
2026年全球闭源大模型排名与全面评估(含头部模型深度解析)
前言:2026年是全球闭源大模型竞争白热化的一年,OpenAI、Anthropic、Google等国际巨头持续迭代旗舰产品,阿里巴巴、智谱AI等中国厂商也实现技术突破,形成“国际头部领跑、国产并跑突围”的竞争格局。本文将从第一梯队旗舰模型、第二梯队新兴模型两大维度,结合技术性能、商业化程度、创新能力、行业认可度四大核心维度,对2026年全球主流闭源大模型进行全面解析,为开发者、企业选型提供参考。
一、全球闭源大模型技术发展与评估
1.1 第一梯队大模型综合评估(头部旗舰模型深度解析)

GPT-5.2 系列(OpenAI)
GPT-5.2 作为 OpenAI 在 2026 年推出的旗舰模型系列,代表了当前闭源大模型技术的最高水平,包含 GPT-5.2 Auto、GPT-5.2 Instant 和 GPT-5.2 Thinking 三个核心版本,形成覆盖不同场景的完整产品矩阵,是目前企业级应用的首选模型之一。
技术架构:引入革命性的自适应推理系统,这是业界首次实现“智能选择推理模式”的设计——GPT-5.2 Auto 可作为统一入口,根据任务复杂度自动调用 Instant(快速响应)或 Thinking(深度推理)版本,标志着大模型从“单一能力输出”向“智能化适配任务”的关键转变。
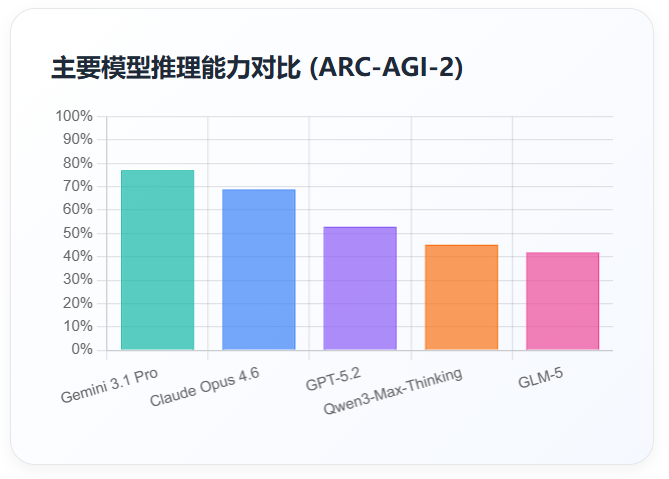
性能表现:多项权威评测稳居领先,AIME 2025 数学测试实现 100% 准确率,ARC-AGI-2 测试得分 52.9%,推理能力保持业界顶尖;核心亮点是幻觉率降至 6.2%,较前代降低 40%,大幅提升了模型在高精度场景(如金融、医疗)的可靠性。
商业化程度:市场统治力突出,年化收入达 140 亿美元,其中企业 API 收入占比 91%,服务 5.7 万+ 企业客户,全球科技百强企业合作占比 72%;最大优势是中立性——唯一可在 AWS、Azure、Google Vertex 三大云平台部署,避免企业平台锁定风险,灵活性拉满。
定价策略:采用分层收费模式,适配不同用户需求:免费版每 5 小时限 10 条消息,Plus/Go 用户每 3 小时限 160 条消息,Business/Pro 方案提供无限访问(含滥用防护);虽定价偏高,但结合其性能和稳定性,在高价值场景中不可替代。
Claude Opus 4.6(Anthropic)
Claude Opus 4.6 于 2026 年 2 月 5 日发布,核心突破集中在编程能力和长文本处理,是软件开发、复杂文档分析场景的最优解之一,延续了 Anthropic 对“实用化”的深耕。
核心优势:编程能力业界最强、超长上下文支持、自适应思考系统,三大亮点形成差异化竞争力。
编程能力:SWE-bench 测试准确率 80.9%,终端编程(Terminal-Bench 2.0)得分 65.4%,电脑操控能力 72.7%,智能体搜索能力 84%,实现断层式领先,在代码生成、调试、系统操作等场景表现突出。
上下文处理:首次在 Opus 级别开放 100 万 token 上下文窗口(测试版),远超 GPT-5.2 的 256K 标准窗口,可高效处理大型代码库、长文档,适配复杂项目开发、文献分析等场景。
技术创新:推出自适应思考(Adaptive Thinking)系统,废弃传统“思考开/关”模式,采用语义化 effort 参数实现细粒度控制,可根据任务复杂度自动调整推理强度,兼顾输出质量与计算效率。
商业化应用:已全面上线 claude.ai、官方 API 及主流云平台,保持原有定价(每百万 token 输入 5 美元、输出 25 美元),在性能大幅提升的同时维持高性价比,深受开发者青睐。
Gemini 3.1 Pro(Google)
Gemini 3.1 Pro 于 2026 年 2 月正式发布,是 Google 大模型技术的里程碑产品,核心优势集中在推理能力、超长上下文和原生多模态,在多媒体处理场景形成绝对壁垒。
推理能力:ARC-AGI-2 测试准确率 77.1%,较前代 Gemini 3 Pro(31.1%)翻倍,大幅领先 Claude Opus 4.6(68.8%)和 GPT-5.2(52.9%),在复杂多步推理、知识整合任务中实现历史性突破。
上下文处理:原生支持 200 万 token 上下文窗口,是目前主流模型中最长,可一次性处理《三体》三部曲体量的文本,输出上限提升至 65,536 tokens(较前代增加 50%),确保复杂任务完整输出。
多模态能力:原生支持文本、图像、音频、视频、PDF 等全模态输入,无需预处理或外部工具;实际应用中可生成复杂 3D 星椋鸟群飞动画,同步生成视觉代码、手势追踪交互和动态音乐,沉浸式体验拉满。
技术创新:业界首创三层思考模式(Low/Medium/High),首次实现“计算-质量-成本”三角关系的显式化管理,用户可根据需求调整计算强度,平衡输出质量与资源消耗。
商业化部署:已在 Google Cloud 全面上线,与 Google Workspace 深度集成;定价偏高,但结合其多模态和超长文本优势,仍是多媒体处理、复杂交互场景的首选。
Qwen3-Max-Thinking(阿里巴巴)
Qwen3-Max-Thinking 于 2026 年 1 月 26 日发布,是国产大模型的标杆产品,标志着中国大模型从“跟随”向“并跑、领跑”转变,尤其在中文场景和性价比方面优势显著。
技术规格:采用万亿参数级 MoE(混合专家)架构,总参数超 1T,活跃参数 22B,与 GPT-5.2、Gemini 3 Pro 处于同一梯队;19 项关键基准测试中与国际顶级模型平分秋色,HMMT Feb 复杂数学测试 98.0 分,AIME25 测试 92.3% 准确率。
核心能力:多轮自反思能力超越 Gemini 3 Pro,数学、推理、编程、知识、工具使用五大维度均衡发展;中文能力碾压所有国际竞品,自适应工具调用(自动选择 Search、Memory 等工具)、Agentic 能力对标 Claude,原生支持 119 种语言,推理步骤可控可解释。
性价比优势:价格较 GPT-5.2 便宜 50% 以上,中文能力强 10 倍;较 Claude Opus 4.5 推理能力更强、性价比更优;较 Gemini 3 速度更快、成本低 50%,是中文用户和成本敏感型企业的首选。
1.2 第二梯队及新兴大模型分析(开源+高性价比首选)
第二梯队模型以“开源、高性价比、场景化”为核心优势,虽整体性能略逊于第一梯队,但在特定场景和成本敏感型需求中表现突出,尤其国产模型占据主导地位,成为全球开源市场的重要力量。
智谱 GLM-5(智谱 AI)
2026 年 2 月 12 日发布并开源,由智谱 AI 与清华大学联合研发,是目前开源模型中参数规模最大的产品之一,定位为复杂系统工程与长程 Agent 任务的基座模型。
技术架构:采用 744B 总参数、40B 激活参数的 MoE 架构,具备强大的知识存储和复杂推理能力,适配长程依赖任务。
性能表现:SWE-bench 测试代码通过率 77.8%,位列开源模型第一;擅长复杂智能体任务、多工具协同和长链思考,在政务、学术、金融工程等高精度场景表现优异。
应用优势:采用 MIT 许可证,支持研究和商业应用双重场景,兼顾开放性与商业化灵活性,是国产开源模型的核心代表之一。
DeepSeek R1(深度求索)
深度求索 2026 年推出的推理专用开源模型,基于 Transformer 架构,采用多阶段训练、强化学习等技术,专门优化推理任务,是接近 GPT-5 水平的高性价比选择。
核心亮点:完全开源可自部署,免费使用;采用与 GPT-o1 相同的 Thinking 架构,推理能力仅比 GPT-5 低 1-2%,但成本仅为 GPT-5 的 2%,性价比极高。
性能与部署:数学推理接近人类水平,代码生成、知识问答表现优异;支持本地部署,保障企业数据隐私,具备完整思维链和推理过程可视化,适配可解释性需求场景。
Kimi K2.5(月之暗面)
2026 年 1 月 27 日发布的开源多模态模型,采用 MoE 架构,核心优势是长文本处理和低门槛部署,在办公自动化场景广泛应用。
技术架构:总参数 1 万亿,但每处理 1 个 token 仅激活 320 亿参数,可在消费级硬件上微调,大幅降低使用门槛,践行“大而不笨”的技术路线。
核心能力:支持 200 万 token 超长上下文窗口,适配超大型文档、复杂代码库处理;擅长文档摘要、表格解析、PDF/Excel/PPT 全链路处理,是个人和企业知识管理的常用工具。
MiniMax M2.5(MiniMax)
MiniMax 旗舰产品,主打轻量化高性能,采用稀疏 MoE 架构(激活参数 10B),在低成本、实时交互场景表现突出。
效率优势:推理成本仅为旗舰模型的 1%,但性能接近旗舰水平,是成本敏感型场景的最优解;全球调用量位列 OpenRouter 平台前五,与其他三款国产模型合计占据 Top5 总调用量的 85.7%。
应用场景:适配轻量化部署和实时交互,原生支持 Agent 能力,在智能客服、实时翻译、内容生成等快速响应场景表现优异。
1.3 闭源大模型综合对比分析(2026核心指标汇总)
结合多个权威评测机构数据,从技术性能、商业化程度、创新能力、行业认可度四大维度,对主流模型进行综合对比,为选型提供清晰参考。
1. 技术性能对比(核心指标)
-
推理能力:Gemini 3.1 Pro(ARC-AGI-2 77.1%)> Claude Opus 4.6(68.8%)> GPT-5.2(52.9%),Google 在复杂推理领域实现突破。
-
编程能力:Claude Opus 4.6 断层领先(SWE-bench 80.9%),终端编程、电脑操控、智能体搜索能力均为业界第一。
-
数学推理:GPT-5.2 最优(AIME 2025 100% 准确率),幻觉率 6.2%(较前代降 40%),高精度场景可靠性最高。
-
多模态能力:Gemini 3.1 Pro 绝对领先,原生支持全模态输入,无需预处理,跨模态生成与交互能力突出。
-
上下文窗口:Gemini 3.1 Pro(200 万 token)> Claude Opus 4.6(100 万 token 测试版)> GPT-5.2(256K token 标准版)。
2. 商业化程度评估
-
市场规模:2026 年全球 AI 大模型市场规模 8720 亿美元,同比增速 78.5%,企业级服务占比 74.3%,成为行业增长主力。
-
客户基础:GPT-5.2 领先,年化收入 140 亿美元,企业 API 收入占比 91%,服务 5.7 万+ 企业客户,全球科技百强合作占比 72%。
-
云平台支持:GPT-5.2 唯一支持 AWS、Azure、Google Vertex 三大云平台,中立性优势显著;其他模型多局限于自有或单一云平台。
-
定价策略:Qwen3-Max-Thinking 性价比最高(较 GPT-5.2 便宜 50%+);Claude Opus 4.6 定价稳定;GPT-5.2 分层收费适配全场景;Gemini 3.1 Pro 定价偏高但多模态优势明显。
3. 创新能力评估
-
架构创新:GPT-5.2 自适应推理系统(智能选择模型版本);Claude Opus 4.6 自适应思考系统(effort 参数细粒度控制);Gemini 3.1 Pro 三层思考模式(显式管理计算-质量-成本)。
-
功能创新:GPT-5.2 幻觉控制突破;Claude Opus 4.6 编程与长文本能力飞跃;Gemini 3.1 Pro 全模态原生支持;Qwen3-Max-Thinking 自适应工具调用与中文优势。
-
应用创新:Gemini 3.1 Pro 沉浸式多模态交互(3D 动画+手势追踪+动态音乐),引领 AI 应用与用户交互的融合方向。
4. 行业认可度分析
-
第三方评测:LMArena 综合榜单前三:claude-opus-4-6、gemini-3.1-pro-pr、grok-4.20-beta1;国产 Seed 2.0 位列第 9,是唯一进入全球前十的国产大模型。
-
市场份额:OpenRouter 平台 Top5 大模型中,4 款来自中国(MiniMax M2.5、Kimi K2.5、智谱 GLM-5、DeepSeek V3.2),合计占总调用量 85.7%。
-
用户采用:中国开源模型调用量三周暴涨 127%,首次超越美国模型;80% 美国 AI 初创企业选择中国开源模型,凸显国产模型的技术与性价比优势。
-
生态建设:OpenAI 生态最广泛(API+开发者工具);Google 深度集成自有产品(Android、Chrome);Anthropic 开源友好;中国厂商通过开源快速扩大全球影响力。
二、总结与展望
2026 年全球闭源大模型呈现“三足鼎立+国产突围”的格局:OpenAI、Anthropic、Google 占据第一梯队,凭借技术积累和生态优势主导高端企业市场;中国厂商通过开源策略和场景化创新,在第二梯队形成绝对优势,实现从“并跑”向“领跑”的突破。
未来发展趋势清晰:一是多模态融合成为核心竞争力,Gemini 3.1 Pro 已树立标杆,后续各厂商将持续发力全模态交互;二是轻量化、低成本成为重要方向,MiniMax M2.5、DeepSeek R1 等模型验证了“小而精”的可行性;三是开源与闭源协同发展,开源模型降低使用门槛,闭源模型聚焦高端商业场景;四是中文大模型将持续突破,在本土场景和国际市场的竞争力将进一步提升。
对于开发者和企业而言,选型需结合自身需求:高价值企业级场景优先选择 GPT-5.2(中立灵活)、Gemini 3.1 Pro(多模态);编程、长文本场景优先 Claude Opus 4.6;中文场景、成本敏感型需求优先 Qwen3-Max-Thinking、智谱 GLM-5 等国产模型。
后续将持续跟踪各模型的迭代动态,及时更新技术评估,助力大家精准把握大模型技术趋势与选型方向。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)