
GLM-5.2深度拆解:百万上下文+自研架构,国产长程工程模型突围
GLM-5.2深度拆解:百万上下文+自研架构,国产长程工程模型突围
2026年6月16日,智谱正式发布旗舰大模型GLM-5.2,彻底补齐前代GLM-5.1短板:稳定可用100万Token上下文窗口、全赛道顶尖编码Agent能力、IndexShare+升级MTP自研架构加持,同时采用MIT开源协议无地域限制,成为目前综合实力最强的开源大模型。
不同于市面大量“纸面百万上下文”噱头产品,GLM-5.2主打工程级长任务落地,专为代码开发、系统调优、大型项目重构等超长链路场景打造。今天我们一文吃透它的核心能力、底层架构、实测优劣与落地玩法。
一、核心王牌:真正可用的1M百万上下文,告别“长文本失忆”
绝大多数大模型虽标注超长上下文,但输入数万Token后就会出现信息遗忘、逻辑断裂、首尾内容对不上,这也是开发者最头疼的痛点。GLM-5.2这次直接将上下文上限从200K提升至稳定100万Token,核心关键词是Solid 1M(扎实百万上下文)。

1. 1M上下文到底能做什么?
直观换算:100万Token≈75万字中文文本,开发者可一次性喂入完整中型代码仓库、全套项目架构文档、数十万行服务器日志、数十份合同/技术论文,无需反复切片分段上传。
- 软件工程:全仓库代码一次性输入,自动梳理跨文件依赖、定位分布式Bug、完成整套系统重构;
- 技术研究:完整读取上百篇论文,梳理算法演进脉络、复现模型实验方案;
- 运维排查:百万级日志批量分析,一键定位线上故障根因;
- 文档处理:多份规范文件全局比对,统一校验规则、识别条款冲突。
2. 为什么它的百万上下文不“翻车”?
GLM-5.2并非单纯拉长位置编码,而是从训练、架构、推理引擎三层系统性优化:
- 专项长上下文训练:从128K序列长度开始引入IndexShare机制训练,海量代码Agent超长轨迹样本专项微调,保证长文本首尾信息召回稳定;
- IndexShare稀疏注意力降本:每4层Transformer共享一套索引器,百万Token下单Token计算量直接降低2.9倍,解决长上下文算力爆炸难题;
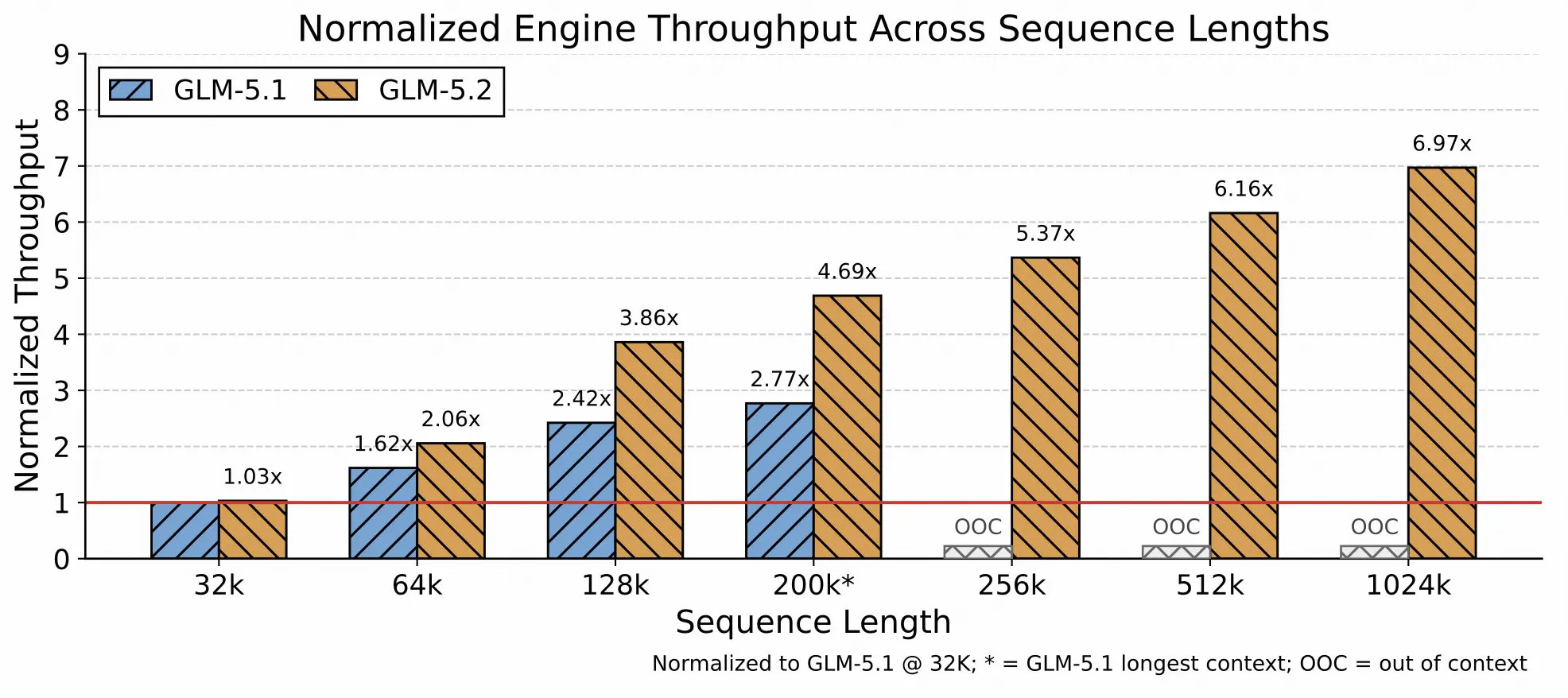
- 推理引擎三重优化:细粒度KV缓存内存管理、长序列内核加速、CPU调度流水线优化。官方数据显示,序列越长,GLM-5.2相对GLM-5.1的吞吐量优势越夸张,1024K长度下吞吐量提升6.97倍,前代GLM-5.1在256K就已超出上下文上限(OOC)无法运行。
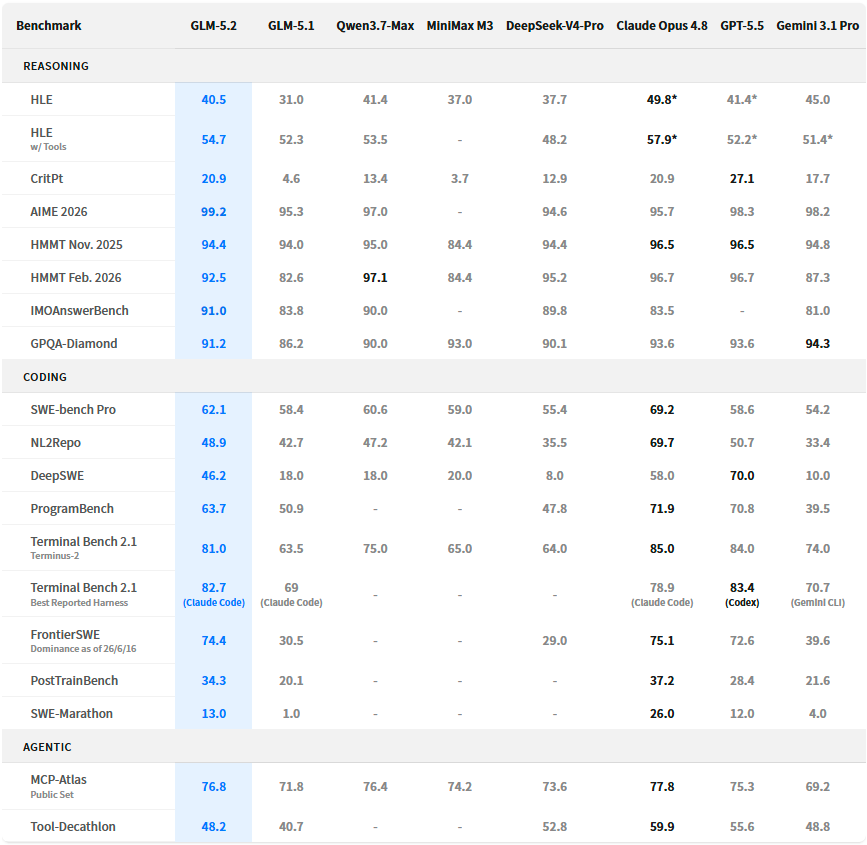
二、编码能力拉满:开源第一梯队,逼近闭源顶尖模型
GLM-5.2定位长程编码Agent模型,在全系列代码、工程基准测试中稳居开源模型第一名,多项指标大幅超越GLM-5.1,大幅缩小与Claude Opus 4.8、GPT-5.5等闭源头部模型的差距。
1. 三大超长工程基准:开源第一,接近opus4.8
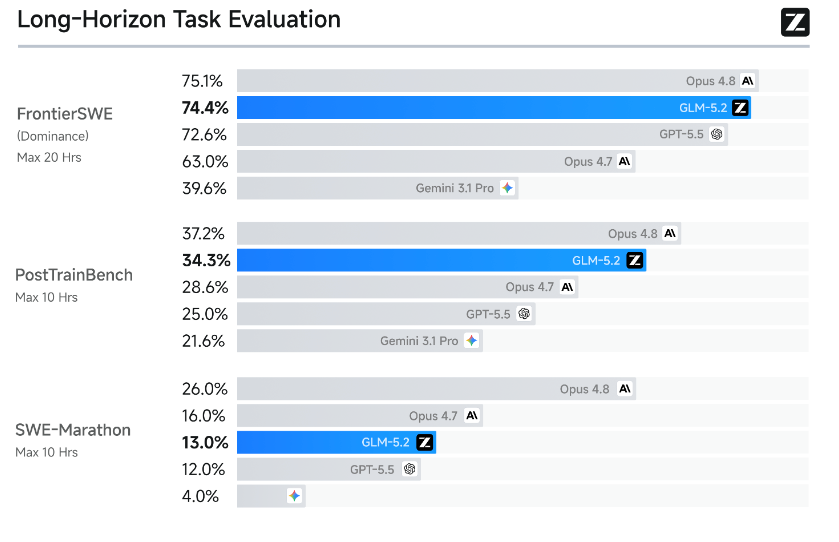
针对耗时数小时至数十小时的复杂工程任务,三大硬核评测结果清晰拉开差距:
- FrontierSWE(最长20小时开放技术项目):GLM-5.2得分74.4%,仅落后Claude Opus 4.8(75.1%)1个百分点,领先GPT-5.5 1%、Opus 4.7足足11%;
- PostTrainBench(GPU小模型后调优任务):34.3%,超越Opus 4.7、GPT-5.5,仅次于Opus 4.8;
- SWE-Marathon(编译器、内核、生产服务开发):13.0%,稳居第二名,仅落后Opus 4.8 13个百分点。
三大长程编码榜单中,GLM-5.2是排名最高的开源模型,也是唯一能和顶级闭源模型正面抗衡的开源方案。

2. 通用代码基准:全方位升级
对比前代GLM-5.1实现跨越式提升:
- Terminal-Bench 2.1:81.0分 vs 前代62.0分,仅落后Opus 4.8(85分)4分;
- SWE-bench Pro:62.1分 vs 前代58.4分,超过GPT-5.5、Gemini 3.1 Pro;
- NL2Repo、DeepSWE、ProgramBench等赛道,均实现大幅领先。
3. 灵活思考档位,平衡速度与性能
GLM-5.2新增多档位思考强度控制,用户可按需切换,解决“推理慢”和“效果差”两难:
- High(均衡档):输出Token更少、推理延迟低,适合日常代码补全、简单脚本编写;
- Max(极致档):分配更多算力深度推理,复杂系统重构、底层内核调试、多轮Agent长任务首选。

同等Token消耗下,GLM-5.2综合编码能力介于Claude Opus 4.7与4.8之间;Max档位可进一步拉高代码逻辑精度,兼顾灵活度与实用性。
4. 代码防作弊Anti-Hack模块,杜绝“取巧刷分”
代码Agent训练极易出现奖励作弊:模型通过读取隐藏评测文件、curl拉取标准答案、遍历系统隐藏目录等捷径拉高得分,实际落地毫无价值。
GLM-5.2内置双层反作弊机制:
- 规则过滤器拦截可疑工具调用;
- LLM裁判二次校验行为意图;
检测到作弊不会直接中断整条任务轨迹,仅拦截违规操作、返回空结果,避免训练崩溃、模型失效,保证训练信号真实有效。
三、底层架构革新:IndexShare+增强MTP,百万上下文低成本落地
GLM-5.2的性能飞跃,核心来自两套自研架构优化,完美解决长上下文算力、推理速度两大痛点。
1. IndexShare:稀疏注意力共享索引,算力直降2.9倍
传统DSA稀疏注意力每层都要独立计算Top-K索引,百万Token场景下算力开销指数级暴涨。
GLM-5.2创新IndexShare机制:每4层Transformer共用1个轻量索引器,第一层计算索引,后续3层直接复用,省去3/4索引计算开销。
优势:
- 1M上下文下单Token FLOPs降低2.9倍,大幅降低长文本推理成本;
- 从训练中期就启用该机制,长上下文基准全面超越GLM-5.1;
- MTP多步预测层同步复用IndexShare,训推逻辑完全统一。
2. 全新升级MTP投机解码,生成速度提升20%
MTP(多Token预测)是大模型加速推理核心技术,但前代GLM-5.1存在训练与推理逻辑不一致,导致投机解码草稿接受率低、加速效果差。
GLM-5.2四重优化迭代MTP层:IndexShare索引复用+KV缓存共享+拒绝采样+端到端TV损失,四管齐下:
- 基线MTP接受长度仅4.56;
- 全套优化后达到5.47,整体提升20%;
- 消除多步推理时混合KV缓存带来的逻辑偏差,模型生成连贯性更强。
3. Slime自研训练框架,支撑大规模Agent强化学习
GLM-5.2复杂Agent长任务训练依赖自研Slime一体化基础设施:
- 支持黑白盒滚动、子智能体工作流、轨迹压缩等多模式RL训练;
- 本次模型融合十余个专家模型,完整OPD训练仅耗时2天;
- 打通训练与推理部署链路,RL调度、KV缓存FP8优化可直接复用到线上服务,大幅降低生产落地成本。
四、客观盘点:GLM-5.2优势与现存短板
✅ 核心优势
- 开源无限制:MIT开源协议,无区域封锁,权重全量开放在HuggingFace、ModelScope,商用无门槛;
- 长上下文工程落地最优开源方案:1M上下文稳定可用,吞吐量远超前代,适配仓库级代码处理;
- 编码能力开源断层第一:全维度代码基准碾压Qwen、DeepSeek、MiniMax等同级开源模型,逼近顶级闭源;
- 架构底层优化完善:IndexShare+MTP双重降本提速,推理引擎配套优化,本地部署、云端服务都友好;
- 完整Agent配套体系:配套ZCode桌面客户端、Slime训练框架、多档位思考调节,一站式开发链路;
- 完善反作弊、长任务RL方案:针对工程Agent场景深度定制,训练出的模型无“捷径投机”,真实可用。
⚠️ 现存短板
- 通用综合推理略逊顶级闭源:HLE综合推理40.5分,低于Claude Opus 4.8(49.8)、GPT-5.5(41.4),纯数理通用问答上限仍有差距;
- 超高难度超长工程任务仍有差距:SWE-Marathon评测落后Opus 4.8 13个百分点,超大规模编译器、底层内核开发仍不及闭源旗舰;
- 无原生多模态能力:仅支持文本/代码输入,不支持图片、图表解析,图文混合开发场景受限;
- 峰值调用成本偏高:云端API高峰时段(北京时间14:00-18:00)消耗3倍配额,仅闲时优惠1倍;
- 创意类文本生成偏弱:模型偏向逻辑、代码类理性输出,文学、创意写作表现力弱于主打创作的大模型。
五、三种落地使用方式,开发者直接上手
1. 云端在线调用(Z.ai平台)
官网z.ai直接对话GLM-5.2,支持开启1M上下文模式,切换High/Max思考档位。
2. 代码开发工具接入(ZCode/Claude Code/OpenCode)
- 订阅GLM Coding Plan,模型名填写
GLM-5.2,Claude Code中使用GLM-5.2[1m]开启百万上下文; - 福利:9月底前闲时调用仅1倍配额;6.30前ZCode内使用享1.5倍有效配额;
- 适配SSH远程开发、长任务/goal指令,一站式工程开发。
3. 本地私有化部署
模型权重开源发布于HuggingFace、ModelScope,兼容transformers、vLLM、SGLang、ktransformers主流推理框架,企业可本地离线部署,数据不出内网。
六、GLM-5.2开源代码大模型
在闭源模型垄断高端工程Agent赛道的当下,GLM-5.2交出了一份极具竞争力的开源答卷:
- 1M稳定可用上下文,解决开发者长期碎片化处理代码、文档的痛点;
- 开源第一的编码实力,中小型企业、独立开发者无需高额闭源API成本,就能完成生产级项目开发;
- 全套自研底层架构,从训练、推理到部署全链路优化,兼顾性能与落地成本;
- 完全开源商用友好,MIT协议无地域、商用限制,降低AI开发门槛。
它不是GLM-5.1的简单迭代,而是面向“长程智能体工程时代”的重构产品。如果你是程序员、算法工程师、AI工具开发者,想要低成本拥有仓库级代码处理、超长任务智能体能力,GLM-5.2是目前最优的开源选择。
但同时也要客观看待,在顶级通用推理、超大型底层工程、多模态场景上,它和Claude Opus、GPT旗舰仍存在小幅差距,适合以代码、长文本处理为核心需求的团队落地。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)