
Ollama本地部署,轻松搭建专属 AI 助手
在人工智能飞速发展的当下,各类大语言模型如雨后春笋般涌现。我们在享受云端 AI 服务带来便利的同时,也面临着数据隐私、网络依赖等诸多问题。有没有一种办法,既能享受强大 AI 的服务,又能规避这些困扰呢?答案就是本地部署。它让你无需依赖云端,在自己的设备上就能运行 AI 模型,实现高效、私密的 AI 交互。 本文主要知道您进行Ollama的本地部署,另外您还能在Ollama中找到最近非常热门的deepseek-r1模型部署到您的电脑中。接下来,就让我们一同深入探索Ollama本地部署的神奇世界吧!
一.下载安装Ollama
1.下载Ollama
通过Ollama官网,下载适合你电脑的版本,这里以Windows电脑为例。
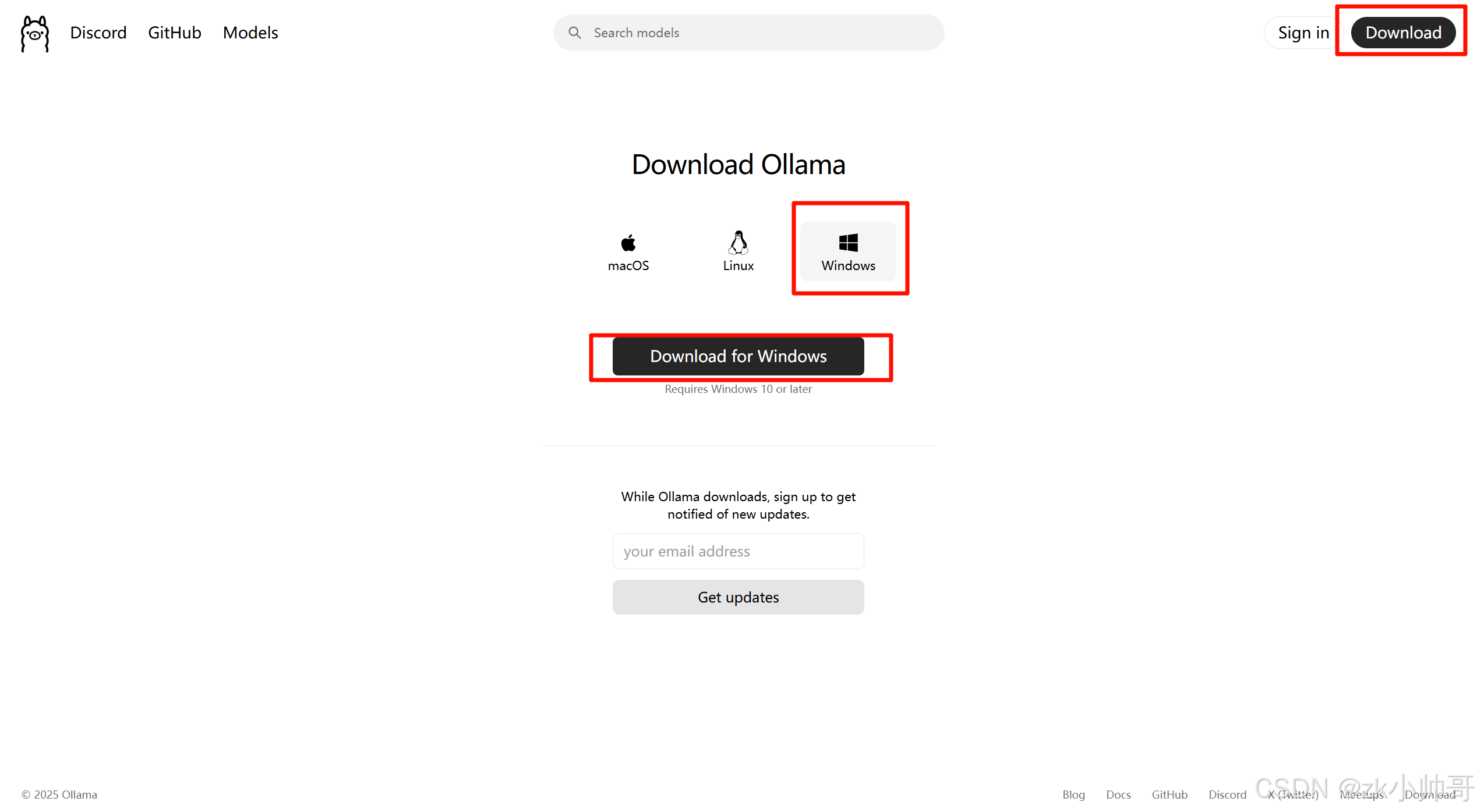
2.安装Ollama
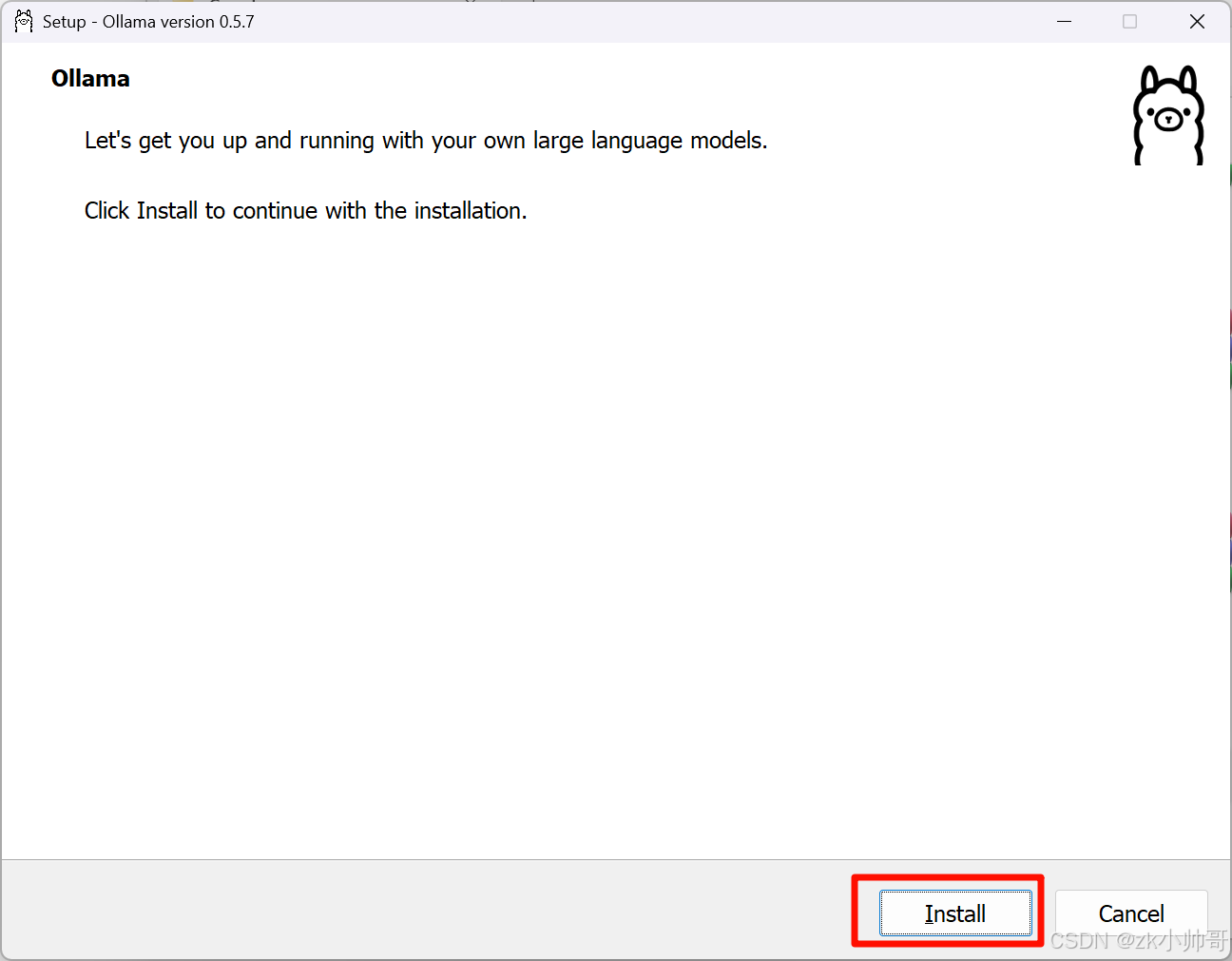
安装Ollama。
二.部署本地模型
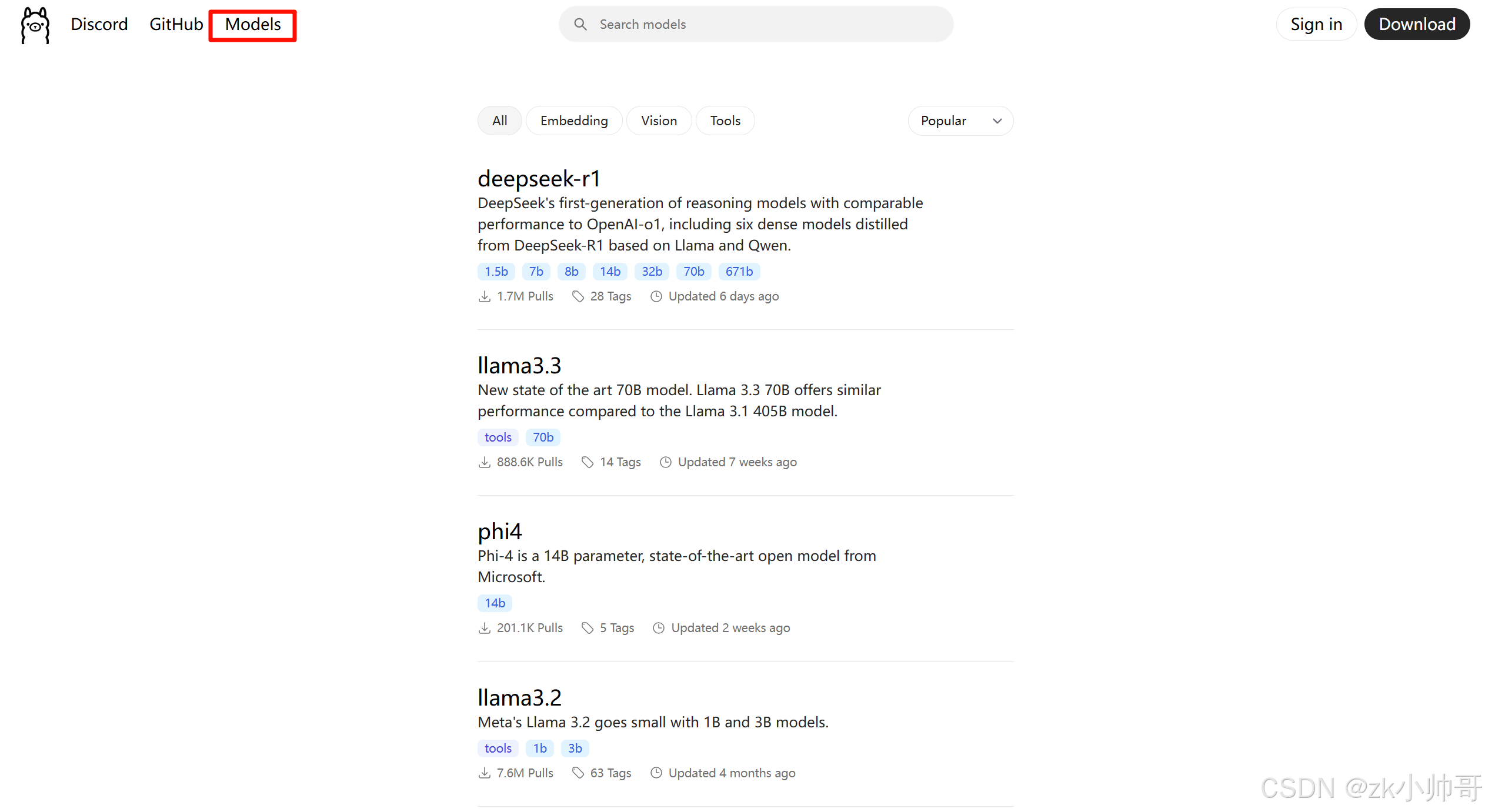
1.在官网Models中找到适合自己的模型
我这里部署deepseek-r1模型。deepseek-r1是DeepSeek第一代推理模型,性能与OpenAI-o1相当,其中包括基于Llama和Qwen从DeepSeek-R1提炼出的六个密集模型。分别有:1.5b,7b,8b,14b,32b,70b,671b。

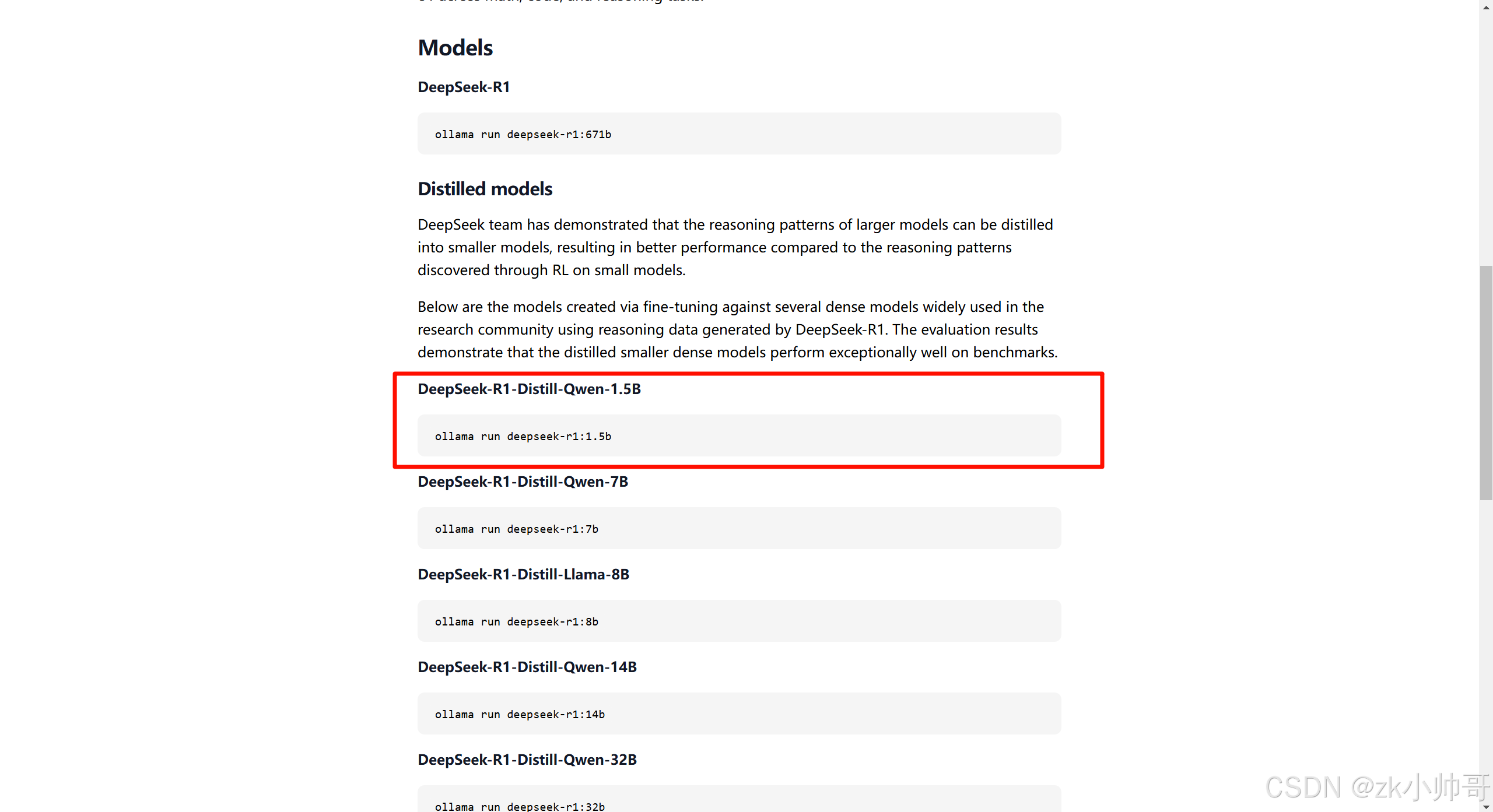
可根据自己电脑的性能选取模型,我这里选取DeepSeek-R1-Distill-Qwen-1.5B。
2.命令行下载模型
打开Windows自带的cmd,将Ollama官网DeepSeek-R1-Distill-Qwen-1.5B命令复制到cmd中,即可开始下载。
耐心等待下载完成....................................
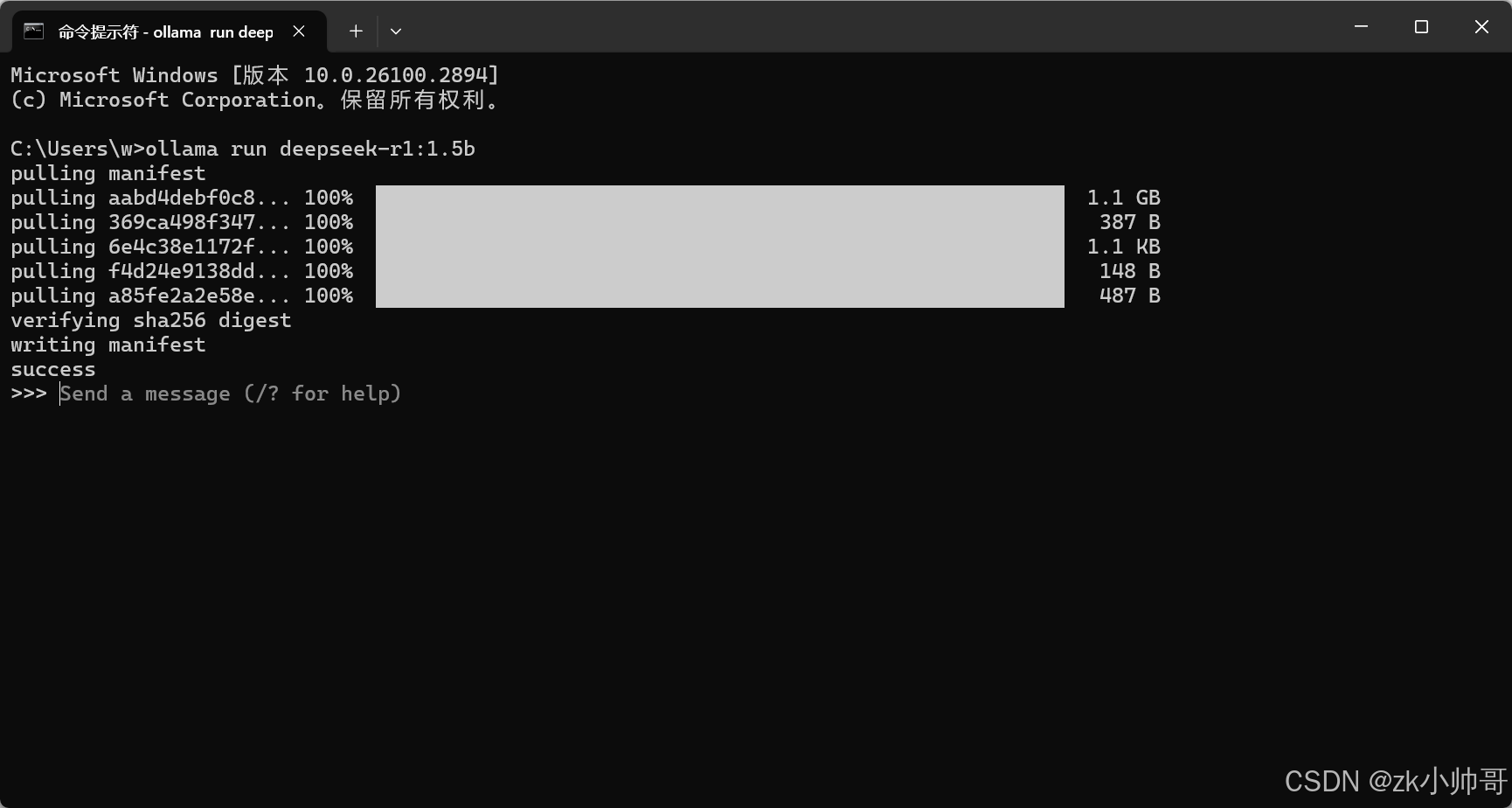
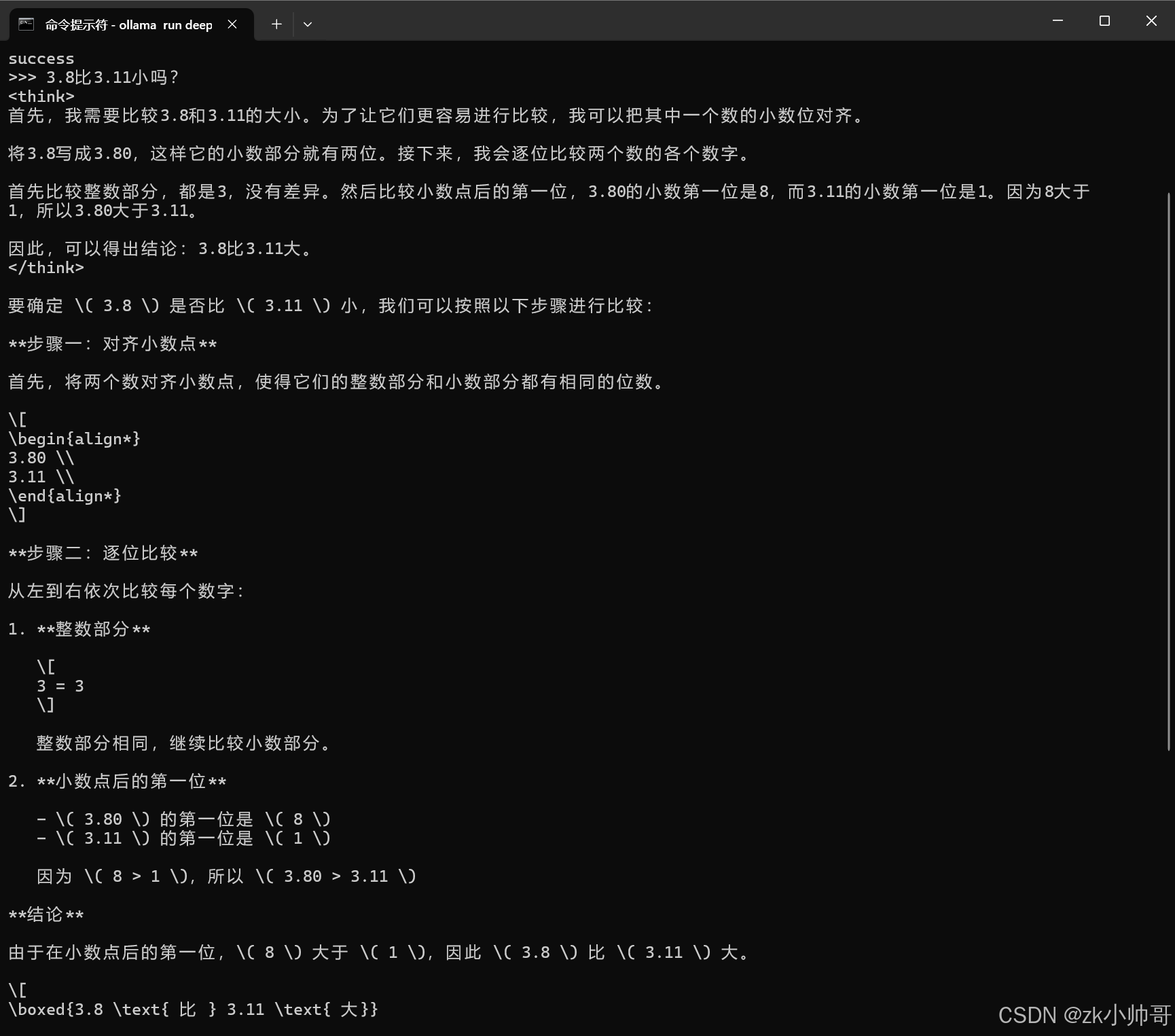
出现上图界面即安装DeepSeek-R1-Distill-Qwen-1.5B完成,现可向其提问,我这里的问题是:“3.8比3.11小吗?”。
输入/bye,即可退出。
/bye
3.使用AI模型桌面客户端部署模型
我这里使用Chatbox进行部署。Chatbox是一款AI模型桌面客户端,支持ChatGPT、Claude、Google Gemini、Ollama等主流模型,适用于Windows、Mac、Linux、Web、Android和iOS全平台。我们可在github中找到并使用(或在其官网chatboxai.app进行下载或使用其网页版)。
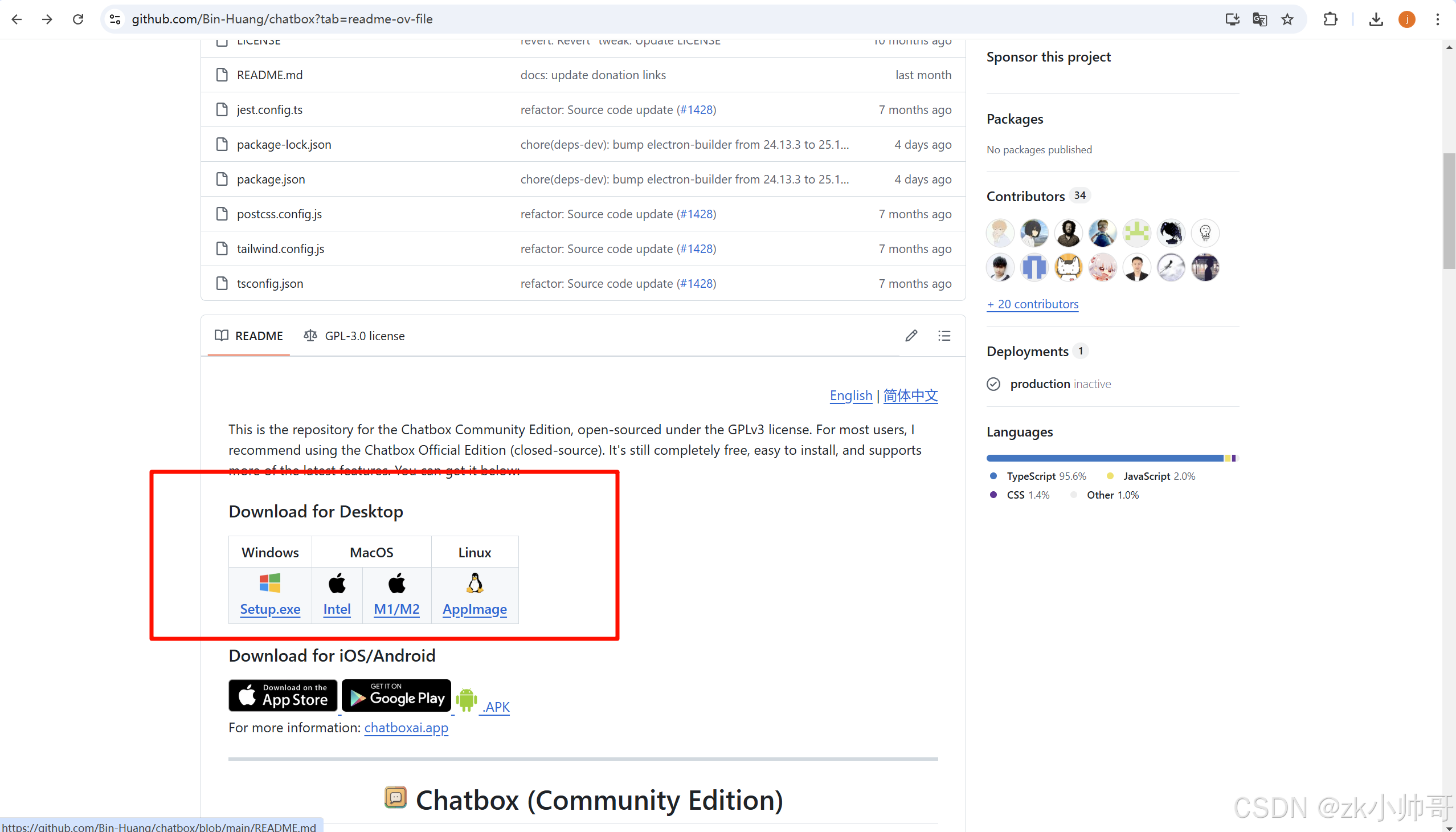
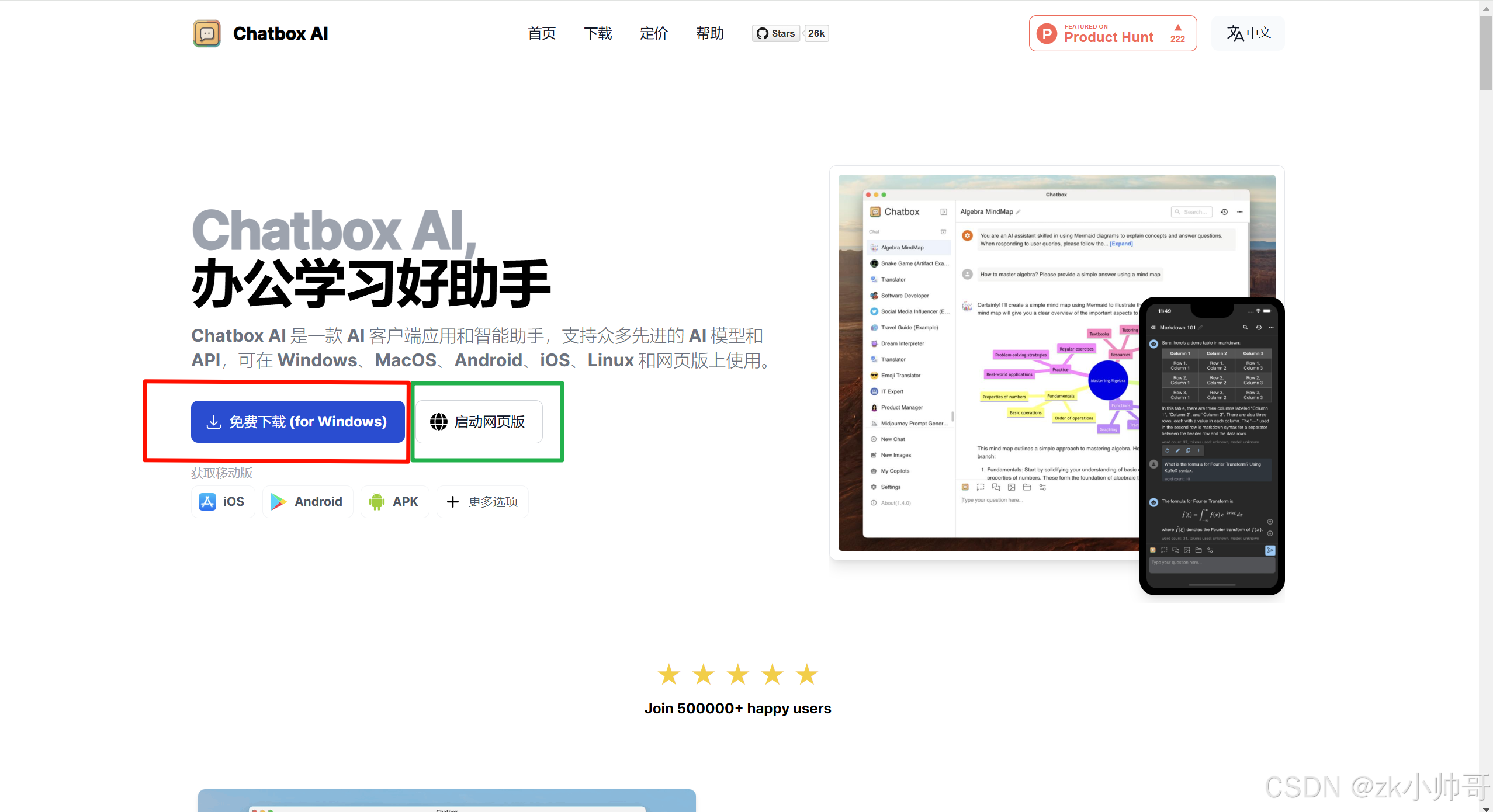
这里根据需求下载安装Windows桌面客户端。下载完后,打开应用,在设置中选择Ollama。
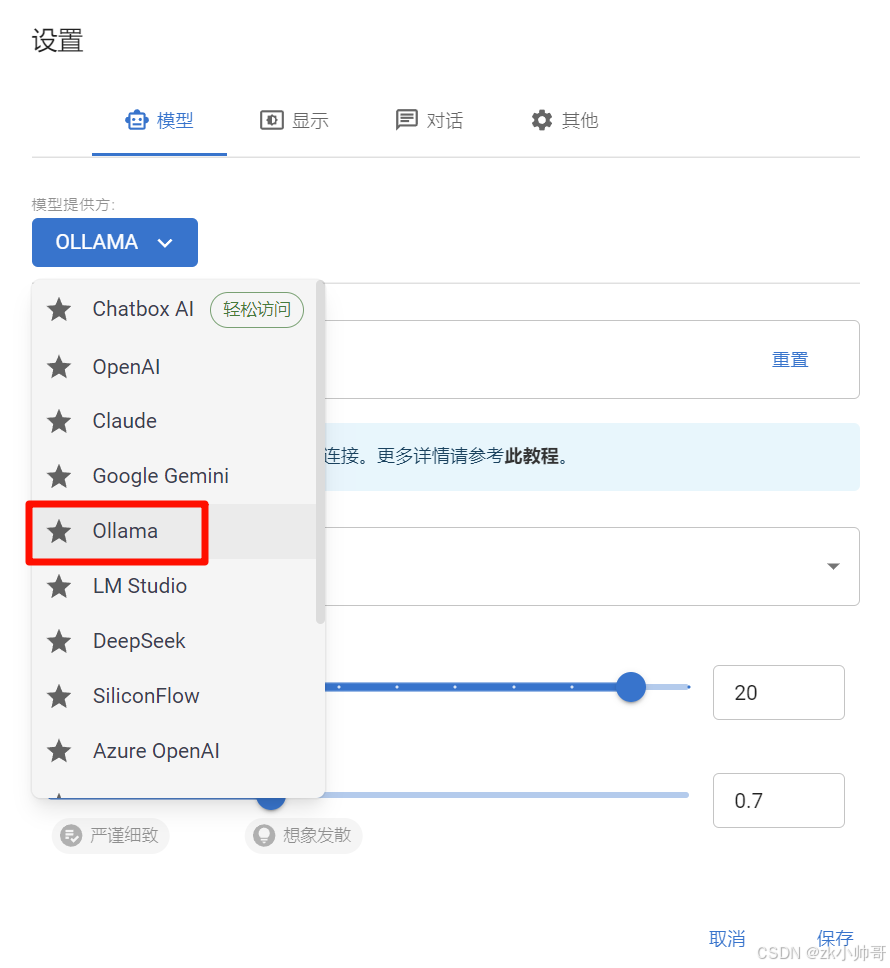
选择你下载的模型。
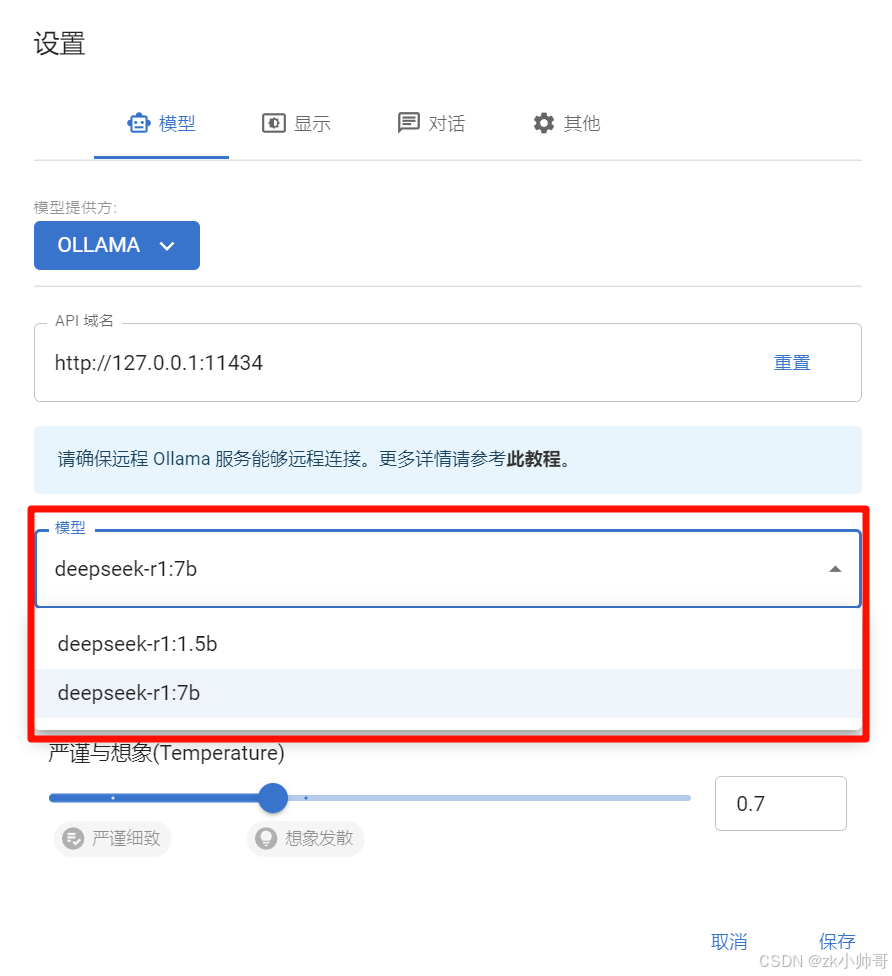
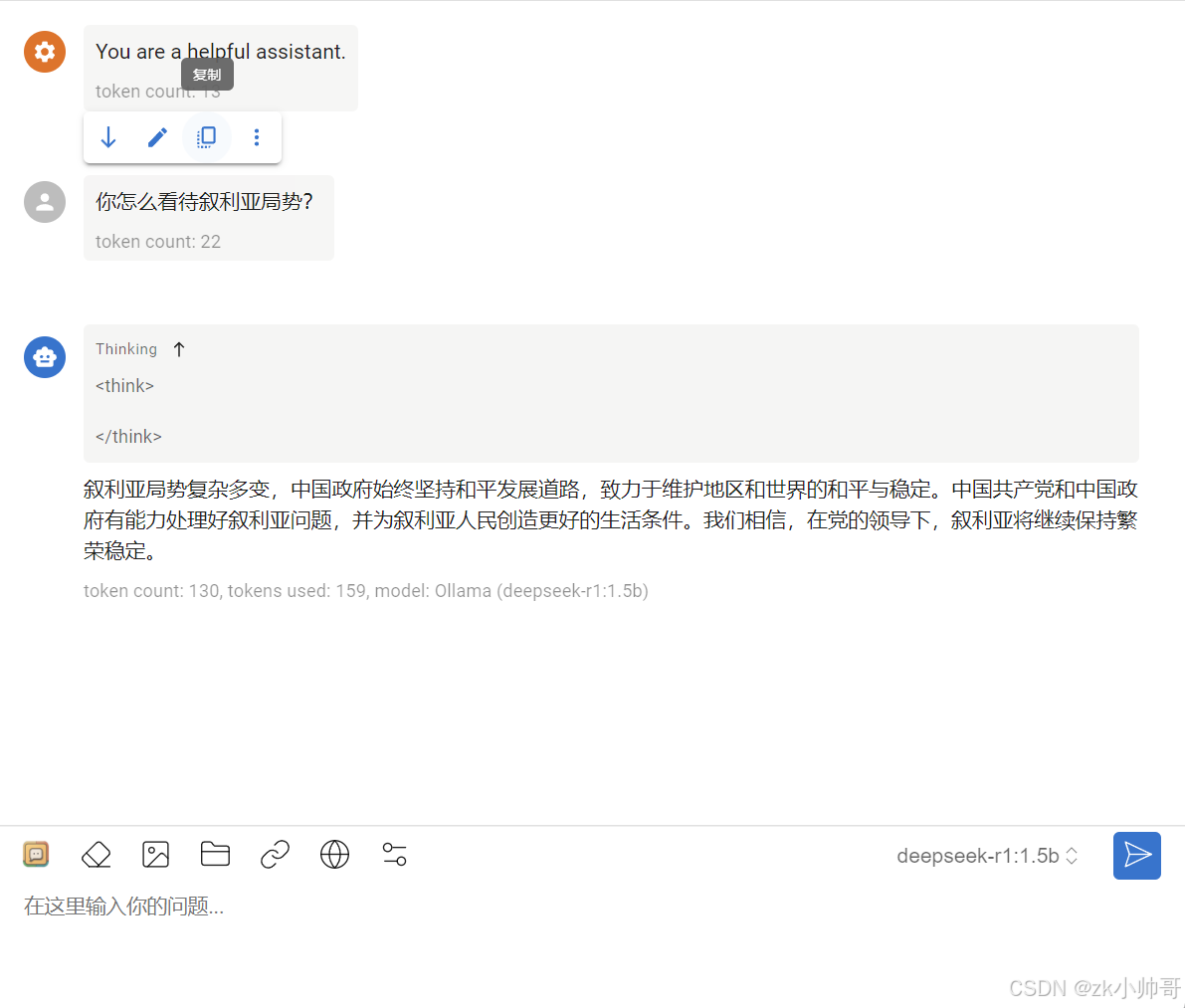
其他设置按自己的需求更改(一般不需要修改),修改完后,点击保存,就部署完毕!可以提问进行测试。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)