
LLaMA-Factory微调qwen(-vl)遇到的问题和解决方法实录
1. 按照官方教程,最好先创建虚拟环境再安装依赖,使用python3.10。
2. 单纯按照官方教程在运行时会报"Processor was not found, please check and update your model file."的错误,原因是没有安装transformers。qwen在huggingface中指定的transformers版本可能不对,比如qwen3-vl指定的transformers=4.57.0,如果你安装的python版本是3.10,这个版本的transformers就会被LLaMA-Factory禁用。解决方法是安装稍微高一点的兼容版本,如transformers=4.57.1,python版本维持3.10不要改。

3. 数据集格式,这里展示qwen-vl常用的一种带图片的数据格式。在LLaMA-Factory/data/下,创建自己的数据json文件,内容示例如下,第一条数据是格式内容说明,第二条数据是一个具体的例子。其中图片可以放在任何位置,只要路径正确就行。

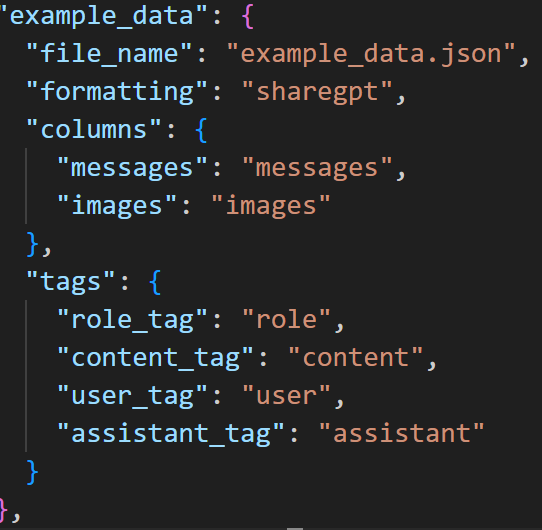
假设以上数据文件命名为example_data.json,则创建完成后,需要在同一文件夹即LLaMA-Factory/data/下找到dataset_info.json,这是总体的数据集说明文件,需要在其中添加自己的数据集说明,以以上的example_data.json为例,需要写入dataset_info.json的内容如下。完成上述步骤中,LLaMA-Factory才能检测到并使用你的数据集。
4. 推荐使用UI模式,在终端通过"llamafactory-cli webui"打开,有些服务器配置了转发端口,可以直接将这个UI界面显示到本地且能正常地使用,可以先尝试一下,实在不行再使用纯终端。
5. 模型权重最好自己从modelscope下载到服务器,并指定模型路径到权重文件,因为LLaMA-Factory有极大概率无法在线加载权重且速度非常慢。
6. 如果使用服务器,特别是使用UI界面来训练,记得在启动UI前先在终端运行"export CUDA_VISIBLE_DEVICES=?,?",问号处填可用gpu的序号,否则LLaMA-Factory不会自动使用GPU来跑;如果你选择在终端执行训练命令而不是在UI界面,则可以在训练命令前添加"CUDA_VISIBLE_DEVICES=?,?"。
7. 在正式开始训练之前,建议先用"Chat"模式测试模型是否能加载成功、模型是否有使用GPU(从推理速度、显卡内存检测可以判断)
8. 对训练命令中的部分参数进行说明如下,测试命令也比较相似。
CUDA_VISIBLE_DEVICES=?,? llamafactory-cli train \
--...
--model_name_or_path 模型权重路径 \
--...
--dataset_dir data \
--dataset 你的数据集名字如example_data \
--...
--save_steps 保存步数的间隔 \
--...
--output_dir 输出结果的保存路径,包括日志和损失曲线图 \
--...
汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)