
从Java转行大模型应用,LangChain核心学习,数据检索,Chain使用
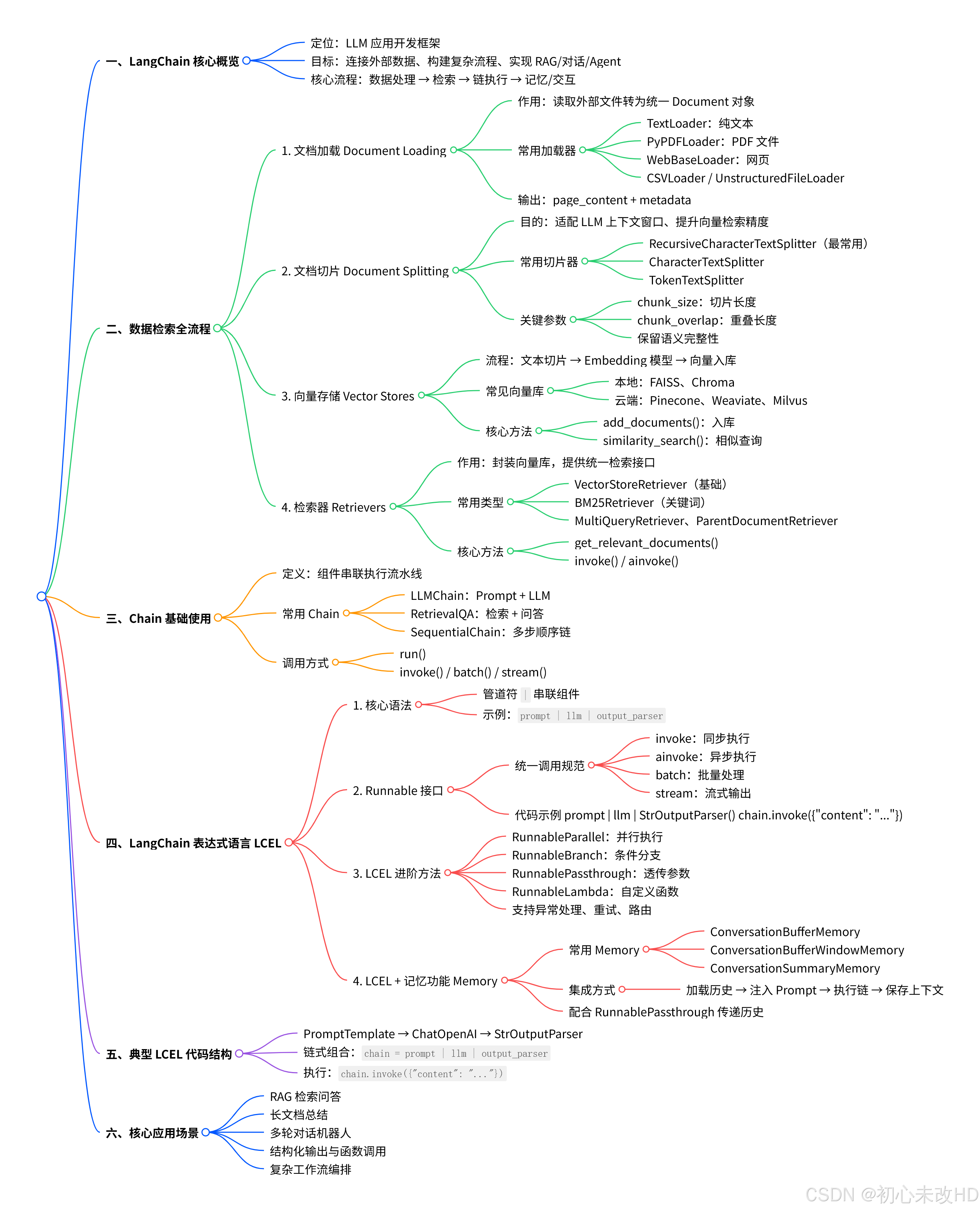
一、LangChain 核心概述
LangChain 是一个用于构建大语言模型(LLM)应用的开发框架,核心目标是解决 LLM 上下文有限、无法高效连接外部数据、难以实现复杂逻辑流程的问题。其核心设计理念是“模块化”,将 LLM 应用拆解为多个可组合、可替换的组件,通过组件串联实现复杂功能,核心组件包括:数据检索相关组件、Chain 流程组件、LCEL 表达式语言、记忆组件等。
学习重点:掌握各组件的核心作用、使用场景,以及如何通过组件组合构建端到端 LLM 应用。
二、数据检索核心流程(文档加载 → 文档切片 → 向量存储 → 检索器)
数据检索是 LangChain 连接外部数据的核心能力,解决 LLM“知识过时”“无法访问私有数据”的问题,完整流程分为 4 个步骤,环环相扣。
2.1 文档加载(Document Loading)
核心作用:将外部不同格式的文档(文本、PDF、Excel、网页等)读取为 LangChain 统一的 Document 格式(包含 page_content 内容和 metadata 元数据),为后续处理提供统一标准。
关键要点:
-
常用加载器:针对不同格式选择对应加载器,如 TextLoader(文本文件)、PyPDFLoader(PDF 文件)、WebBaseLoader(网页)、CSVLoader(CSV 文件)。
-
核心操作:通过加载器的 load() 方法读取文档,返回 Document 列表;可通过 metadata 添加自定义信息(如文档来源、作者、时间),方便后续检索过滤。
-
注意事项:加载大文件时需注意内存占用,可结合分片加载(如 PyPDFLoader 按页加载)。
2.2 文档切片(Document Splitting)
核心作用:将加载后的完整文档(通常内容较长)切分为多个小的文本片段(Chunk),原因是 LLM 有上下文窗口限制,且小片段更易生成精准的向量表示,提升检索效率和准确性。
关键要点:
-
常用切片器:RecursiveCharacterTextSplitter(最常用,按字符递归切片,支持自定义 chunk_size 片段长度、chunk_overlap 片段重叠度)、CharacterTextSplitter(按固定字符切片)、TokenSplitter(按 Token 数量切片,适配 LLM Token 限制)。
-
核心参数:chunk_size(每个片段的最大长度,单位:字符或 Token)、chunk_overlap(相邻片段的重叠部分长度,建议 10%-20%,避免上下文断裂)。
-
切片原则:根据文档类型调整,如结构化文档(CSV)按行切片,非结构化文档(文章)按语义片段切片,确保每个 Chunk 语义完整。
2.3 向量存储(Vector Stores)
核心作用:将切片后的文本片段(Chunk)通过嵌入模型(Embedding)转换为向量(Embedding Vector),并存储到向量数据库中,方便后续通过“语义相似性”快速检索相关片段。
关键要点:
-
核心流程:文档切片 → 嵌入模型(如 OpenAIEmbeddings、HuggingFaceEmbeddings)将 Chunk 转为向量 → 向量存储到数据库。
-
常用向量存储:
-
本地存储:Chroma(轻量、易部署,适合开发测试)、FAISS(Facebook 开源,高效相似性检索,适合小规模数据);
-
云端存储:Pinecone、Weaviate、Milvus(适合大规模数据、生产环境,支持分布式部署)。
-
-
核心操作:add_documents()(添加文档向量)、similarity_search()(按查询语句的向量检索相似片段)、similarity_search_with_score()(检索相似片段并返回相似度分数)。
2.4 检索器(Retrievers)
核心作用:作为“向量存储的访问入口”,封装向量存储的检索逻辑,提供统一的检索接口,方便后续与 Chain、LLM 集成,无需直接操作向量存储。
关键要点:
-
常用检索器:VectorStoreRetriever(最常用,基于向量存储的检索器,可配置检索数量 k)、BM25Retriever(基于关键词匹配的检索器,与向量检索互补)、MultiQueryRetriever(多查询检索,通过生成多个查询语句提升检索准确性)。
-
核心操作:get_relevant_documents(query)(输入查询语句,返回最相关的文档片段列表)。
-
检索优化:可通过调整 k 值(检索数量)、结合过滤条件(如按 metadata 过滤)、使用混合检索(向量检索 + 关键词检索)提升检索效果。
三、Chain 使用(核心流程串联)
Chain 是 LangChain 中串联多个组件(LLM、Retriever、工具等)的核心机制,将“输入 → 处理 → 输出”的流程自动化,避免手动串联组件的繁琐操作。
关键要点:
-
核心概念:每个 Chain 包含一个或多个组件,接收输入(如用户查询),经过组件处理(如检索相关文档、调用 LLM 生成回答),最终返回输出。
-
常用基础 Chain:
-
LLMChain:最基础的 Chain,仅包含 LLM 和 PromptTemplate,用于简单的文本生成(如问答、总结);
-
RetrievalQA:检索增强 QA Chain,串联 Retriever 和 LLM,流程为:用户查询 → Retriever 检索相关文档 → 将查询 + 相关文档传入 LLM → 生成回答(解决 LLM 知识有限问题);
-
SequentialChain:顺序 Chain,将多个 Chain 按顺序串联,前一个 Chain 的输出作为后一个 Chain 的输入(如“文档总结 → 总结问答”)。
-
-
核心操作:通过 Chain 的 run() 方法执行流程,或使用 invoke() 方法(支持更灵活的输入输出格式)。
-
自定义 Chain:当基础 Chain 无法满足需求时,可通过继承 Chain 类,自定义输入处理、组件串联逻辑。
四、LangChain 表达式语言(LCEL)
LCEL(LangChain Expression Language)是 LangChain 最新的核心特性,用于更简洁、灵活地定义组件和 Chain 流程,替代传统的 Chain 子类写法,支持组件的组合、并行、条件判断等复杂逻辑。
核心优势:语法简洁、可组合性强、支持动态调整流程、与 Runnable 接口深度集成。
4.1 LCEL 核心语法
-
组件组合:使用 | 符号串联组件,实现“输入 → 组件1 → 组件2 → 输出”的流程,例如:prompt | llm | output_parser(Prompt 渲染 → LLM 生成 → 输出解析)。
-
输入输出适配:当组件的输出格式与下一个组件的输入格式不匹配时,可通过 lambda 函数或自定义函数进行转换。
-
参数传递:支持通过字典传递多个输入参数,组件可按需获取对应参数。
4.2 Runnable 接口使用
Runnable 是 LCEL 的核心接口,所有 LangChain 组件(LLM、PromptTemplate、Retriever、Chain 等)都实现了该接口,确保组件可被统一组合、调用。
关键方法:
-
invoke(input):同步调用组件,接收输入并返回输出(最常用);
-
ainvoke(input):异步调用组件,适合异步场景(如 FastAPI 接口);
-
batch(inputs):批量调用组件,接收多个输入,返回多个输出,提升效率;
-
stream(input):流式输出,适合需要实时返回结果的场景(如聊天机器人)。
示例:将 PromptTemplate、LLM、OutputParser 通过 Runnable 组合:
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
prompt = PromptTemplate.from_template("请总结以下内容:{content}")
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
result = chain.invoke({"content": "LangChain 是一个 LLM 应用开发框架..."})4.3 LCEL 进阶方法
-
并行执行:使用 RunnableParallel 并行调用多个组件,同时获取多个输出,例如:并行检索多个向量存储的结果。
-
条件判断:使用 RunnableBranch 实现条件分支逻辑,根据输入内容选择不同的组件流程(如“判断查询是否需要检索,需要则调用 Retriever,否则直接调用 LLM”)。
-
循环执行:使用 RunnableSequence + 条件判断,实现循环逻辑(如“多次检索,直到获取足够相关的文档”)。
-
自定义 Runnable:通过继承 Runnable 类,实现自定义组件,适配特殊业务场景(如自定义检索逻辑、输出处理逻辑)。
五、LCEL 添加记忆功能
记忆(Memory)功能用于保存对话历史或上下文信息,让 LLM 能够基于历史交互生成连贯的回答(如聊天机器人记住用户之前的提问)。LCEL 中通过将 Memory 组件与 Runnable 组合,实现记忆功能的集成。
关键要点:
-
常用记忆组件:
-
ConversationBufferMemory:简单的对话缓冲区,保存所有对话历史(适合短对话);
-
ConversationBufferWindowMemory:保存最近 N 轮对话历史(避免对话历史过长,节省 Token);
-
ConversationSummaryMemory:将对话历史总结为一段文本,节省 Token,适合长对话。
-
-
LCEL 集成记忆的核心流程:
-
创建记忆组件,指定记忆的存储方式和参数(如 window_size);
-
通过 RunnablePassthrough 传递对话历史,将记忆中的对话历史与当前查询结合;
-
将组合后的输入传入 LLM,生成回答;
-
更新记忆组件,将当前查询和回答添加到对话历史中。
-
-
示例代码核心逻辑:
-
注意事项:记忆组件的 return_messages 参数需设为 True,确保返回的对话历史为 Message 格式,与 Prompt 适配;长对话场景建议使用 ConversationSummaryMemory,避免 Token 溢出。
六、核心总结
1. 数据检索是 LangChain 连接外部数据的核心,流程为:文档加载 → 文档切片 → 向量存储 → Retriever 检索,核心目标是为 LLM 提供精准的外部上下文;
2. Chain 用于串联组件,简化流程;LCEL 是更灵活的流程定义方式,基于 Runnable 接口实现组件的组合、并行、条件判断;
3. 记忆功能通过 Memory 组件与 LCEL 组合实现,核心是保存对话历史,让 LLM 生成连贯回答;
4. 学习关键:掌握各组件的核心作用,学会用 LCEL 组合组件,根据业务场景选择合适的检索方式、记忆方式和 Chain 流程。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 21
21 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)