
【llama.cpp】llama.cpp部署大模型
·
官方网站
https://github.com/ggml-org/llama.cpp
使用windows的编译exe
下载编译的文件
https://github.com/ggml-org/llama.cpp/releases
有GPU下载带cuda的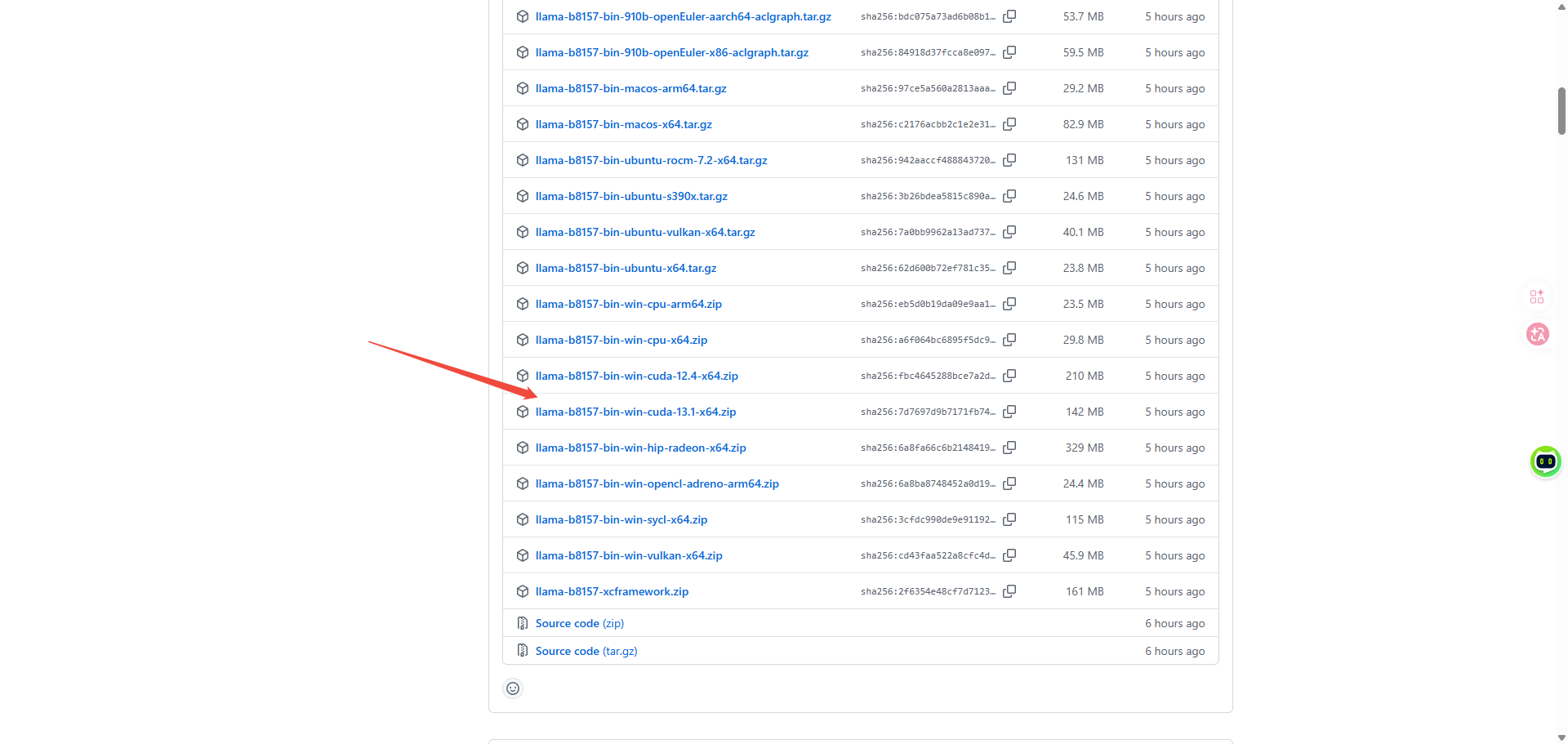
使用命令行工具llama-cli
解压文件后启动终端
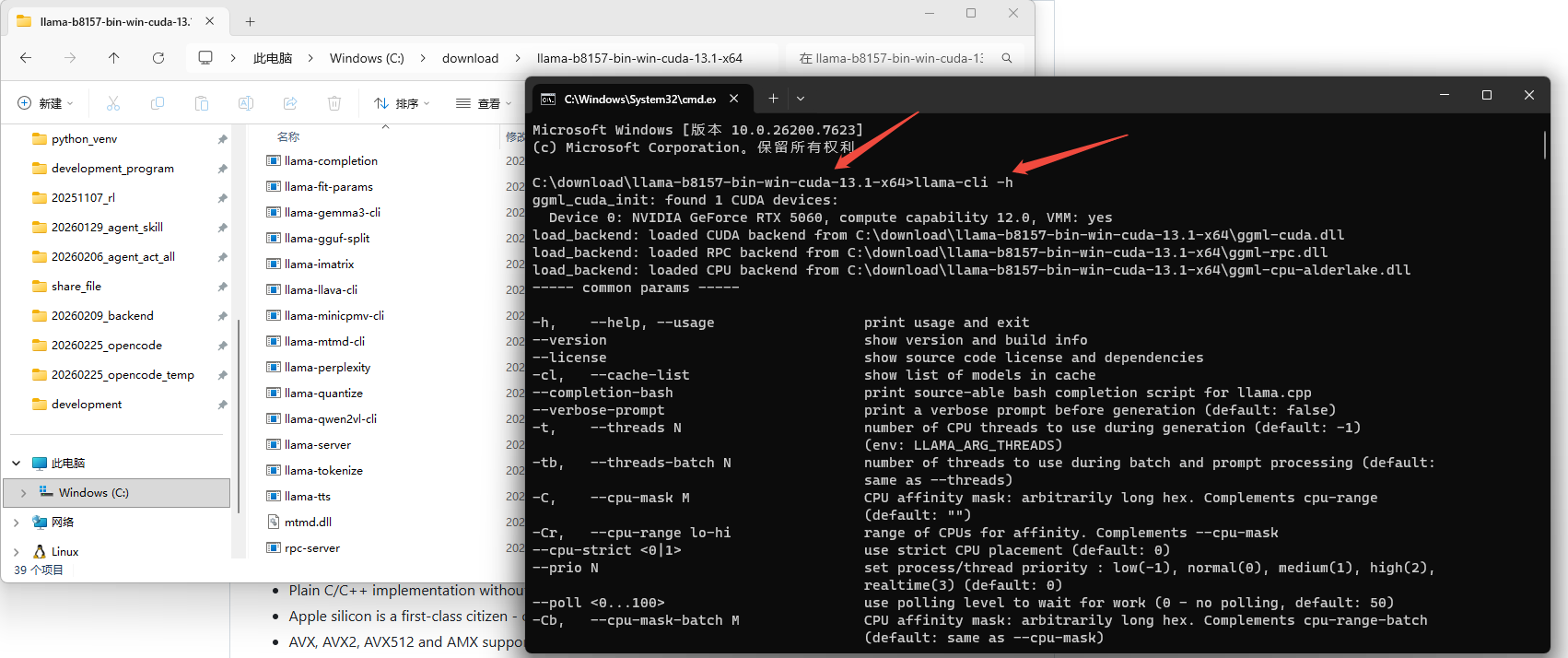
输入以下查看可用的命令
llama-cli -h
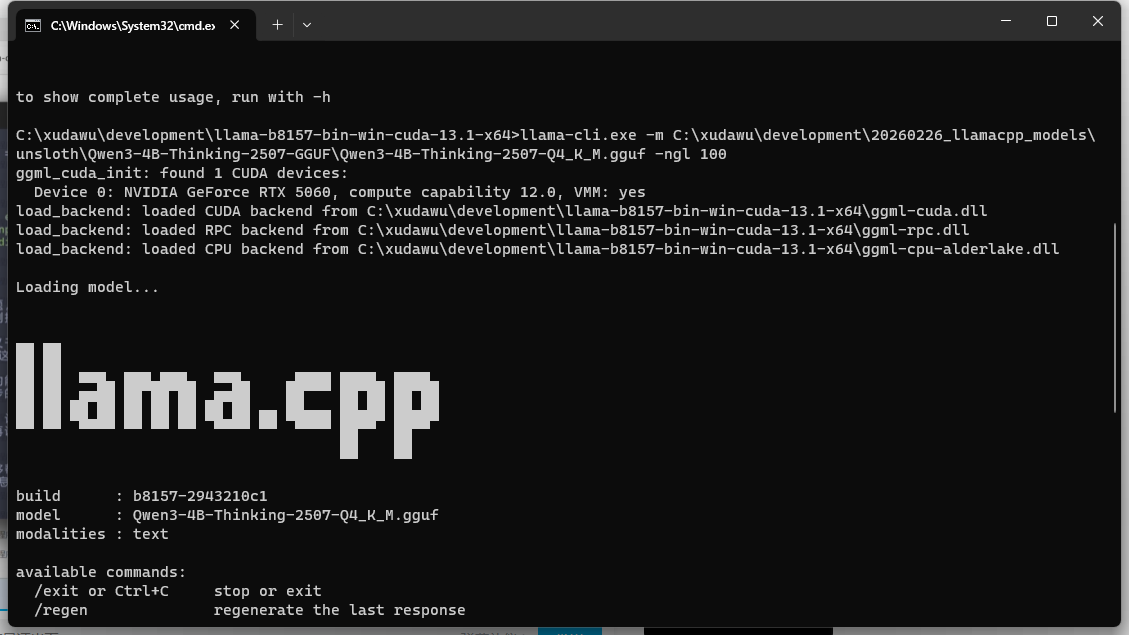
启动模型
llama-cli.exe -m C:\xudawu\development\20260226_llamacpp_models\unsloth\Qwen3-4B-Thinking-2507-GGUF\Qwen3-4B-Thinking-2507-Q4_K_M.gguf -ngl 100
-m指定模型位置,如果模型很大有多个gguf切片,只需要给出一个剩下的会自动索引-ngl指定模型加载到GPU的层数
直接测试对话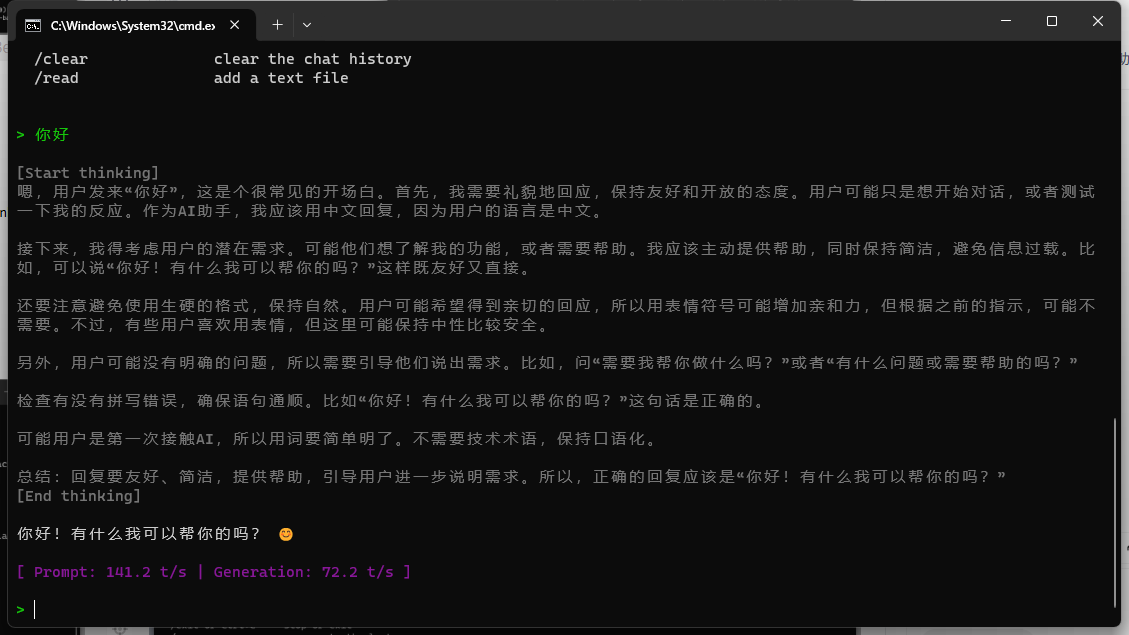
测试性能llama-bench
使用llama-bench.exe工具测试此电脑的性能
llama-bench.exe -m C:\xudawu\development\20260226_llamacpp_models\unsloth\Qwen3-4B-Thinking-2507-GGUF\Qwen3-4B-Thinking-2507-Q4_K_M.gguf -ngl 100
输入512token的速度,和输出128token的速度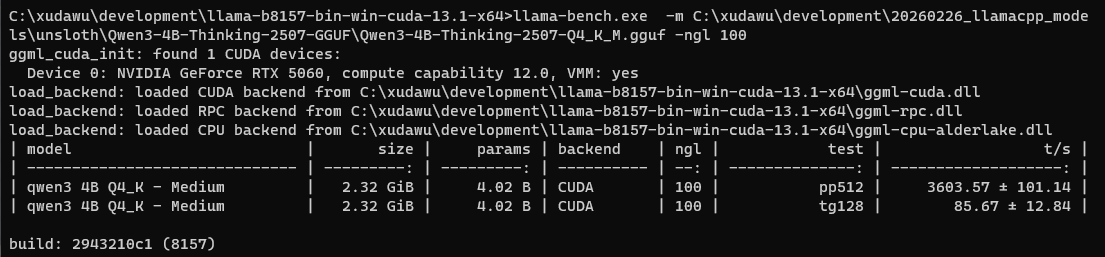
启动模型服务llama-server
llama-server.exe -m C:\xudawu\development\20260226_llamacpp_models\unsloth\Qwen3-4B-Thinking-2507-GGUF\Qwen3-4B-Thinking-2507-Q4_K_M.gguf --ctx-size 16384 --host 0.0.0.0 --port 8080
--ctx-size 上下文长度,不设置则默认为0,从模型配置中加载上下文长度--port 端口,默认为8080-a 指定模型服务启动的名字,不设置则默认使用-m指定的文件名
启动成功
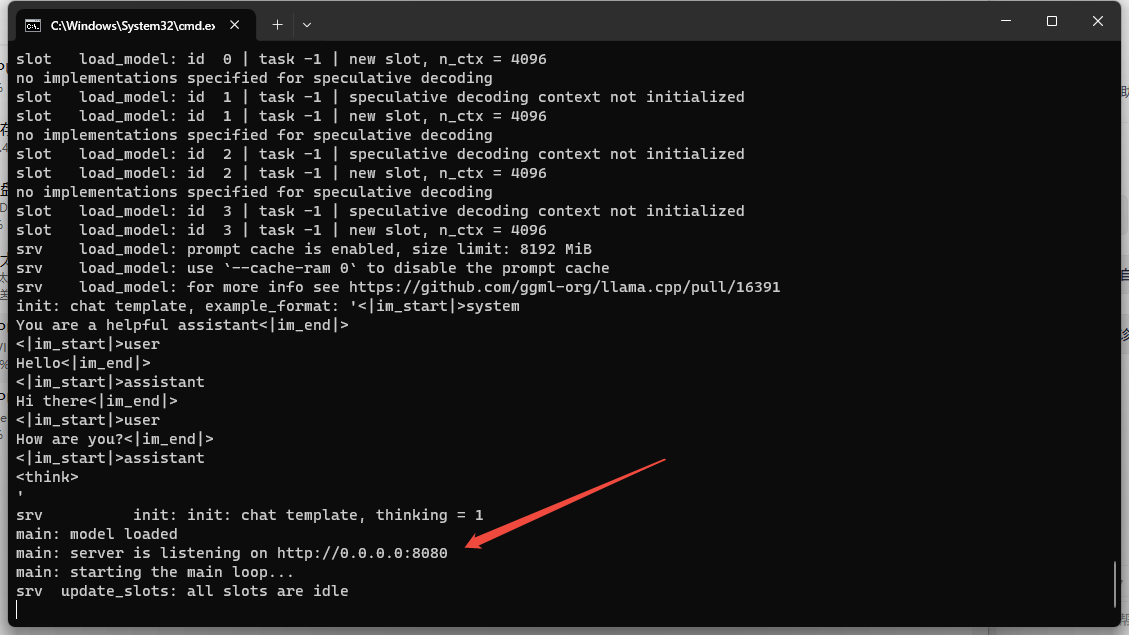
启动webui
进入指定的网址进入llama自带的web界面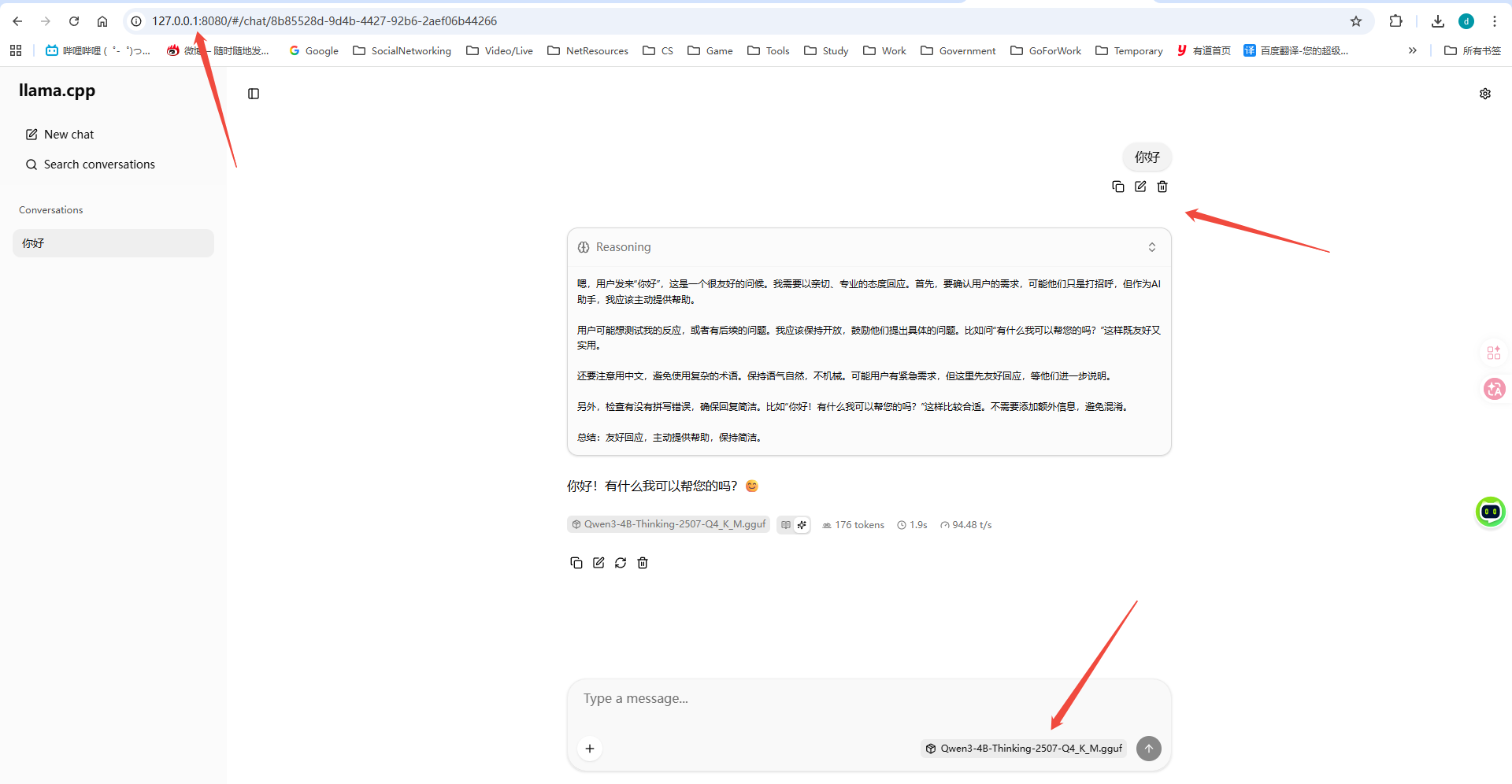
启动多模态模型服务
下载视觉投影模型mmproj-BF16.gguf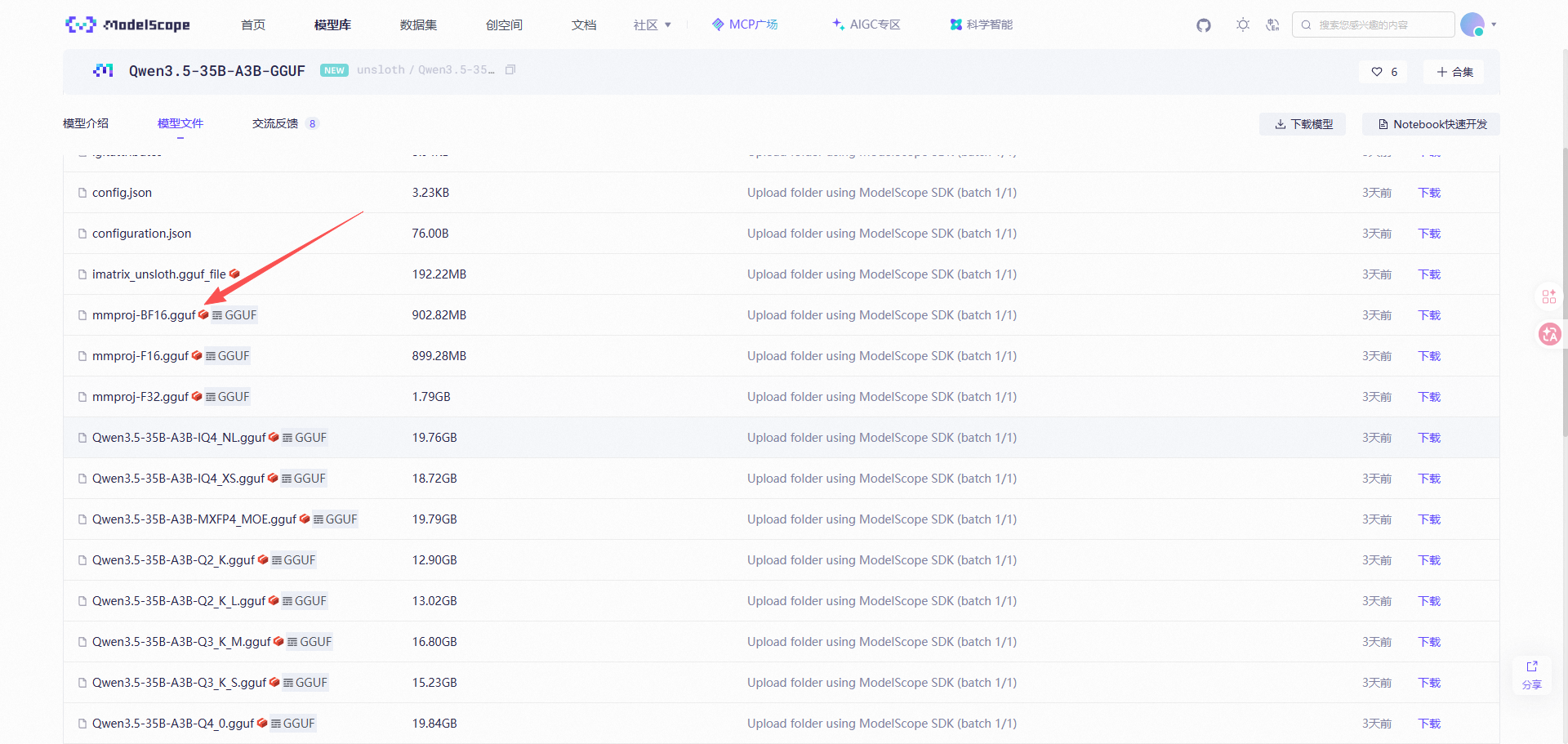
启动模型服务
llama-server.exe -m models/Qwen3.5-35B-A3B-GGUF/Qwen3.5-35B-A3B-Q4_K_M.gguf --mmproj models/Qwen3.5-35B-A3B-GGUF/mmproj-BF16.gguf --ctx-size 32768 --host 0.0.0.0 --port 8080
--mmproj models/Qwen3.5-35B-A3B-GGUF/mmproj-BF16.gguf指定multimodal projector的位置
获得所有模型
启动服务并指定模型文件夹地址
llama-server.exe --models-dir C:\xudawu\development\20260226_llamacpp_models\unsloth --sleep-idle-seconds 180
通过get请求可以获得可用模型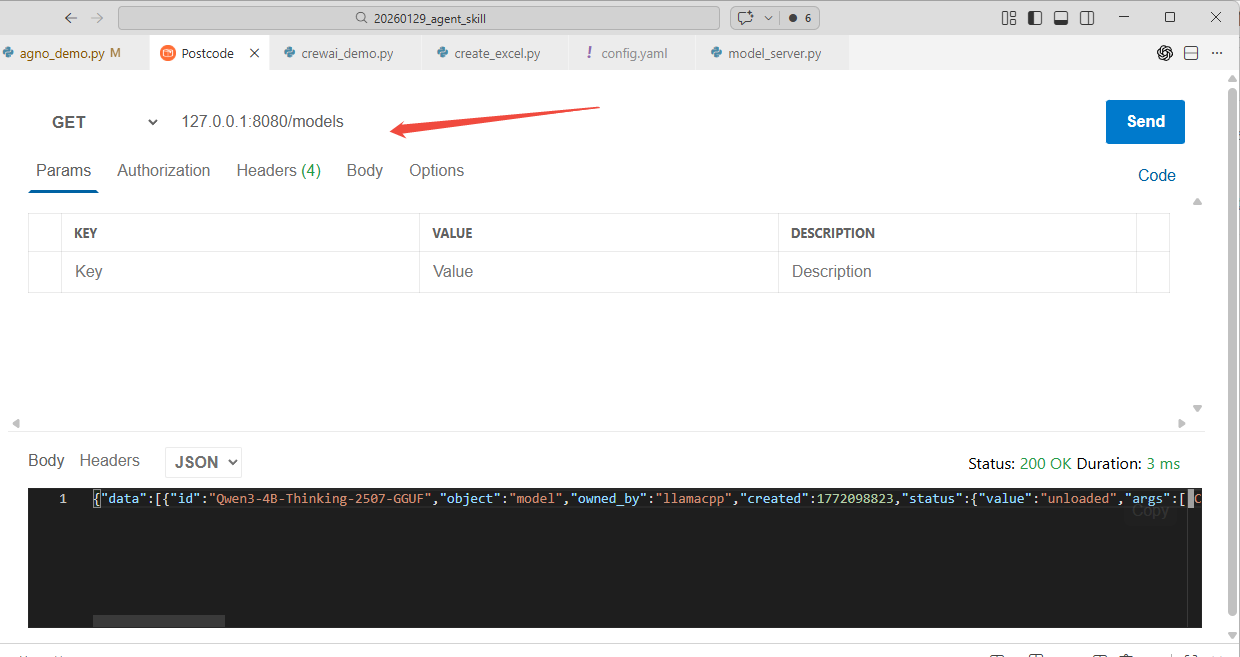
以下参数在服务器空闲多少秒时卸载模型
--sleep-idle-seconds
推荐创建一个bat文件方便一键启动
bat文件内容如下
文件名1a_start_llama_server.bat
llama-server.exe --models-dir ../../models --ctx-size 65536 --host 127.0.0.1 --port 8080
--ctx-size 65536设置模型上下文长度为65536token--models-dir ../../models使用当前目录的上两级目录中的models文件夹作为模型文件夹其余参数不设置由llama.cpp进行自适应调整
官方文档
https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
使用docker
官方教程
https://github.com/ggml-org/llama.cpp/blob/master/docs/docker.md
选择这个镜像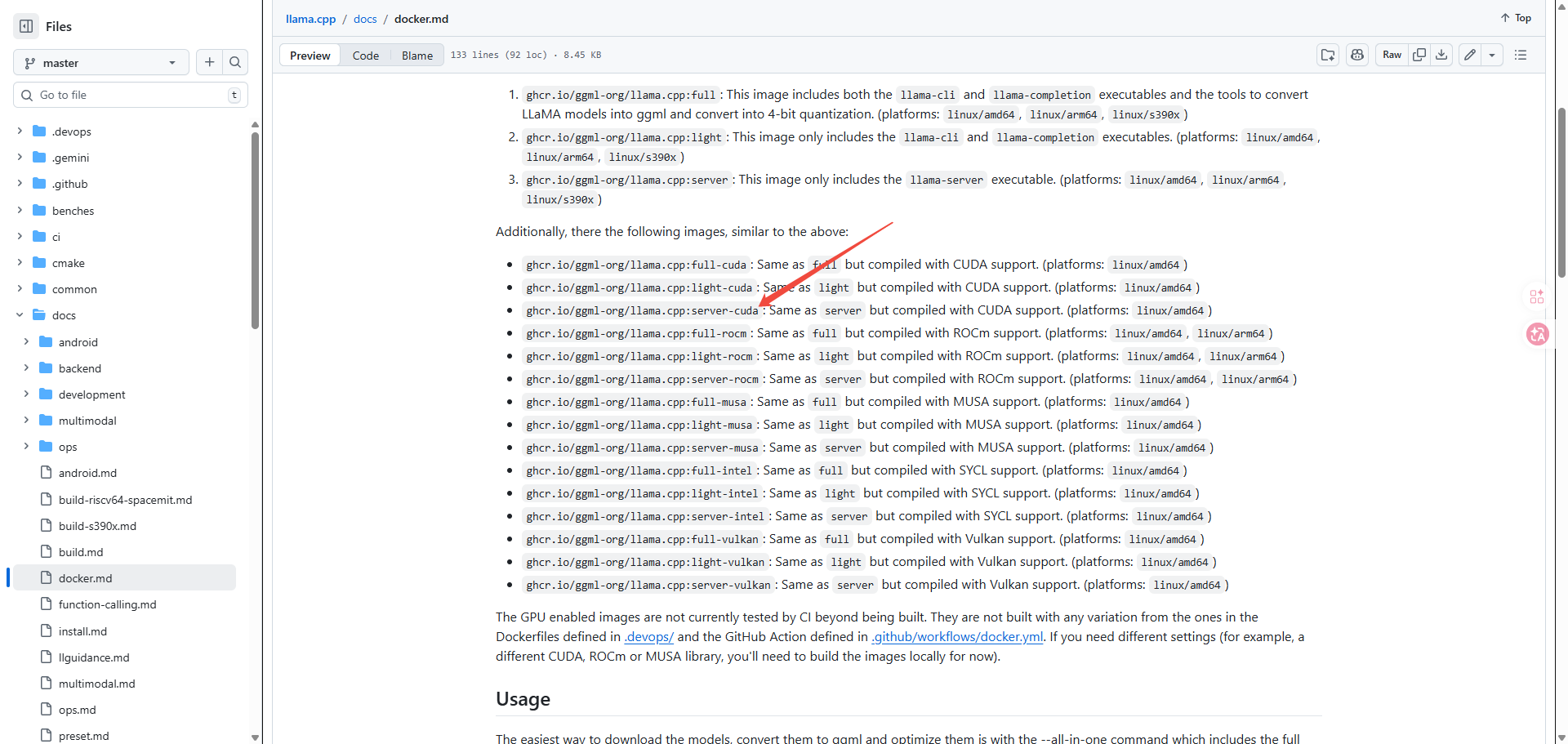
启动容器服务
启动单个模型
docker run --name llama-server --gpus all -p 8080:8080 -v C:/xudawu/development/docker_data/llama_cpp/models:/models ghcr.io/ggml-org/llama.cpp:server-cuda -m /models/Qwen3.5-35B-A3B-Q4_K_M.gguf --ctx-size 32768 --host 0.0.0.0 --port 8080
推荐使用--ctx-size 32768设置固定上下文长度
而使用-fitc 32768设置最小上下文长度,启动模型时会自动检测可用显存然后拓展上下文长度,会增加显存占用和减慢模型首次启动速度
启动服务,模型按需加载
docker run --name llama-server --gpus all -p 8080:8080 -v C:/xudawu/development/docker_data/llama_cpp/models:/models" ghcr.io/ggml-org/llama.cpp:server-cuda --models-dir /models --sleep-idle-seconds 1800 --ctx-size 32768 --host 0.0.0.0 --port 8080
如果使用的是full-cuda的镜像
启动单个模型
docker run --name llama-server --gpus all -p 8080:8080 -v C:/xudawu/development/docker_data/llama_cpp/models:/models ghcr.io/ggml-org/llama.cpp:full-cuda --server -m /models/Qwen3.5-35B-A3B-Q4_K_M.gguf --ctx-size 32768 --host 0.0.0.0 --port 8080
启动服务,模型按需加载
docker run --name llama-server --gpus all -p 8080:8080 -v C:/xudawu/development/docker_data/llama_cpp/models:/models ghcr.io/ggml-org/llama.cpp:full-cuda --server --models-dir /models --sleep-idle-seconds 1800 --ctx-size 32768 --host 0.0.0.0 --port 8080
加载模型
POST /models/load
卸载模型
POST /models/unload
模型保存在内存中
不交换到磁盘
--mlock

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)