
Spring AI + Ollama + DeepSeek 环境搭建与模型调用
步骤1:Ollama安装与配置
Ollama是一个用于本地运行大型语言模型的工具,支持多种模型。以下是安装与配置的详细步骤:
1. 下载Ollama
访问Ollama官方网站:https://ollama.com/,点击Download下载,如下图所示。
2. 安装Ollama
下载完成后,得到“OllamaSetup.exe”文件,运行该文件,点击“Install”开始安装,按照提示完成安装过程。
3. 验证安装
安装完成之后,打开一个新的命令提示符窗口,输入“ollama”命令,如果显示ollama相关的信息就证明安装已经成功了!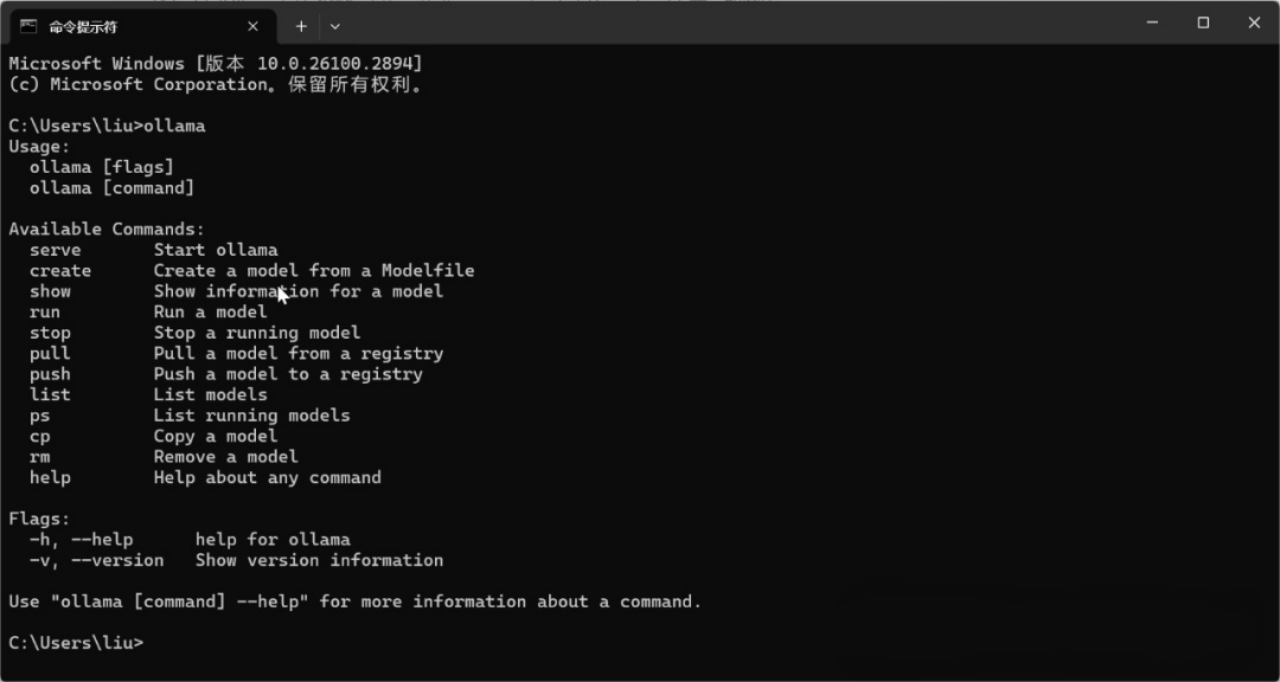
4. 配置模型存储路径
默认情况下,ollama模型的存储目录位于C:\Users<username>.ollama\models,在Windows系统中,若要更改Ollama模型的存放位置,需要在环境变量窗口中,点击“新建”创建一个新的系统变量或用户变量:
-
变量名:
OLLAMA_MODELS -
变量值:输入你希望设置的新模型存放路径,例如:
D:\Ollama\Models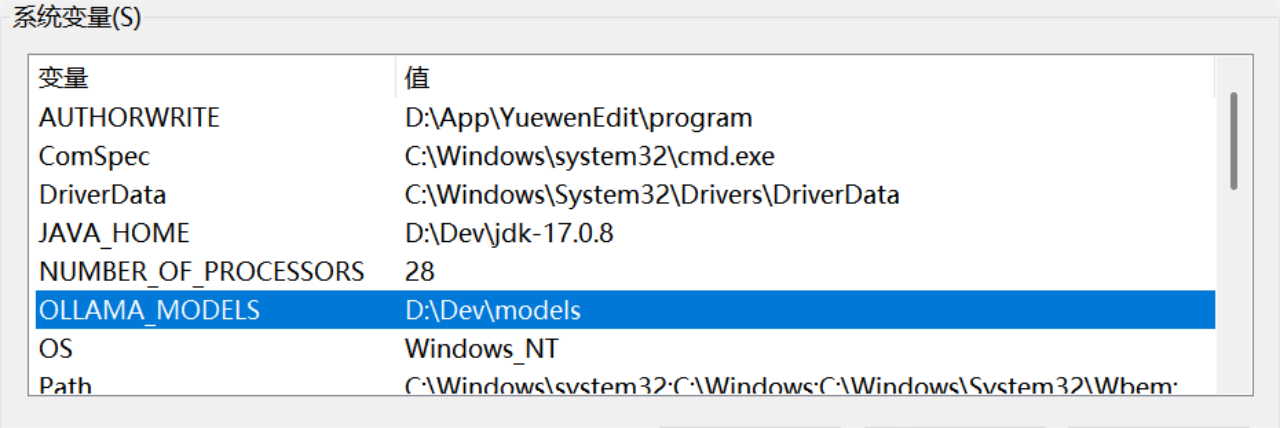
最后,重启已经打开的Ollama相关应用程序,以便新的路径生效。
步骤2:DeepSeek模型下载与运行
1. 搜索模型
访问Ollama官方网站:https://ollama.com/,在主页的搜索框中输入“deepseek”,点击搜索结果中的deepseek--r1模型。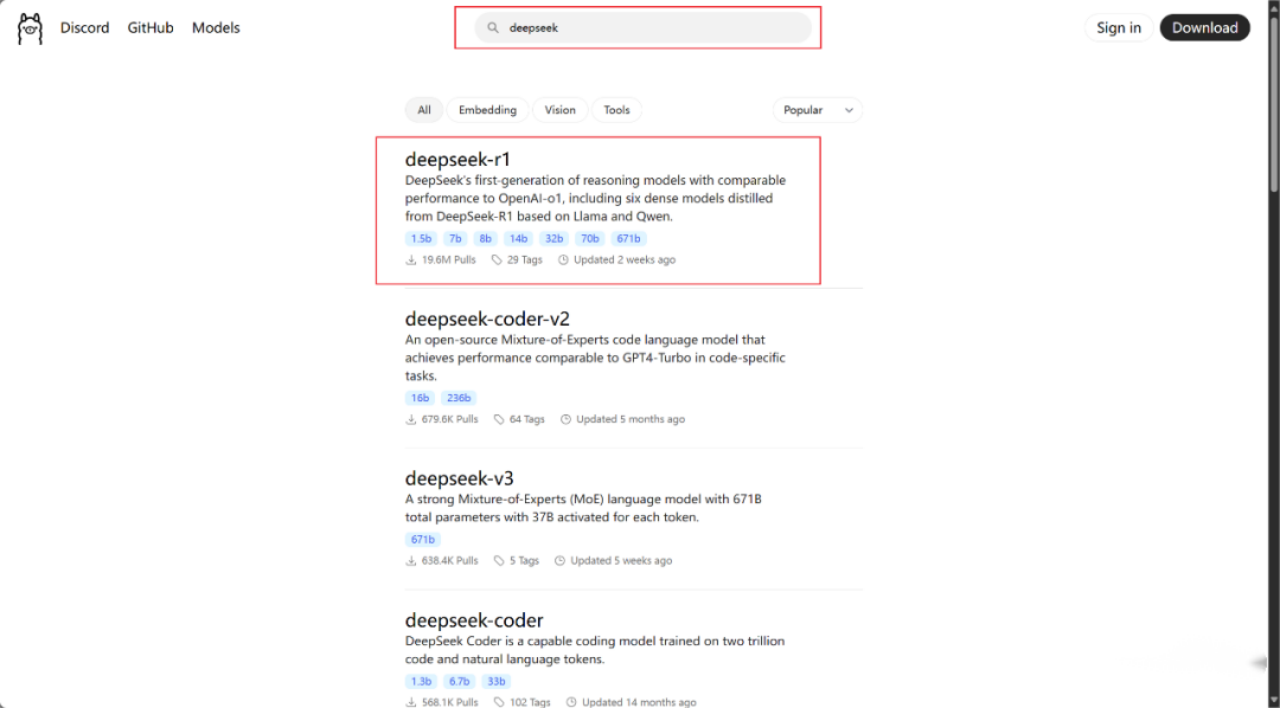
在模型详情页面,用户可以找到运行DeepSeek-R1模型的具体命令。页面列出了DeepSeek团队开发的原始基础模型,该模型拥有6710亿(B代表十亿)参数。此外,还展示了多个经过蒸馏处理的模型,它们的参数量从1.5B到32B不等。
这些蒸馏模型通过将大型模型的高级推理能力迁移到更小的模型中,不仅提升了性能,而且在基准测试中展现出卓越的表现。这种技术的应用使得小型模型在保持高效的同时,也能够拥有接近大型模型的推理能力。
用户可以根据自己的硬件配置和需求选择适合的DeepSeek-R1模型进行下载和部署。以下是不同参数量模型的本地部署硬件要求和适用场景分析:
| 模型版本 | 显存需求(量化后) | 推荐硬件 | 典型场景 |
|---|---|---|---|
| 1.5B | 4-6GB | RTX 3060/T4 | 移动端实时交互、嵌入式设备 |
| 7B | 6-8GB | RTX 3090(单卡) | 中小型企业对话系统 |
| 14B | 12GB | A10/A100(单卡) | 本地知识库、政务服务智能客服12 |
| 32B | 19-24GB | RTX 4090/A100 | 金融分析、代码生成 |
| 671B | 640GB+ | 8*A100-80GB集群 | 超大规模科研计算、多模态推理等,需企业级硬件支持 |
2. 模型下载
选择好合适的模型后,打开新的命令行窗口,输入相应命令并运行,此处选择1.5B模型,命令如下:
ollama run deepseek-r1:1.5b如果本地没有对应模型,Ollama 会先下载该模型,下载完成后,模型会启动并进入交互模式,你可以直接与模型对话,如下图所示: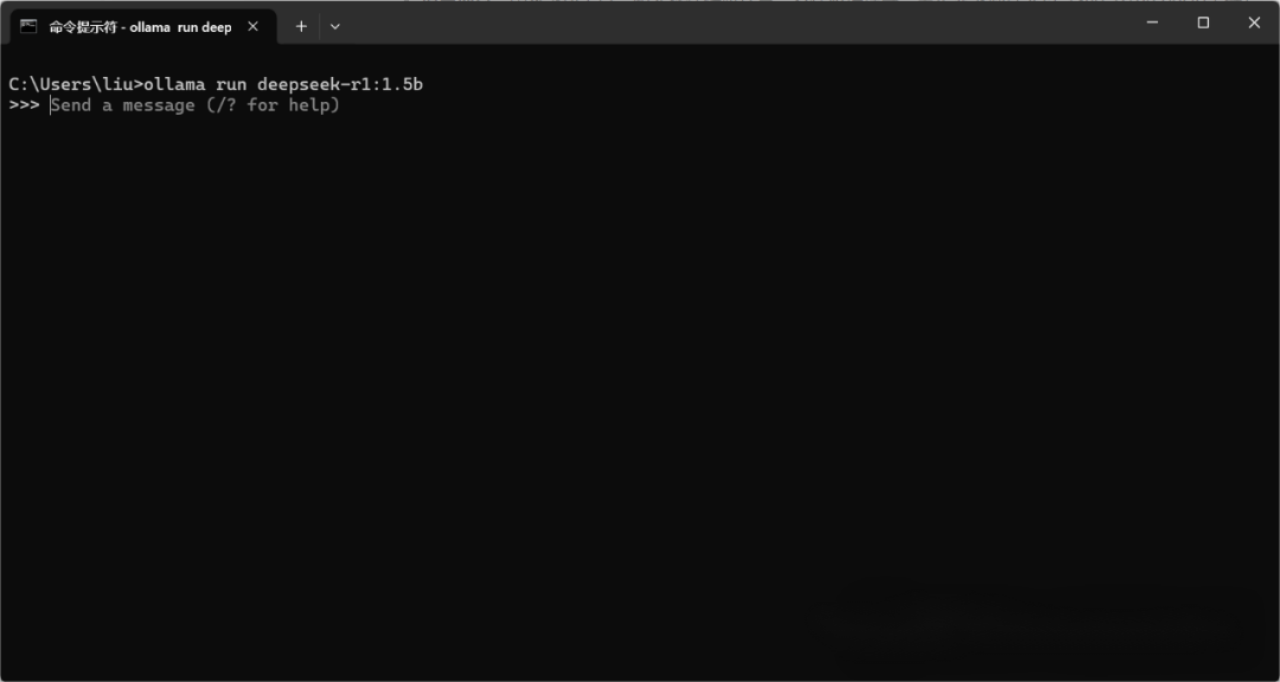
如果你希望提前下载模型而不运行,可以使用 ollama pull 命令:
ollama pull deepseek-r1:1.5b步骤3:创建 Spring Boot 项目
Spring Initializr是一个在线工具,用于快速生成一个新的 Spring Boot 项目。它提供了一个直观的 web 界面,使用户能够选择所需的依赖项、项目元数据以及其他配置选项,然后生成一个压缩的项目包,可以直接下载并使用。
首先访问Spring Initializr官方地址:https://start.spring.io/,在打开的页面中对项目进行基本的设置。
-
配置项目信息
-
指定项目类型、编程语言及构建工具,分别对应页面中的Project、Language、Spring Boot选项,构建工具包括Maven 、 Gradle,编程语言可以选择Java、Kotlin 或 Groovy,此处选择Java语言,Maven工具,Spring Boot 版本采用3.4.3。
-
指定项目的元信息,对应页面中的 Project Metadata,此选项用于定义和描述项目的元数据。它们的主要目的是帮助唯一地标识一个项目,并提供有关项目的基本信息,包括 Group、Artifact、Name、Description 和 Package name等,此处使用默认设置,读者可根据自己的情况进行修改。
-
-
指定项目的打包方式,对应页面中的Packaging选项,有JAR和WAR两种选择,此处选择Jar。
-
指定Java版本,此处使用17。
-
添加Ollama依赖:单击右侧的“ADD DEPENDENCIES”选项,可以在项目中添加额外的依赖。搜索
Ollama添加依赖,这是Spring AI对Ollama的实现支持,如下图所示。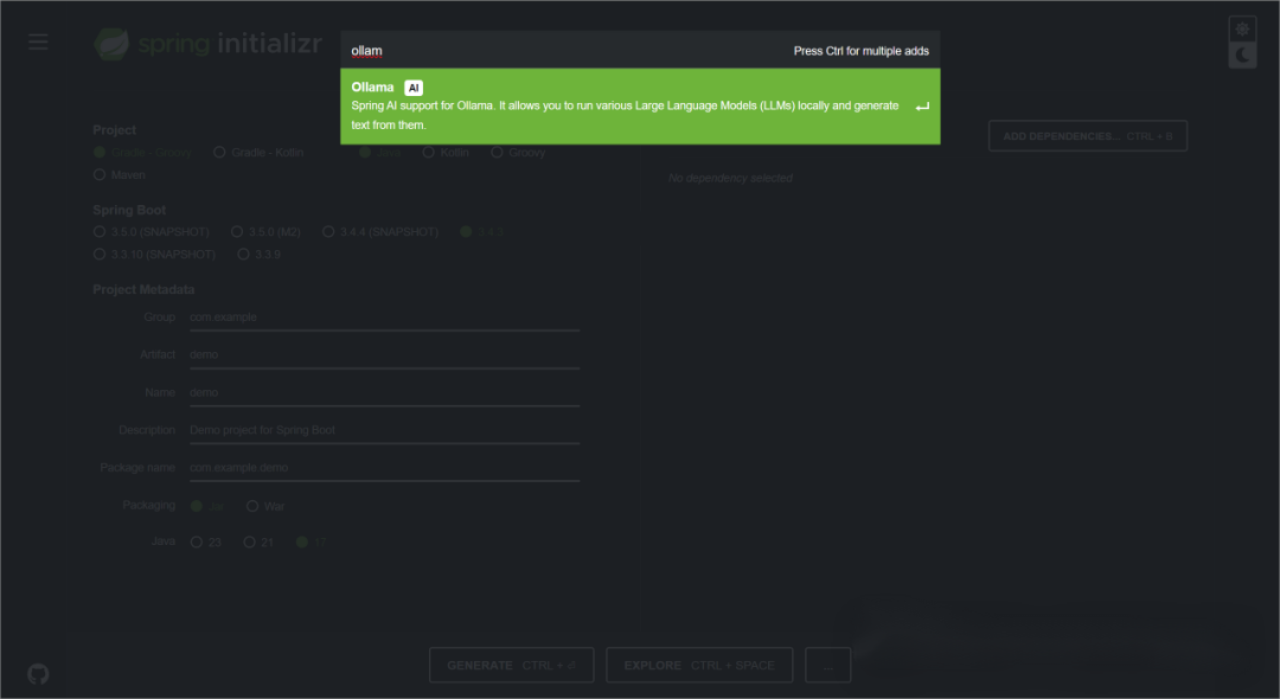
单击Generate按钮,它将生成一个包含你选择的所有依赖和配置的 ZIP 文件。下载并解压 ZIP 文件。然后,可以使用IDEA打开和运行它,上述所有配置信息如下图所示。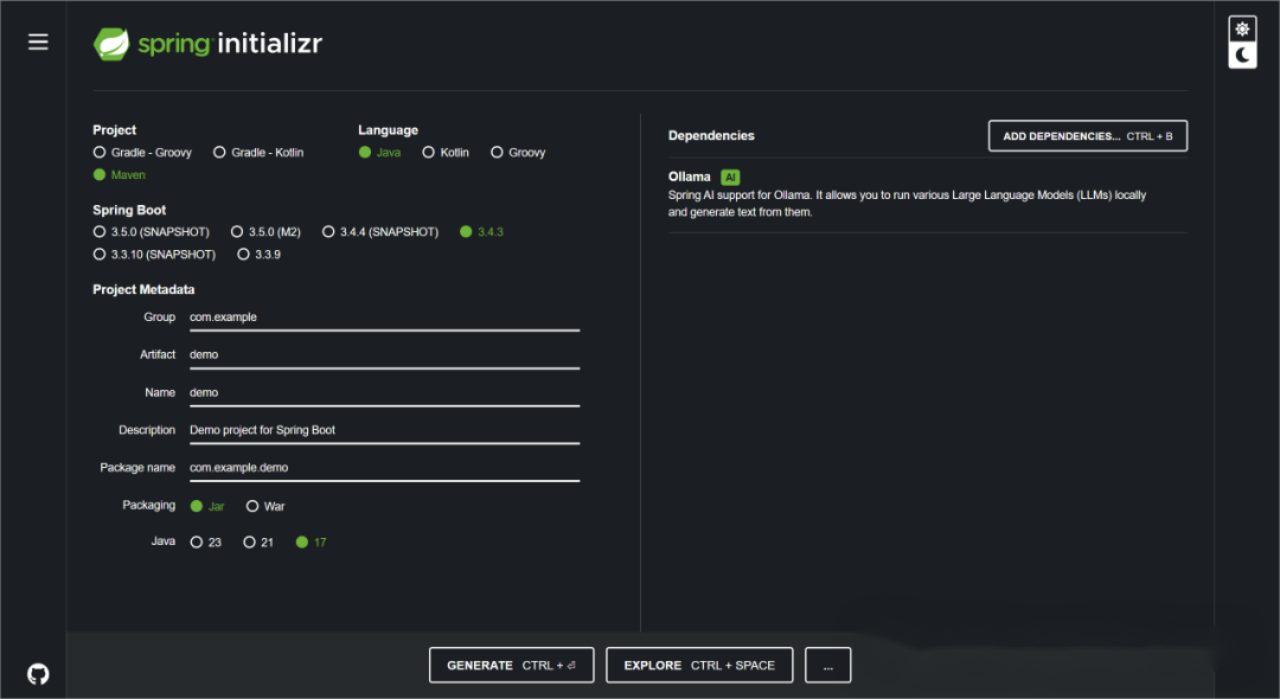
步骤3:调用模型
1. 配置Ollama信息
将上个步骤中下载的demo.zip文件解压至任意目录,使用IDEA打开项目,在生成的项目目录中,查看pom.xml,可以看到核心依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama-spring-boot-starter</artifactId></dependency>
如果你要在现有项目中集成的话,就可以直接添加这个依赖即可。
打开项目配置文件application.properties,配置Ollama的相关信息,如下:
spring.ai.ollama.base-url=http://localhost:11434spring.ai.ollama.chat.model=deepseek-r1:1.5b
-
spring.ai.ollama.base-url: Ollama的API服务地址,如果部署在非本机,就需要做对应的修改 -
spring.ai.ollama.chat.model: 要调用的模型名称,对应上一节ollama run命令运行的模型名称
2. 编写代码调用模型
打开test目录的DemoApplicationTests文件,尝试调用Ollama中的deepseek-r1模型,这里尝试实现一个翻译的功能,代码如下:
package com.example.demo;import org.junit.jupiter.api.Test;import org.springframework.ai.ollama.OllamaChatModel;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;@SpringBootTestclass DemoApplicationTests {@Autowiredprivate OllamaChatModel ollamaChatModel;@Testvoid contextLoads() {}@Testpublic void testChatModel() {String prompt = """你是一位资深的双语专家,擅长在中文与英文之间精准转换。当我提供英文内容时,你负责将其准确、流畅地译为中文;反之,当我给出中文文本,你则高效地将其转化为地道的英文表达。""";String message = """Ollama now supports tool calling with popular models such as Llama 3.1.This enables a model to answer a given prompt using tool(s) it knows about,making it possible for models to perform more complex tasks or interact with the outside world.""";String result = ollamaChatModel.call(prompt + ":" + message);System.out.println(result);}}
这段代码的主要功能是测试 OllamaChatModel 的翻译能力。它通过 Spring Boot 的测试框架加载应用程序上下文,注入 OllamaChatModel 的实例,并调用其 call 方法,将一段英文文本翻译成中文。测试结果会打印到控制台。
运行单元测试,结果如下:
<think>好,我收到一个用户的请求,需要将一段英文翻译成中文。内容是关于Ollama模型支持工具调用的功能。首先,我得仔细阅读原文,确保理解每个术语的意思。“Ollama now supports tool calling with popular models such as Llama 3.1.” 这里,“Ollama”指的是一个AI模型或工具。“supports tool calling”翻译成“支持工具调用”,意思是支持使用工具来操作或执行任务。“with popular models”意味着使用的是流行的模型,这里的“popular models”可能是指常见的模型系列。接下来的句子:“This enables a model to answer a given prompt using tool(s) it knows about, making it possible for models to perform more complex tasks or interact with the outside world.” 这里有几个关键点。“answer a given prompt”可以翻译为“回答给定的提示”,表示使用模型来回答问题。“knows about”是“知道”或“了解”的意思,具体在上下文中应该是“它知道”。“tool(s) it knows about”是“在它所知方面的一些工具”。接下来的部分“making it possible for models to perform more complex tasks or interact with the outside world.” 翻译为“让模型能够执行更复杂的任务或与外部世界进行交互”,这解释了支持工具调用后,模型可以执行更多复杂任务或与其他世界交互。整个翻译要保持原文的逻辑和专业性,确保技术术语准确。同时,注意句子的流畅性和自然ness,避免直译带来的生硬感。比如,“support tool calling”可以用“支持工具调用”,而“popular models”则用“流行的模型”来传达意思。最后,检查一下整个翻译是否涵盖了所有信息,并且没有遗漏任何关键点,确保准确传达出Ollama的功能和优势。</think>Ollama 现在支持流行模型如 Llama 3.1 这样工具调用的功能。通过使用这些工具,模型能够回答给定的提示,并进行更复杂的任务或与外部世界进行交互。
可以看到结果响应分成两部分,先是<think>标签包含的内容,这是模型根据提供的提示,生成了一个思考的过程,最后才输出了翻译后的结果。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)