
Langchain揭秘Agent核心系统:跟ChatGPT完全不同
作为一个基于Deep Agents框架的无代码平台,它主要面向非技术用户,帮助他们实现日常工作流的自动化。在最初阶段,开发团队就决定将重心放在记忆功能上。
近期,LangChain团队正式推出了LangSmith Agent Builder,并重点强调了其集成的“记忆”能力。为什么这项功能会被置于如此核心的地位?它背后的技术架构是怎样的?在开发过程中又有哪些核心经验?本文将带你一探究竟。
什么是 LangSmith Agent Builder?
作为一个基于Deep Agents框架的无代码平台,它主要面向非技术用户,帮助他们实现日常工作流的自动化。在最初阶段,开发团队就决定将重心放在记忆功能上。
“与ChatGPT、Claude或Cursor不同,LangSmith Agent Builder并非一个通用型的AI Agent。”
因为它主要执行重复性的定制化工作流,能够“记住过去的指令”对于提供顺畅的用户体验至关重要。
团队在设计时,参考了COALA框架中定义的三种记忆类型:程序性记忆(决定行为的规则)、语义记忆(事实性知识)以及情景记忆(过去的行为序列)。
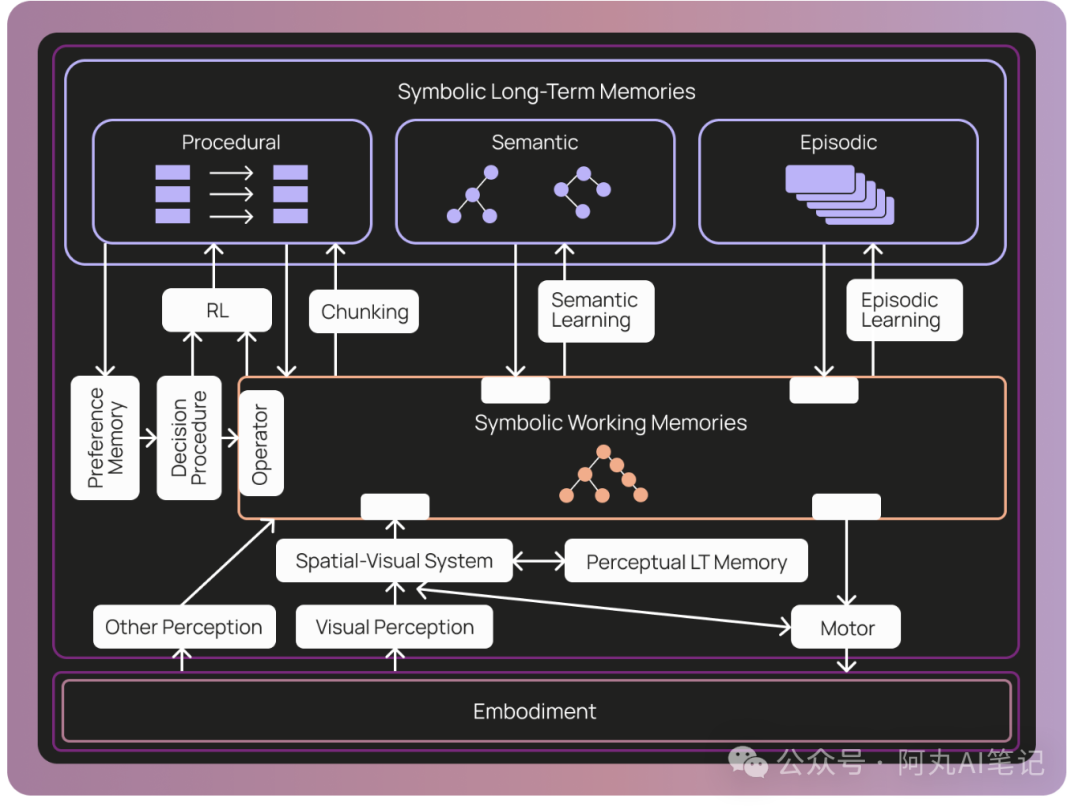
虚拟文件系统:记忆的底层架构
为了充分发挥AI模型处理文件结构的优势,系统将知识表示为由Postgres数据库支持的虚拟文件系统(也可以使用S3或者MySQL)。这种设计允许机器人无缝地读取和修改其自身的指令。
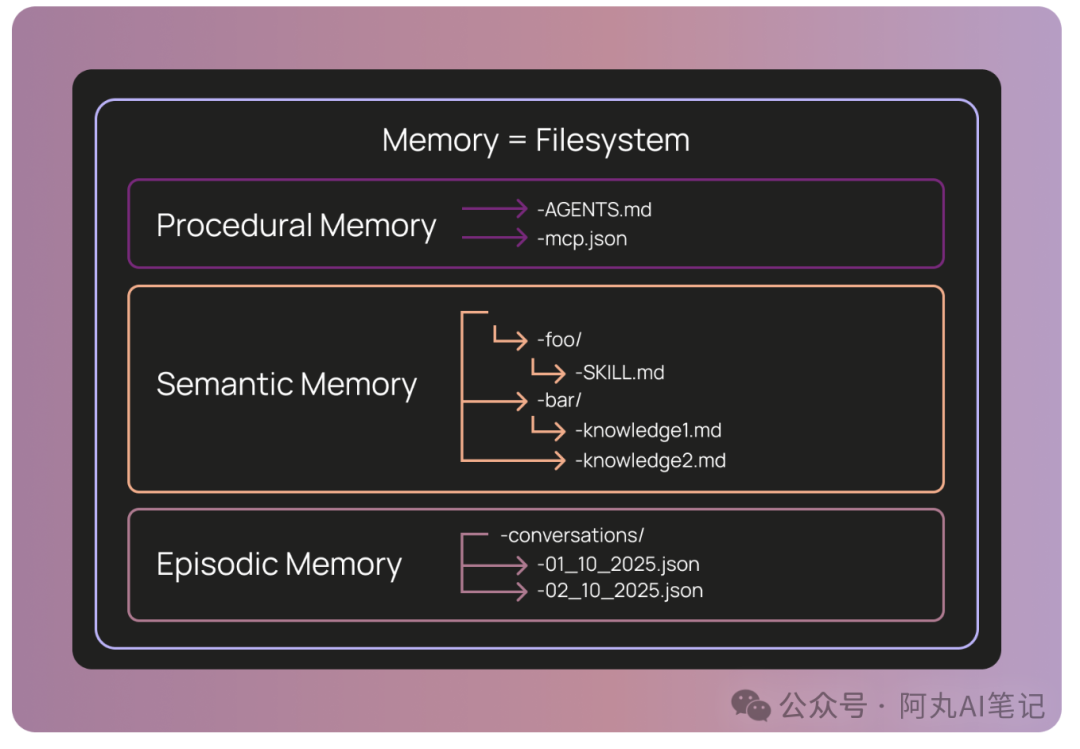
它们依赖像 AGENTS.md 这样的标准格式来存储主要指令,并通过专门的技能文件来保存语义事实。
在连接外部服务时,系统使用了一个自定义的 tools.json 文件,而不是标准的 mcp.json。这样做的目的是限制工具的访问权限,防止超出大模型的上下文窗口限制。底层的Deep Agents负责处理那些复杂的上下文任务,让用户只需通过简单的指令来引导机器人。
目前的架构已经成功地覆盖了程序性和语义性记忆的需求,不过在初期版本中尚未包含情景记忆功能。
文件系统中的记忆长什么样?
以一个内部的LinkedIn招聘机器人为例,它的文件系统结构非常清晰:包括一个主要的指令文件、一个用于候选人寻源的子Agent文件夹、一个连接MCP(模型上下文协议)的工具配置tools.json,以及AI主动管理和不断更新的各个候选人的独立文档。
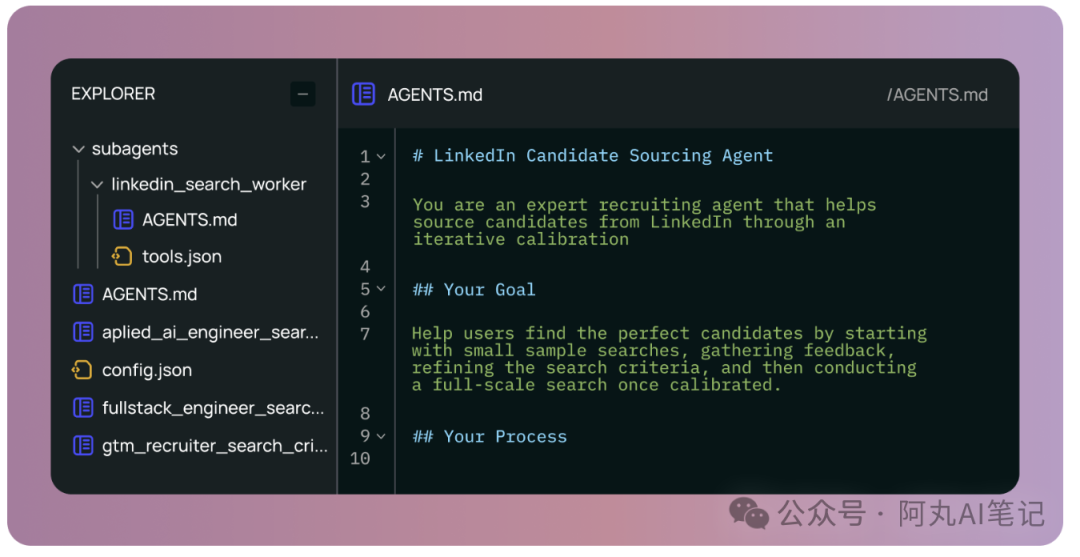
记忆是如何编辑的:一个具体例子
这个系统最强大的地方在于,它会在长期的交互中“有机地”完善自身行为。
比如,如果用户在第一周要求使用“项目符号”而不是长段落进行总结,机器人就会直接更新自己的配置文件。到了第二周,它便会自动应用这条新规则。
几个月后,系统将自主积累出一份庞大而详尽的格式偏好、参与者角色以及边缘情况清单。
“AGENTS.md 文件是通过在日常使用中不断地纠正构建起来的,而不是依靠人工预先撰写的详尽文档。”
开发过程中的血泪教训
在构建这个系统的过程中,团队遇到了不少挑战:
• 提示词优化是最大难关 - 团队投入了大量资源去解决AI“记错细节”或“将文件格式弄乱”的问题。
• 严格的Schema验证 - 因为AI偶尔会生成格式损坏的文件,所以必须在底层引入严格的格式校验。
• 泛化能力不足 - 虽然AI在添加“新规则”时表现出色,但在“合并或泛化”现有规则时却显得有些吃力。
• 安全与防御 - 为了抵御提示词注入攻击,系统默认要求在更新文件之前必须经过人工的明确批准(高级用户可选择关闭)。
这一切带来了什么?
将知识作为标准文件来处理,为非程序员提供了一个高度可扩展且易于访问的接口。它极大地简化了迭代创建过程——操作者可以通过自然语言对话来微调AI设置,全程无需编写任何代码。
同时,这种基于文件的方法也确保了创建出来的Agent配置在不同AI框架之间具有极高的可移植性。
未来的发展方向
团队计划在未来的版本中进行多项重磅增强。首先是通过赋予AI访问历史聊天记录的权限,来正式引入“情景记忆(Episodic recall)”。
此外,他们还希望实现自动化的后台任务来定期整合积累的知识,添加专门的“反思(Reflection)”命令,引入语义搜索功能,并将记忆的存储范围扩展到覆盖用户和整个组织层级。目前,LangChain团队也在积极招聘开发者,以进一步扩展这些令人兴奋的AI能力。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)