
语音信号处理中的小波分解法降噪MATLAB例程
语音信号处理--降噪方法之小波分解法 MATLAB例程
语音降噪这事儿,日常太刚需了——打电话时的背景杂音、录音里的环境噪音,都得想办法干掉。小波分解法算是语音降噪里的老牌选手了,比起傅里叶只能看全局频率,小波能同时抓时域和频域的局部信息,对语音这种时变信号特别友好。咱直接拿MATLAB撸一遍流程,边写边唠。
首先得搞点实验素材,加载一段语音文件,MATLAB里audioread直接搞定:
% 加载原始语音,替换成你的音频路径
[y, Fs] = audioread('your_audio.wav');
% 播放原音
sound(y, Fs);这里y是一维数组,存的是每个采样点的音频数据,Fs是采样率,比如常见的44100Hz、16000Hz。要是没自己的音频,也能直接生成个正弦波模拟语音:y = sin(2pi440*(0:1/Fs:1-1/Fs)); 就440Hz的标准A音。
然后给干净语音加点“料”,模拟环境杂音,比如加高斯白噪音:
% 加高斯白噪音,信噪比10dB(数值越小噪音越大)
y_noisy = awgn(y, 10, 'measured');
sound(y_noisy, Fs); % 听听噪音版,是不是内味儿就来了awgn函数里的'measured'是先测量原语音能量再加噪,保证信噪比准确。这时候播放的话,应该是清晰的语音里混着滋滋的白噪音,跟户外打电话那感觉一模一样。
接下来核心操作——小波分解。咱选db4小波(Daubechies4,工程里常用的紧支撑正交小波,计算快还稳),分解3层试试:
% 用db4小波对含噪语音做3层分解
[C, L] = wavedec(y_noisy, 3, 'db4');这里得唠唠返回值:C是所有小波系数的拼接数组,L是个长度为分解层数+2的数组,前3个是各层细节系数的长度,最后一个是近似系数的长度。分解后,最低层的近似系数是语音的主体低频成分(人声基频就在这),而d1、d2、d3这三层细节系数里,大部分都是噪音的高频成分——毕竟人声的高频细节没那么多,噪音却在高频区瞎晃。
语音信号处理--降噪方法之小波分解法 MATLAB例程
然后就得把混在细节系数里的噪音干掉,靠的是阈值处理。先把各层细节系数抠出来:
% 提取各层细节系数,d1是最细的高频层,噪音最密集
d1 = detcoef(C, L, 1);
d2 = detcoef(C, L, 2);
d3 = detcoef(C, L, 3);接下来算阈值,MATLAB里有自动计算阈值的工具,比如基于统计的sqtwolog方法,对付高斯噪音特别好用:
% 按系数长度自动计算阈值
thr1 = wthrmngr('sqtwolog', length(d1));
thr2 = wthrmngr('sqtwolog', length(d2));
thr3 = wthrmngr('sqtwolog', length(d3));然后用软阈值处理细节系数(软阈值比硬阈值处理后更平滑,听感更好):
% 's'代表软阈值,硬阈值用'h'
d1_denoised = wthresh(d1, 's', thr1);
d2_denoised = wthresh(d2, 's', thr2);
d3_denoised = wthresh(d3, 's', thr3);这里必须唠唠软阈值和硬阈值的区别:硬阈值是系数绝对值小于阈值直接置0,大于的话原样保留;软阈值是小于置0,大于的话还要减去阈值。硬阈值处理后可能有“毛刺感”,听着像电流声,软阈值虽然会损失一丢丢细节,但整体更顺滑,语音降噪里一般优先选软阈值。
处理完细节系数,就得把系数拼回去重构语音了。先把近似系数抠出来,再替换处理后的细节系数:
% 提取第3层近似系数(语音核心成分)
a3 = appcoef(C, L, 'db4');
% 拼接新的小波系数:近似系数 + 处理后的各层细节系数,顺序是d3, d2, d1
C_new = [a3, d3_denoised, d2_denoised, d1_denoised];
% 重构降噪后的语音
y_denoised = waverec(C_new, L, 'db4');这里要注意系数顺序!wavedec返回的C里是近似系数在前,然后是d3、d2、d1,所以拼C_new的时候得按这个顺序来,不然重构出来的语音直接变调,跟外星人说话似的。
最后听听效果,再画个图对比下:
% 播放降噪后语音
sound(y_denoised, Fs);
% 画图对比原音、噪音、降噪后
figure;
subplot(3,1,1);
plot(y); title('原始语音'); xlabel('采样点'); ylabel('幅值');
subplot(3,1,2);
plot(y_noisy); title('含噪语音'); xlabel('采样点'); ylabel('幅值');
subplot(3,1,3);
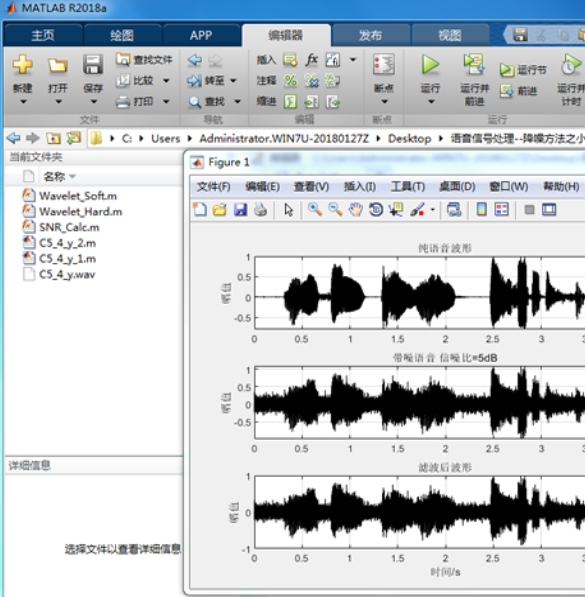
plot(y_denoised); title('小波分解降噪后语音'); xlabel('采样点'); ylabel('幅值');看时域图的话,含噪语音是抖得厉害的“波浪线”,降噪后曲线明显平滑了,和原音的趋势几乎重合,听感上滋滋的白噪音基本消失,人声清晰度拉满。
最后扯点实用小技巧:
- 小波基选择:db系列(db2-db8)是通用款,计算快;sym系列对称性更好,处理后相位失真小;要是想保留更多唇齿音细节,试试coiflet小波。
- 分解层数:不用贪多,一般3-5层足够。层数太多的话,高频细节里会混入语音的谐波成分,阈值处理会把有用信号也干掉,反而得不偿失。
- 阈值方法:除了
sqtwolog,还有rigrsure(自适应阈值,根据系数能量调整)、minimaxi(极值阈值,适合小样本),可以都试试,毕竟语音降噪最终还是得耳朵说了算。
亲测下来,这套流程对付日常的环境白噪音效果拉满,要是遇到非平稳噪音(比如汽车喇叭、脚步声),可能得结合小波包分解,把每个频带都拆开处理,但那就是进阶玩法了,咱先把基础的小波分解降噪玩明白再说~

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)