
巨头争霸赛:Claude Fable 5 vs GPT-5.5——算法创意能力评测
·
6.10凌晨1点,Claude发布了Fable 5,号称是Claude向大众发布过的能力最强的模型。Fable 5属于Mythos系列,只是为了大众使用,在安全上做了一些限制。

接下来,我们在算法设计与创意能力上对Fable和gpt-5.5进行综合评测,分析Fable的在该领域上的特点和优势。
评测设置
我们在官方客户端和对应的智能体产品claude code和codex中进行评测,其中claude code中使用Claude Fable 5模型,思考等级为extra,codex中使用gpt-5.5,思考等级为超高。
官方客户端测试8条连续的复杂算法问题,智能体测试对于算法仓库的连续3条复杂定向修改任务。
评测问题主要覆盖以下几个方面:
| 维度 | 测试形态 | 测试目的 | 测试方案(多智能体、强化学习领域) |
|---|---|---|---|
| 算法基础知识 | 客户端问答 | 主要测概念边界、定义、反例、误区,不需要工具环境 | 解释 Dec-POMDP、CTDE、IGM、Coordination Graph、CMDP、Lagrangian RL,并要求区分相近概念 |
| 算法比较能力 | 客户端问答 | 研究脉络、技术分类和洞察主要是认知能力;自动分析比较 5 种类似方法 | 给定论文列表,让模型比较 VDN/QMIX/QTRAN/QPLEX/COMA/MAPPO 的技术演进 |
| 研究问题发现 | 客户端问答 | 重点是问题定义、可验证性、研究价值,不依赖执行环境 | 给一个方向,让模型提出 3 个具体 open problems,并说明假设、实验验证和失败风险 |
| 创新性构思 | 客户端问答 | 主要测算法设计动机、机制一致性、是否不是简单拼接 | 要求设计一个新算法框架,包括目标函数、训练流程、推理流程和消融 |
| 数学与理论能力 | 客户端问答 | 推导、建模、复杂度、反例构造都适合静态问答 | 证明 QMIX 单调性是 IGM 的充分非必要条件;推导 Lagrangian primal-dual 更新 |
| 实验设计能力 | 客户端问答;智能体任务 | 客户端可测设计是否严谨;智能体可进一步测是否能写脚本跑实验 | 给一个方法,让模型设计任务、指标、baseline、ablation、统计检验和反证实验 |
| 代码与复现能力 | 智能体任务 | 真正的复现需要读 repo、装依赖、运行、debug、改脚本 | 客户端只能测代码阅读、伪代码 bug 识别、复现 checklist |
评测结果分析
整体效果:
| 模型 | 条理性与结构 | 表达清晰度 | 技术深度 |
|---|---|---|---|
| Claude Fable 5 | 非常系统化,每个问题拆解成多个子点(例如非平稳性、credit assignment、各算法局限) | 使用 Markdown/公式分层结构,概念解释清晰 | 对 MARL 基本概念和 CTDE/QMIX/COMA/CG 等有深刻理解,但在一些数学符号或公式精度上略保守 |
| GPT-5.5 | 条理性略偏自然语言流,仍保持分点 | 解释更口语化,强调直觉和因果关系 | 对理论概念和推理关系更深入,强调概率视角、因果机制和公式化表达,但公式过于冗长,容易分散注意力 |
细节维度分析:
| Dimension | Claude Fable 5 | GPT-5.5 | Evaluation Rationale |
|---|---|---|---|
| 内容准确度Conceptual Accuracy | 9.2 | 9.0 | 两者都准确。Claude 在 CTDE、centralized execution、communication boundary 上表述更紧凑;GPT-5.5 同样正确,但部分公式排版影响可读性。 |
| 推理深度Mechanistic Depth | 9.3 | 8.9 | Claude 对 IQL 非平稳性、relative overgeneralization、lazy agent、COMA counterfactual baseline 等机制解释更细。GPT-5.5 解释清楚,但机制层次略少。 |
| 数学逻辑Mathematical Rigor | 9.0 | 8.8 | 两者公式基本正确。Claude 在 IGM 证明中更注意 argmax 集合、充分非必要关系等边界;GPT-5.5 也正确,但格式扰动较明显。 |
| 结构比较Structural Comparison | 9.4 | 8.7 | Claude 对 Coordination Graph vs QMIX 的“单调 mixing vs 图上低阶交互项”比较更有洞察,尤其指出 CG 执行时需要图推理/消息传递,而 QMIX 是独立 greedy。 |
| 对方法的局限性分析Critical Limitation Awareness | 9.2 | 8.7 | Claude 对各方法局限展开更充分,例如 COMA 的 on-policy 样本效率、critic 可扩展性、高阶协同 credit limitation;GPT-5.5 也覆盖主要局限,但略更常规。 |
| 研究问题设计Research Problem Framing | 9.1 | 9.0 | 两者都能提出具体 open problems。Claude 更强调 offline、safe、partial observability 三者耦合;GPT-5.5 更偏实验落地与 benchmark 组织。 |
| 算法设计Algorithmic Originality | 9.0 | 8.9 | Claude 的 CORSET 设计中区分 reward graph 与 cost-side safety coupling,结构动机较强;GPT-5.5 的 DCSR-MARL 也清楚提出 dynamic coordination + safety responsibility + distillation。 |
| 实验设计Experimental Design | 8.8 | 9.2 | GPT-5.5 在实验设计上更强,给出了更系统的任务组、baseline、指标和反证实验,例如 reward-cost graph mismatch、非单调安全交互、高阶安全交互、Safe-MPE、SMAC/SMACv2 safety modification 等。 |
| 输出质量Communication Quality | 9.6 | 8.6 | Claude 的层次、标题、表格和论证节奏明显更稳定。GPT-5.5 内容扎实,文本中多处公式渲染成分隔线或破碎符号,影响阅读。 |
| 可靠性及校准Reliability & Calibration | 8.9 | 8.7 | 两者基本能说明“不保证训练过程安全、逐轨迹安全、全局最优”等 caveat。Claude 在 Lagrangian limitations 上展开更细,GPT-5.5 也覆盖了期望约束和 finite-sample 限制。 |
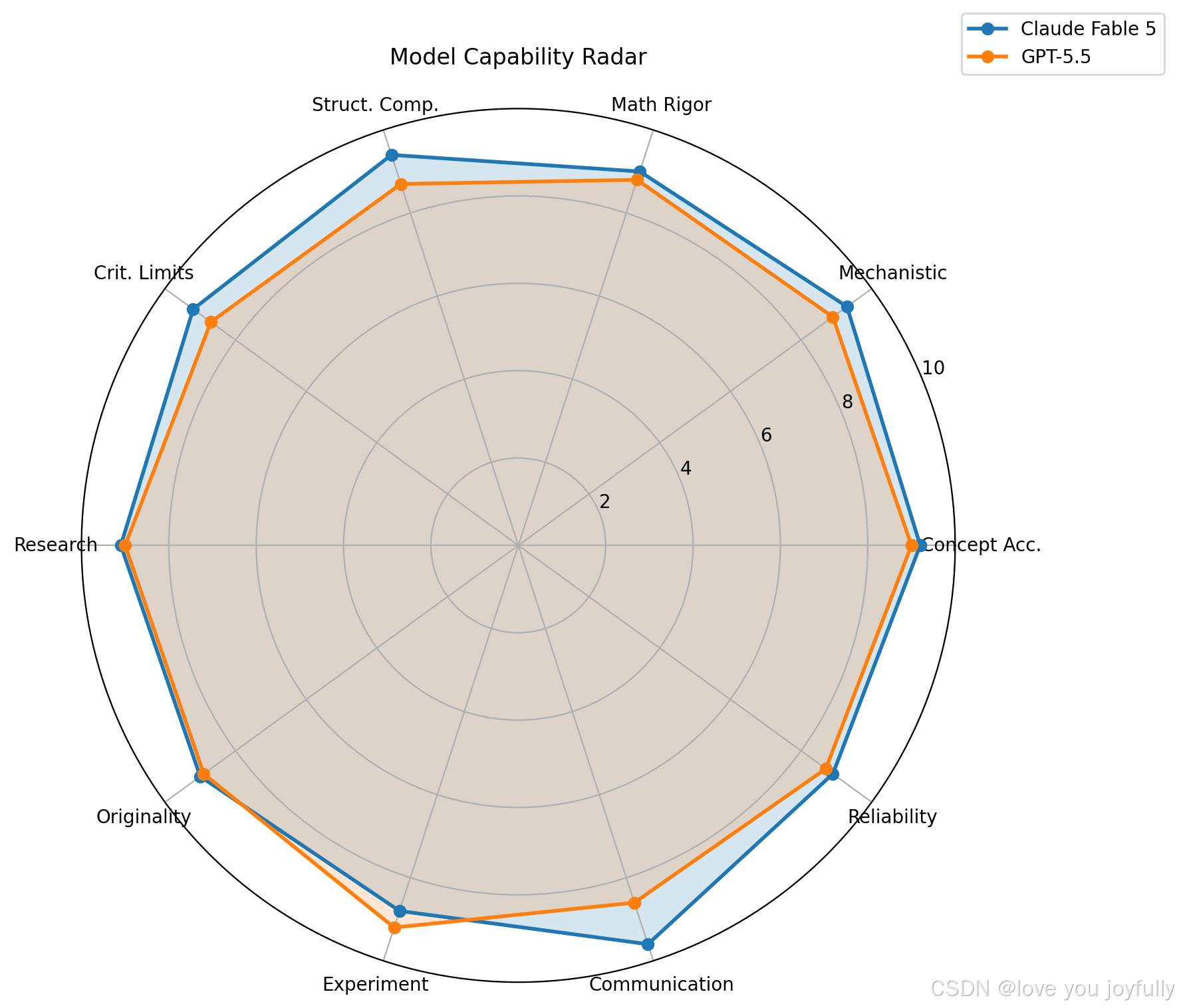
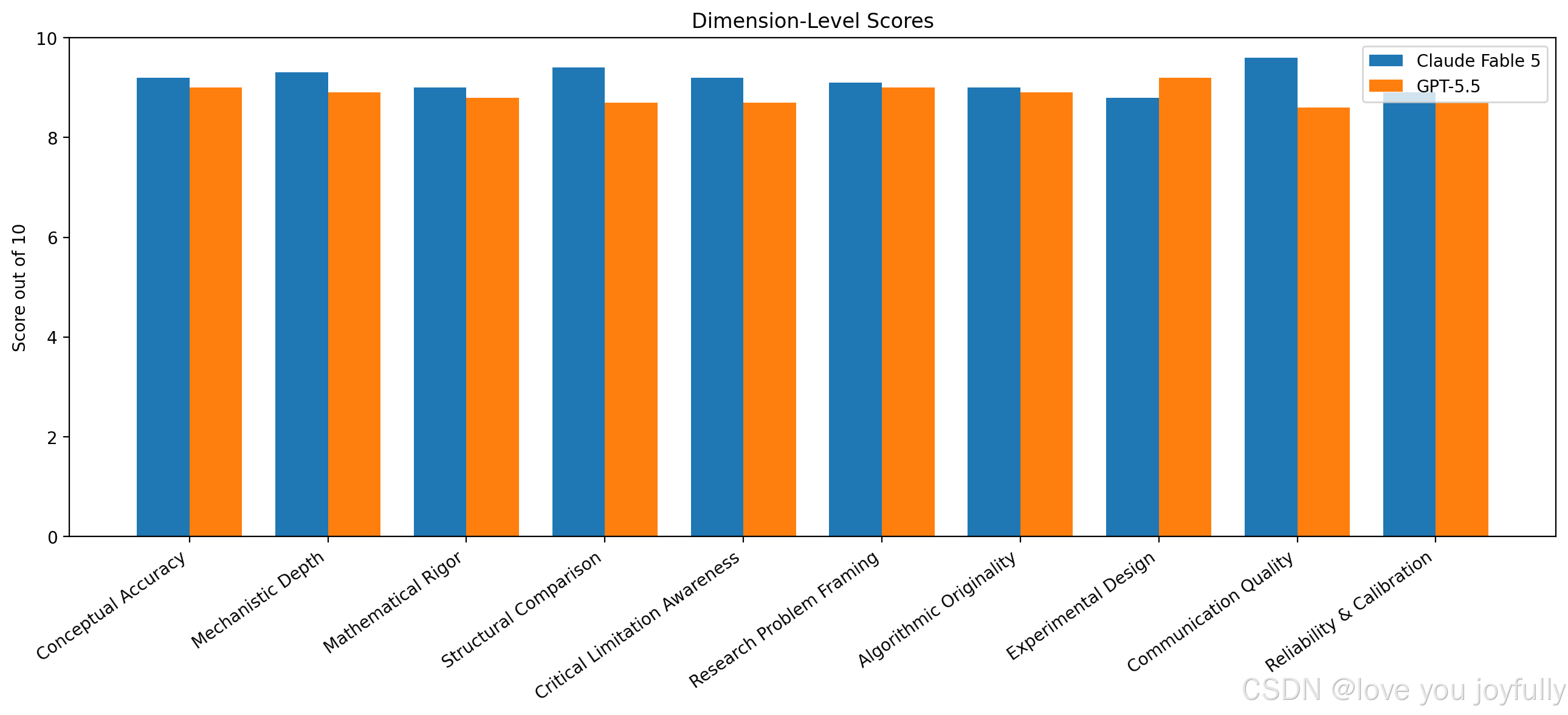
总体而言,在算法设计与创意能力上Claude Fable 5具有明显的优势,但是并没有比较大的差距,或许在不远的将来,这块的下一个霸者可以是gpt-5.6呢?谁也说不好,哈哈~

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)