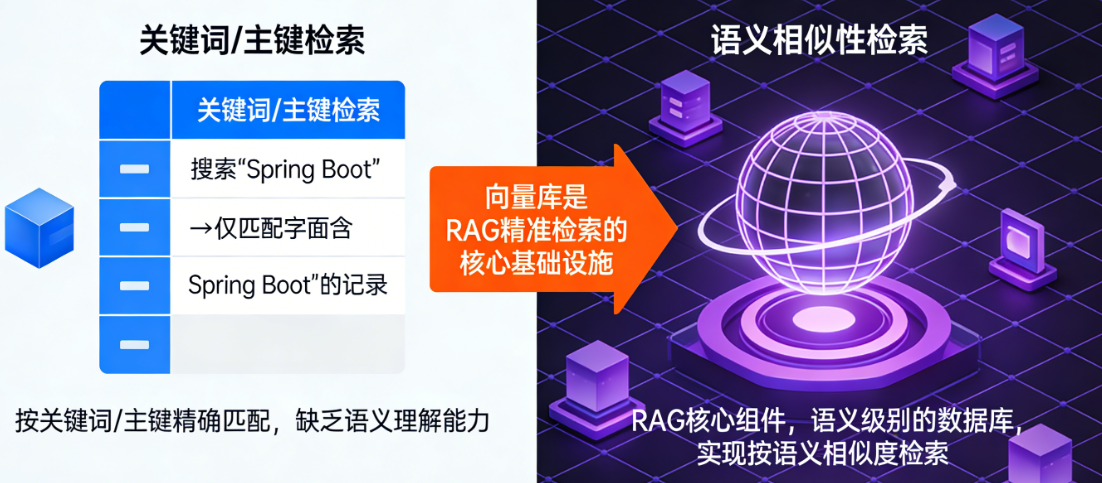
向量库的核心作用
存储海量向量 + 快速找到和 “目标向量” 语义最相似的向量,并关联回原始文本 / 数据,为 RAG 提供 “精准的本地知识库素材”。
拆解为 3 个具体作用:
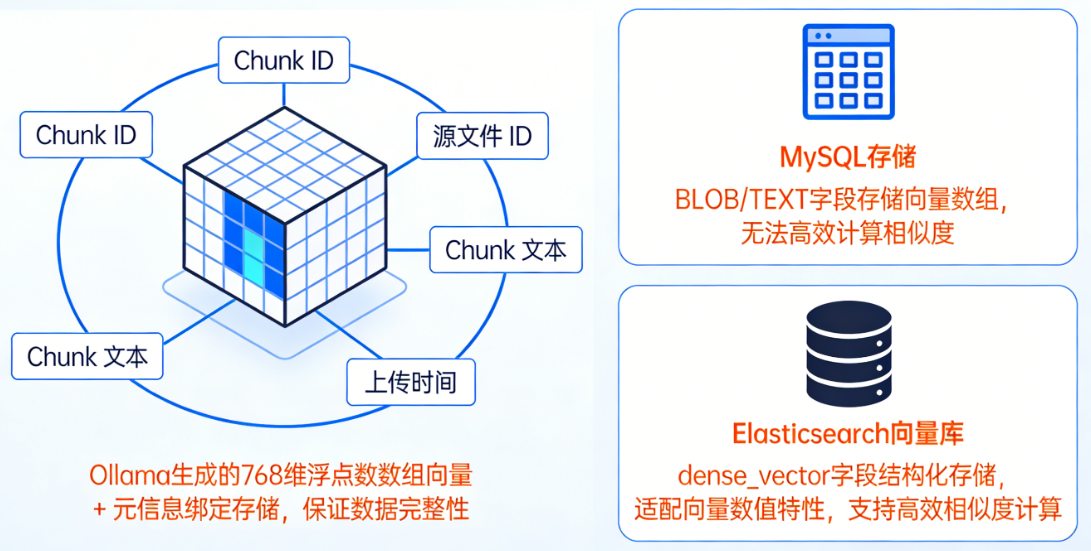
向量存储:安全、结构化管理向量数据
- 通过 Ollama 生成的文档片段(Chunk)向量(比如 768 维浮点数数组),需要一个专门的地方存储 ,向量库会将向量与「Chunk ID、源文件 ID、Chunk 文本、上传时间」等元信息绑定存储,保证数据完整性。
- 对比:如果直接存在 MySQL 中,只能用 BLOB/TEXT 存向量数组,无法高效计算相似度;而 Elasticsearch 这类向量库会对向量做结构化存储(dense_vector 字段),适配向量的数值特性。
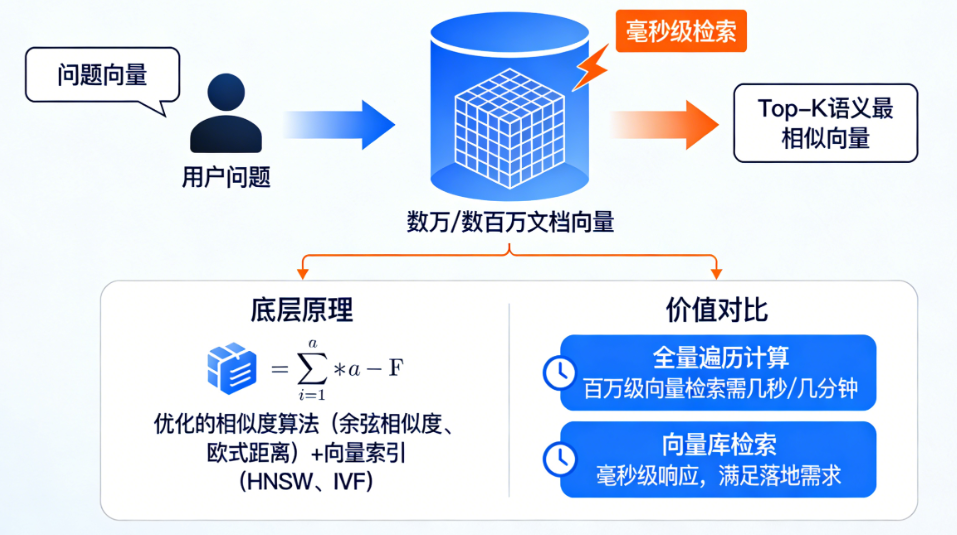
相似性检索:核心价值,实现 “语义匹配”
这是向量库最核心的作用 : 当用户提问生成 “问题向量” 后,向量库能在毫秒级内从数万 / 数百万个文档向量中,找到「语义最相似的 Top-K 个向量」:
- 底层原理:通过优化的相似度算法(如余弦相似度、欧式距离)+ 向量索引(如 HNSW、IVF),避免 “全量遍历计算”(否则百万级向量检索要几秒 / 几分钟,无法落地);
向量管理:支撑知识库的动态维护
实际落地中,你的本地知识库会不断更新(新增文件、删除过期文件、修改文档内容),向量库能支持:
- 新增:上传新文件后,分割→向量化→插入向量库;
- 删除:删除源文件时,批量删除关联的向量;
- 更新:修改文档后,重新分割向量化,替换旧向量;
- 过滤:检索时可结合元信息过滤(比如 “只检索 2025 年上传的 PDF 文档的向量”)。
向量库解决哪些问题
举个例子:
- 用 MySQL 查 “如何用 Spring Boot 做向量检索”,只能找到包含 “Spring Boot”+“向量检索” 关键词的文本;
- 用 Elasticsearch 向量库查,能找到 “Spring Boot 整合 ES 实现相似性查询” 这类语义相似但关键词不完全匹配的文本 —— 这正是 RAG 需要的 “精准检索”。
向量库的落地价值
- 保证回答的 “本地性”:所有向量都存在本地 Elasticsearch 中,检索过程不依赖外部服务,数据隐私可控;
- 提升回答的 “精准度”:大模型不再凭空回答,而是基于向量库检索到的 “语义最匹配” 的本地素材作答,避免 “胡说八道”;
- 支撑高并发 / 大数据量:如果你的知识库有上千份文档、数百万个 Chunk,向量库的索引优化能保证用户提问后 100~500ms 内返回检索结果,满足实际使用的响应要求;
- 溯源便捷:向量库存储了向量与源文件 / Chunk 的关联关系,检索结果能直接关联到原始文档,方便用户核对答案来源。
常见向量库
向量库的核心价值在于高维向量的高效存储与快速相似性检索,不同产品在性能、功能、部署方式上各有侧重,以下是业界常用的几款向量库:
- FAISS(Facebook AI Similarity Search)
- 核心定位:Facebook 开源的轻量级向量检索库,专注于单机高性能向量检索。
- 关键特性:支持稠密向量的 L2、内积等相似度计算,提供多种索引类型(Flat、IVF、HNSW 等),可通过量化(Scalar Quantization、Product Quantization)降低存储成本。
- 适用场景:小规模数据场景、离线向量检索任务,需结合其他工具实现分布式部署。
- Pinecone
- 核心定位:云端托管式向量数据库,主打 “零运维” 的向量检索服务。
- 关键特性:完全托管,支持自动扩缩容,提供 REST API 接口,兼容多种向量生成模型,内置数据备份与高可用机制。
- 适用场景:快速上线的业务系统、不愿投入运维资源的中小团队,按使用量付费。
- Weaviate
- 核心定位:开源的分布式向量数据库,支持混合检索(向量检索 + 结构化数据过滤)。
- 关键特性:基于 GraphQL 查询接口,支持动态模式定义,内置文本向量化功能(集成 Hugging Face 模型),支持容器化部署。
- 适用场景:需要结合结构化数据与非结构化数据检索的场景,如智能文档管理系统。
- Qdrant
- 核心定位:轻量级开源向量数据库,主打 “简单易用” 与 “低资源占用”。
- 关键特性:支持稠密向量与稀疏向量检索,提供 REST API 和 gRPC 接口,支持动态索引更新,部署简单(单二进制文件或容器)。
- 适用场景:小规模部署、边缘计算场景、快速原型验证。
- Milvus
- 核心定位:开源分布式向量数据库,专为大规模高维向量检索设计,兼顾性能、可靠性与扩展性。
- 关键特性:支持 PB 级向量存储、毫秒级检索响应,兼容多索引类型与相似度度量方式,提供完善的分布式架构与运维工具。
- 适用场景:大规模生产环境、高并发检索需求、多模态数据处理系统。
6.ElasticSearch
- 核心定位:开源分布式全文检索与分析引擎,支持向量存储 / 检索能力,兼顾文本检索与语义相似性检索,适配多场景数据处理需求。
- 关键特性:原生支持全文关键词检索 + 向量稠密向量(dense_vector)存储,内置余弦相似度 / 欧氏距离等度量方式,具备成熟的分布式分片 / 副本机制、动态扩缩容能力,可结合元数据过滤实现精准的混合检索(关键词 + 语义)。
- 适用场景:中小规模向量检索场景、文本 + 向量混合检索需求、已有 ES 生态的企业级生产环境、需轻量化部署的本地知识库系统。
示例代码
代码仓库:https://gitee.com/xiangweilll/spring-ai-rag-redis-elasticsearch.git
项目结构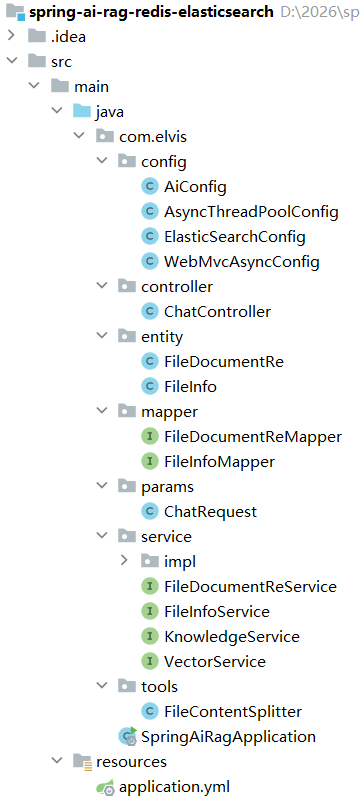
核心依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.elvis</groupId>
<artifactId>spring-ai-rag-redis-elasticsearch</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>spring-ai-rag-redis-elasticsearch</name>
<url>http://maven.apache.org</url>
<properties>
<java.version>17</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>3.3.4</spring-boot.version>
<spring-ai.version>1.0.0-M6</spring-ai.version>
<mybatis-plus.version>3.5.9</mybatis-plus.version>
<mysql.version>8.0.33</mysql.version>
<elasticsearch.version>8.14.0</elasticsearch.version>
<poi.version>5.2.4</poi.version>
<apache-lucene.version>8.11.4</apache-lucene.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.55</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-elasticsearch-store</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
<exclusions>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${apache-lucene.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${apache-lucene.version}</version>
<scope>runtime</scope>
</dependency>
<!-- 文本处理 -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>${poi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>${poi.version}</version>
</dependency>
<!-- 字符编码处理 -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.3-jre</version>
</dependency>
<!-- PDFBox for PDF -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.29</version>
</dependency>
<dependency>
<groupId>com.googlecode.juniversalchardet</groupId>
<artifactId>juniversalchardet</artifactId>
<version>1.0.3</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>17</source>
<target>17</target>
<encoding>UTF-8</encoding>
<compilerArgs>
<arg>-parameters</arg> <!--在编译代码是保留参数的名字-->
</compilerArgs>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<configuration>
<mainClass>com.elvis.SpringAiRagApplication</mainClass>
<skip>true</skip>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
主配置文件
spring:
elasticsearch:
uris: http://localhost:9200 # 明确指定 HTTP 协议
username: elastic
password: root123
connection-timeout: 5000
socket-timeout: 30000
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: qwen2.5:1.5b
temperature: 0.2
embedding-model-name: bge-m3:latest
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mall_116?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
username: root
password: root1234
# 知识库配置
knowledge:
vector-index: knowledge-base # 向量索引名(和主索引保持一致)
vector-dims: 1024 # 向量维度(根据模型调整,qwen2.5:1.5b 通常是 1024/768)
chunk-overlap: 80
chunk-min-length: 50
chunk-max-length: 600
top-k: 10
file-upload-dir: D:/knowledge-uploads/
logging:
level:
org.springframework.data.elasticsearch: debug # 增加 ES 日志,便于排查
org.springframework.ai: debug # 增加 AI 模块日志
AI配置
import io.micrometer.observation.ObservationRegistry;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.ollama.OllamaEmbeddingModel;
import org.springframework.ai.ollama.api.OllamaApi;
import org.springframework.ai.ollama.api.OllamaOptions;
import org.springframework.ai.ollama.management.ModelManagementOptions;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Author XiangWei
* @Date 2025/12/15 14:55
* @Description:
*/
@Configuration
public class AiConfig {
@Value("${spring.ai.ollama.embedding-model-name:bge-m3:latest}")
private String ollamaEmbeddingModelName;
@Bean
public ChatClient chatClient(OllamaChatModel ollamaChatModel){
return ChatClient.builder(ollamaChatModel).build();
}
// 嵌入模型配置
@Bean
public ObservationRegistry observationRegistry() {
return ObservationRegistry.NOOP;
}
@Bean
public ModelManagementOptions modelManagementOptions() {
return ModelManagementOptions.defaults();
}
@Bean
public OllamaOptions embeddingOllamaOptions() {
return OllamaOptions.builder()
.model(ollamaEmbeddingModelName)
.build();
}
@Bean
public OllamaEmbeddingModel ollamaEmbeddingModel(
OllamaApi ollamaApi,
OllamaOptions embeddingOllamaOptions,
ObservationRegistry observationRegistry,
ModelManagementOptions modelManagementOptions
) {
return new OllamaEmbeddingModel(
ollamaApi,
embeddingOllamaOptions,
observationRegistry,
modelManagementOptions
);
}
}
es配置
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.springframework.ai.ollama.OllamaEmbeddingModel;
import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStore;
import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStoreOptions;
import org.springframework.ai.vectorstore.elasticsearch.SimilarityFunction;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.elc.ElasticsearchConfiguration;
import org.springframework.data.elasticsearch.client.elc.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import javax.net.ssl.SSLContext;
import javax.net.ssl.TrustManager;
import javax.net.ssl.X509TrustManager;
import java.security.cert.X509Certificate;
import java.time.Duration;
/**
* @Author XiangWei
* @Date 2025/12/15 15:05
* @Description: Elasticsearch 配置类
*/
@Configuration
public class ElasticSearchConfig extends ElasticsearchConfiguration {
@Value("${spring.elasticsearch.uris}")
private String esUris;
@Value("${spring.elasticsearch.username}")
private String esUsername;
@Value("${spring.elasticsearch.password}")
private String esPassword;
// 向量索引名
@Value("${knowledge.vector-index:knowledge-base}")
private String vectorIndex;
// 向量维度
@Value("${knowledge.vector-dims:1024}")
private int vectorDims;
@Override
public ClientConfiguration clientConfiguration() {
String hostAndPort = esUris.replace("https://", "").replace("http://", "");
SSLContext sslContext = createSSLContext();
return ClientConfiguration.builder()
.connectedTo(hostAndPort)
.usingSsl(sslContext)
.withBasicAuth(esUsername, esPassword)
.withConnectTimeout(Duration.ofMillis(10000))
.withSocketTimeout(Duration.ofMillis(30000))
.build();
}
/**
* 创建 Elasticsearch RestClient(用于向量存储)
*/
@Bean
public RestClient elasticsearchRestClient() {
String hostAndPort = esUris.replace("https://", "").replace("http://", "");
String[] hostPort = hostAndPort.split(":");
String host = hostPort[0];
int port = hostPort.length > 1 ? Integer.parseInt(hostPort[1]) : 9200;
SSLContext sslContext = createSSLContext();
// 创建凭证提供者
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(
AuthScope.ANY,
new UsernamePasswordCredentials(esUsername, esPassword)
);
return RestClient.builder(new HttpHost(host, port, esUris.startsWith("https") ? "https" : "http"))
.setRequestConfigCallback(requestConfigBuilder ->
requestConfigBuilder
.setConnectTimeout(10000)
.setSocketTimeout(30000))
.setHttpClientConfigCallback(httpClientBuilder ->
httpClientBuilder
.setSSLContext(sslContext)
.setDefaultCredentialsProvider(credentialsProvider))
.build();
}
/**
* 创建 SSL 上下文
*/
private SSLContext createSSLContext() {
try {
SSLContext sslContext = SSLContext.getInstance("TLSv1.3");
sslContext.init(null, new TrustManager[]{new X509TrustManager() {
@Override
public X509Certificate[] getAcceptedIssuers() { return new X509Certificate[0]; }
@Override
public void checkClientTrusted(X509Certificate[] certs, String authType) {}
@Override
public void checkServerTrusted(X509Certificate[] certs, String authType) {}
}}, new java.security.SecureRandom());
return sslContext;
} catch (Exception e) {
throw new RuntimeException("初始化 SSL 上下文失败", e);
}
}
/**
* 创建 Elasticsearch 操作模板
*/
@Bean
public ElasticsearchOperations elasticsearchOperations(ElasticsearchClient elasticsearchClient) {
return new ElasticsearchTemplate(elasticsearchClient);
}
/**
* 配置 Spring AI Elasticsearch 向量存储
*/
@Bean
public ElasticsearchVectorStore elasticsearchVectorStore(
RestClient restClient,
OllamaEmbeddingModel ollamaEmbeddingModel) {
// 创建配置选项
ElasticsearchVectorStoreOptions options = new ElasticsearchVectorStoreOptions();
options.setIndexName(vectorIndex);
options.setDimensions(vectorDims);
options.setSimilarity(SimilarityFunction.cosine);
// 使用 Builder 模式创建向量存储
return ElasticsearchVectorStore.builder(restClient, ollamaEmbeddingModel)
.options(options)
.initializeSchema(true) // 自动创建索引和映射
.build();
}
}
线程池配置
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
import java.util.concurrent.ThreadPoolExecutor;
@Configuration
@EnableAsync // 必须开启异步注解支持
public class AsyncThreadPoolConfig {
/**
* 对话记录落库专用线程池(指定bean名称,供@Async引用)
*
*/
@Bean(name = "chatTaskExecutor")
public Executor chatTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 核心线程数(根据服务器配置调整,比如4核8G设为8)
// 获取到当前服务器CPU核心数
int cpus = Runtime.getRuntime().availableProcessors();
executor.setCorePoolSize(cpus);
// 最大线程数(核心线程忙不过来时,最多扩容到这个数)
executor.setMaxPoolSize(cpus * 2);
// 队列容量(核心线程满了,任务先入队列,避免直接创建新线程)
executor.setQueueCapacity(1000);
// 线程空闲时间(超过60秒空闲的非核心线程会被销毁)
executor.setKeepAliveSeconds(60);
// 线程命名前缀(便于日志排查问题)
executor.setThreadNamePrefix("chat-async-");
// 拒绝策略(队列满+最大线程数满时,让提交任务的线程执行,避免任务丢失)
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 初始化线程池(必须调用,否则线程池不生效)
executor.initialize();
return executor;
}
}
SpringMvc请求配置
import lombok.RequiredArgsConstructor;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.web.servlet.config.annotation.AsyncSupportConfigurer;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
/**
* Spring MVC 异步请求配置(解决默认SimpleAsyncTaskExecutor告警)
*/
@Configuration
@RequiredArgsConstructor
public class WebMvcAsyncConfig implements WebMvcConfigurer {
// 注入自定义的线程池(指定bean名称)
private final ThreadPoolTaskExecutor chatTaskExecutor;
/**
* 配置MVC异步请求的线程池
*/
@Override
public void configureAsyncSupport(AsyncSupportConfigurer configurer) {
// 1. 指定MVC异步请求使用的线程池
configurer.setTaskExecutor(chatTaskExecutor);
// 2. 可选:设置异步请求超时时间(默认30秒,根据业务调整)
configurer.setDefaultTimeout(60 * 1000); // 60秒
}
}
文件上传(添加知识库)
建表sql
create table file_info(
id bigint primary key,
file_name varchar(256),
file_type varchar(32),
file_path varchar(256),
create_time datetime
);
create table file_document(
id bigint primary key,
file_info_id bigint,
document_id varchar(64)
);
实体类
package com.elvis.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.time.LocalDateTime;
@Data
@TableName("file_info")
public class FileInfo {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String fileName;
private String fileType;
private String filePath;
private LocalDateTime createTime;
}
package com.elvis.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName("file_document_re")
public class FileDocumentRe {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private Long fileInfoId;
private String documentId;
}
Mapper层
package com.elvis.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.elvis.entity.FileInfo;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface FileInfoMapper extends BaseMapper<FileInfo> {
}
package com.elvis.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.elvis.entity.FileDocumentRe;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface FileDocumentReMapper extends BaseMapper<FileDocumentRe> {
}
service层
package com.elvis.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.elvis.entity.FileInfo;
import org.springframework.ai.document.Document;
import java.util.List;
public interface FileInfoService extends IService<FileInfo> {
public void saveFileInfo(String fileName,String filePath, List<Document> documents);
}
package com.elvis.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.elvis.entity.FileDocumentRe;
public interface FileDocumentReService extends IService<FileDocumentRe> {
}
实现类
import lombok.Data;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.util.List;
/**
* @Author XiangWei
* @Date 2025/12/16 10:34
* @Description:
*/
@Slf4j
@Data
@Service
@RequiredArgsConstructor
public class FileInfoServiceImpl extends ServiceImpl<FileInfoMapper, FileInfo> implements FileInfoService {
private final FileDocumentReService fileDocumentReService;
@Async("chatTaskExecutor")
@Override
public void saveFileInfo(String fileName, String filePath, List<Document> documents) {
log.info("文件 {} 开始保存文件信息到数据库,线程id:{}", fileName, Thread.currentThread().getId());
// 1.创建文件信息实体
FileInfo fileInfo = new FileInfo();
fileInfo.setFileName(fileName);
fileInfo.setFilePath(filePath);
fileInfo.setFileType(fileName.substring(fileName.lastIndexOf(".") + 1));
fileInfo.setCreateTime(LocalDateTime.now());
// 2.保存
save(fileInfo);
// 3.保存文件文档实体
fileDocumentReService.saveBatch(documents.stream().map(document -> {
FileDocumentRe fileDocument = new FileDocumentRe();
fileDocument.setFileInfoId(fileInfo.getId());
fileDocument.setDocumentId(document.getId());
return fileDocument;
}).toList());
}
}
package com.elvis.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.elvis.entity.FileDocumentRe;
import com.elvis.mapper.FileDocumentReMapper;
import com.elvis.service.FileDocumentReService;
import org.springframework.stereotype.Service;
@Service
public class FileDocumentReServiceImpl extends ServiceImpl<FileDocumentReMapper, FileDocumentRe> implements FileDocumentReService {
}
controller层
package com.woniuxy.knowledge.controller;
import com.woniuxy.knowledge.service.VectorService;
import lombok.RequiredArgsConstructor;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
/**
* @Author XiangWei
* @Date 2025/12/15 14:18
* @Description:
*/
@RestController
@RequestMapping("/chat")
@RequiredArgsConstructor
public class ChatController {
private final VectorService vectorService;
// 上传文件
@PostMapping("/upload")
public ResponseEntity uploadFile(MultipartFile file) throws IOException {
// 调用向量服务上传文件
return vectorService.uploadFile(file);
}
}
知识库问答
基本流程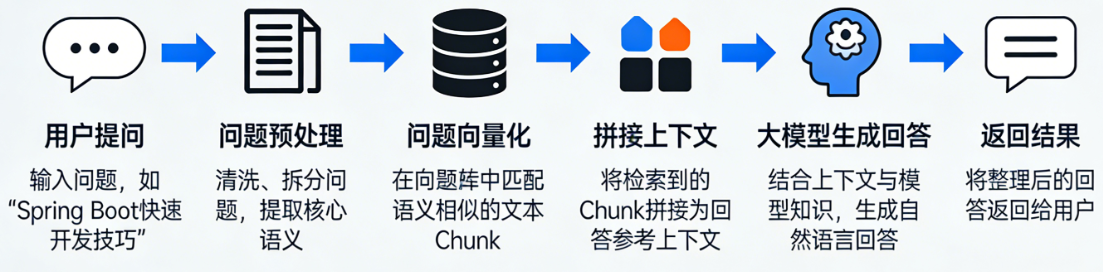
参数类
package com.elvis.params;
import lombok.Data;
@Data
public class ChatRequest {
private String message;
}
service层
package com.elvis.service;
import reactor.core.publisher.Flux;
public interface KnowledgeService {
Flux<String> ask(String message);
}
实现类
import com.woniuxy.knowledge.service.KnowledgeService;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.ai.document.Document;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* @Author XiangWei
* @Date 2025/12/15 19:03
* @Description:
*/
@Service
@RequiredArgsConstructor
public class KnowledgeServiceImpl implements KnowledgeService {
private final ElasticsearchVectorStore elasticsearchVectorStore;
private final ChatClient chatClient;
// 提示词模板(核心:告诉AI基于检索到的上下文回答问题)
private static final String PROMPT_TEMPLATE = """
1.请基于以下提供的上下文信息回答用户的问题,只使用上下文里的内容,不要编造信息。
2.如果上下文里没有相关信息,请回答"暂无相关信息"。
3.只包含上下文中的信息,不要包含其它信息。
上下文:
{context}
用户问题:
{question}
回答:
""";
@Value("${knowledge.top-k:3}")
private int topK;
@Override
public Flux<String> ask(String message) {
// 步骤1:从ES向量库检索最相似的文档(自动将提问转为向量并做相似度匹配)
SearchRequest searchRequest = SearchRequest.builder()
.topK(topK)
.query(message).build();
List<Document> documents = elasticsearchVectorStore.similaritySearch(searchRequest);
// 步骤2:拼接检索到的文档作为上下文
String context = documents.stream()
.map(Document::getText) // 获取文档内容
.collect(Collectors.joining("\n\n")); // 多个文档用换行分隔
// 步骤3:构建Prompt(将上下文和问题传入模板)
PromptTemplate promptTemplate = new PromptTemplate(PROMPT_TEMPLATE);
Map<String, Object> params = new HashMap<>();
params.put("context", context);
params.put("question", message);
Prompt prompt = promptTemplate.create(params);
// 步骤4:调用 AI
return chatClient.prompt()
.user(prompt.getContents()) // 用户输入
.stream() // 流式响应
.content() // 只提取内容(过滤元数据)
.filter(content -> content != null && !content.trim().isEmpty());
}
}
controller层
controller中添加代码
private final KnowledgeService knowledgeService;
// 知识库问答 流式输出
@PostMapping(value = "/ask", produces = "text/event-stream")
public Flux<String> ask(@RequestBody ChatRequest request) {
return knowledgeService.ask(request.getMessage());
}

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)