
史上最全LangChain 学习教程
真正让大模型落地的,从来不是那一句提示词。
而是提示词之外那一大堆脏活累活。
模型怎么接、消息怎么传、工具怎么调、知识库怎么检索、状态怎么保存、输出怎么约束、出了问题怎么追...这些都是我们要考虑的,既是痛点也是难点。
LangChain 的价值,就在这里。
它是啥?
它不是大模型。
它也不是一个单纯的提示词库。
它更像一层工程框架,把大模型应用里最重复、最混乱、最容易失控的部分,整理成一套可以复用、可以替换、可以扩展的构件。官方现在对它的定位也很直接:它是一个开源框架,提供预构建的 agent 架构,以及面向不同模型和工具的集成,用来更快地构建 LLM 应用和 agents。
很多人用过LangChain,觉得它只是在链 prompt,还能加快agent开发。
这不算错,但已经不够了。
今天的 LangChain,核心目标已经从“把几个步骤串起来”升级成了把 agent 应用工程化。官方文档里已经明确把重点放在 agent、工具调用、memory、middleware、observability,以及和 LangGraph 的关系上。LangChain 负责更高层、更易上手的抽象,LangGraph 负责更底层的编排能力,比如长流程、有状态、可恢复、可中断的人机协同这些都是比较重要的。
一、LangChain 是什么
Lang = Language,指语言模型
Chain = Chains,指把多个步骤串起来执行
LangChain 官方文档直接写了:“The name LangChain comes from ‘Language’ and ‘Chains’. ”
更直白一点说,:不要只调用一次大模型,而是把一连串步骤接起来。比如先检索资料,再把资料塞进提示词,再调用模型生成答案。LangChain 官方也把 chains 描述为一组预先设定好的计算步骤,例如 RAG 里的先检索,再生成。
所以你可以把它理解成一句大白话:
LangChain = 把语言模型接入一条工作链路的框架。
最简单的定义是:
LangChain 是一套面向大模型应用的开发框架。它把模型调用、上下文组织、工具接入、知识检索、状态管理和调试追踪,抽象成了统一的开发接口。
这件事很重要,为什么?
因为大模型开发真正的难点和痛点,从来不是发一个请求给模型。
真正难的是下面这些问题:
你今天用 OpenAI,明天想换 Anthropic,代码要不要全改。
你想让模型能查天气、查数据库、发请求、执行函数,怎么把工具安全地接进去。
你做 RAG,要怎么把文档加载、切分、向量化、检索、拼上下文这一整套接起来。
你做多轮对话,历史消息怎么管,状态怎么存。
你做 agent,模型中途调用了三次工具,到底哪一步错了,怎么追。
你上线后,效果退化了,是模型变了,prompt 变了,还是检索坏了。
LangChain 不是替你解决业务问题,更多的是重复性、复杂性高的基础工作。
不过,从设计哲学上看,LangChain 的判断也很鲜明:
大模型本身很强,但接入外部数据之后更强。未来应用会越来越 agent 化。但从原型走向生产并不容易,真正难的是可靠性。它存在的目的,就是让大模型跑的更稳。
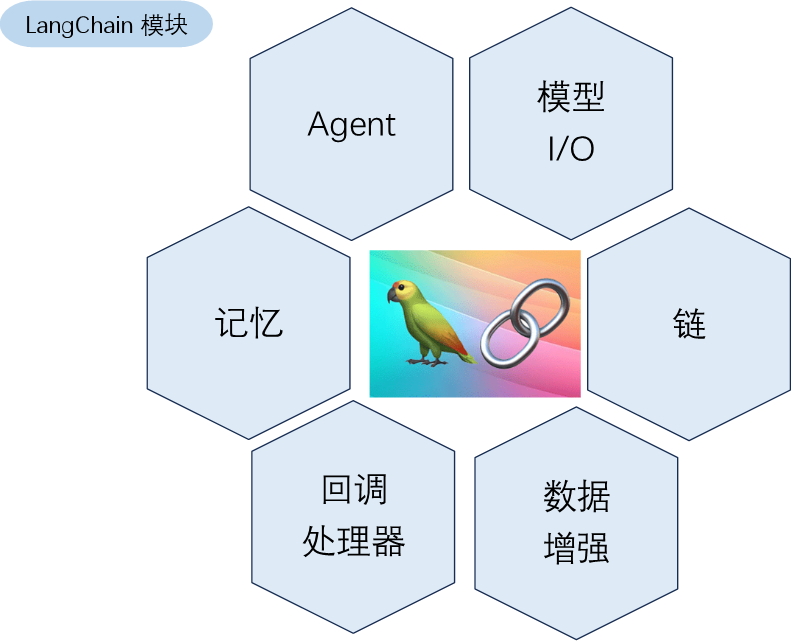
二、LangChain 的核心组成部分
其实官方现在给出的口径很克制。
在 LangChain 当前文档里,Core components 只有 7 个:

这就说明 LangChain 想先教你的,不是一个大而全的 AI 系统,而是一个最小但完整的 agent 运行框架,告诉你agent是怎么运行的。LangChain 官方对自己的定位也很直接,它是一个开源框架,提供预构建的 agent 架构,以及面向任意模型和工具的集成,用来快速搭建 LLM 应用。
2.1 Agents
如果说 LangChain 是一台机器,Agent 就是这台机器的总控台。
简单讲:agent = LLM + prompt + memory + tools
官方对 agent 的定义非常清楚:“Agents combine language models with tools to create systems that can reason about tasks, decide which tools to use, and iteratively work towards solutions.”agent 把语言模型和工具结合起来,让系统能够围绕任务进行推理,决定该用什么工具,并通过反复迭代逐步逼近答案。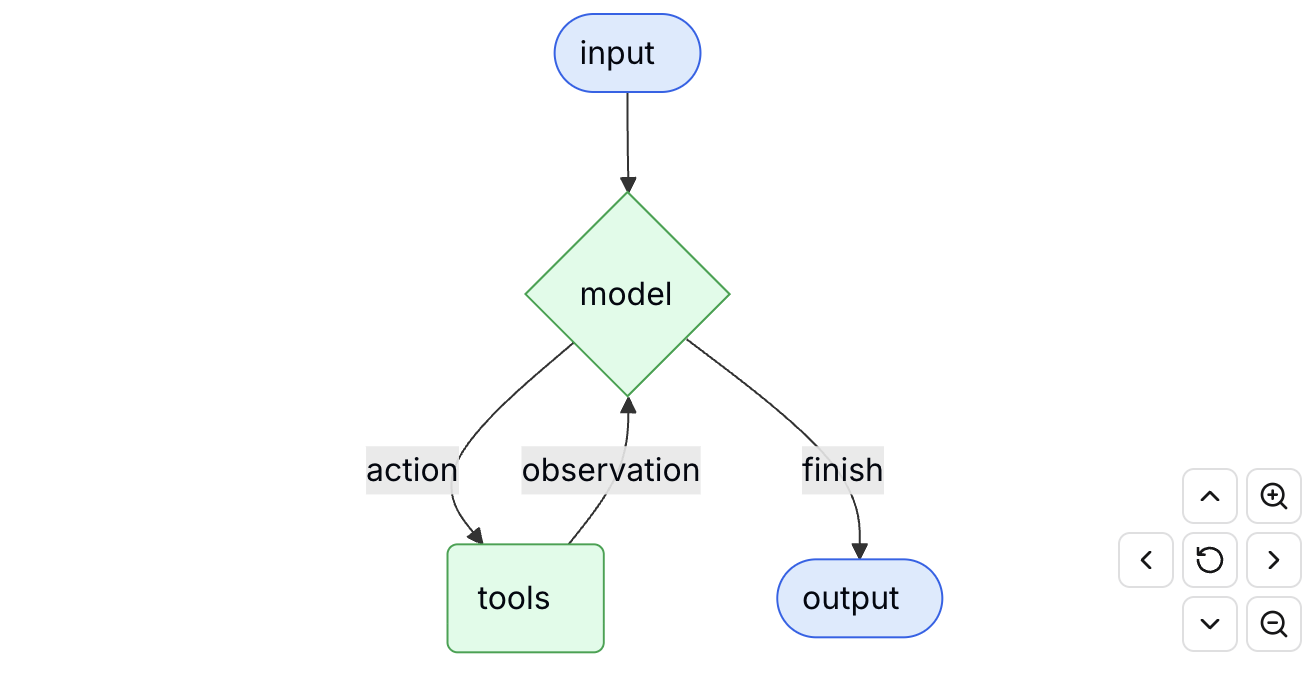
其实很简单,LangChain 把 Agents 放在第一位,不是因为它技术有多深,而是因为它定义了整套系统的组织方式。你后面看到的模型、消息、工具、记忆、流式输出,本质上都在服务这个循环。
2.2 Models
不要认为LangChain中模型只是一个调用的接口。
在 LangChain 里,模型不只是接口,它是推理引擎。
官方文档写到,LLM 是强大的 AI 工具,能够像人类一样解读和生成文本。他们足够多才多艺,能够撰写内容、翻译语言、总结和回答问题,而无需专门培训。很多现代模型除了文本生成,还支持工具调用、结构化输出、多模态处理和多步推理。
它开始承担判断、选择、规划和收敛的角色。
比如什么时候该调用工具,调用完之后怎么解释结果,什么时候该停止循环给出最终答案,这些都由模型来驱动。模型选得好不好,决定了 agent 的底盘稳不稳。
并且
LangChain 的价值,不是替你发一次请求,而是把不同模型尽量放到统一接口下。这样你做应用时,注意力可以更多放在系统设计上,而不是陷在不同厂商 SDK 的细枝末节里。
2.3 Messages
如果说模型是推理引擎,Messages 就是它看到的世界。
官方把 messages 定义为 模型上下文的基本单位,包括角色、内容、元数据三部分。它们表示模型的输入和输出,里面不仅有内容,还有角色和元数据。一个 message 至少包含三层信息:谁说的,说了什么,还带着哪些附加信息。LangChain 还提供了跨模型提供商统一的消息类型。
简单来说,message就是agent中传递的信息包,包括
| 类型 | 本质 |
|---|---|
| 用户问题 | message |
| 模型回答 | message |
| 工具调用请求 | message |
| 工具返回结果 | message |
| system prompt | message |
| 思考过程(有些框架) | message |
一个最简单的message形态长这样:
{
"role": "user",
"content": "帮我写一个 Python 函数"
}最简单的用途是创建消息对象,并在调用时传递给模型。
from langchain.chat_models import init_chat_model
from langchain.messages import HumanMessage, AIMessage, SystemMessage
model = init_chat_model("gpt-5-nano")
system_msg = SystemMessage("You are a helpful assistant.")
human_msg = HumanMessage("Hello, how are you?")
# Use with chat models
messages = [system_msg, human_msg]
response = model.invoke(messages) # Returns AIMessage四、Tools
没有工具,模型大多只能输入输出。
有了工具,模型才真正开始做。
官方文档对 tools 的描述很直接:工具让 agent 能获取实时数据、执行代码、查询外部数据库,并对外部世界采取动作。在底层,工具就是输入输出明确的可调用函数,传给聊天模型之后,由模型根据对话上下文决定是否调用,以及传什么参数。
这一层非常关键。
它可以解释天气,却拿不到此刻的天气。
它可以写 SQL,却不等于真的查了数据库。
它可以规划一件事,却不等于真的执行了动作。
Tools 的诞生给了,agent手臂。
from pydantic import BaseModel, Field
from typing import Literal
class WeatherInput(BaseModel):
"""Input for weather queries."""
location: str = Field(description="City name or coordinates")
units: Literal["celsius", "fahrenheit"] = Field(
default="celsius",
description="Temperature unit preference"
)
include_forecast: bool = Field(
default=False,
description="Include 5-day forecast"
)
@tool(args_schema=WeatherInput)
def get_weather(location: str, units: str = "celsius", include_forecast: bool = False) -> str:
"""Get current weather and optional forecast."""
temp = 22 if units == "celsius" else 72
result = f"Current weather in {location}: {temp} degrees {units[0].upper()}"
if include_forecast:
result += "\nNext 5 days: Sunny"
return resultLangChain 为什么能从“聊天框架”走向“agent 框架”,核心原因之一就在这里。它把外部能力标准化成模型可调用的工具。
2.5 Short-term memory
真正有用的系统,不能每一轮都失忆。
官方对 short-term memory 的定义是,它让应用记住单个线程或单次会话里的历史交互。对 agent 来说,记忆很关键,因为它能帮助系统记住之前发生过什么,从反馈中学习,并逐步适应用户偏好。
这里最值得注意的一点是,LangChain 现在已经不把 memory 只看成把聊天记录再贴回去。
在 agent 体系里,短期记忆更像运行时状态。
它记录对话历史,也记录中间过程。
它不只是为了聊天连贯,更是为了让 agent 知道自己已经做到了哪一步。
memory更像是agent的执行状态。
没有状态,就没有真正的多轮任务。
没有状态,所谓 agent 往往只是“会反复调用模型的脚本”。
2.6 Streaming
流式输出是否重要?我觉得是,它算是大模型使用体验的一个里程碑。
其实它不仅是产品细节,它也是体验分水岭。
官方文档写得很明确,LangChain 实现了一套 streaming 系统,用来把 agent 运行过程中的实时更新暴露出来。这样应用不必等完整结果全部生成完,用户可以提前看到进度,从而明显改善响应体验。
更重要的是,它支持至少五类流 LangChain 文档 :

这意味着什么?
意味着 streaming 在 LangChain 里不只是显示层的小优化,而是把系统内部运行过程显性化。
你不仅能看到答案在生成,还能看到 agent 走到了哪一步,一旦你开始做稍复杂一点的 agent,就会明白这件事有多重要。
2.7 Structured 结构化 output
大模型真正接入系统时,最怕的一件事,就是输出太像人话。
人话适合阅读。
系统需要的是可消费的数据。
Structured output 应运而生!
官方文档:它让 agent 直接返回可预测的结构化结果,而不是让你再去解析自然语言。这些结果可以是 JSON、Pydantic model 或 dataclass。LangChain 的 create_agent 会自动处理这件事,把模型生成的结构化数据捕获、校验,并放进 agent state 里的 structured_response。
hh,其实我感觉没那么重要,自己解析其实也慢不到哪去。
补充
这里要先说明一下。
下面这些不是“官方没提到”。
更准确地说,它们不在官方那 7 个 Core components 清单里,但在官方其他栏目里都有明确位置。
1. Middleware 中间件
官方甚至单开一栏。
官方把 middleware 放在 Core components 之外,给了单独栏目。它的作用是在 agent 执行的每一步进行控制和定制,包括日志、调试、改 prompt、改工具选择、加重试、加 fallback、提前终止、限流、加 guardrails 和 PII 检测。
说白了,Core components 决定 agent 能不能跑。
Middleware 决定 agent 跑起来之后,能不能被你真正管住。
详细可以看官方文档。
2. Retrieval 检索
很多人一学 LangChain,第一反应就是 RAG。
但官方现在没有把 Retrieval 放进核心七件套,而是放进 Advanced usage。
这背后的意思很微妙。
LangChain 想先让你理解 agent 的基本骨架。
至于检索,是在很多真实场景里常见且重要的一种扩展能力。
官方检索文档也讲得很明白:LLM 有上下文有限的天然约束,所以 retrieval 的作用,是在运行时为模型拿到相关上下文。你既可以自己构建知识库,也可以直接连接已有数据库、CRM 或内部文档系统。
3. 文档加载、切分、Embedding、Vector store
这几个东西,很多人学 LangChain 时会以为它们就是核心本体。
其实从官方今天的组织方式看,它们更像是 Retrieval 这条线里的基础积木。官方在 retrieval 页面明确列出了 retrieval pipeline 的几个 building blocks,包括 document loaders、text splitters、embedding models 和 vector stores,并且强调这些组件是可替换的。
感觉这很像搭积木。
加载数据,是把知识搬进来。
切分文本,是把知识拆到能被召回的粒度。
Embedding,是把文本投到向量空间。
Vector store,是把这些向量存起来并搜索。
4. Long-term memory
长期记忆,被很多人忽略了
短期记忆解决的是单轮会话内的连续性。
长期记忆解决的是跨会话的持续性。
官方把 long-term memory 放在 Advanced usage 里。它允许 agent 在不同会话、不同线程之间存储和召回信息,而不是只记住当前这一段对话。
这类能力一旦进入生产环境就会非常重要。
比如用户画像、偏好、历史行为、任务记录,这些都不属于单次会话状态,而属于更长期的系统记忆。
messages 提供上下文,models 做推理,agents 决定流程,tools 执行动作,memory 保存状态,structured output 规范结果,middleware 控制整个运行过程。
LangChain把这7个组件串联起来,让大模型跑在想要的路上。
三、LangChain 到底做了什么
我觉得最重要的就是,统一了度量衡。
不同模型厂商有不同的 API、不同的消息格式、不同的参数命名;工具、向量库和外部系统也各有各的接法。LangChain做的第一件事,就是把这些差异收拢成一套相对统一的抽象,让你可以更平滑地替换底层模型和工具,而不必每换一家供应商就重写一遍业务代码。
但是这样就片面了,准确地说,LangChain做的事情,可以从四层来看:统一接口、组织工作流、把 agent 工程化、补齐调试与评测。
官方现在把它定义为一个带有预构建 agent 架构、并能连接任意模型和工具的开源框架;它的 agent 又是构建在 LangGraph 之上的,而调试、评测和部署则可以接到 LangSmith 上。
四、如何学习 LangChain
学 LangChain 最怕两件事。
第一件事,沉迷 API 名字。
第二件事,一上来就做多 agent 大项目。
正确的学法,不是背类图。
而是顺着大模型应用的演化路径去学。
1.先把大模型跑起来 (LangChain Docs)
可以先做一个demo,只包含三件事:
用户输入
模型调用
模型输出
官方的 Quickstart 就是最好的教程,从最小 agent 开始,展示模型、工具和提示如何协同工作。安装入口也很直接,LangChain 当前要求 Python 3.10 及以上。
第一阶段只做三件事:
-
model 怎么初始化
-
message 怎么传
-
tool 是怎么被模型调用的
可以先看看:
LangChain Overview,Quickstart,Models,Messages,Tools。
2.补上检索和结构化输出 (LangChain Docs)
学完大模型的基本调用就可以接触RAG了,因为绝大多数真实场景都离不开外部知识。官方 Learn 区已经把 semantic search、RAG agent、SQL agent、voice agent 等典型路径整理好了。
这一阶段建议做两个小项目:
第一个项目,给一份 PDF 做语义检索。
第二个项目,在检索基础上加一个最小 RAG 问答。
可以看看:
Retrieval,Build a semantic search engine,Build a RAG agent,Structured output。
这一阶段学完,你会第一次真正理解 LangChain 的价值和作用。
3.深入agent工作原理
很多人一开始就学 agent,最后只学会了几个 demo。
更好的顺序是,先把模型、工具、检索学明白,再回来看 agent 为什么成立。
这一阶段重点看:
-
Agents
-
Short-term memory
-
Middleware
-
Observability
重点关注:
它怎么决定下一步做什么。
它怎么记住过程中的状态。
你怎么拦截和控制它的执行。
它出了问题你怎么定位。
如果这四个问题你都能答清楚,你对 LangChain 的理解就可以说你掌握LangChain了。
4. LangGraph
当你的流程开始变长,开始有条件分支、循环、检查点、人工确认,或者你希望 agent 可以中断后恢复,就该进 LangGraph 了。
官方建议也很明确:
入门先用 LangChain 的高层 agent。
需要更深定制时,再转 LangGraph。
这个阶段重点在于:
-
LangGraph Overview
-
LangGraph Quickstart
-
Use the Graph API
-
Thinking in LangGraph
看这些内容时,多想想是怎么设计和实现的,以及为什么,而不是只会调包。
5. LangSmith
很多人把 tracing 当成上线前才需要的东西。
其实从第一个 RAG demo 开始,你就该接 LangSmith。官方 tracing quickstart 直接演示了如何把 retrieval 和 LLM 调用都记录进 trace,然后在界面里看完整过程。
没有可观测性,你只是“觉得系统能跑”。
有了可观测性,你才开始真正“理解系统为什么这样跑”。
总结
如果你想要一条能落地的路线,可以参考:
第一周
只学 LangChain 基础组件。
把 Quickstart 跑通,理解 model、message、tool。
第二周
做一个最小 RAG。
用自己的 PDF 或文档,完成加载、切分、向量化、检索、回答。
第三周
加 structured output、memory 和 tracing。
开始感受“从 demo 到应用”的区别。
第四周
进入 agent 和 LangGraph。
做一个会调工具、能追踪、有简单状态管理的 agent。
五、推荐的资料
网课讲的都比较浅显而且是被动学习,学起来慢不说还容易忘,这边推荐直接看官方文档 LangChain 文档
其他网站:
5. Hugging Face

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)